目次
0.結論
1.はじめに
2.FlickrAPI取得
3.スクリプトの説明
4.おわりに
0. 結論
Python(FlickrAPI)を用い、目的の検索語句にて自動画像取集が可能。
FlickrAPI取得し、本内容をコピペすることで誰でも活用可能。
▼作成したスクリプト
Get_Image_At_Flickr_For_Qiita.ipyb
1. はじめに
機械学習を進める中で一つの大きなフェーズとして、学習に用いるデータ取集があります。
AIコンペティション参加するのであれば、用意されているデータセットを使うことで、データ取集を省略できます。
しかし、自ら課題設定を行い、AI開発を進めていく場合はデータ収集を自分で行う必要があります。
今回は画像分類AI作成の前段階の画像取集について記載させていただきます。
スクリプトは大きく分けて2つのパート「FlickrAPI取得」「スクリプトの説明」に分けられますので、それぞれを紹介していきます。
なお開発環境ですがGoogle Colaboratoryを利用しています。
では、以下から作成したスクリプトについて紹介していきます。
2. FlickrAPI取得
ここではプログラム作成前処理として、今回画像取得を行うサイトのFlickrでのAPIを取得することについて記載していきたいと思います。
まずAPIとは自動車でいう車輪と思っていただいたらと思います。
何度も使うようなプログラム(自動車で言う車輪)に対して、毎回作成するのは効率が悪いため、汎用的に使用できるプログラム(API)が作成されており、無償、有償等のさまざまな提供スタイルで、企業から公開されています。
今回は画像取集を行うサイトとして、以下の写真の共有を目的として立ち上げられているFlickrを使用します。
Flickr: Find your inspiration.
以下のページからFlickrのAPIKeyを取得してください。
APIKey取得の際には以下の画像を参考にしてください。
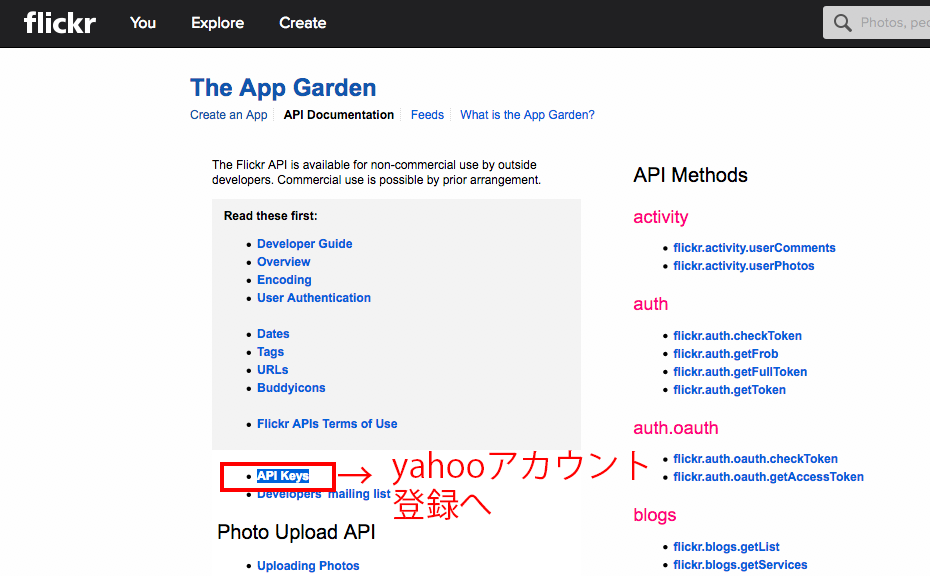
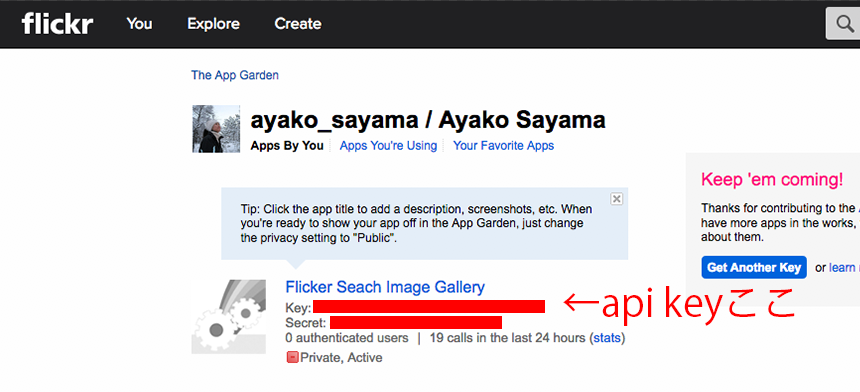
上記の操作でAPIKey取得できたと思いますので、スクリプト内容に移っていきます。
3. スクリプトの説明
ここでは、作成したスクリプトのメインの部分となるFlickrAPIを利用した画像収集について紹介していきたいと思います。
まずはFlickrAPIライブラリのインストールです。
# FlickrAPIのインストール
!pip install flickrapi
次には周辺環境ライブラリのインストールです。
#周辺環境のimport
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
from pprint import pprint
import os, time , sys
from tqdm.contrib import tenumerate
wait_time = 1
以下に前の章で取得したAPIKeyの情報を記載します。
