今回は「Tesseract OCR」と「PyOCR」を使用して、OCR(光学的文字認識)を試してみました。
Tesseract OCRとは
「Tesseract OCR」はGoogle、HPが開発したオープンソースOCRエンジン。
Unicode(UTF-8)をサポートしており、100以上の言語を「そのまま」認識できます。
PyOCRとは
「PyOCR」はPython用のOCRツールラッパー。
PythonプログラムからさまざまなOCRツールを使用できます。
現在サポートされているOCRツールは以下の3種類。
- Libtesseract
- Tesseract
- Cuneiform
環境構築
※実行環境はMacOSです。
1. Tesseract OCR
①Tesseractのインストール
Homebrewの場合brew install tesseractで終了です。
②学習データの準備
https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
上記リンクから訓練データをDLし、以下に格納します。
/usr/local/Cellar/tesseract/[tesseractのバージョン]/share/tessdata
バージョン4.0.0からは速度重視の「tessdata_fast」精度重視の「tessdata_best」が選べます。
本記事では通常の訓練データ「tessdata」を使用します。
※他環境の場合は以下を参照してください。
https://github.com/tesseract-ocr/tesseract/wiki
2. PyOCR
①PyOCRのインストール
以下のコマンドを実行するだけです。
sudo pip3 install pyocr
以上で環境構築は終了です。簡単ですね。
実行してみる
こちらのサンプルを実行します。(※少しいじっています。)
from PIL import Image
import sys
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
txt = tool.image_to_string(
Image.open("[ファイル名]"),
lang="jpn",
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print( txt )
①Wikipedia
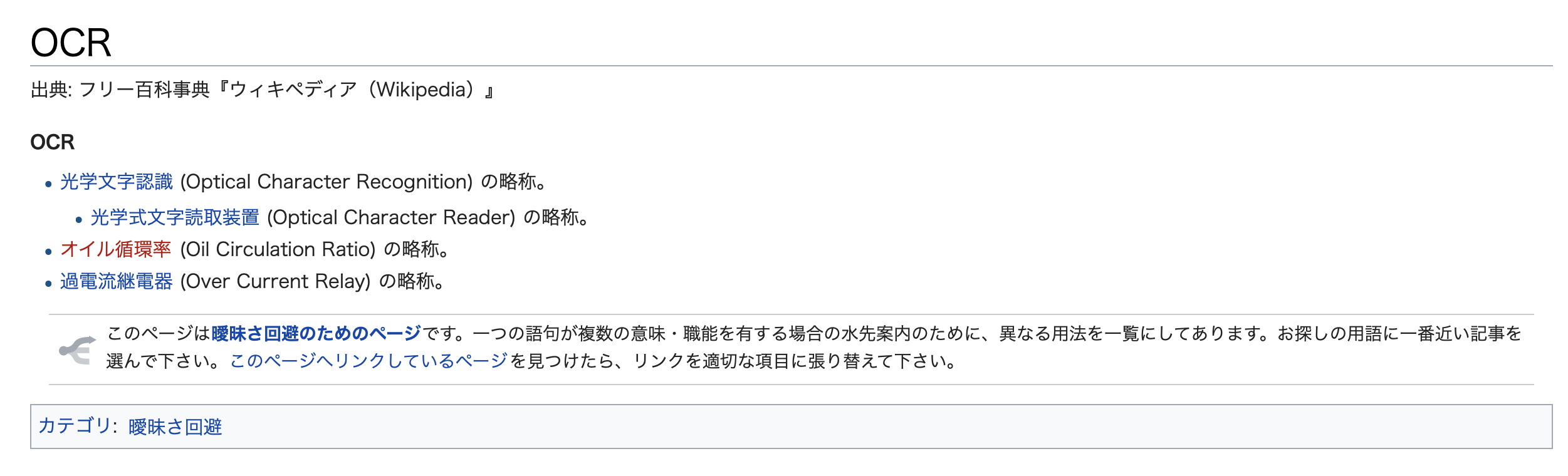
出 典 : フ リ ー 百 科 事 典 『 ウ ィ キ ペ デ ィ ア (Wikipedia) 』
OCR
・ 光 学 文 字 認 識 (Optical Character Recognition) の 略 称 。
・ 光 学 式 文 字 読 取 装 置 (Optical Character Reader) の 略 称 。
・ オ イ ル 循 環 率 (Oil Circulation Ratio) の 略 称 。
・ 過 電 流 継 電 器 (Over Current Relay) の 略 称 。
こ の ペ ー ジ は 曖 昧 さ 回 避 の た め の ペ ー ジ で す 。 一 つ の 語 句 が 複 数 の 意 味 ・ 職 能 を 有 す る 場 合 の 水 先 案 内 の た め に 、 異 な る 用 法 を 一 覧 に し て あ り ま す 。 お 探 し の 用 語 に 一 番 近 い 記 事 を
選 ん で 下 さ い 。 こ の ペ ー ジ ヘ リ ン ク し て い る ペ ー ジ を 見 つ け た ら 、 リ ン ク を 適 切 な 項 目 に 張 り 替 え て 下 さ い 。
