聞いた話あれこれ
Web サイト運用関連の仕事をしていると、サイトの情報まとめレポート作成や、サイト分析を頼まれることがあります。大規模サイトであれば CMS で管理されていたり、統計ツールが導入されていることが多いですが…
中規模以下のサイトでは、いまだに「今サイトに何ページ公開されているか」がはっきりわからないサイトの管理者も多いのです。また仕組みがしっかりしている大規模サイトでも、権限設定の関係で最新の情報へのアクセスに苦労している場合もあるようです。
今まで耳にした中で、わりと悲惨なパターンは…
統計システムから毎月、ちゃんとしたアクセスレポートが得られるんだけど… URL とアクセス統計だけで、ページタイトルがないから詳細わからなくて、毎回、上位のページはタイトルなど手動で調べて、資料作成しているので辛い…
また新規に Web サイト管理を見積もる場合、ちゃんとした情報が貰えず、いきなり URL だけ送られてきて「このサイト、月幾らで運用頼める?」なんて言われる場合もある、という都市伝説もありますw
※ これら全て聞いた話です、ええ全て。そういう事にしといてください…
Web クローラー
こんな時に役立つのが、Web クローラー です。Web サイトにアクセスして、いろいろな情報を集めてくれるツール。意外と簡単に作成できますので、幾つかのパターンを用意しておけば、ちょろっと修正して、クイックに解決できることが、わりとあります。
また汎用ツールと違って、自作の簡易ツールであれば、コード修正で柔軟な対応が可能です。毎月のレポートで作業が決まっているのであれば、ツールに組み込んで自動化しちゃえばいいのです。
そしてなにより、開発者たるもの、単純な手作業は無理やりでも自動化していく!手作業の時間も開発の時間に変えてしまう!そちらのほうが、楽しいし、知識が身につきますよね。
今回は Node.js 環境で動作する、簡単な Web クローラー作成の様子をまとめてみました。この手の作業をするにはライブラリが充実していますし、JavaScript ベースでロジックを記載できるので、個人的にはすごくお勧めの開発環境です。
今回のコードの方針
まあ今回に限らない気がしますが、こういった簡易的な、対象が狭いもしくは使い捨てに近いツールを作成する場合の方針はこんな感じです。
- 少し冗長でもシンプルな処理のコード
- 対象に固有の値は const 変数にいったんセット
- パーツごとに使い分けできるようになるべく分割
- 汎用性は考えない
考えるのは一定数のコードが溜まってから - エラーチェックは最小限に
ただし Runtime の Error で止まるようあえて脆弱に
今回の対象サイト
今回の対象ですが、私の知り合いがちょっとだけ運用に関わっている、以下のサイトにします。こちらにある100以上のパターンのリストを作成したい。
このサイトを選んだ一番の理由は、ページ下部にある以下のモジュールです。

いわゆる ページャー 機能なのですが、これが付いているサイトは、リストされた情報を取るのが簡単な場合が多いんですよ。
