はじめに
ついにS3 Vectorsが東京リージョンにきました。
待ち望んでいた方もいたかと思います。
そこで早速触ってみました。
S3 Vectorsとは
プレビュー版のときのAWS公式ブログには以下のように記載されています。
ベクトルのアップロード、保存、クエリの総コストを最大 90 % 削減できる、耐久性に優れたベクトルストレージソリューションです。Amazon S3 Vectors は、大規模なベクトルデータセットの保存をネイティブにサポートし、1 秒未満のクエリパフォーマンスを実現する初めてのクラウドオブジェクトストアです。これにより、企業が AI 対応データを大規模に低コストで保存できるようになります。
ベクトルのアップロード、保存、クエリの総コストを最大 90 % 削減できる、耐久性に優れたベクトルストレージソリューションです。Amazon S3 Vectors は、大規模なベクトルデータセットの保存をネイティブにサポートし、1 秒未満のクエリパフォーマンスを実現する初めてのクラウドオブジェクトストアです。これにより、企業が AI 対応データを大規模に低コストで保存できるようになります。
要するに、ベクトルストアを低コストで利用可能ということです。
ただそこにはトレードオフの関係が存在します。
S3 Vectorsはベクトルストレージサービスとして基本的な「ベクトルの保存 (追加)」「ベクトルデータのクエリ」「メタデータによるフィルタリング」といった機能のみを備えていますが、
OpenSearch Serviceのような「ハイブリッド検索」「高度なフィルタリング」「ファセット検索」といった機能は持っていません。
高機能を求めない、お試しで使いたい、低コストで運用したいということならS3 Vectors一択になるかと思います。
実際に確認してみた
東京リージョンにて、AWSマネジメントコンソールからBedrockのコンソールに入ります。
左ペインの「ナレッジベース」を選択します。

「ベクトルストアを含むナレッジベース」を選択し、「作成」を選択します。

ナレッジベース名を入力し、IAM許可はそのまま、データソースでAmazon S3を選択します。

データソース名を入力し、S3のURIには既に作成済みのS3のものを入力します。
あとはデフォルトのままで「次へ」を選択します。

埋め込みモデルには「Titan Text Embedding V2」を選択します。

ベクトルデータベースで「新しいベクトルストアをクイック作成」を選択します。

Amazon S3 Vectorsを選択します。

なお、ここで事前にS3でベクトルバケット等を作っていると、「既存の~~」から選択できます。
暗号化はデフォルトではSSE-S3になっていますが、追加設定でチェックマークを入れると、SSE-KMSを選択できます。
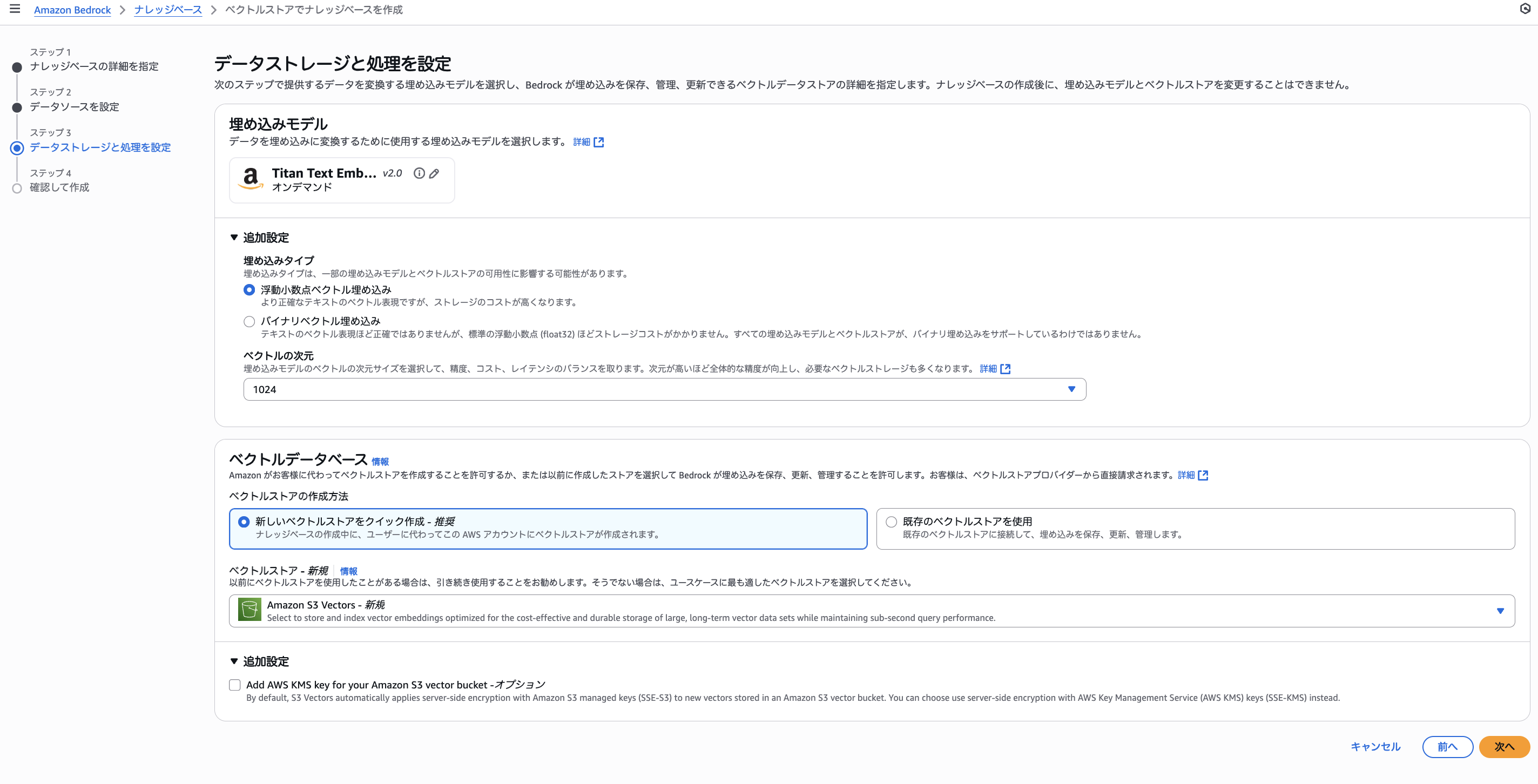
確認して間違いなければ作成です。

テストをやってみました。
S3内には「AWS Certified Generative AI Developer - Professional (AIP-C01)」試験ガイドのPDFファイルが入っています。
まずはモデルを「Claude Haiku 4.5」でやってみました。
きちんと日本語で返ってきています。

モデルをリリースしたての「Nova 2 Lite」にして、同じ質問を入力してみました。
英語で返ってきました。

モデルを「Nova Pro 1.0」にすると、回答の仕方は変わりましたが、日本語で返ってきました。

終わりに
S3 Vectorsが東京にきたのは嬉しいと思われる方は私を含めて多いのではないでしょうか。
Nova 2 Liteが日本語対応していなかったのは少し残念ですが、もしかしたらやり方があるか、今後のアップデートを待つしかないのかなと思いました。