はじめに
朝日新聞社 メディア研究開発センターの山野陽祐です。
早速ですが、皆さんは朝日新聞デジタルの「宮沢喜一日録 戦後政治の軌跡」をご存知でしょうか。連載はすでに30回分が公開され、今後もさらに続く予定となっております。1966年12月から2006年9月まで、40年にわたる宮沢喜一元首相の詳細な政治行動が記された185冊のノートをもとに、朝日新聞社を中心として史実の検証や分析を進めています。
第1回の記事では、私たちメディア研究開発センターの取り組みにもスポットが当たっています。我々は、朝日新聞の記事、首相動静、国会議事録といった多様な資料を、日付を糸口に日録と結びつけ、1966年から2006年までの膨大なテキストを横断検索できるサービスを構築しました。このサービスは、東京大学名誉教授・御厨貴氏を中心とする研究者グループに提供しています(Fig.1)。

Fig. 1 1991年11月4日の画面。画面左に宮沢喜一元首相が綴った日録、画面右にその日の朝日新聞記事・首相動静・国会議事録を表示。さらに、1966年から2006年までの全テキストを検索可能。2020年にリリースして以降、現在も運用中。
この横断検索の中核をなすのが、40年分の「日録」テキストになります。手書きで記録された膨大な紙のアーカイブをデジタル世界へ復元する作業に、大変な労力を費やしました。

Fig.2 1992年11月4日の日録。キッシンジャーとの電話会談についての書き込みが確認できる。
こうしたデータを、再利用可能なものとして整理するため、我々は入念な検討を重ね、約40ものルールを策定し、ページ単位で丁寧なアノテーションを付与することで、14万件以上の高品質なデータを作ることができました。この地道な下準備こそが、政治史の研究を進めていく上での基盤となっています。

Fig.3 取り消し線の扱い方を示した例。
