こんにちは。自分の覚えのためにいろいろ書きます。
LocalLLMを試してみた記録です。
前提とやることとやらないこと
やることとやらないことを書いていきます
前提
・筆者の環境:i5-13400、RAM32GB、RTX2060(6GB)←友人から五千円くらいで買った、ありがとう
やること
・WSLにUbuntu Server 24.04 / Dockerは導入済み。/GPU関係の色々も導入済み
やらないこと
・ubuntuの初期設定、WSLの初期設定、docker導入についての解説
ゴール
- Docker Hubの公式コマンドでOllamaを立ち上げる
- モデル(軽いやつ)を入れる
- CLIで対話できることを確認する
- Open WebUIでブラウザからLLMを触れるようにする
- RAGみたいなやつ試す
1. DockerでOllamaを立ち上げる
DockerでNvidia Driverを使う設定はすでに済んでいるものとします。詳しくはOllamaのDocker Hubに書いてあるので、そこのコマンドを貼り付けながらエラーが出たらChatGPTに聞けばいいと思う。
https://hub.docker.com/r/ollama/ollama
やること:コンテナをrunする
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
だいたいイメージサイズが1.5GBくらいなので、まあまあ時間かかります。ゆっくり待ちましょう。この設定だとポート11434で公開されます。
ダウンロード・インストールの色々が終わったら
curl -s http://127.0.0.1:11434
で”Ollama is running"と帰ってきたら大丈夫だと思う。
2. モデルをいれます(Qwen3 0.6B)
まずはさっきrunしたdockerコンテナに入りましょう
docker exec -it ollama bash
ollamaのコンテナに入ったら、モデルをインストールします。今回は最近話題のqwen3の軽いモデル、"qwen3:0.6B"を使います。
ちなみに、ollamaのsearchのページをみると、いろいろなモデルがあるので、qwrn3:0.6Bでなくても動かしたいものがあればそれで大丈夫です。
ollama pull qwen3:0.6b
完了したら、
ollama list
で確認できます。
NAME ID SIZE MODIFIED
qwen3:0.6b 7df6b6e09427 522 MB 2 days ago
こんな感じで確認できるはずです。
3. CLIで動くことを確認してみる
では、入れたモデルを早速動かしてみましょう
ollama run qwen3:0.6b
しばらくくるくるした後に"Send a message"と言われるので試しに「日本語でqwen3について自己紹介して」なんて聞いてみると

こんな感じで返ってきます。動作が問題ないことをこれで確認できます。あとは対話履歴をクリアしたり、モデルの情報を表示したりは /?で確認できるのでやってみてください。
終了はCtrl + dです。
4. WebUI(Open WebUI)で触ってみる
一番カンタンな起動方法はこちら(Ollamaはホストの11434で稼働中という前提)(GPUを使っている前提)
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
あとは、localhost:3000に飛べばOPEN WEBUIにアクセスできます。会員登録みたいなものだけしたらモデルが選択できるはず。
詳しくはここに書いてます。 https://github.com/open-webui/open-webui
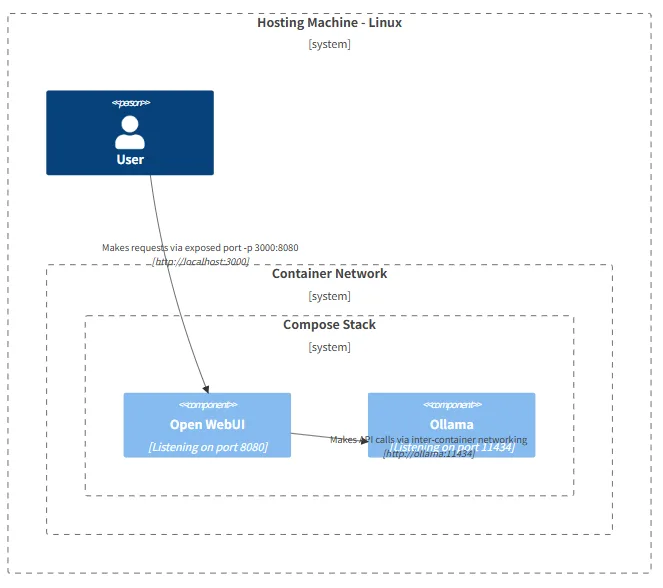
ここの図もめちゃくちゃわかりやすいので、おすすめ。今回は別々のコンテナで実行したけど、この図で示されているような、1コンテナで構成したほうがわかりやすいかも。
https://docs.openwebui.com/getting-started/advanced-topics/network-diagrams/#mac-oswindows-setup-options-%EF%B8%8F
実際に動いているところはこちら。こんな感じで、よく見る感じのUIで触れるのでおすすめ。(てか、Gemma3ってすごいべ。4Bモデルでもちゃんとしてる。舐めてました。)
5. Open-WebUIでRAGみたいなこと試してみる
Open-WebUIでRAGっぽいことできます。詳しくはここって感じですが。
https://docs.openwebui.com/tutorials/tips/rag-tutorial/
左側のメニューからworkspace → Knowledgeに飛び、+を押せるのでそこから設定します。
画像がないのですみませんという感じですが、そこでKnowledge Baseを作成すると、ドキュメント等登録できます。
自分は大学時代に学んでいた領域の研究論文を入れてみた上で、XXについてYY氏はどのような見解を述べていますか?など質問すると、エビデンスとしてドキュメントを参照した上で回答してくれます。
結構簡単にできるので、やってみてください。
まとめ
というわけで、Dockerをフル活用して、OllamaとWebUIでLocalLLMお試しを簡単にやってみました。
感覚的には4Bモデルは筆者の環境だと比較的普通に動きます。8Bモデルはちょっと重いかな、回答来ないなあ。という感じ。
モデルのサイズ、あまり意識したことはなかったけど、比較的最近出たGPT-OSSは120Bでしょ。4Bでも割と頑張ってるな!と思ったのに、30倍ってすごい。80GBのグラボで動くらしい。
知り合いがとんでもないグラボ積んだサーバ・PC貸してもらえるらしくて素直に羨ましい気持ちを発散したところで、本記事は終わりです。
気が向いたらRAGの部分に画像追加します。次はVScode + Contunue、Open-WebUIとContinueのバックグラウンドに共通のRAG持たせて動かすとかやってみたい。
以上です。