はじめに
elasticsearch-railsを使うことが前提の記事になります。記事の中で出てくるサンプルや環境は、RailsとElasticsearchで検索機能をつくり色々試してみる - その1:サンプルアプリケーションの作成をもとにしています。
サジェストを実装する上でのElasticsearchのデータスキーマやアナライザー等の設計部分はElasticsearch キーワードサジェスト日本語のための設計の記事を参考にさせてもらっています。
本記事では、サジェスト機能をelasticsearch-railsを使ってRailsアプリケーションに追加していく方法に焦点を当てて紹介していきます。最終的なソースコードはGitHubに上げておきます。
完成イメージ

こんな感じで検索窓に2文字以上入力すると候補となるキーワードをサジェストする機能を追加します。
全体像
検索履歴を保存してサジェストワードとして使用
実際のアプリケーションを想定してユーザーの検索したキーワードをサジェストワードとして使用するようにします。
要件によっては検索してほしいキーワードをサジェストワードに登録していく方法などいろんな方法がが考えられますが今回はこの方法でいきます。

Railsアプリを経由してサジェストワードを取得
ユーザーの環境からElasticsearchが公開されているような場合は、ブラウザから直接Elasticsearchにリクエストを送ることも考えられますが、今回はRailsアプリケーションのみからElasticsearchが公開されている場合を想定して、Railsアプリケーションを経由してサジェストワードを返却していきます。

検索ワードの保存
ここから実装に入っていきます。まずは検索ワードを保存するテーブルを追加し保存していきます。
後ほどElasticsearchにキーワードを登録する際に、検索にひっかからないワードはサジェストのワードからは除外できるように検索されたワードだけでなくhitした件数も保存するようにします。
保存用のテーブル追加
$ bundle exec rails g migration create_search_word_log
キーワードとhitした件数を保存するカラムを追加します。
class CreateSearchWordLog < ActiveRecord::Migration[5.2]
def change
create_table :search_word_logs do |t|
t.string :word
t.integer :hit_number
t.timestamps
end
end
end
$ bundle exec rails db:migrate
対応するモデルを追加します。
class SearchWordLog < ApplicationRecord
end
保存処理追加
コントローラに検索履歴をためるための処理を追加していきます。
class MangasController < ApplicationController
before_action :set_manga, only: [:show, :edit, :update, :destroy]
+ after_action :save_search_log, only: [:index]
def index
@mangas = if search_word.present?
Manga.es_search(search_word).page(params[:page] || 1).per(5).records
else
Manga.page(params[:page] || 1).per(5)
end
end
private
+ def save_search_log
+ return if search_word.blank?
+ SearchWordLog.create(word: search_word, hit_number: @mangas.size)
+ end
サジェスト用のindexの定義と検索クエリの作成
ここまででサジェストに登録するワードの準備できたので、Elasticsearchにどうのように登録していくかの定義と同時に検索のクエリを追加していきます。
検索機能で追加したものと同様にconcernを作成します。
module SearchWordLogSearchable
extend ActiveSupport::Concern
included do
include Elasticsearch::Model
# a. サジェスト用のindex
index_name "es_search_log_#{Rails.env}"
# b. self.analyzer_settingsで下のほうに定義したanalyzerを使えるようにする。
settings analysis: self.analyzer_settings do
mappings dynamic: 'false' do
indexes :id, type: 'text', analyzer: 'kuromoji'
# c. マルチフィールドを定義する
indexes :word, type: 'text', fielddata: true, analyzer: 'keyword_analyzer' do
indexes :autocomplete, type: 'text', analyzer: 'autocomplete_index_analyzer', search_analyzer: 'autocomplete_search_analyzer'
indexes :readingform, type: 'text', analyzer: 'readingform_index_analyzer', search_analyzer: 'readingform_search_analyzer'
end
indexes :hit_number, type: 'integer'
indexes :created_at, type: 'date', format: 'YYYY-MM-dd kk:mm:ss'
end
end
def as_indexed_json(*)
attributes
.symbolize_keys
.slice(:id, :word, :hit_number)
.merge(
created_at: created_at.strftime("%Y-%m-%d %H:%M:%S")
)
end
end
class_methods do
def create_index!
