はじめに
RailsアプリケーションでElasticsearchを使った検索機能を実装する機会があったため、その際に調査して試したことなどを複数回に分けてまとめていく予定です。
その1としてdocker-composeを使ったローカル環境構築と簡単な検索ができるサンプルアプリケーションを作成していきます。
その2以降で検索機能のカスタマイズや実運用を想定した実装などもう少し掘り下げたところを書いていく予定です。
その2以降の記事
RailsとElasticsearchで検索機能をつくり色々試してみる - ドキュメントの操作
RailsとElasticsearchで検索機能をつくり色々試してみる - Rspec
RailsとElasticsearchで検索機能をつくり色々試してみる - サジェスト機能の追加
RailsとElasticsearchで検索機能をつくり色々試してみる - Synonym(類義語)編
サンプルアプリケーション
登録した漫画の情報を検索して表示するアプリケーションを作成していきます。

環境
- Ruby 2.5.3
- Rails 5.2.2
- Mysql 5.7
- Elatsticsearch 6.5.4
- Kibana 6.5.4
構成
docker-composeを使ってローカル環境を作成します。
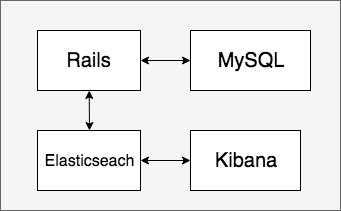
Rails:アプリケーション本体
Mysql:データの永続化
Elasticsearch:検索で使用
Kibana:アプリケーションそのものとは無関係(Elasticsearchで色々試すときに使う)
Rails newまでの流れ
docker-composeを使って環境をつくりRailsとElasticsearchを起動するまでの流れを書いていきます。(本題とはあまり関係ないので不要な人は読み飛ばしてください)
docker-compose.yml
プロジェクトのルートに以下のようにファイルを置きます。
.
├── Dockerfile
├── docker
│ ├── es
│ │ └── Dockerfile
│ └── mysql
│ └── my.cnf
└── docker-compose.yml
version: '3'
services:
# Elasticsearch用のコンテナ
es:
build: ./docker/es
container_name: es_sample
environment:
- cluster.name=rails-sample-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es_sample_data:/usr/share/elasticsearch/data
ports:
- 9200:9200
# Kibana用のコンテナ
kibana:
image: docker.elastic.co/kibana/kibana:6.5.4
environment:
SERVER_NAME: localhost:5601
ELASTICSEARCH_URL: http://es_sample:9200
ports:
- 5601:5601
depends_on:
- es
# MYSQL用のコンテナ
db:
environment:
- MYSQL_ROOT_PASSWORD=docker
- MYSQL_PASSWORD=docker
- MYSQL_USER=docker
- MYSQL_DATABASE=rails_es_sample
build: ./docker/mysql
ports:
- "3306:3306"
# Rails用のコンテナ
rails:
build: .
