はじめに
主に、機械学習をやろうと思い、google colab からまずは始めてみよう、と思った人向けに、ちょっとした tips や例題を紹介しておきたい。著者は宇宙天文分野なので、少し宇宙寄りな tips も書き留めておきます。
宇宙天文学に限らないと思いますが、特に最近は機械学習を捉えるときに、deep な neural net だけ知っていれば良い場合はほとんどなく、古典的なデータ解析や基礎的な手法から現状の機械学習の限界まで幅広く見渡せる視野の広さが大切になってきてる気がします。
その意味で、基礎技術(この記事はtensorflowの基礎に終始しますが基礎も大切という意味)の習得も大事にしつつ、高い視点、遠い未来を想像できる力もつけておくとよいはずです。
(2025.5.30. その時点で google colab のコードがエラーなく動くように改修)
参考資料とか
特筆して紹介するまでもないとは思いますが、
物理と機械学習の関係については、「ディープラーニングと物理学 オンライン」 (オンラインWeb会議システムを利用したセミナー)の内容は勉強によいかと思います。
オンラインコンテンツは山ほどありますが、逆にありすぎて何が良いのか迷うでしょう。下記とか入るといいのかな。
あるいは、コードを動かながら理解したいという人は、scikit-learn に一通りのライブラリは揃ってるので、
で遊びながらまずは動かしてみる、というのもよいかもしれません。
にまとまった記事が出てます。
もっと基本的な話などは、下記の記事に書いています。
google colab でやる機械学習の例
全結合ネットワークで MNIST をつかった google colab 上のサンプルです。いくつかのポイントをこれを使って説明していきます。データを見る、データを保存する、などそういう基本的なところや、なんとなく使ってる(場合がある)部分の確認です。最近は、tensorflow or pytorch の2択になりつつありますが、ここでは初学者向けのtensorflowの例を紹介します。pytorchの方が自由度が高く、玄人向け、という感じです。
MNISTの簡単なコード
サンプルコードを、
においてます。コードを見ればわかる人はOKで、下記はいくつか特だしした説明になります。
(1) tensorflow と CUDA のバージョンを確認する
「動くはずなのに、動かない!!」という場合、ほとんどが tensorflow or CUDAのバージョン不整合なことが多いです。まずは、自分の使ってる tensorflow のバージョンを確認します。
print("tensorflow :", tf.__version__)
tensorflow : 2.8.0
2022年4月のgoogle colabのデフォルトでは、tensorflow の 2.8.0 が入っています。もし、別のバージョンで動かしたければ、uninstall して、適当なversionを install します。
次に、CUDAのバージョンを確認します。
# check GPU and CUDA Version
!nvidia-smi
Thu Apr 7 00:46:59 2022
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
....
CUDA の Version が 11.2 であることが確認できます。
2025.5.29の実行時
- tensorflow : 2.18.0
- CUDA : NVIDIA-SMI 550.54.15
- Driver Version: 550.54.15
- CUDA Version: 12.4
これは、それほど変える必要はないと思います。
手前味噌で恐縮ですが、もし、自前の解析マシン(ubuntu20.04)にCUDAなどをインストールする場合は、
に記事を書いております。
(2) 作業ディレクトリを作成して、移動しましょう。
google colab の作業スペースはなくて、自分の google drive 上で動かします。そうすることで、google drive 上に結果を保存することができます。
# create and change directories to match your environment
rundir="/content/drive/MyDrive/Qiita/機械学習練習/keras_MNIST_NN"
!ls $rundir
%cd $rundir
の部分で、rundir は自分の環境に合うように書き換えてください。 ! と % から始まるのは、google colab のお約束で、google colab の使い方については、
など参考にしてください。
(3) ログが残る設定をしておきましょう。
ModelCheckpoint という関数を用いて、モデルを保存する設定をします。save_best_only = True とすることで、モデルが改善したときだけ保存する設定になります。
checkpoint = ModelCheckpoint(
filepath=os.path.join(MODEL_DIR, "model-{epoch:04d}.h5"), save_best_only=True)
CSV_FILE = "trainlog.csv"
CSV_FILE_PATH = MODEL_DIR + "/" + CSV_FILE
で、トレーニング曲線を保存する csv ファイルも設定しておきましょう。
(4) データを準備します。
ここでは、MNISTを用いるので、単に、
(Xtrain, ytrain), (Xtest, ytest) = mnist.load_data()
とするだけでデータが取得できます。(一般論としては、このようなデータを用意する、作成する、適切な前処理を施す、という部分が、機械学習と同等かそれ以上に大事な部分になります。)
(5) モデルを作成します
tensorflow には、モデルを作成するための、大きくは2つの方法があります。
- Sequential API
- Funtional API
があります。Functional API を用いた方が汎用性が高いので、そちらを使った例を示してますが、コメントアウトを外せば、sequential model が動きます。
玄人になると、
- カスタム定義 (自分でレイヤやモデルを作成する)
が必要になるかもしれません。カスタム Layer や Model の作り方はこの記事では紹介しませんが、
