■ 経緯
簡単にデスクトップで起動するOCRアプリを作れないかと考え、作ってみました。
■ 環境
・MacOS Catalina 10.15.4
・Visual Studio Code
・Python3.8.1
■ ライブラリのインストール
1.PysimpleGUI(GUIの作成)
pip install pysimplegui
2. Tesseract OCR(OCR)
brew install tesseract
3. pyocr(Python用のOCRツールラッパー)
sudo pip3 install pyocr
4.pillow(画像の読み込み)
sudo pip3 install pillow
● これらのライブラリって何なの?ということも含めて、OCRについては以下のサイトを大いに参考にさせていただきました(感謝)。
Tesseract+PyOCRで簡易OCRを試してみる
● Windowsの方はこちらがわかりやすいかも。
【Python】画像から文字起こししてテキストに変換する方法(tesseract-OCR、pyocr)
では、画像から文字を読み取るコードをどのように書いていくか、見てみましょう(ライブラリのインポートは、最後の全体のソースコードに載せているので、ここでは省略させていただきます)。
def scan_file_to_str(file_path, langage):
"""read_file_to_str
画像ファイルから文字列を生成する
Args:
file_path(str): 読み取るファイルのパス
langage(str): 'jpn' または 'eng'
Returns:
読み取った文字列
"""
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
text = tool.image_to_string(
# 引数で送られてきたファイルを開く
Image.open(file_path),
# 引数で送られてきた言語を指定する('jpn' または 'eng')
lang=langage,
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
# 最後に画像から読み取った文字列を返す
return text
わずか15行程度て画像から文字列を読み取れてしまうなんて、本当驚きですよね。感動しました。
では次に、これをGUIに載せていきます。PythonのGUIというとtkinterが有名かと思います。僕もはじめはtkinterを使ってコードを書いていましたが、その調べものをしているときに次の記事に出会いました。
Tkinterを使うのであればPySimpleGUIを使ってみたらという話
簡潔なコードでGUIが実装できてしまうことにまた感動し、こちらを使っていくことにしました。
GUIの部分のコードはこちらです。
# テーマを設定(テーマはたくさんあります)
sg.theme('Light Grey1')