# 必要であればshなどに bundle install や rails s を実行してrailsを起動する処理を書く
# command: scripts/start-server.sh
volumes:
- .:/app
# 公式のDockerfile(ruby:2.5.3-stretch)では環境変数のBUNDLE_APP_CONFIGがデフォルトで
# /usr/local/bundleに設定されているため、dockerのローカルvolumeでマウントしてそこにgemを入れている
- vendor_bundle:/user/local/bundle
ports:
- "3003:3000"
links:
- db
- es
environment:
- RAILS_DATABASE_USERNAME=root
- RAILS_DATABASE_PASSWORD=docker
- RAILS_DATABASE_NAME=rails_es_sample
- RAILS_DATABASE_HOST=db
tty: true
stdin_open: true
volumes:
es_sample_data:
driver: local
vendor_bundle:
driver: local
FROM ruby:2.5.3-stretch
ENV BUNDLE_GEMFILE=/app/Gemfile \
BUNDLE_JOBS=2 \
RAILS_ENV=development \
LANG=C.UTF-8
RUN apt-get update -qq
RUN apt-get install -y build-essential
RUN apt-get install -y libpq-dev
RUN apt-get install -y nodejs
# ワーキングディレクトリの設定
RUN mkdir /app
WORKDIR /app
# ElasticDocker
FROM docker.elastic.co/elasticsearch/elasticsearch:6.5.4
# 日本語をあつかうときに使うプラグイン
RUN bin/elasticsearch-plugin install analysis-kuromoji
./docker/mysql/my.cnfは本題ではないの割愛します。
一応こちらにのせておきます。
imageのbuildと起動
# imageのbuildと起動
$ docker-compose up -d
# 起動確認
$ docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------
es_sample /usr/local/bin/docker-entr ... Up 0.0.0.0:9200->9200/tcp, 9300/tcp
rails_es_sample_db_1 docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp, 33060/tcp
rails_es_sample_kibana_1 /usr/local/bin/kibana-docker Up 0.0.0.0:5601->5601/tcp
rails_es_sample_rails_1 irb Up 0.0.0.0:3003->3000/tcp
rails new
コンテナに入りrailsプロジェクトを作成していきます
# コンテナに入る
# 「rails_es_sample_rails_1」 は docker-compose ps の Name
$ docker exec -it rails_es_sample_rails_1 /bin/bash
# コンテナ内で実行
/app# bundle init
gemファイルを編集
# frozen_string_literal: true
source "https://rubygems.org"
git_source(:github) {|repo_name| "https://github.com/#{repo_name}" }
# railsがコメントアウトされているので外す
gem "rails"
Railsのインストールとプロジェクト作成
# railsのコンテナ内
/app# bundle install
/app# bundle exec rails new .
# 以下のようにgemfileを上書きするか聞かれますが、まだ何も追加していない状態なので「Y」で上書き
# Overwrite /app/Gemfile? (enter "h" for help) [Ynaqdhm]
mysql用の設定
mysqlのアダプタ追加
# gem 'sqlite3'
gem 'mysql2'
/app# bundle install
database.ymlがデフォルトのままになっているため修正
default: &default
adapter: mysql2
encoding: utf8
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
username: root
password: docker
host: db
development:
<<: *default
database: rails_es_sample
rails起動
/app# bundle exec rails s
起動確認
rails
ブラウザでhttp://localhost:3003/ にアクセスして、いつものやつが表示されることを確認

Elasticsearch
$ curl -XGET http://localhost:9200/
# 以下のようなクラスターやversionの情報が返ればOK
{
"name" : "338gbNM",
"cluster_name" : "rails-sample-cluster",
"cluster_uuid" : "HphoN9CyQcmWeruBOQr1oQ",
"version" : {
"number" : "6.5.4",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "d2ef93d",
"build_date" : "2018-12-17T21:17:40.758843Z",
"build_snapshot" : false,
"lucene_version" : "7.5.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
kibana
ブラウザでhttp://localhost:5601/app/kibana にアクセスして以下のような画面が表示されればOK

ER図
環境は整ったのでサンプルアプリケーションの作成に入っていきます。
ER図ように漫画の情報と関連する作者、出版社、カテゴリを格納するテーブルをを作成していきます。

モデルとテーブルの作成
migrationファイルを作成していきます。
# migrationファイルの作成
/app# bundle exec rails g model author name:string
/app# bundle exec rails g model publisher name:string
/app# bundle exec rails g model category name:string
/app# bundle exec rails g model manga author:references publisher:references category:references title:string description:text
# テーブルの作成
/app# bundle exec rails db:migrate
データの準備
db/seeds.rbにデータを準備をしていきます。(追加するデータのサンプルをこちら)
/app# db/seeds.rbを修正後に実行
bundle exec rails db:seed
コントローラ、ビュー、ルーティングの追加
rails g でファイルを作成して修正していきます。
/app# bundle exec rails g controller Mangas index --helper=false --assets=false
class MangasController < ApplicationController
def index
@mangas = Manga.all
end
end
Rails.application.routes.draw do
resources :mangas, only: %i(index)
end
<h1>Mangas</h1>
<table>
<thead>
<tr>
<th>Aauthor</th>
<th>Publisher</th>
<th>Category</th>
<th>Author</th>
<th>Title</th>
<th>Description</th>
<th colspan="3"></th>
</tr>
</thead>
<tbody>
<% @mangas.each do |manga| %>
<tr>
<td><%= manga.author.name %></td>
<td><%= manga.publisher.name %></td>
<td><%= manga.category.name %></td>
<td><%= manga.author.name %></td>
<td><%= manga.title %></td>
<td><%= manga.description %></td>
</tr>
<% end %>
</tbody>
</table>
Bulmaを使ったスタイルの修正
この時点で、http://localhost:3003/mangasにアクセスすると登録したデータがリスト表示されるようになりますが、見た目がしょぼいので、BulmaというCSSフレームワークを使って少し見た目を整えます。
Gem追加
gemを追加してbundle install
gem "bulma-rails", "~> 0.7.2"
css -> scssに変更して、bulmaをimportする
/
*= require_tree .