このデータを活用して検索システムを提供するだけでなく、将来的には他の分析や研究に役立てたいと考えています。本記事では、その試みの一端をご紹介したいと思います。
データ駆動型政治史研究
宮沢喜一元首相の日録データを観察すると、いつ、どこで、誰と、何をしていたかが克明に記されていることがわかります。

Fig.4 1991年11月7日の日録。
とりわけ「誰と」に注目することで、当時の政治的意思決定の背景にあった人脈やネットワーク、さらには特定の人物・組織が政策や国際関係の形成にどれほど深く関わっていたかといった、通常の記事や公的記録からは見えにくい政治の“人と人とのつながり”が、よりはっきりと見えてきます。
そこで本記事では固有表現抽出、Wikipediaとのデータ連携、LLMを用いた属性付与などを通じて、人物に焦点を当てた分析の取り組みをしていきます。
固有表現抽出と姓名問題
まず、自然言語処理技術の一つである「固有表現抽出」を日録テキストに適用し、人名が抽出できるか検証しました。

Fig.5 本記事では固有表現抽出はGiNZAを用い、TransformerをベースとしたELECTRAのモデルを活用。
日録テキストに対して人名抽出したところ、独自に用意した日録評価データ50件に対して以下の結果となりました。なお、評価データには苗字のみの人物も含まれており、その数16人となります。
| 指標 | 結果 |
|---|---|
| Precision | 100(%) |
| Recall | 88(%) |
| F1 | 93.16(%) |
人名であるにも関わらず抽出されなかった例としては、瓦力議員、亀岡農水大臣、尾崎大蔵事務次官などが挙げられます。一方、フルネームで記された人物に限ればRecallが97%という結果が得られました。本記事では分析対象をフルネームに限定することで精度を確保しています。