# どこに何を配置するのか(行単位で配置する、ということが分かると組み立てやすいかと思います)
layout = [
# 1行目(Text:テキストを置く)
[sg.Text('読み取るファイル(複数選択可)', font=('IPAゴシック', 16))],
# 2行目(InputText:テキストボックス, FilesBrowse:ファイルダイアログ)
[sg.InputText(font=('IPAゴシック', 14), size=(70, 10),), sg.FilesBrowse('ファイルを選択', key='-FILES-'),],
# 3行目(Text:テキスト, Radio:ラジオボタン × 2)
[sg.Text('読み取る言語', font=('IPAゴシック', 16)),
sg.Radio('日本語', 1, key='-jpn-', font=('IPAゴシック', 10)),
sg.Radio('英語', 1, key='-eng-', font=('IPAゴシック', 10))],
# 4行目(Button:ボタン)
[sg.Button('読み取り実行'),],
# 5行目(MLine:100列×30行のtextarea)
[sg.MLine(font=('IPAゴシック', 14), size=(100,30), key='-OUTPUT-'),]
]
# ウィンドウを取得(Windowの引数は、「タイトル、レイアウト」)
window = sg.Window('簡単OCR', layout)
# 読み取ったファイルを入れるリスト
files = []
# ここで無限ループを回し、ボタンクリックなどのイベントを待ちます。
while True:
event, values = window.read()
# Noneはウィンドウの「✕」ボタン。これが押されたらループを抜け、ウィンドウを閉じる。
if event == None:
break
# '読み取り実行' のボタンが押されたとき
if event == '読み取り実行':
# key='-FILES-'で指定したInputTextの値を';'で区切り、ファイル名のリストを得る
files.extend(values['-FILES-'].split(';'))
# ラジオボタンが values['-jpn-'] なら language は 'jpn'、そうでなければ 'eng'
language = 'jpn' if values['-jpn-'] else 'eng'
text = ''
# ファイルの数だけループする
for i in range(len(files)):
if not i == 0:
# ファイルごとに区切りを入れている
text += '================================================================================================\n'