などをご参照ください。
# # モデル (方法1) sequential model using tensorflow 簡単だが汎用性が低い。
# model = tf.keras.models.Sequential([
# # (None, 28, 28) -> (None, 784)
# tf.keras.layers.Flatten(input_shape=(28, 28), name='input'),
# # Layer1: Linear mapping: (None, 784) -> (None, 512)
# tf.keras.layers.Dense(512, name='fc_1'),
# # Activation function: ReLU
# tf.keras.layers.Activation(tf.nn.relu, name='relu_1'),
# # Layer2: Linear mapping: (None, 512) -> (None, 256)
# tf.keras.layers.Dense(256, name='fc_2'),
# # Activation function: ReLU
# tf.keras.layers.Activation(tf.nn.relu, name='relu_2'),
# # Layer3: Linear mapping: (None, 256) -> (None, 10)
# tf.keras.layers.Dense(10, name='dense_3'),
# # Activation function: Softmax
# tf.keras.layers.Activation(tf.nn.softmax, name='softmax')
# ])
# モデル (方法2) Functional API using keras 汎用性が高い
inputs = tf.keras.layers.Input(shape=(28, 28))
x = tf.keras.layers.Flatten()(inputs)
x = tf.keras.layers.Dense(512, activation='relu')(x)
x = tf.keras.layers.Dense(256, activation='relu')(x)
predictions = tf.keras.layers.Dense(10, activation='softmax')(x)
model = tf.keras.Model(inputs=inputs, outputs=predictions)
はじめのうちはモデルを作成したら、モデルを必ずプロットしましょう。
(方法2では、変数xを使ってますが、これは何でも構いません。同じxを使いまわすことで、1行だけコピペすることで層を増やせるとか、そういう小さな実用上の理由です。)
# plot model
tf.keras.utils.plot_model(model, show_shapes=True, expand_nested=True, show_dtype=True, to_file="model.png")
とするだけです。

と表示されるはずです。
(6) 活性化関数の確認
活性化関数が適切かどうかのチェックをしましょう。今では活性化関数の種類は調べると山ほどあって、逆に覚えなくても良いのか?と思う人もいるかもしれないが、意味を理解して、適切に選択できなければ、機械学習はできません。
まずは、下記の4つの概念をおさえておくとよいです。
- sigmoid 関数
- 出力が 0 から 1
- 入力が -2 から 2 で値が変化する
- 確率変数として使うと素性が良い
- tanh 関数
- sigmoidの兄弟のようなもの、ただし、出力が -1 から 1 となる
- ReLU 関数
- 出力が 0 から +無限大
- 入力が負なら 0、正ならそのあたいそのまま
- sigmoid or tanh と異なり、入力値に範囲に依存しない (逆に言うと、sigmoid, tanh は出力が大きすぎると、値が全然変わらないので注意が必要ということ。)
- Softmax 関数
- 多入力を確率変数の多出力に変換
- 値を指数関数の肩に取るので、全て正に変換(=確率変数として扱いやすく変換)
- 統計力学のように分母は全部の指数関数の和、分子は該当する入力のみ(=確率)
の4つの種類と特徴だけは暗記しておくとよいです。
山ほどの例はこちらなど。
(7) 学習とコールバックの設定
最適化に用いる方法(optimizer)と最小化する数(loss)を指定します。
metris は最適化には使われない数字で、ついでに計算する数のリストだと思えば良いです。
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Set callback functions which are called during model training
callbacks = []
callbacks.append(tf.keras.callbacks.CSVLogger(CSV_FILE_PATH))
callbacks.append(checkpoint)
history = model.fit(Xtrain, Ytrain,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(Xtest, Ytest),
callbacks=callbacks)
model.save(modelname)
callbackは、model.fit 時に与えます。
バッチサイズはとても重要です。
batch_size
Integer or None. Number of samples per batch of computation. If unspecified, batch_size will default to 32. Do not specify the batch_size if your data is in the form of a dataset, generators, or keras.utils.Sequence instances (since they generate batches)
とありますように、デフォルトでは32になってます。ただし、これが最適かどうかは問題に強く依存するので、自分の問題の規模感と照らし合わせて考えます。
計算ログの最初の数行をちゃんと見ましょう!