client = __elasticsearch__.client
client.indices.delete index: self.index_name rescue nil
client.indices.create(index: self.index_name,
body: {
settings: self.settings.to_hash,
mappings: self.mappings.to_hash
})
end
# d. 検索クエリの定義
def es_search(query)
__elasticsearch__.search({
size: 0,
query: {
bool: {
should: [{
match: {
"word.autocomplete" => {
query: query
}
}
}, {
match: {
"word.readingform" => {
query: query,
fuzziness: "AUTO",
operator: "and"
}
}
}]
}
},
aggs: {
keywords: {
terms: {
field: "word",
order: {
_count: "desc"
},
size: "10"
}
}
}
})
end
# e. analyzerの定義
def analyzer_settings
{
analyzer: {
keyword_analyzer: {
type: "custom",
char_filter: ["normalize", "whitespaces"],
tokenizer: "keyword",
filter: ["lowercase", "trim", "maxlength"]
},
autocomplete_index_analyzer: {
type: "custom",
char_filter: ["normalize", "whitespaces"],
tokenizer: "keyword",
filter: ["lowercase", "trim", "maxlength", "engram"]
},
autocomplete_search_analyzer: {
type: "custom",
char_filter: ["normalize", "whitespaces"],
tokenizer: "keyword",
filter: ["lowercase", "trim", "maxlength"]
},
readingform_index_analyzer: {
type: "custom",
char_filter: ["normalize", "whitespaces"],
tokenizer: "japanese_normal",
filter: ["lowercase", "trim", "readingform", "asciifolding", "maxlength", "engram"]
},
readingform_search_analyzer: {
type: "custom",
char_filter: ["normalize", "whitespaces", "katakana", "romaji"],
tokenizer: "japanese_normal",
filter: ["lowercase", "trim", "maxlength", "readingform", "asciifolding"]
},
},
filter: {
readingform: {
type: "kuromoji_readingform",
use_romaji: true
},
engram: {
type: "edgeNGram",
min_gram: 1,
max_gram: 36
},
maxlength: {
type: "length",
max: 36
}
},
char_filter: {
normalize: {
type: "icu_normalizer",
name: "nfkc_cf",
mode: "compose",
},
katakana: {
type: "mapping",
mappings: [
"ぁ=>ァ", "ぃ=>ィ", "ぅ=>ゥ", "ぇ=>ェ", "ぉ=>ォ",
"っ=>ッ", "ゃ=>ャ", "ゅ=>ュ", "ょ=>ョ",
"が=>ガ", "ぎ=>ギ", "ぐ=>グ", "げ=>ゲ", "ご=>ゴ",
"ざ=>ザ", "じ=>ジ", "ず=>ズ", "ぜ=>ゼ", "ぞ=>ゾ",
"だ=>ダ", "ぢ=>ヂ", "づ=>ヅ", "で=>デ", "ど=>ド",
"ば=>バ", "び=>ビ", "ぶ=>ブ", "べ=>ベ", "ぼ=>ボ",
"ぱ=>パ", "ぴ=>ピ", "ぷ=>プ", "ぺ=>ペ", "ぽ=>ポ",
"ゔ=>ヴ",
"あ=>ア", "い=>イ", "う=>ウ", "え=>エ", "お=>オ",
"か=>カ", "き=>キ", "く=>ク", "け=>ケ", "こ=>コ",
"さ=>サ", "し=>シ", "す=>ス", "せ=>セ", "そ=>ソ",
"た=>タ", "ち=>チ", "つ=>ツ", "て=>テ", "と=>ト",
"な=>ナ", "に=>ニ", "ぬ=>ヌ", "ね=>ネ", "の=>ノ",
"は=>ハ", "ひ=>ヒ", "ふ=>フ", "へ=>ヘ", "ほ=>ホ",
"ま=>マ", "み=>ミ", "む=>ム", "め=>メ", "も=>モ",
"や=>ヤ", "ゆ=>ユ", "よ=>ヨ",
"ら=>ラ", "り=>リ", "る=>ル", "れ=>レ", "ろ=>ロ",
"わ=>ワ", "を=>ヲ", "ん=>ン"