APIKeyは登録した個人所有のものとなりますので、自分で取得したものを使用しましょう。
#FlickrAPIの情報
key = 'XXXXXX'
secret = 'XXXXXX'
flickr = FlickrAPI(key, secret, format = 'parsed-json')
以下では取得する画像の検索語句および取得枚数を記載します。
検索語句はリストに格納することで、一度の処理で複数の検索語句に対応しています。
また、pathは適切なものを設定してください。
#取得する画像の名前、保存する枚数、保存するフォルダ
names = ['banana', 'apple', 'strawberry']
get_img_num = 100
path = ''
以下の内容はAPIを利用して画像のURLを取得しています。
#取得する画像の情報を取得
def get_images_info_flickr(names, results):
for name in names:
result = flickr.photos.search(
text = name,
per_page = get_img_num,
media = 'photos',
sort = 'relevance',
safe_search = 1,
extras = 'url_q, licence'
)
results.append(result['photos'])
return results
以下の内容は取得したURLを用いて画像を保存している処理です。
#画像の保存
def save_img_flickr(path, names, results):
for name, result in zip(names, results):
print(f'{name}の保存')
for i, photo in tenumerate(result['photo']):
url_q = photo['url_q']
img_path = path + name + '_' + str(i) + '.jpg'
urlretrieve(url_q, img_path)
time.sleep(wait_time)
以下にて、上記の作成した2つの関数を用いた画像処理処理を記載しています。
#実行関数
def main():
results = []
results = get_images_info_flickr(names, results)
save_img_flickr(path, names, results)
以下にて実際に画像取集処理を実行しています。
#実行するぞ
main()
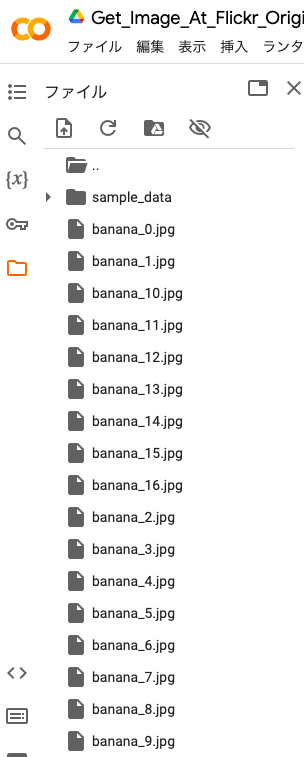
上記を実行するとColab上のフォルダに以下のように画像が保存されます。
4. おわりに
初めてAPIによる画像取集を開発してみましたが、自分の思った通りの動作ができてよかったです。
ぜひ、本スクリプトを活用し、良い画像取集生活を!
長い文章を最後までお読みいただき、ありがとうございました!!