まずは下準備
今回、私の環境は Windows 10 Home で、node は nodist で導入しており、選択しているバージョンは v8.12.0 です。
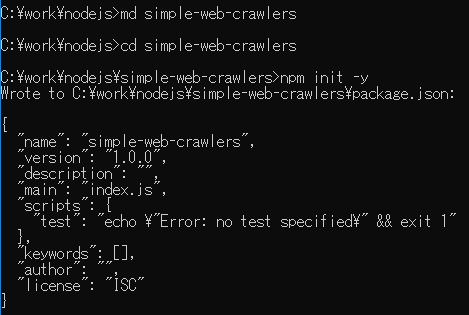
simple-web-crawlers ディレクトリを作成して npm init -y コマンドで package.json ファイルを自動作成します。
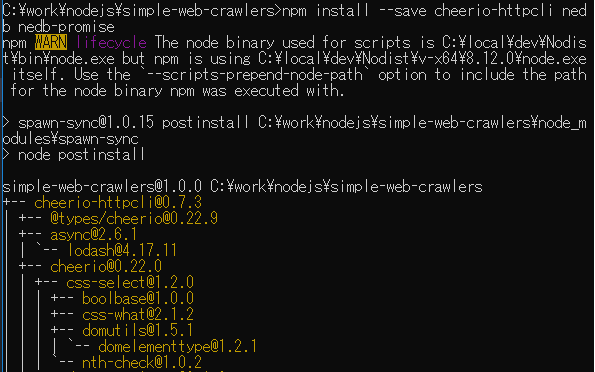
使用モジュールとして Web ページへのアクセス用に cheerio-httpcli を使用します。またデータ保存用に nedb と、そのアクセスを簡単にするため nedb-promise を使用します。
npm install --save cheerio-httpcli nedb nedb-promise を実行してモジュールを用意します。
(中略)
自動作成され、更新された package.json ファイルはこちら:
{
"name": "simple-web-crawlers",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"cheerio-httpcli": "^0.7.3",
"nedb": "^1.8.0",
"nedb-promise": "^2.0.1"
}
}
パターンをリストしよう
リスト用jsファイルの作成
好みのエディタ(私の場合は ATOM)を開き、リスト用のjsファイルを作成しましょう。私は list-ibmjp-patterns.js としてみました。
そして先頭は以下のように定番のモジュール読み込みと、起動時のヘルプメッセージを適当に記載しておきます。
const client = require('cheerio-httpcli')
const nedb = require('nedb');
const nedb_promise = require('nedb-promise');
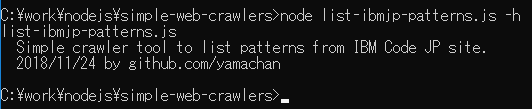
if (process.argv.length !== 2) {
console.log('list-ibmjp-patterns.js');
console.log(' Simple crawler tool to list patterns from IBM Code JP site.');
console.log(' 2018/11/24 by github.com/yamachan');
return;
}
今回の簡易ツールは実行時に何もパラメータ指定が必要ないので、何か指定されたらヘルプメッセージを表示して終わるようになっています。
そして、使用する値をベタに定義しておきましょう。
const nedb_file_name = 'list-ibmjp-patterns.nedb';
対象サイトのURL分析