# ここで先ほど定義したscan_file_to_strメソッドで、読み取った文字列を受け取る
text += scan_file_to_str(files[i], language)
if language == 'jpn':
# 日本語の文字列の場合、余分なスペースが多かったため、それを消す処理をした
text = text.replace(' ', '')
# 次のファイルの文字列とは2行あけておく
text += '\n\n'
# 読み取ったデータ(=text)をkey='-OUTPUT-'で指定したMLineに表示させる
window.FindElement('-OUTPUT-').Update(text)
# ポップアップウィンドウで終了を知らせる
sg.Popup('完了しました')
window.close()
GUIに関してはほかにもいくつか大いに参考にさせていただいたものがありますので、掲載します
・K-TechLaboゼミ用学習ノート
→ PDFのテキストがとても分かりやすい。
・PySimpleGUIでVBAの代わりになるUIをつくってみる(ファイルダイアログ、リスト、ログの出力)
→ 先ほど紹介した記事と同じ方が書かれています。こちらからも学ばせていただきました。
■ ソースコード(完成)
import os
import sys
from PIL import Image
import PySimpleGUI as sg
import pyocr
import pyocr.builders
def scan_file_to_str(file_path, langage):
"""read_file_to_str
画像ファイルから文字列を生成する
Args:
file_path(str): 読み取るファイルのパス
langage(str): 'jpn' または 'eng'
Returns:
読み取った文字列
"""
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
text = tool.image_to_string(
Image.open(file_path),
lang=langage,
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
return text
# テーマを設定
sg.theme('Light Grey1')
layout = [
# 1行目
[sg.Text('読み取るファイル(複数選択可)', font=('IPAゴシック', 16))],
# 2行目
[sg.InputText(font=('IPAゴシック', 14), size=(70, 10),), sg.FilesBrowse('ファイルを選択', key='-FILES-'),],