]
},
romaji: {
type: "mapping",
mappings: [
"キャ=>kya", "キュ=>kyu", "キョ=>kyo",
"シャ=>sha", "シュ=>shu", "ショ=>sho",
"チャ=>cha", "チュ=>chu", "チョ=>cho",
"ニャ=>nya", "ニュ=>nyu", "ニョ=>nyo",
"ヒャ=>hya", "ヒュ=>hyu", "ヒョ=>hyo",
"ミャ=>mya", "ミュ=>myu", "ミョ=>myo",
"リャ=>rya", "リュ=>ryu", "リョ=>ryo",
"ファ=>fa", "フィ=>fi", "フェ=>fe", "フォ=>fo",
"ギャ=>gya", "ギュ=>gyu", "ギョ=>gyo",
"ジャ=>ja", "ジュ=>ju", "ジョ=>jo",
"ヂャ=>ja", "ヂュ=>ju", "ヂョ=>jo",
"ビャ=>bya", "ビュ=>byu", "ビョ=>byo",
"ヴァ=>va", "ヴィ=>vi", "ヴ=>v", "ヴェ=>ve", "ヴォ=>vo",
"ァ=>a", "ィ=>i", "ゥ=>u", "ェ=>e", "ォ=>o",
"ッ=>t",
"ャ=>ya", "ュ=>yu", "ョ=>yo",
"ガ=>ga", "ギ=>gi", "グ=>gu", "ゲ=>ge", "ゴ=>go",
"ザ=>za", "ジ=>ji", "ズ=>zu", "ゼ=>ze", "ゾ=>zo",
"ダ=>da", "ヂ=>ji", "ヅ=>zu", "デ=>de", "ド=>do",
"バ=>ba", "ビ=>bi", "ブ=>bu", "ベ=>be", "ボ=>bo",
"パ=>pa", "ピ=>pi", "プ=>pu", "ペ=>pe", "ポ=>po",
"ア=>a", "イ=>i", "ウ=>u", "エ=>e", "オ=>o",
"カ=>ka", "キ=>ki", "ク=>ku", "ケ=>ke", "コ=>ko",
"サ=>sa", "シ=>shi", "ス=>su", "セ=>se", "ソ=>so",
"タ=>ta", "チ=>chi", "ツ=>tsu", "テ=>te", "ト=>to",
"ナ=>na", "ニ=>ni", "ヌ=>nu", "ネ=>ne", "ノ=>no",
"ハ=>ha", "ヒ=>hi", "フ=>fu", "ヘ=>he", "ホ=>ho",
"マ=>ma", "ミ=>mi", "ム=>mu", "メ=>me", "モ=>mo",
"ヤ=>ya", "ユ=>yu", "ヨ=>yo",
"ラ=>ra", "リ=>ri", "ル=>ru", "レ=>re", "ロ=>ro",
"ワ=>wa", "ヲ=>o", "ン=>n"
]
},
whitespaces: {
type: "pattern_replace",
pattern: "\\s{2,}",
replacement: "\u0020"
},
},
tokenizer: {
japanese_normal: {
mode: "normal",
type: "kuromoji_tokenizer"
},
engram: {
type: "edgeNGram",
min_gram: 1,
max_gram: 36
}
},
}
end
end
end
作成したconcernをモデルで使えるようにinclude
class SearchWordLog < ApplicationRecord
+ include SearchWordLogSearchable
end
定義の解説
b. analyzerの登録
self.analyzer_settings の箇所を追加することで analyzer_settings メソッド内に独自に定義したアナライザーを登録しています。
c.マルチフィールドの定義
Elasticsearchへの登録、検索、読み仮名での登録、検索、検索結果の集計とキーワードの表示で別のAnalyzerを使いたいため、マルチフィールドを使いその中で登録と検索で別のAnalyzerを使うようにマッピングを定義しています。
それぞれの用途は以下の表のようになります。各Analyzerで具体的にどのようにキーワードがアナライズされるかの例を記事の最後に載せていますので詳しくはそちらを参照ください。
| filed | analyzer | 用途 |
|---|---|---|
| word | keyword_analyzer | 検索した結果の集計とサジェストとして表示する文字列を登録するためのアナライザー |
| word.autocomplete | autocomplete_index_analyzer | 検索ワードを加工して登録していくためのアナライザー |
| word.autocomplete | autocomplete_search_analyzer | 前方一致検索を行う際に使用するのアナライザー |
| word.readingform | readingform_index_analyzer | 読み仮名でhitできるように検索ワードを加工して登録していくためのアナライザー |
| word.readingform | readingform_search_analyzer | 読み仮名で前方一致検索を行う際に使用するのアナライザー |
それぞれどこで使用されているかは、全体像で使った図でいうと以下のようなイメージになります。
キーワード登録時のアナライザーのイメージ

検索時のアナライザーのイメージ

docker imageの修正
さきほどのanalyzerの定義でchar_filterにicu_normalizerを指定しているのでanalysis-icuのプラグインを使えるように以下を追加してイメージをビルドしておきます。