さて、今回の対象 URL は https://developer.ibm.com/jp/patterns/ なわけですが、ページャー機能がある場合には調べ方にパターンがあって:
- ページャーで2ページ目のURLを確認
- 確認したURLが1ページ目にも同様に適用できるか確認
- 対象の数がページ内に表示されているか確認
3a. 表示されていればok
3b. 表示されていない場合は9999ページ目などの表示を確認
さて、これを順に確認していきましょう。まずページャーで2ページ目のURLですが
https://developer.ibm.com/jp/patterns/page/2/
です。次にこれを1ページ目に適用すると以下になり、これはトップにリダイレクトされます。リダイレクト処理は面倒な(ことがある)ので、リダイレクト先のURLを指定することにします。
https://developer.ibm.com/jp/patterns/page/1/
=> https://developer.ibm.com/jp/patterns/
対象の数は残念ながらページ内に見当たらないので、9999ページ目の表示を確認すると、ページはエラーにならず表示され、ただボディ部分が空になっているのがわかります。これは特別対応しなくても良いので、わりと楽なパターンです。
https://developer.ibm.com/jp/patterns/page/9999/
これらを元に、対象 URL を得るための関数を追加しておきましょう。
function getListURL(_page) {
if (_page == 1) {
return 'https://developer.ibm.com/jp/patterns/';
} else {
return 'https://developer.ibm.com/jp/patterns/page/' + _page + '/';
}
}
対象サイトのコンテンツ分析
さて、対象ページの構成を Web の開発者ツールで確認してみましょう。ここが今回のクローラー作成の最重要ポイントです。
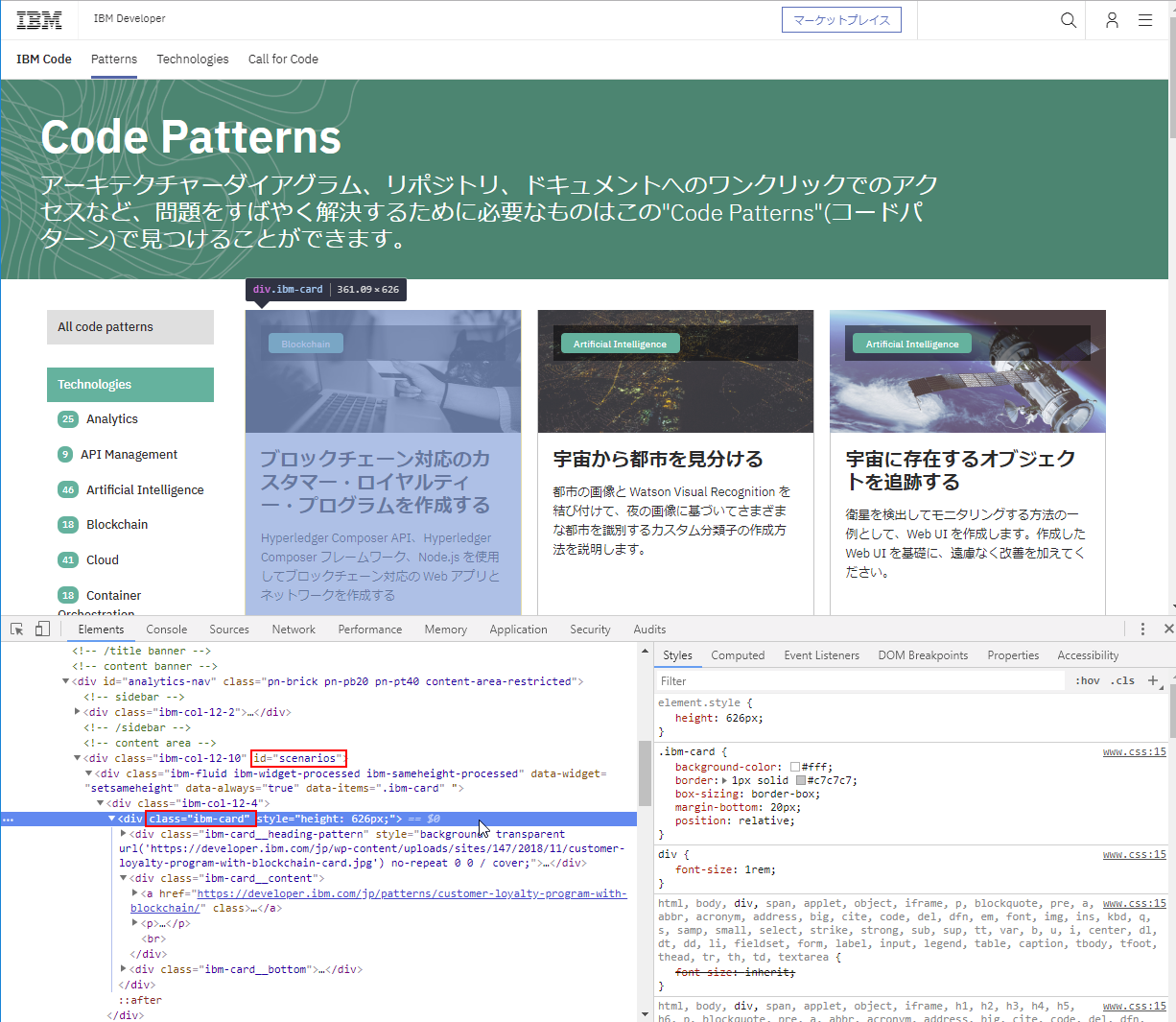
リスト対象に ibm-card というクラスが付与されているのがわかります。その親となる要素には scenarios というidが付与されているようです。
早速、開発者ツールのコンソールに切り替えて、これらの条件が絞り込みに利用できるか試してみましょう。
document.querySelectorAll("#scenarios .ibm-card")
素晴らしい!ちゃんとページ内のパターン15個がリストされることが確認できました。
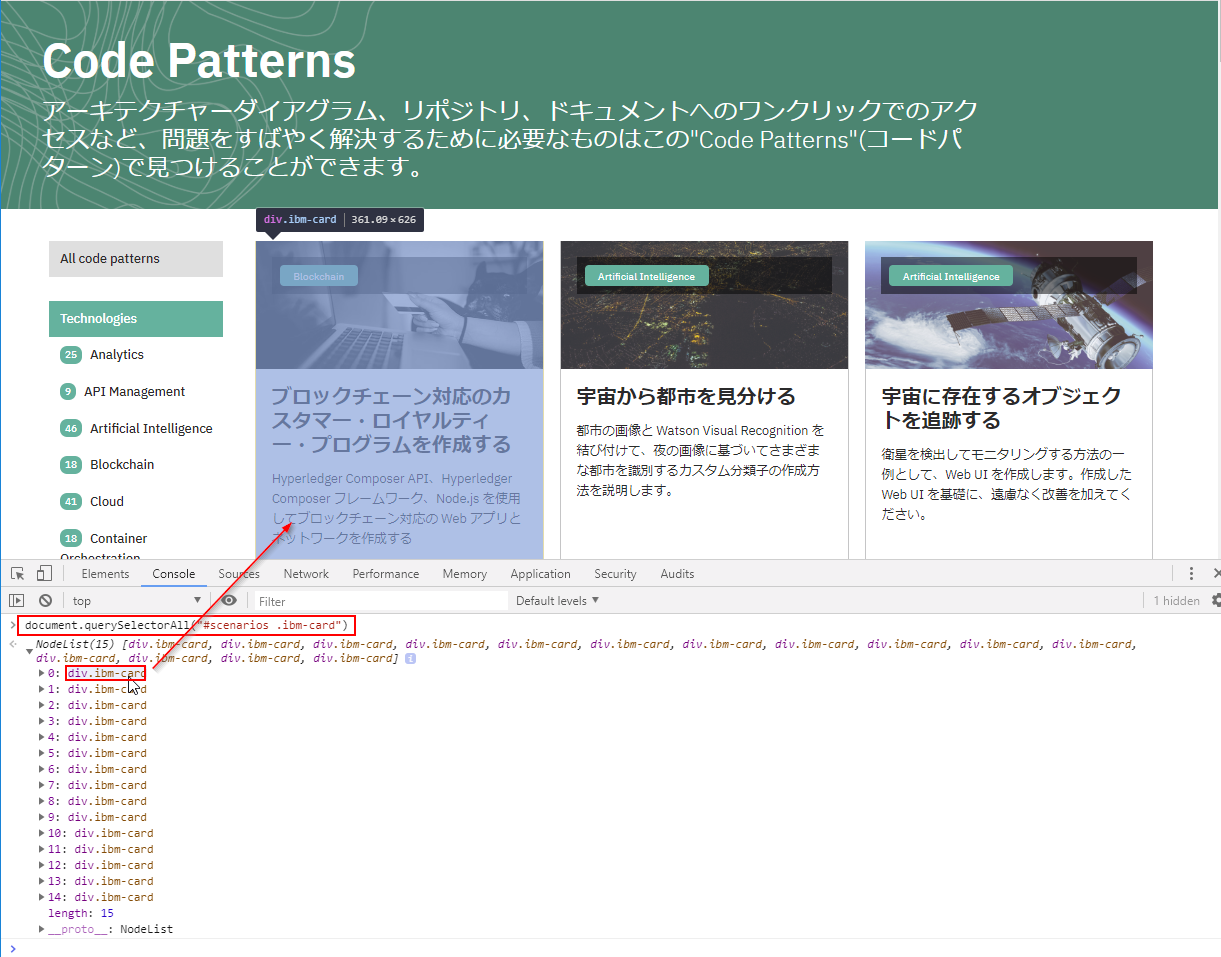
早速、js コードのほうにこの値(query用の文字列)を書き込んでおきましょう。
const list_item_query = '#scenarios .ibm-card';
メインロジックを書いてみよう
アイテムを絞り込めたところで、そろそろメインロジックを書いてみましょう。