# 3行目
[sg.Text('読み取る言語', font=('IPAゴシック', 16)),
sg.Radio('日本語', 1, key='-jpn-', font=('IPAゴシック', 10)),
sg.Radio('英語', 1, key='-eng-', font=('IPAゴシック', 10))],
# 4行目
[sg.Button('読み取り実行'),],
# 5行目
[sg.MLine(font=('IPAゴシック', 14), size=(100,30), key='-OUTPUT-'),]
]
# ウィンドウを取得
window = sg.Window('簡単OCR', layout)
files = []
a = 0
while True:
event, values = window.read()
if event == None:
break
if event == '読み取り実行':
files.extend(values['-FILES-'].split(';'))
language = 'jpn' if values['-jpn-'] else 'eng'
text = ''
for i in range(len(files)):
if not i == 0:
text += '================================================================================================\n'
text += scan_file_to_str(files[i], language)
if language == 'jpn':
text = text.replace(' ', '')
text += '\n\n'
window.FindElement('-OUTPUT-').Update(text)
sg.Popup('完了しました')
window.close()

2枚の画像を読み取らせてみる
【英語1枚目(The White House Buildingより)】

【英語2枚目】

☟
【結果】
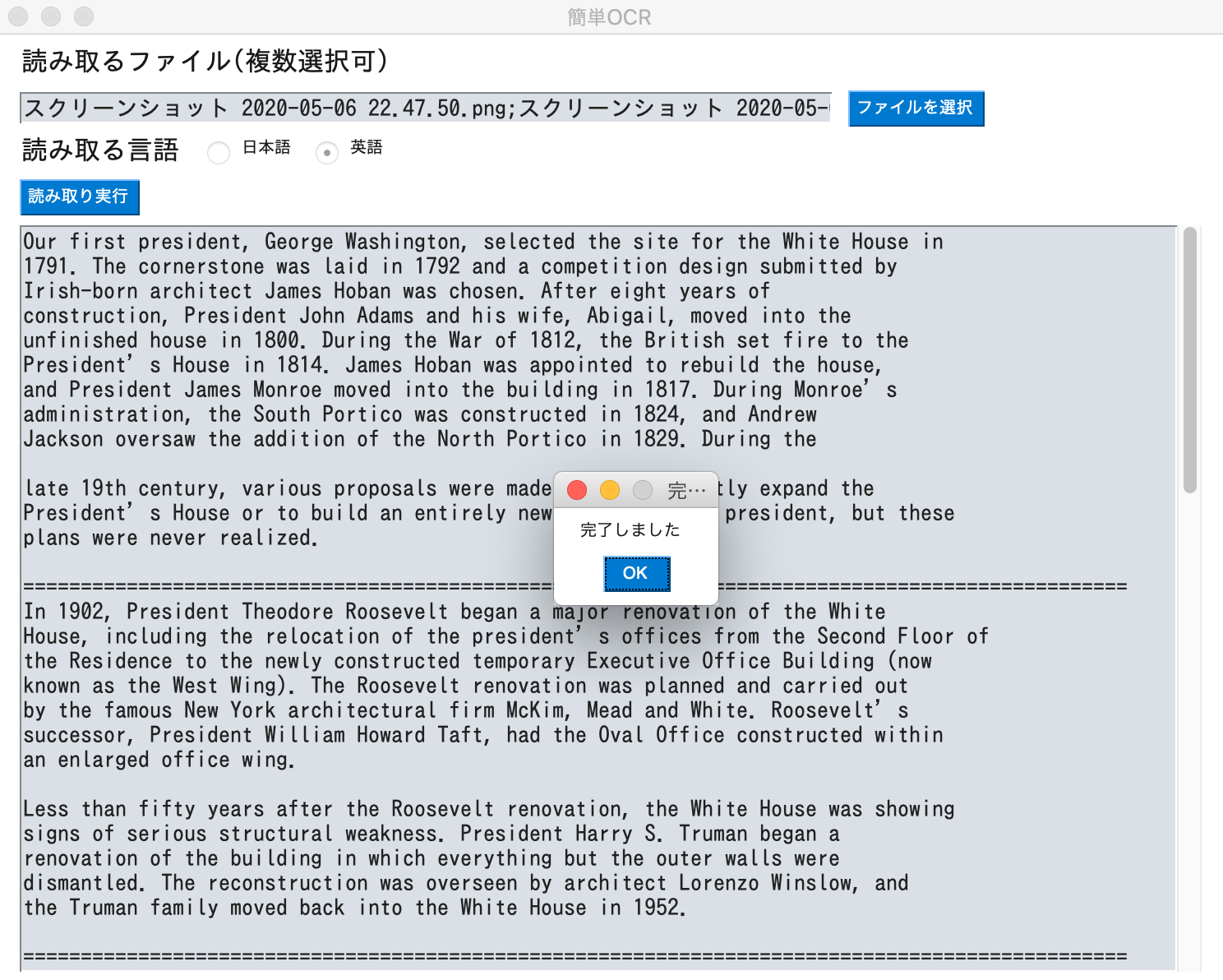
英語は読み取りが早く、かつ精度もかなり高いのではないでしょうか。
【日本語(青空文庫より)】

☟
【結果】
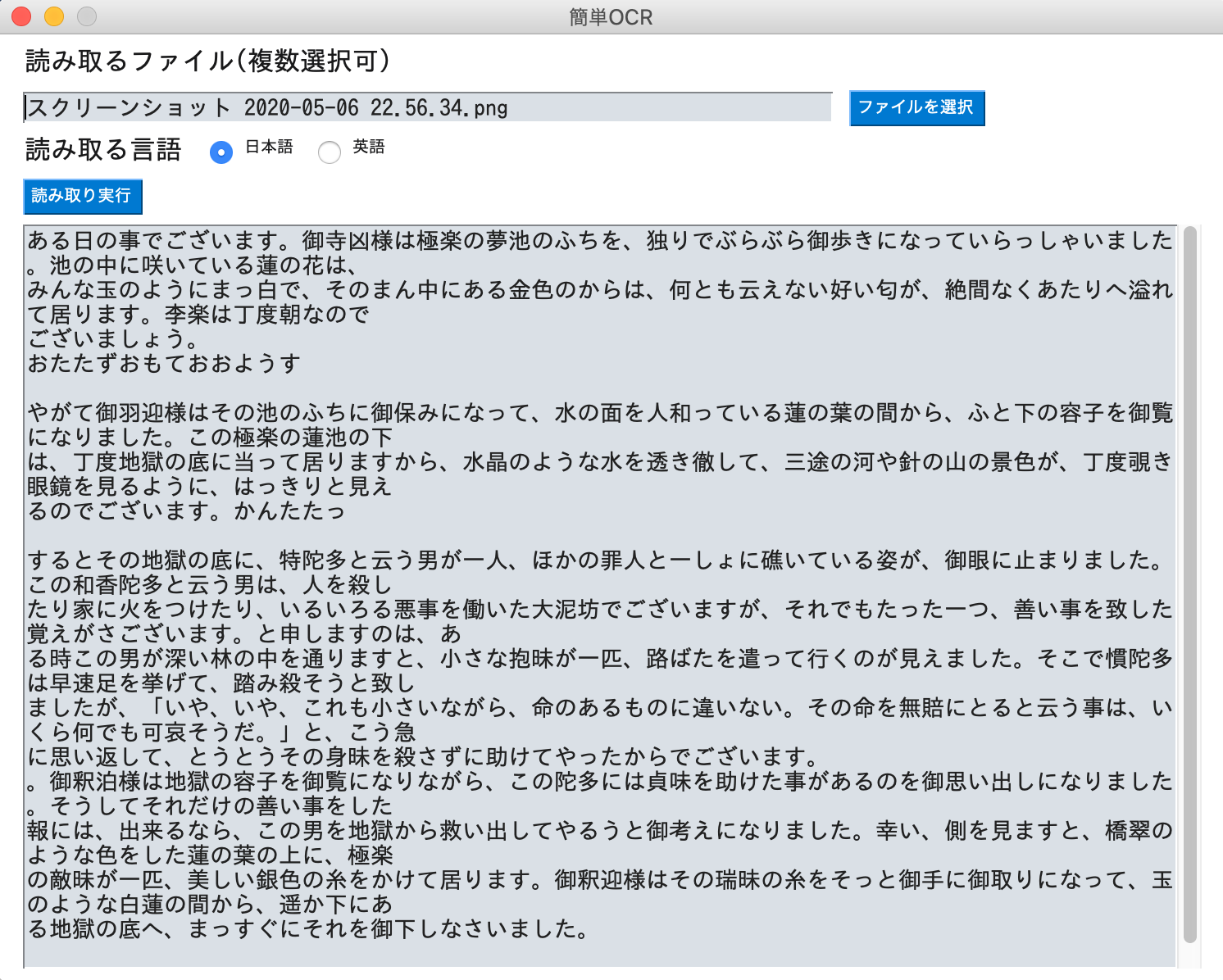
日本語は時間がかかります。それでも、精度はまあなんとか使えそうなレベルです。
■ 最後に
本当はこのアプリを実行可能ファイルとして、MacやWindowsのデスクトップ上で動作するものにしたかったのですが、pyinstallerもpy2appもうまく行かず、一旦この状態で記事にすることとしました。もし今後それができたら、更新していきます。
また、「ここ違うんじゃない?」とか「ここは、こういうやり方もあるよ」といったご指摘、ご意見、ご提案などありましたらお気軽にコメント欄にお書きください。