一方で、日録には「田中」さんのように、同一姓が長期にわたって登場するケースも多く、一意に特定することが困難な場合が散見されます。
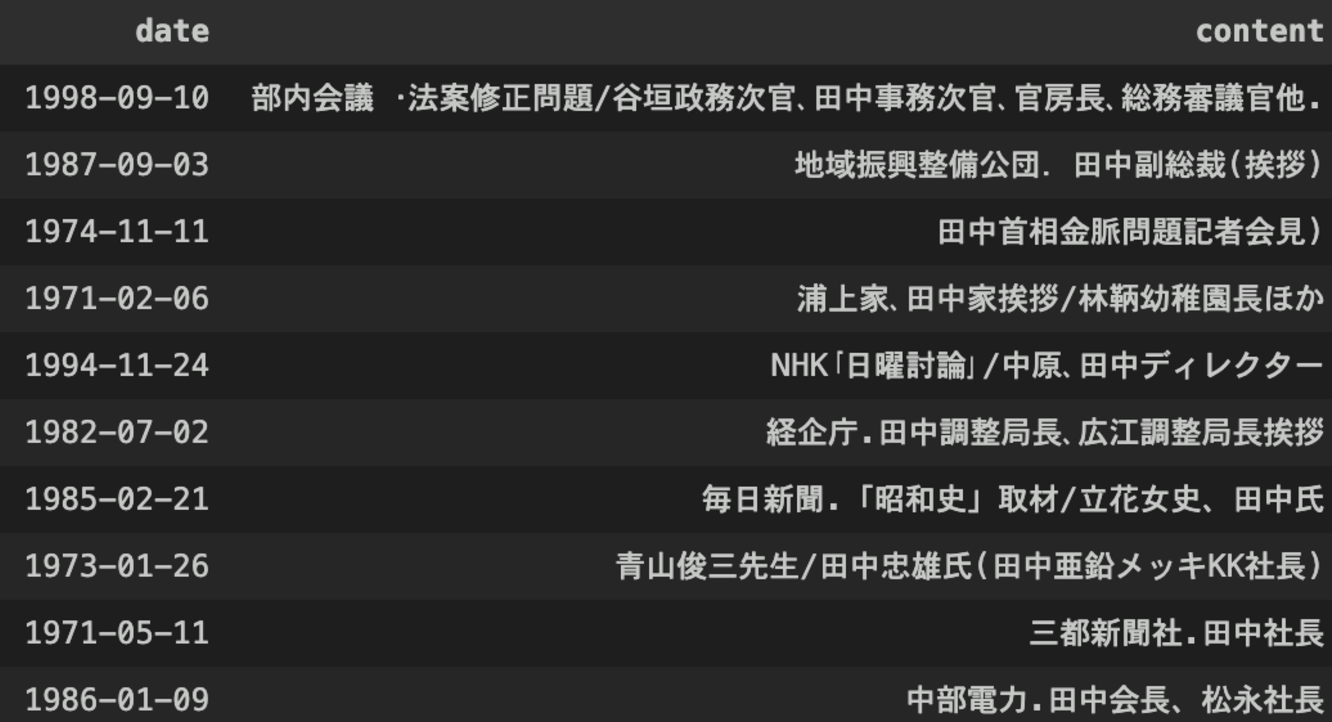
Fig.6 日録で”田中”さんが登場する一例
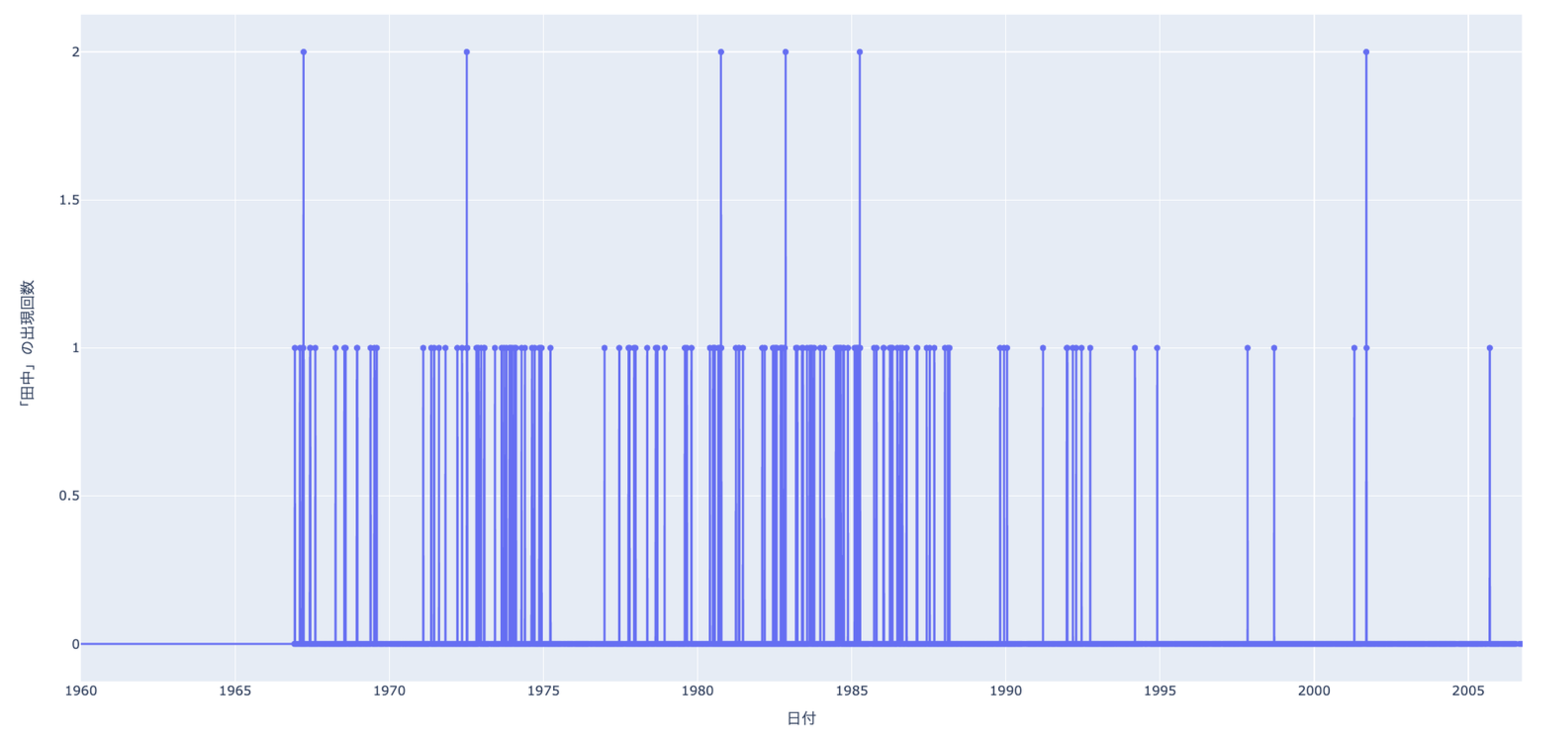
Fig.7 長い期間にわたって田中さんが出現し、一意に特定することが難しい。
こうした問題があるため、今回の分析ではフルネームが判明している人物に対象を絞りました。
Wikipediaとのリンキング
日録から人名を抽出するだけでは、その人物の「属性情報」がわからず、単純な分析結果となってしまうでしょう。「誰と頻繁に接触していたか」は分かっても、「その人物がどのような背景・役割を持っていたか」を把握することは難しいためです。
そこで人物名とWikipediaページを対応づけ、属性情報を補うことにしました。本記事ではwikipediaapiを用いて評価データ100件を確認したところ、98件が正しく該当ページとリンキングすることができました。間違ったケースとしては、該当人物のWikipediaページは存在しないものの、同姓同名人物のページが存在していたこと、ページは存在するが同姓同名の別の人物をリンキングしてしまうことが挙げられました。
また、wikipediaapiを使った結果、別の人物がリンキングされることもありました。そういった場合は文字列が完全一致をしているか判定し、文字列が異なっていれば除外しています。
上記のプロセスを経て、日録に出てくるユニークな人物8,295人中3,081人をWikipediaと紐づけることができました。
属性情報付与
リンキングできたのはいいものの、Wikipediaのテキストは非構造的となっています。そのため政治家・官僚・学者・経済人などのカテゴリー、所属組織、活動分野など、人物属性を定義しデータをLLMを使って構造化していきます。