と言っても、「ページごとにアイテムを処理していき、アイテムが0のページで終了」というロジックはよくあるもので、以下はわりと使いまわしのコードだったりします。
// ----- Main Loop -----
(async () => {
let page = 1; // ページャー機能のページ数
let number_of_items = 0;
let count_of_items = 0;
do { // ループの開始
console.log('LOOP: page = ' + page);
let url = getListURL(page); // ページ数に対応したURLを入手
let ret = client.fetchSync(url); // ここでWebページへアクセスし情報を得る
if (ret.error || !ret.response || ret.response.statusCode !== 200) {
console.log('ERROR:' + url);
return; // Web アクセスに問題があればツールを即終了させる
} else {
let items = ret.$(list_item_query); // 今回対象としているカード要素の配列を取得
number_of_items = items.length; // 現在のページに含まれる対象要素の数
processListItems(ret, items, page); // 要素の配列に対して処理を実行
count_of_items += number_of_items; // 要素の総数をカウントする
console.log('number_of_items = ' + number_of_items);
page++;
}
} while (number_of_items > 0); // 対象要素の数が0になるまでループを繰り返す
console.log('count_of_items = ' + count_of_items);
})();
async function processListItems(_ret, _items, _page) {
// ここに要素の配列に対するメイン処理を記述します
}
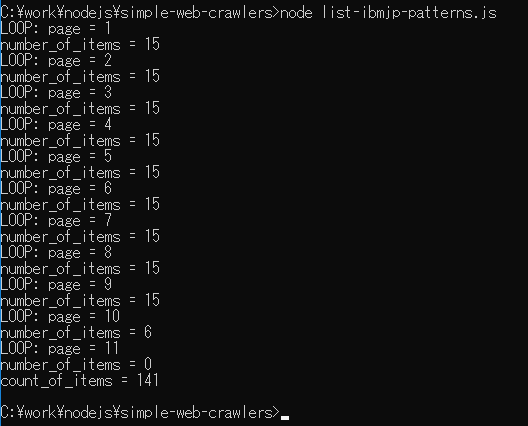
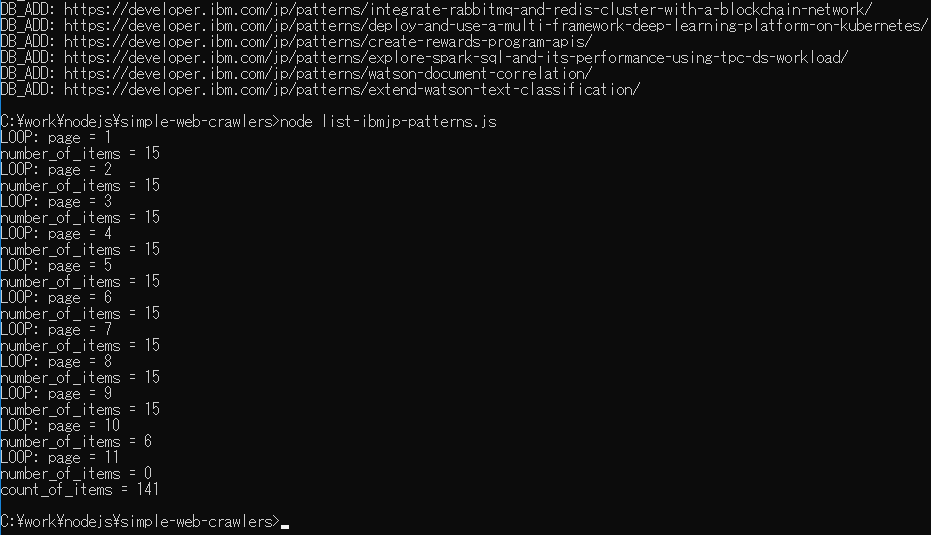
processListItems(ret, items, page) という関数がまだ空ですが、とりあえず実行してみましょう。以下が実行の様子ですが、11ページ目でアイテムが0なので動作が終了していること、パターンの合計は現在 141 個であることがわかりますね。
全体を (async () => { ... })(); で囲んでいるのは、nedb_promise ライブラリを使用するときのお約束、だと今回は理解しておいてください。
リスト対象の分析