Total params: 439,728
Trainable params: 439,728
Non-trainable params: 0
Epoch 1/50
235/235 [=..=] - 2s 7ms/step - loss: 0.2245 - val_loss: 0.1537
Epoch 2/50
235/235 [=..=] - 1s 6ms/step - loss: 0.1379 - val_loss: 0.1251
計算時のログからは、
- 全パラメータ数を確認する(パラメータ数自体はモデル生成時に確認できます。いろいろとモデルを変える場合などもあるので、実行時に自分が意図したモデルかどうかを確認するためにもちゃんとみましょう、という意味です)。自分の想定したパラメータの数であるのかどうか。なければ何かモデルの生成でコケている可能性がある。
- loss, val_loss が下がっているか。全く val, val_loss が下がってない場合は、入力のパラメータやモデルか何かがおかしい場合が多い。
を確認しましょう。数万パラメータもある最適化問題で、全くlossが下がらない、というのは普通の問題ではないはずで、多少でもlossは下がるはずですので。
(8) 学習曲線をプロットします。
df = pd.read_csv(CSV_FILE_PATH)
で学習曲線を取得してプロットして確認します。これをサボることはほとんどないです。
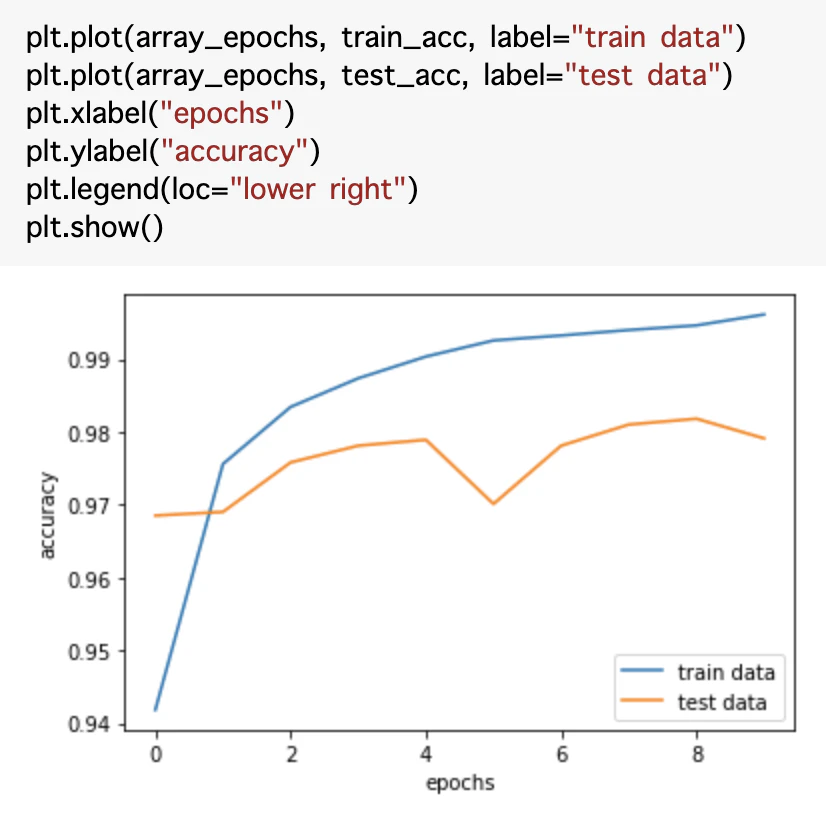
性能が良いのか、まだ改善するのか、過学習が起きてるのかななど、様々な情報は学習曲線から読み取れます。epoch 数を長くして、学習曲線がどういう挙動をするか見るのも大切な確認方法の一つです。
ここでは用いてませんが、dropout を使うと、training と test で用いているネットワークが異なるので、予想した挙動にならないことがあります。
など、色んな解説記事があります。
(9) モデルの評価
保存したモデルを読み込みます。
model = tf.keras.models.load_model(modelname)
で学習した、best なモデルを読み込みます。
その上で、
predict_x=model.predict(Xtest)
として、test データを入れて、予測値を取得します。 ここで、もし間違えて training データをいれてしまうと、過学習していたときは特にものすごい性能がでていると勘違いしてしまいますので、test データで評価していることを確認してください。
train_loss, train_acc, *is_anything_else_being_returned_1 = model.evaluate(Xtrain, Ytrain, verbose=1)
として、loss, accuracy を取得して、その他の評価値は *is_anything_else_being_returned_1 などの適当な可変長の配列に入れています。