*= require_self
*/
@import "bulma";
styleの調整
修正後はこんな感じです。

Elasticsearch用のgem追加
前置きが長くなってしまいましたがここからElasticsearch関連の修正を加えていきます。
elasticの公式リポジトリにあるgemを使っていきます。
gem 'elasticsearch-model', github: 'elasticsearch/elasticsearch-rails', branch: '6.x'
gem 'elasticsearch-rails', github: 'elasticsearch/elasticsearch-rails', branch: '6.x'
elasticsearch-model
include Elasticsearch::Modelをモデルに追加することで様々なメソッドが使えるようになります。
ドキュメント
elasticsearch-rails
Elasticsearchを使うためのrakeタスクやloggerのカスタマイズ、templateの提供などができるようです。
ドキュメント
config設定
接続先の情報を設定します。
# 「es」はdocker-composeのservicesに設定した名前
config = {
host: ENV['ELASTICSEARCH_HOST'] || "es:9200/",
}
Elasticsearch::Model.client = Elasticsearch::Client.new(config)
concernsの追加
Elasticsearch関連の処理をまとめるconcernを作成していきます。
concernのファイルを作成しmodelでincludeするようにします。
class Manga < ApplicationRecord
include MangaSearchable
belongs_to :author
belongs_to :publisher
belongs_to :category
end
module MangaSearchable
extend ActiveSupport::Concern
included do
include Elasticsearch::Model
# ①index名
index_name "es_manga_#{Rails.env}"
# ②マッピング情報
settings do
mappings dynamic: 'false' do
indexes :id, type: 'integer'
indexes :publisher, type: 'keyword'
indexes :author, type: 'keyword'
indexes :category, type: 'text', analyzer: 'kuromoji'
indexes :title, type: 'text', analyzer: 'kuromoji'
indexes :description, type: 'text', analyzer: 'kuromoji'
end
end
# ③mappingの定義に合わせてindexするドキュメントの情報を生成する
def as_indexed_json(*)
attributes
.symbolize_keys
.slice(:id, :title, :description)
.merge(publisher: publisher_name, author: author_name, category: category_name)
end
end
def publisher_name
publisher.name
end
def author_name
author.name
end
def category_name
category.name
end
class_methods do
# ④indexを作成するメソッド
def create_index!
client = __elasticsearch__.client
# すでにindexを作成済みの場合は削除する
client.indices.delete index: self.index_name rescue nil
# indexを作成する
client.indices.create(index: self.index_name,
body: {
settings: self.settings.to_hash,
mappings: self.mappings.to_hash
})
end
end
end
①index名を設定します。誤った操作防止のため環境名を含めるようにしています。
②登録していくドキュメントのマッピング情報を定義しています。ここでフィールドのタイプや、使用するアナライザーなどを指定できます。また、settingsの情報も定義できますが、今回の例ではデフォルトのままとしています。
③モデルの情報を登録するために、mappingで定義した情報に合わせてjsonに変換するためのメソッドです。
④indexを作成するメソッド。作成済みの場合は再作成するように一度削除処理を入れています。
動作確認
Elasticsearch::Modelをincudeすることでgemに追加されたメソッドなどが使えるようになります。
コンソールで動きを確認してみます。
Elasticsearchとの接続確認
pry(main)> Manga.__elasticsearch__.client.cluster.health
=> {"cluster_name"=>"rails-sample-cluster",
"status"=>"green",
"timed_out"=>false,
"number_of_nodes"=>1,
"number_of_data_nodes"=>1,
"active_primary_shards"=>1,
"active_shards"=>1,
"relocating_shards"=>0,
"initializing_shards"=>0,
"unassigned_shards"=>0,
"delayed_unassigned_shards"=>0,
"number_of_pending_tasks"=>0,
"number_of_in_flight_fetch"=>0,
"task_max_waiting_in_queue_millis"=>0,
"active_shards_percent_as_number"=>100.0}
[5] pry(main)>
indexの作成
pry(main)> Manga.create_index!