コンテンツ分析と同様に、リスト対象の各アイテムの構成を Web の開発者ツールで把握しましょう。カード型の表示のためか、今回はわりと複雑な構成(HTML)になっているようです。
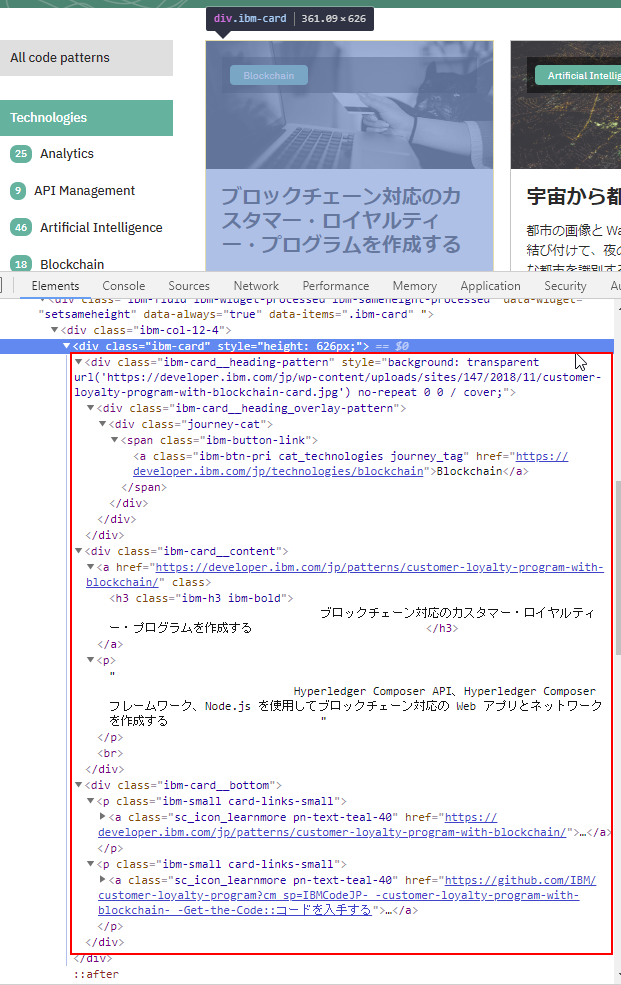
この構成を手掛かりに、必要なデータそれぞれの要素を入手し、cheerio や cheerio-httpcli のメソッドで操作して値を入手していきます。
今回は itemToObject(ret, item) という関数を追加し、この関数の中で上記の HTML 情報(を解析したDOM)から、JavaScript のデータオブジェクトを生成します。
function itemToObject(_ret, _item) {
return {
title: _ret.$('.ibm-h3', _item).text().trim(),
desc: _ret.$('.ibm-card__content p', _item).text().trim(),
url: _ret.$('.ibm-card__bottom p:first-child a:first-child', _item).url(),
github: _ret.$('.ibm-card__bottom p:nth-child(2) a:first-child', _item).url().replace(/\?cm_sp=IBMCodeJP-_-.*$/, ''),
tech: _ret.$('.ibm-card__heading-pattern .journey-cat a', _item).map(function(){
return _ret.$(this).text().trim()
}).get().sort()
};
}
title、desc、url は単に値を得ているだけなので、Web 構成をもとに探し方(query文字列)をどううまく見つけるか、というだけの話ですね。
github も同様なのですが、URL 末尾にあるパラメーター値が不要なので String の replace 関数で除去しています。
tech が一番複雑で、これは対象アイテムの分類項目なのですが、要素として複数指定されているものがあるのです。なのでその各要素を cheerio の map 関数を使って文字列に変換し、結果として文字列の配列を返すようにしています。
ちなみに以下は、上記のロジックでJavaScript のデータオブジェクト化したアイテムの例です。
{
"title":"ブロックチェーン対応のカスタマー・ロイヤルティー・プログラムを作成する",
"desc":"Hyperledger Composer API、Hyperledger Composer フレームワーク、Node.js を使用してブロックチェーン対応の Web アプリとネットワークを作成する",
"url":"https://developer.ibm.com/jp/patterns/customer-loyalty-program-with-blockchain/",