ここでは、人物を表す属性スキーマを独自に定義し、Wikipedia本文をLLMへ入力しその出力を属性情報とします。



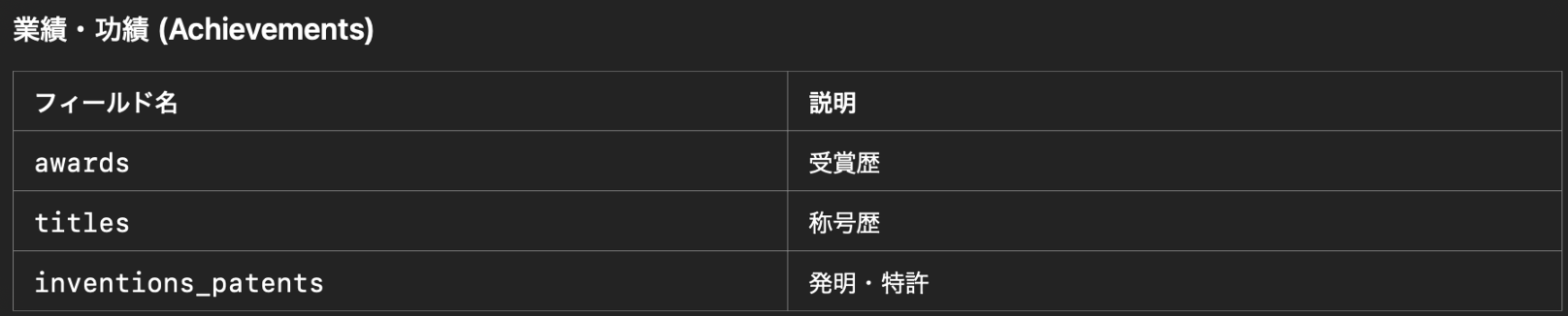

Fig.8 人物を表す属性情報一覧
これらの情報が正しく付与されるかは、Wikipediaに記載されている情報量やLLMの性能、あるいはその性能を引き出すプロンプトが影響するため、特にLLMの選定とプロンプトは慎重に検討しました。本記事ではOpenAIのgpt4o-2024-08-06のStructured Outputを用いて、Wikipediaの本文を入力に属性情報を付与していきます。
宮沢喜一元首相の構造化データ
basic_info
name: 宮沢喜一
birth_date: 1919-10-08
death_date 2007-06-28
birth_place: 東京都
gender: 男性
education
degree: null,
major: 政治学,
university: 東京帝国大学,
enrollment_year: null,
graduation_year: 1941
occupation
{
occupation: 政治家,
position: 内閣総理大臣,
affiliation: {
category: 政府機関,
subcategory 中央政府,
name: 日本政府
},
start_date: 1991,
end_date: 1993
},
{
occupation: 政治家,
position: 大蔵大臣,
affiliation: {
category: 政府機関,
subcategory: 中央政府,
name: 日本政府
},
start_date: 1986,
end_date: 1988
},
{
occupation: 政治家,