=> {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"es_manga_development"}
データの登録
importメソッドでmodelの情報を登録します。さきほど追加したas_indexed_jsonの形式に変換してデータが登録されるます。
pry(main)> Manga.__elasticsearch__.import
(5.5ms) SET NAMES utf8, @@SESSION.sql_mode = CONCAT(CONCAT(@@sql_mode, ',STRICT_ALL_TABLES'), ',NO_AUTO_VALUE_ON_ZERO'), @@SESSION.sql_auto_is_null = 0, @@SESSION.wait_timeout = 2147483
Manga Load (3.0ms) SELECT `mangas`.* FROM `mangas` ORDER BY `mangas`.`id` ASC LIMIT 1000
Publisher Load (3.3ms) SELECT `publishers`.* FROM `publishers` WHERE `publishers`.`id` = 1 LIMIT 1
Author Load (0.5ms) SELECT `authors`.* FROM `authors` WHERE `authors`.`id` = 1 LIMIT 1
検索機能の追加
Elasticsearchとの接続確認やデータの登録が完了したので、次は検索機能をつくっていきます。
検索用のメソッド追加
concernに検索用のメソッドを追加します。今回の例では複数のフィールドのいずれかにマッチするものを検索できるように、multi_matchとcross_fieldsを指定しています。指定できるクエリなどはドキュメントに詳しくのっています。
class_methods do
# ...
def es_search(query)
__elasticsearch__.search({
query: {
multi_match: {
fields: %w(id publisher author category title description),
type: 'cross_fields',
query: query,
operator: 'and'
}
}
})
end
end
end
controllerの修正
search_wordというパラメータを受けとってさきほど作成したes_searchメソッドで検索します。検索ワードが空の場合は全てのデータを取得します。
class MangasController < ApplicationController
def index
@mangas = if search_word.present?
Manga.es_search(search_word).records
else
Manga.all
end
end
private
def search_word
@search_word ||= params[:search_word]
end
end
viewの修正
検索窓を追加します。
// ...
</div>
</div>
</section>
// ヘッダーとテーブルの間に検索窓を追加
<div class="container" style="margin-top: 30px">
<%= form_tag(mangas_path, method: :get, class: "field has-addons has-addons-centered") do %>
<div class="control">
<%= text_field_tag :search_word, @search_word, class: "input", placeholder: "漫画を検索する" %>
</div>
<div class="control">
<%= submit_tag "検索", class: "button is-info" %>
</div>
<% end %>
</div>
<div class="container" style="margin-top: 50px">
<table class="table is-striped is-hoverable">
// ...