"github":"https://github.com/IBM/customer-loyalty-program",
"tech":["Blockchain"]
}
書き込み先のDBの準備をしておこう
さて、簡易ツールが実現できそうな目途がついたところで、出力先である nedb の準備をしておきましょう。nedb は NoSQL DB (OODB) で、手軽に使えることと、保存された DB ファイルが単なるテキストの JSON 風形式で扱いやすいのがポイントです。
※ JSON風、というのは JSON 形式のオブジェクト情報が単に行ごとに並んでいるから。改行をカンマに変換し、[]で囲めばちゃんと JSON 形式のオブジェクト配列になります。
さて、以下の nedb 準備コードを js コードに追加しておきましょう。
const db = new nedb_promise({
filename: nedb_file_name,
autoload: true
});
いよいよDBへの書き込み
お待たせしました、さきほど空だった processListItems(ret, items, page) 関数の中身を実装していきましょう。この関数はページごとに、対象アイテムの配列(今回は最大で15個入り)を渡される、のでしたね。
実はこの部分もわりとワンパターンで、汎用的に使えるもので、各オブジェクトごとに
- DB をキー (今回はURL) に
db.findで検索 - 見つからなければ
db.insertで追加して終了 - 見つかれば
checkUpdateObject関数で更新を確認し、更新がなければ終了 - 更新されていれば
db.updateでデータ更新
を実施すれば良く、以下のようなコードにしました。
function checkUpdateObject(_obj, _doc) {
return JSON.stringify(_obj) !== JSON.stringify({
title: _doc.title,
desc: _doc.desc,
url: _doc.url,
github: _doc.github,
tech: _doc.tech
});
}
async function processListItems(_ret, _items, _page) {
for (let loop = 0; loop < _items.length; loop++) {
let obj = itemToObject(_ret, _items[loop]);
let doc = await db.findOne({url: obj.url}); // db を検索
if (doc) { // 見つかったら
if (checkUpdateObject(obj, doc)) { // 更新を確認して
await db.update({url: obj.url}, {$set: obj}); // DBを更新
console.log('DB_UPDATE: ' + obj.url);
}