position: 大蔵大臣,
affiliation: {
category: 政府機関,
subcategory: 中央政府,
name: 日本政府
},
start_date: 1998,
end_date: 2001
},
{
occupation: 政治家,
position: 外務大臣,
affiliation: {
category: 政府機関,
subcategory: 中央政府,
name: 日本政府
},
start_date: 1974,
end_date: 1976
},
{
occupation: 政治家,
position: 経済企画庁長官,
affiliation: {
category: 政府機関,
subcategory: 中央政府,
name: 日本政府
},
start_date: 1962,
end_date: 1964
}]
achievements
awards: None
titles: 内閣総理大臣, 自由民主党総裁
inventions_patents: None
relationships:
{
name: 宮澤裕,
relation: 父
},
{
name: 宮澤こと,
relation: 母
},
{
name: 宮澤弘,
relation: 弟
},
{
name: 宮澤泰,
relation: 弟
},
{
name: 宮澤庸子,
relation: 妻
},
{
name: 宮澤エマ,
relation: 孫
}
social_cultural_attributes
political_affiliation: None
political_party: 自由民主党
industry: None
attributes: 政治家, 官僚
農林水産大臣や副総理など抜け漏れはあるものの、構造化データに基本的には間違いはなさそうです。(がしっかり評価しなければならないところでもあるので、今後進めていきます。)