動作確認
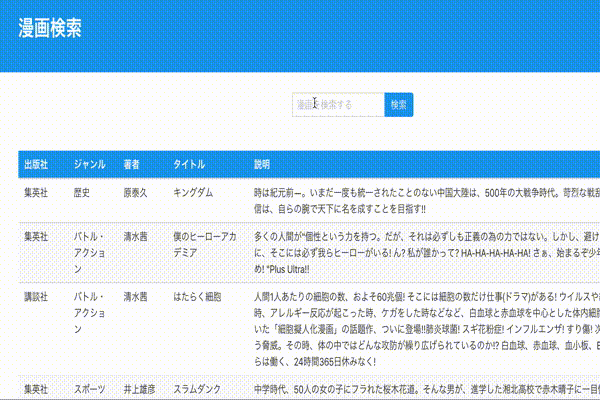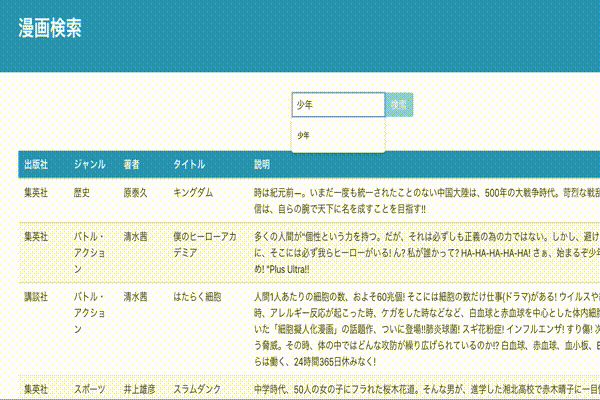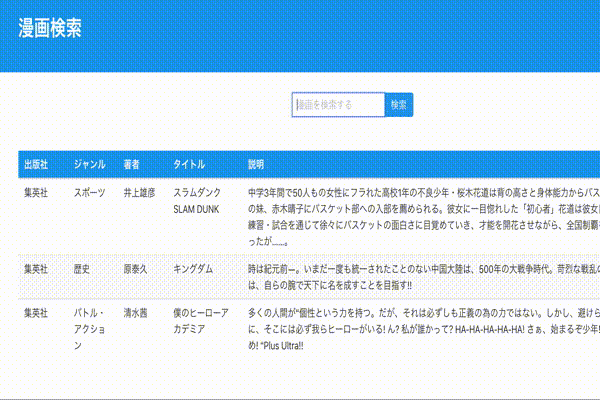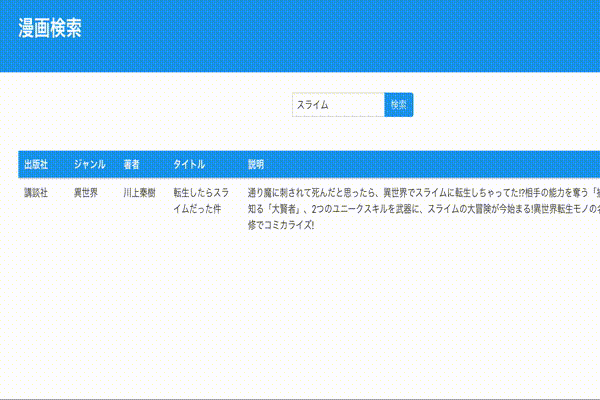
ページネーション
とりあえず検索は動くようになりましたが検索結果のデータを全て表示するのは微妙なので、ページネーションを追加していきます。
gem追加
gem 'kaminari'
注意点としてはElasticsearchのgemよりも上に追加する必要があります
https://github.com/elastic/elasticsearch-rails/tree/master/elasticsearch-model#pagination
The pagination gems must be added before the Elasticsearch gems in your Gemfile, or loaded first in your application.
コントローラ修正
Elasticsearchからのresponseにpageとperを追加します。またElasticsearchを経由しない検索の場合にも追加します。
def index
@mangas = if search_word.present?
Manga.es_search(search_word).page(params[:page] || 1).per(5).records
else
Manga.page(params[:page] || 1).per(5)
end
end
viewの修正
bulmaのスタイルを適用できるようにkaminariのテンプレートを作成します。
/app# bundle exec rails g kaminari:views default
を実行するとapp/views/kaminari以下にファイルが作成されるので、これらのファイルを修正していきます。
細かい修正が多いので割愛しますが、修正版はこちらにのせておきます。
まとめ
少し長くなりましたが、docker-composeで環境をつくってrails newするところからElasticsearchで検索を行うサンプルアプリケーションを作成しました。
とりあえず動くものはできたという段階なので、次回はもう少し掘り下げたところを書いていきたいと思います。