RUN bin/elasticsearch-plugin install analysis-icu
index追加
indexの定義が作成できたのでrakeタスクを追加してindexを作成します。
namespace :elasticsearch do
+ desc 'サジェスト用のindex作成'
+ task :create_suggest_index => :environment do
+ SearchWordLog.create_index!
+ end
end
$ bundle exec rake elasticsearch:create_suggest_index
テスト用に検索履歴を追加
画面上でぽちぽち登録していくか、スクリプトを書いて search_word_logs テーブルにデータ登録していきます。とりあえずサンプルとして動かすなら数十件ほど追加すればOKかと思います。
データがたたまったところでindexに登録していきます。
検索にhitしたキーワードのみをサジェストワードとして使いたいので、scopeを使用します。
class SearchWordLog < ApplicationRecord
include SearchWordLogSearchable
+ scope :searchable_word, -> {
+ where('hit_number > 0')
+ }
end
rakeタスクを登録して実行します。
namespace :elasticsearch do
+ desc 'サジェスト用のキーワードを登録'
+ task :import_suggest_word => :environment do
+ SearchWordLog.__elasticsearch__.import scope: 'searchable_word'
+ end
end
bundle exec rake elasticsearch:import_suggest_word
サジェストを返却するAPIの追加
GET /mangas/suggest?word={keyword} でサジェストワードを取得できるように修正していきます。
ルーティング追加
Rails.application.routes.draw do
resources :mangas do
+ collection do
+ get :suggest
+ end
end
end
コントローラーにアクション追加
class MangasController < ApplicationController
・・・
+ def suggest
+ # concerns に追加した `es_search` メソッドで検索
+ suggest_words = SearchWordLog.es_search(params[:word]).aggregations["keywords"]["buckets"]
+ render json: { suggest_words: suggest_words.map{|word| word["key"]} }
+ end
private
・・・
end
ポイントとしては、今回定義したes_searchメソッドではaggregationsで集計してhitした件数が多いキーワードを取得しているため、aggregationsメソッドを使うことで結果を取り出すことができます。
es_searchで以下のような形式のjsonが返却されaggregations["keywords"]["buckets"]で対象のキーワードの配列を取得しています。
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 6,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"keywords" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "スライム",
"doc_count" : 3
},
{
"key" : "スラムダンク",
"doc_count" : 3
}
]
}
}
}
View側の修正
最後にview側に修正を入れて行きます。今回はライブラリを使わずにシンプルなJavascriptを追加します。
js追加
document.addEventListener('turbolinks:load', function () { // turbolinksを使用しない場合はここは不要
let timeout = null;
function selectSuggest(e) {
document.querySelector("#search_word").value = e.target.textContent;
document.querySelector(".SearchForm").submit();
}
function displayNoneSuggestList () {
let classList = document.querySelector(".dropdown").classList;
if (classList.contains("is-active")) {
classList.remove("is-active")
}
}
function displaySuggestList() {
let classList = document.querySelector(".dropdown").classList;
if (!classList.contains("is-active")) {