この処理をWikipediaとリンクした3,081名に適用したことで、政治家や官僚、学者、企業人、さらにはどの組織・大学・政府機関に属していたかなどを分析する準備が整いました。
グラフネットワーク
さてようやくここまで辿り着きました。
こうして得られた属性を付与した人物データを用いることで、日録中に記録された出会いや会談を単なる「接触の列挙」から「関係理解」へと昇華することができます。特定の政策分野に関わる人々が頻繁に接触していた事実が見えたり、特定の背景や経歴を持つ人物が政策形成の裏側でどのような役割を果たしていたかが浮かび上がる可能性があります。
得られた構造化データから人物関係図に落とし込んでいきます。ここではノード(人物・組織・大学など)とエッジ(人と人、人と組織などの関係)からなるグラフネットワークを用いて、当時の政治にまつわる人物相関図を表現してみることにします。
ノードとエッジのサンプル
エッジ
source target
福永信彦 宮沢喜一
東畑精一 宮沢喜一
近藤鉄雄 カリフォルニア大学バークレー校
村岡兼造 横内正明
神信一 宮沢喜一
水野清 宮沢喜一
小山長規 岡崎勝男
林貞行 宮沢喜一
安倍晋三 宮沢喜一
粕谷茂 宮沢喜一
小林義雄 大蔵省
秦野章 宮沢喜一
佐藤欣子 ハーバード大学
渡部祐 宮沢喜一
大村雅基 国税庁
阿部信泰 ウィーン国際機関日本国政府代表部
ノード
source target
福永信彦 宮沢喜一
東畑精一 宮沢喜一
近藤鉄雄 カリフォルニア大学バークレー校
村岡兼造 横内正明
神信一 宮沢喜一
水野清 宮沢喜一
小山長規 岡崎勝男
林貞行 宮沢喜一
安倍晋三 宮沢喜一
粕谷茂 宮沢喜一
小林義雄 大蔵省
秦野章 宮沢喜一
佐藤欣子 ハーバード大学
渡部祐 宮沢喜一
大村雅基 国税庁