カ テ ゴ リ : 暖 昧 さ 回 避
タイトルの「OCR」は読み取れませんでしたがほぼ完璧ですね。
②Yahooニュース
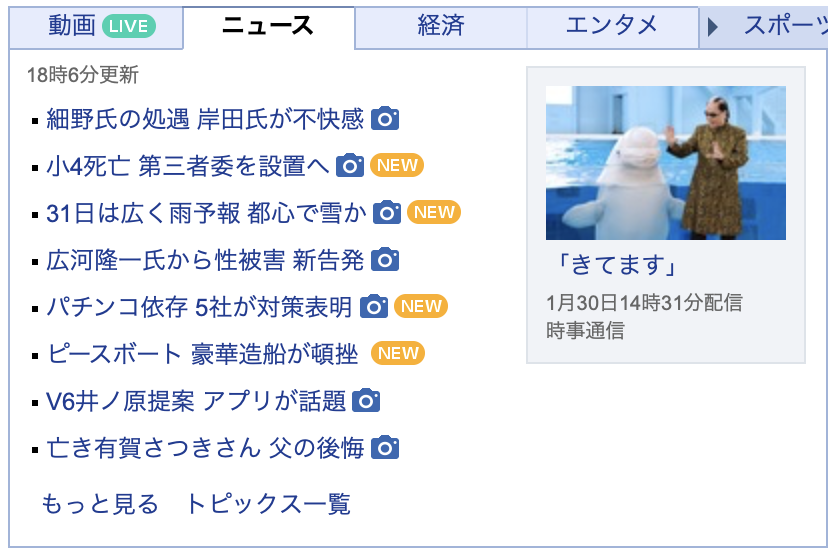
ニ ュ ー ス | 細 津 _ エ ン タ メ レ ス ポ ー
①⑧ 時 ⑥ 分 更 新
・ 細 野 氏 の 処 遇 岸 田 氏 が 不 快 感 國 四 謬 璽以′ 和
・ 小 ④ 死 亡 第 三 者 委 を 設 置 へ 団 E ⑤ ョ ~ 。
・③① 日 は 広 く 雨 予 報 都 心 で 雪 か 団 G ド 】
・ 広 河 隆 一 氏 か ら 性 袖 害 新 告 発 國 ` き て ま す 」
・ パ チ ン コ 依 存 ⑤ 社 が 対 策 表 明 団 (TE 雷睾豊冑4時鵠分配信
・ ピ ー ス ポ ー ト 豪 華 造 船 が 頓 挫 ⑪
・ VG 井 ノ 原 提 案 ア プ リ が 話 題 団
・ 亡 き 有 賀 さ つ き さ ん 父 の 後 悔 國
も っ と 見 る ト ピ ッ ク ス 一 覧
数字が◯で囲まれてます。(仕様っぽいですが)
また、カメラの絵文字なども文字と誤認識されています。
③写真から読み取る

ョ の ス キ ト
辻 点 花 付
紅 余 化 伝
RO 〇 YAL 〟
M ま EL K T イ EA
0 :鯱翼 ① ダ
ロ イ ヤ ル ミ ル ク デ ー 一 ー
繁 勇 表 示 (①00ml 当 た り ノ
① げ ー③⑥kcaL た ん ば く < 質 0Gg、 胆 賀
為 航 化 物 ⑥.⑥⑧ 食 報 柑 き 見 0
② ` 沈 殿 し た り 固 ま っ た り す る `
⑳ 謬 あ り ま せ ん 。g r 声 け て く だ さ い 映 種 城 捨 畜
S 格 a
`幟鱒鱒州 ′~
A ①
流石に精度は落ちたでしょうか…
わかりにくいので、画像のどこを文字として認識しているかを確認してみます。
おまけ(WordBox)
単語と認識されたエリアをボックスで返してくれるので、OpenCVで矩形を描画します。
コードは以下の記事を参考にさせていただきました。
Pythonで日本語OCRを行うときのメモ
import pyocr
import pyocr.builders
import cv2
from PIL import Image
import sys
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
res = tool.image_to_string(Image.open("[ファイル名]"),
lang="jpn",
builder=pyocr.builders.WordBoxBuilder(tesseract_layout=6))
out = cv2.imread("[ファイル名]")
for d in res:
print(d.content)
print(d.position)
cv2.rectangle(out_resize, d.position[0], d.position[1], (0, 0, 255), 2)
cv2.imshow("img",out)
cv2.waitKey(0)
cv2.destroyAllWindows()

模様や文字列を一つの文字として誤認識してしまっているようです。
このように、Tesseract OCR(の訓練データ)は文字の傾きや歪みに弱いです。
模様などの誤認識も多いため実用にあたっては色々と制限をかける必要がありそうですね。
ただオープンソースとしては破格の精度なので、是非試してみてくださいね!