今年は、NECのPC-8001が発売40周年の年だ。復刻版の「PasocomMini PC-8001」が出たりしている。このマシンには当時のN-Basicのエミュレータが搭載されていて昔のBasicのプログラムが動くそうだ。
自分がプログラミングを始めたのは、カシオのFX-502Pというプログラム電卓(1978年)を購入してからだ。この頃から、化学の領域でもプログラムを作るのが大流行りになり、様々な書籍が発行された。
工業化学のためのBASICプログラミング(1983), 実例パソコン-分子の組み立て(1984)、マイコンによる化学工学計算(1985)、Basicによる化学工学プログラミング(1985)、ASOGおよびUNIFAC-BASICによる化学工学物性の推算(1986)、パソコンによる高分子化学演習(1986)、コンピュータケミストリー材料工学編(1988)、パソコンで解く化学工学(1990) などだ。
大学生時代にPC-8801を購入し、PCによるプログラミングが化学に及ぼす影響を体感し、就職した(1985)頃、花開き始めたという事だ。こうした書籍は裁断して自炊してMacの中に保存してある。
当時の書籍には、(ほとんどが、NECの80/88/98用の)BASICプログラムが延々と記載されていた。別売りのフロッピーで購入すると5万円とか法外な値段になるので、夜な夜な打ち込んだものだった。(最初はHarddiskなど存在せず、テープにバックアップを取ったのが懐かしい)自分でソースを打ち込む=プログラムの勉強になり、それはそれで非常に良い経験をした。
こうした、コンピュータ・ケミストリーの黎明期のプログラのうち幾つかは未だに陳腐化していない。化学という学問は長い歴史があり、物理ほど理論的に扱えないので、いまだに当時のプログラムが有用だったりする。それでは、もう一度それを打ち込み直すか?というと、(退職前の身辺整理する歳になってしまった自分としては)そこまでの元気もない。たまたま、「ASOGおよびUNIFAC-BASICによる化学工学物性の推算(1986)」をお書きになった、日大の栃木先生と、その書籍のデジタル教科書版を作ろうと盛り上がったので、その時行なった、ソースコードの光学文字認識について書いておこうと思う。
自分はマシンはMacを使っているので、光学文字認識ソフトは限られる。AdobeのAcrobat proか、FineReader OCR proを使っている。FineReader OCR proはしょちゅう落ちるし、使い方に癖があるが、Acrobatより細かい設定ができるのでこちらを使う。まず、書籍からプログラムの部分だけを切り出したPDFを作る。それをFineReader OCR proで読み込む。勝手にPDFを解析して、PDFの中身を、テキスト、イメージ、テーブルに分類する。プログラムなので全部テキストにマニュアルで変更する。次にテキストの種類を指定する。
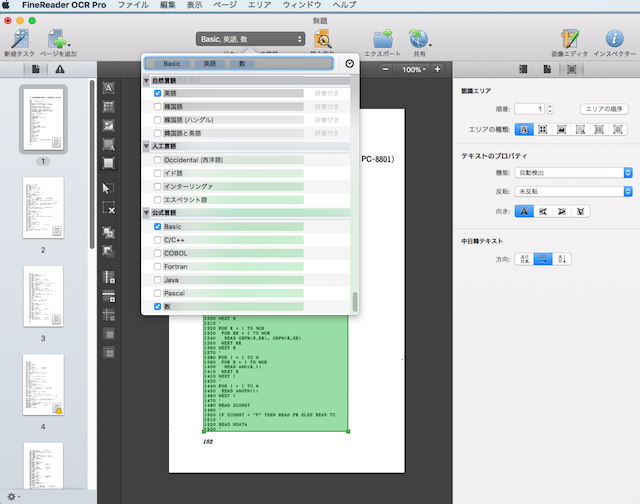
テキストに書かれているものはプログラムなので、英語、BASIC,数を指定する。実際には、プログラムの中にはprint文でカタカナも書かれているが、そこはどの道、書き直さなくてはならないので無視する。そしてページメニューから、全てのページを読み取るを選択すると、光学認識が始まる。それが終わったら、textで書き出す。
作成されたTEXTのうちMainプログラムの一部を示す。
OCRで読み込んだBasicソース例
3860 ’ -------------MAIN----------------- 3870 CLS 3880 ' 3890 IF ZCONST = ”T" THEN 3950 3900 TC = 0# 3910 FOR 1 = 1 TO N 3920 TC = TBP(I) * XL(l,I) + TC 3930 NEXT I 3940 1 3950 FOR JJ = 1 TO NDATA 3960 • VLE-P CAL 3970 IF ZCONST = "P" THEN GOSUB 4140 3980 ’ 3990 * VLE-T CAL 4000 IF ZCONST = "T” THEN GOSUB 4580 4010 ’ 4020 GOSUB 5690 4030 * 4040 NEXT JJ 4050 ' 4060 PRINT : PRINT 4070 PRINT "7*'J>*- V ->a-J'la? 7 ( Y / N ) "; 4080 ZKEY = INPUTS(1) 4090 1F ZKEY = "N" OR ZKEY = "n" THEN 4130 4100 ’ 4110 GOSUB 5890 4120 * 4130 END 4140 • .............VLE-P................ 4150 NO = 0 4160 FF = -1# 4170 ’ 4180 WHILE .000001# <= ABS(FF) 4190 ’ 4200 NO = NO ♦ 1 4210 IF 100 < NO THEN 4540 4220 ' 4230 GOSUB 4800 4240 ’ 4250 FF = -1# 4260 DFF a 0# 4270 ’ 4280 FOR I = 1 TO N 4290 VP(I) = 10# * (ANTA(I) - ANTB(I) / (ANTC(I) + TC)) 4300 YV(JJ.I) = GAM(I) * VP(I) * XL(JJ,J> / PR 4310 FF = FF + YV(JJ,I) 4320 DVP(I) = LOG(10#) * VP(I) * ANTB(I) / <(ANTC / PR 4340 NEXT I 4350 * 4360 DTC = -FF / DFF 4370 IF (ABS(DTC) <= 5#) THEN 4390Print文の中がグチャグチャなのは許すとして、かなりクオリティーの高いソースコードが得られている事がわかる。
こうしたプログラムが、復刻版の「PasocomMini PC-8001」で動くかどうか楽しみなところだ。
自分は、BASIC, C, Fortranは読めるので、それを自分の得意な言語、Java,JavaScriptに変換するのはたいした手間ではない。昔の書籍(こちらの書籍の内容もOCRで読み込み済み)と合わせてePub3にしてデジタル教科書(本文を読み、実際に化学技術計算を行う)も試しに作ってみた。
そうしたプログラム言語の移植はどのくらい自動化できるのであろうか?
f2c(FortranをC言語に変換)
j2cl(javaをjavascriptに変換)
色々ソフトはあるが、NEC独自のN-BASIC, N88-BASICを変換するプログラムは多分誰も作らないかもしれない。
マイクロソフトがGitHubを買収したことはよく知られている。マイクロソフトはなぜ買収したのか?外国の友達と話していたところ、こんな答えを聞いた。「マイクロソフトは、GitHubにあるプログラムをAIに学ばせて、Visual StudioやVSCodeでプログラムしているユーザーに、プログラミングを学んだAIがアシストする」システムを構築している。
まー、そんな時代になったら、OCRしたBASICプログラムをGitHubに置いておけば、自動的に修正して、他の言語に変換までAIがやってくれる様になるのかもしれない。化学者の自分としてはそんなありがたいことはないが、ソースコードの著作権ってこの先どうなるのだろう。
もしかしたら、Qiitaの記事も既にAIが学習していたりして!?