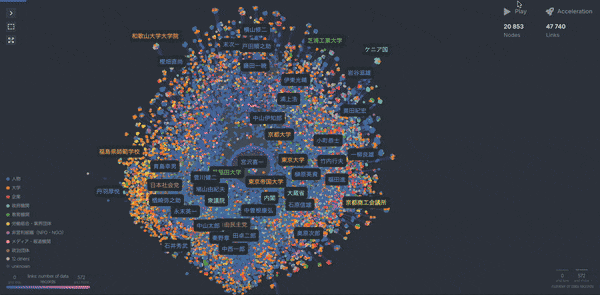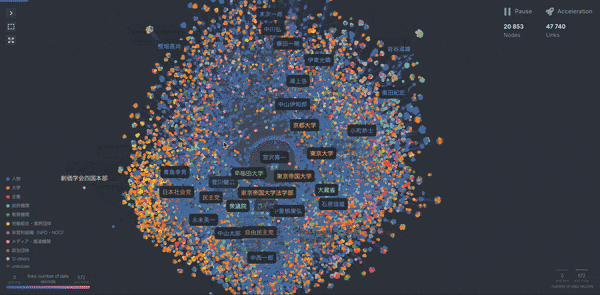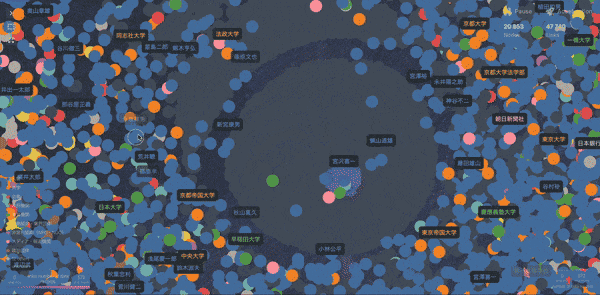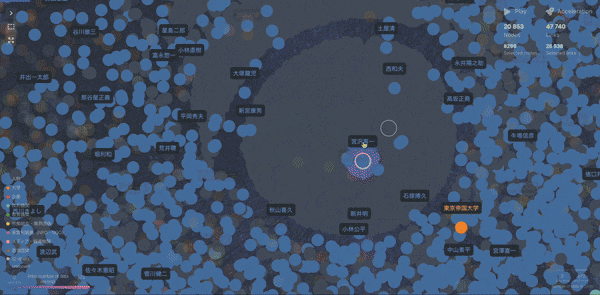
Fig.9 Cosmographを用いたグラフネットワーク
こちらがあらゆる属性情報を含んだグラフネットワーク図です。宮沢喜一元首相を中心に人物や大学や省庁、企業が複雑に絡まっているのがわかります。
これから
データ分析やジャーナリズムの価値は、単に可視化すること自体ではなく、それらをもとに新たな知見や発見を引き出せるかにかかっていると考えています。
今後は、今回得られた結果をもとに宮沢日録を担当する編集者と議論を重ね、さらなる分析を深めていければと思います。
これからも日録プロジェクトを通じてデータを適切に活用する方法を模索し、政治史研究に新しい光を当てる取り組みを積極的に進めていきたいと思います。
おまけ 〜苗字のみから推定する方法について模索中〜
苗字のみで記載された人物に対しては、本記事では分析対象から外していました。この課題に対しては、Tavilyのような検索エンジンAPIを使えば、解決できる可能性があるかもしれません。
以下の検証結果は、苗字と肩書き、その日付を入力とし、tavily searchで人物名を検索した時の出力例と正解率を年代別で表したものになります。
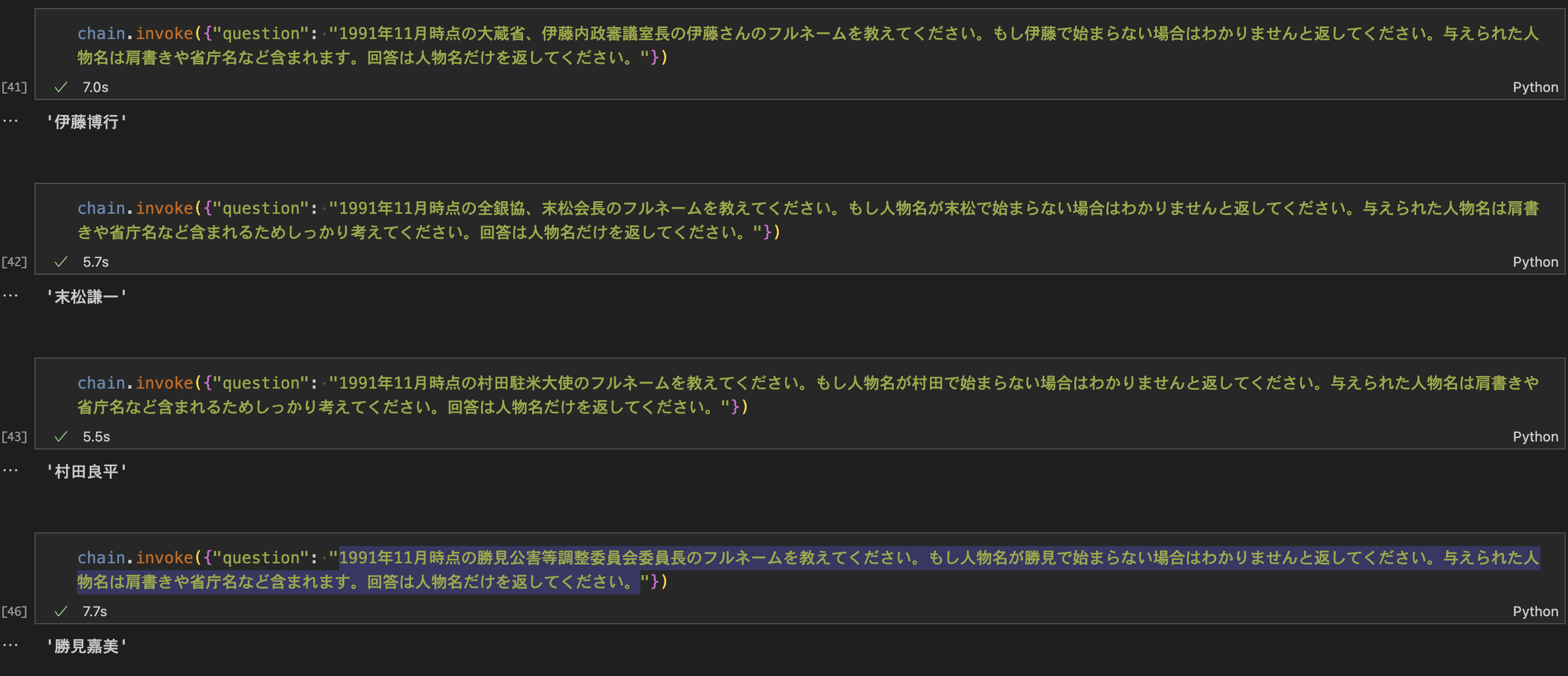
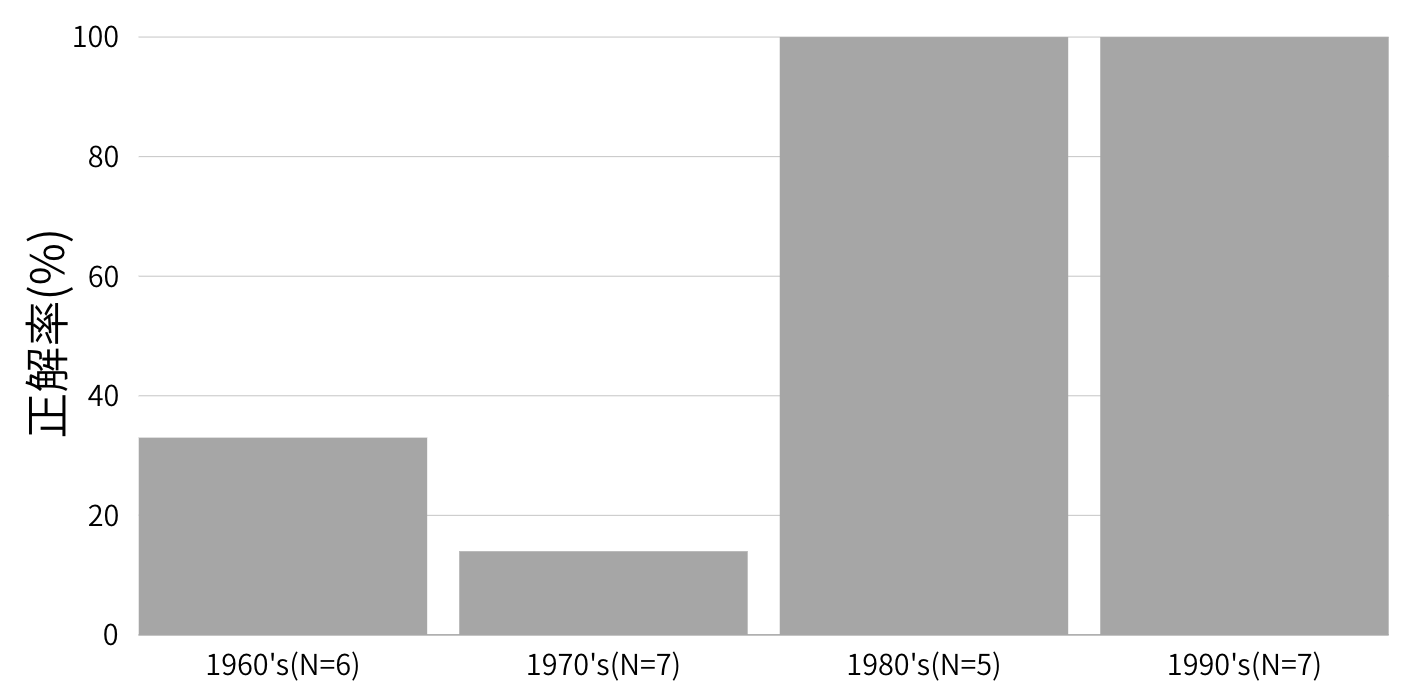
独自の評価データセットでは60年代、70年代の正解率が低い結果が得られています。サンプル数が少なく信頼性に足る結果ではありませんが、これを切り口に年代によって精度が変わっていく理由と適用可能性について深ぼっていく価値はありそうです。