model.evaluate としたの時に何が返ってくるかは、
model.metrics_names # what model.evaluate(Xtrain, Ytrain, verbose=1) will return.
['loss', 'accuracy', 'mse']
とすればわかります。 「model.predict は入力から出力を得る」ためのもので、 「model.evaluate は、評価のためのメトリックを計算する」ためのものになりますので、使い分けましょう。
accuracy とは??
とあるように、"acc" や、"accuracy" とした時は、分類問題の正答率を返す。
def categorical_accuracy(y_true, y_pred):
'''Calculates the mean accuracy rate across all predictions for
multiclass classification problems.
'''
return K.mean(K.equal(K.argmax(y_true, axis=-1),
K.argmax(y_pred, axis=-1)))
である。
確認事項として、学習がイマイチ、という時に、metrics=['accuracy'] を変えても効果はありません。model.fit しているのは, loss の最小化であって、metrics は合い具合の指標を計算しているだけなので、学習が改善することはないです。
(10) モデルを多角的に評価
最後、一番大事なので、モデルを MAE, MSE などの一点のスカラー量だけで評価しただけで終わりにしないことです。単純な指標を足がかりにして、データをいろんな角度から見ることで、どの部分で学習が進まないのか、データの前処理や、活性化関数、バッチサイズなど、何がよくないのか、判断の材料が得られることがあります。人の話を静かに聞くのも大切なように、データを地道に観察するのが大切です。
AEとVAEの簡単なコード
最後、MNISTの次のステップの例だけ紹介しておきます。
AE(Auto Encorder)とVAE(Variational Auto Encorder)は、生成モデルや、異常検知などの基本となる型になります。
2025.5.30 VAEの方は今風にコードを改変。精度が下がったかもしれない。(向上させる方法がわかる方は教えてください。)
その時点で、

くらいのレベルです。
ただし、VAE以前に、主成分分析(PCA)などもっと基本的な手法を知らない人はまずはそちらの知識をいれておくことを強くお勧めします。問題が、線形で解析的に解けるのであれば、主成分分析で十分な場合も多いですし、まずはPCAで問題を眺めてみる、というのも大切なデータの見方になります。
などご参考ください。
まとめ
簡単に google Colab で機械学習を始める人向けのメモを作成しました。日進月歩でコーディングルールなどは変わるので、動かない場合は生成系AIさんに聞いてもらえれば解決できると思います。
関連記事