classList.add("is-active")
}
}
// apiのレスポンスを元にhtmlを成形してサジェストリストを表示する
function updateSuggestWords(words) {
if (words.length > 0) {
const dropdownMenu = document.querySelector("#dropdown-menu");
let wordList = "";
words.forEach(word => {
wordList += `<div class="dropdown-item" role="option">${word}</div>`;
});
const html = `<div id="sugget-list" class="dropdown-content">${wordList}</div>`;
dropdownMenu.innerHTML = html;
displaySuggestList();
const suggestList = document.querySelectorAll(".dropdown-item");
if (suggestList) {
// サジェストワードが選択された場合にそのワードで検索を行うようにイベントリスナーに登録
suggestList.forEach(element => {
element.addEventListener("click", selectSuggest);
});
}
} else {
displayNoneSuggestList();
}
}
function getSuggetWords(e) {
const value = e.target.value;
clearTimeout(timeout);
// 2文字以上入力された場合にサジェストワードを取得
if (value.length > 1) {
// setTimeoutを使ってapiが呼ばれるまでに時間を置く
timeout = setTimeout(function () {
fetch(`http://localhost:3003/mangas/suggest?word=${value}`)
.then(res => {
return res.json();
})
.then(resJson => {
updateSuggestWords(resJson.suggest_words);
})
.catch(error => console.log(error))
}, 300);
} else {
displayNoneSuggestList()
}
}
// 検索ワードの入力をイベントリスナーに登録
const inputWord = document.querySelector("#search_word");
inputWord.addEventListener("input", getSuggetWords);
});
解説
検索ワードが入力されたらapiからサジェストワードを取得してリストを更新するメソッド(getSuggetWords)をイベントリスナーに登録します。
getSuggetWordsでは入力の度にapiが呼ばれてサジェストが何度も変わるのは使いづらいので、2文字以上入力された場合に0.3秒後にapiを呼ぶようにしています。
apiからのレスポンスをupdateSuggestWordsに渡してhtmlを成型してサジェストリストを追加しています。追加するリストにイベントリスナーを登録してキーワードが選択された場合にselectSuggestメソッドを呼び検索を実行するようにしています。
このサンプルアプリではCSSは、bulmaを使用っているので、bulmaのdropdownのクラスを使ってスタイルを整えています。
view修正
jsで使用するクラスや要素を追加し、jsを読み込みます。
<div class="container" style="margin-top: 30px">
- <%= form_tag(mangas_path, method: :get, class: "field has-addons has-addons-centered") do %>
- <div class="control">
+ <%= form_tag(mangas_path, method: :get, class: "field has-addons has-addons-centered SearchForm", autocomplete: "off") do %>
+ <div class="control SearchInput">
<%= text_field_tag :search_word, @search_word, class: "input", placeholder: "漫画を検索する" %>
+ <div class="dropdown">
+ <div class="dropdown-menu" id="dropdown-menu" role="menu">
+ </div>
</div>
</div>
<div class="control">
<%= submit_tag "検索", class: "button is-info" %>
</div>
<% end %>
</div>
・
・
・
+ <%= javascript_include_tag 'suggest' %>
追加したjsを読み込むためにinitializer修正
+ Rails.application.config.assets.precompile += %w(suggest.js)
以上で完成です!