} else { // 見つからなかったら
await db.insert(obj); // DB に追加
console.log('DB_ADD: ' + obj.url);
}
}
}
checkUpdateObject 関数は少し手抜き気味ですが、まあ問題ないレベルで動作するのでお許しくださいw
完成したコード
今回作成したコードを GitHub で公開しました。リポジトリは simple-web-crawlers で、今回のツールのソースコードは list-ibmjp-patterns.js です。
実行してみよう
さて、これで Web クローラーが完成したので、list-ibmjp-patterns.js を実行してみましょう。
最初の実行では DB_ADD が141行ぐらい表示されるとおもいます。二度目の実行ではそれが表示されないのが正解です。以下はその様子の最後のほう:
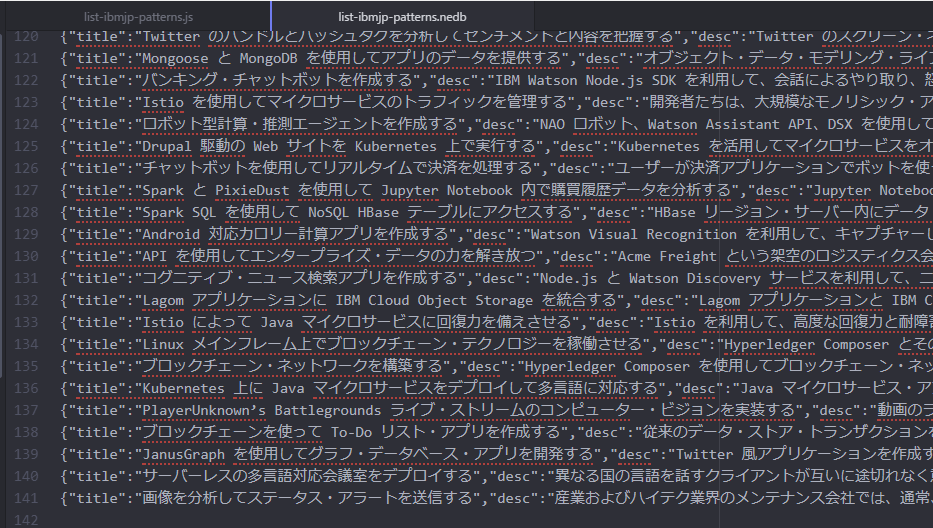
実行後、list-ibmjp-patterns.nedb ファイルに141行ほどのデータが記録されていることを確認できます。
json 形式への変換
nedb 形式のファイルのままだと扱いづらいので、JSON 形式のファイルに変換する小さなツールも書いてみました。GitHub にもあがっています。
const fs = require('fs')
if (process.argv.length !== 3 || process.argv[2].startsWith('-')) {
console.log('nedb2json.js');
console.log(' Convert a nedb file to a json file.');
console.log(' 2018/11/24 by github.com/yamachan\n');
console.log(' node nedb2json list-ibmjp-patterns.nedb > list-ibmjp-patterns.json');
return;
}
let list = fs.readFileSync(process.argv[2])
.toString()
.split('\n')
.filter(s => s.trim() !== '');
console.log('[\n' + list.join(',\n') + '\n]');
以下のようにして変換してください。
node nedb2json list-ibmjp-patterns.nedb > list-ibmjp-patterns.json
というわけで
今回は とあるサイト を対象に、さくっと簡易的な Web クローラーを Node.js で作成してみました。
ページャー機能付きのサイトであれば簡単な改造で適用できるとおもいますので、皆さんも身近なサイトを対象にクローラーを書いてみてください。なかなか楽しいですよ。
【追記】このツールを改造する 続編 も公開しましたので、ご興味があればぜひ!
それではまた!