おまけ:analyzerの動作確認
今回追加したanalyzerが実際にどのように動作するかを「転生」という単語を例に見ていきます。
documentの登録
まずはdocument登録する際のanalyzerの動きを確認します。
「転生」という単語を登録する場合以下のようにanalyzeされてindexされています。
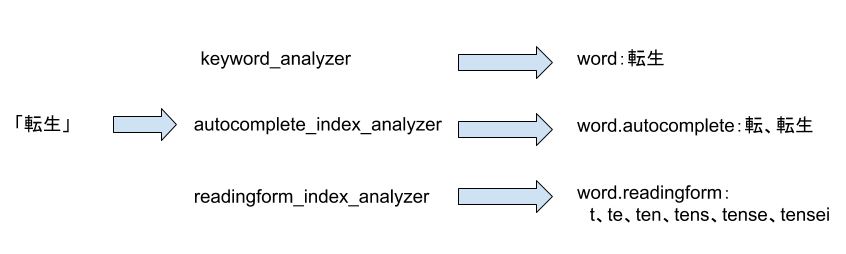
それぞれのAnalyzer APIでの確認結果は以下のようになります。
keyword_analyzer
POST /es_search_log_development/_analyze
{
"analyzer": "keyword_analyzer",
"text": "転生"
}
{
"tokens" : [
{
"token" : "転生",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
}
]
}
autocomplete_index_analyzer
POST /es_search_log_development/_analyze
{
"analyzer": "autocomplete_index_analyzer",
"text": "転生"
}
{
"tokens" : [
{
"token" : "転",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "転生",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
}
]
}
readingform_index_analyzer
POST /es_search_log_development/_analyze
{
"analyzer": "readingform_index_analyzer",
"text": "転生"
}
{
"tokens" : [
{
"token" : "t",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "te",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "ten",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "tens",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "tense",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "tensei",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
}
]
}
documentのsearch
続いてsearch用のanalyzerの動きを見ます。
今度は「転生」、「てんせ」、「ten」のワードで確認します。
以下のイメージのようにanalyzeされています。

autocomplete_search_analyzer
「転生」
POST /es_search_log_development/_analyze
{
"analyzer": "autocomplete_search_analyzer",
"text": "転生"
}
{
"tokens" : [
{
"token" : "転生",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
}
]
}
「てんせ」
POST /es_search_log_development/_analyze
{
"analyzer": "autocomplete_search_analyzer",
"text": "てんせ"
}
{
"tokens" : [
{
"token" : "てんせ",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
}
]
}
「ten」
POST /es_search_log_development/_analyze
{
"analyzer": "autocomplete_search_analyzer",
"text": "ten"
}
{
"tokens" : [
{
"token" : "ten",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
}
]
}
readingform_search_analyzer
「転生」
POST /es_search_log_development/_analyze
{
"analyzer": "readingform_search_analyzer",
"text": "転生"
}
{
"tokens" : [
{
"token" : "tensei",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
}
]
}
「てんせ」
POST /es_search_log_development/_analyze
{
"analyzer": "readingform_search_analyzer",
"text": "てんせ"
}
{
"tokens" : [
{
"token" : "tense",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
}
]
}
「ten」
POST /es_search_log_development/_analyze
{
"analyzer": "readingform_search_analyzer",
"text": "ten"
}
{
"tokens" : [
{
"token" : "ten",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 0
}
]
}
サジェストワード検索時のイメージ
indexとsearchのanalyzerの動きをふまえると、「転生」をindexして「転生」、「てんせ」、「ten」を入力した場合、全て「転生」がサジェストされることがわかります。
