はじめに
Speach to Textモデルは日々進化しています。
特に英語、中国語対応のものが発展してきており、日本語対応モデルが遅れを取っているのが現状です。
今回は、日本語発声→日本語で文字起こしをするモデルを比較してみました。
前提条件
・MacBookPro M1モデルを使用
・マイクには、Ear Podsのものを使用
・以下の文章を私が読み上げる
私は長崎県長崎市出身です。 現在は東京都に住んでいます。 41歳でITエンジニアになりました。
Amazon Transcribe
AWSが提供するSpeach to Textモデル
英語、中国語だけでなく日本語、ロシア語、スペイン語等世界中の言語に対応
上記前提条件のもと、出力された結果は以下のとおりです。
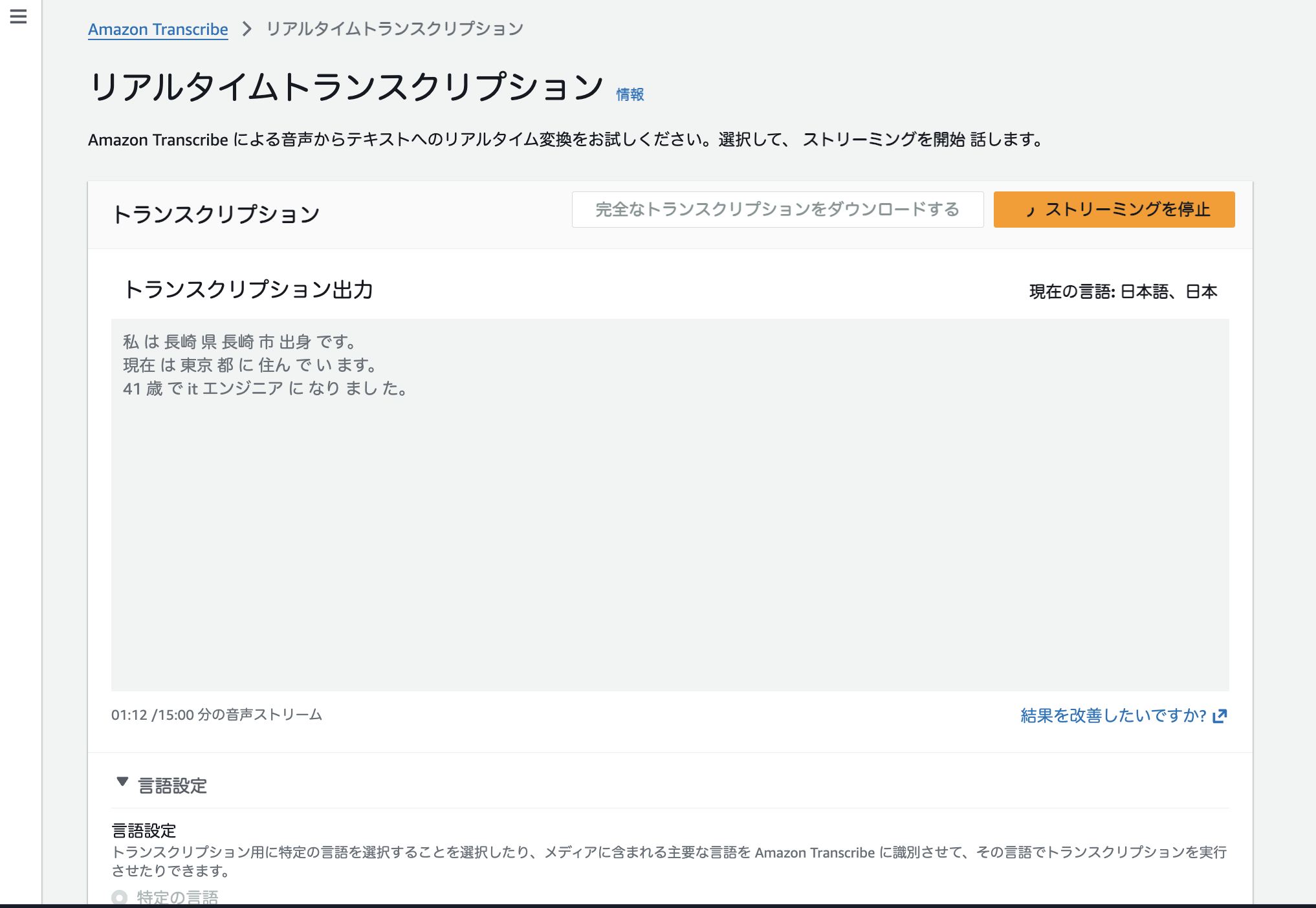
漢字変換も正確にされていますが、仕様の関係か
長崎 県
のようにひとつのまとまった単語として認識されていないようにも見えます。
また、以下の動画でも出てきますが、話しているときにリアルタイムで文字起こしがされています。
NVIDIA canary-1b-asr
NVIDIAが提供する多言語対応Speach to Textモデル
Amazon Transcribeと比べると対応言語は少ないですが、英語、中国語、スペイン語、日本語等に対応しています。
このモデルは、発声した言語を、英語で出力するか、日本語で出力するかを選択できます。
文字起こしだけでなく、翻訳機能もついているというモデルです。
上記前提条件のもと、出力された結果は以下のとおりです。
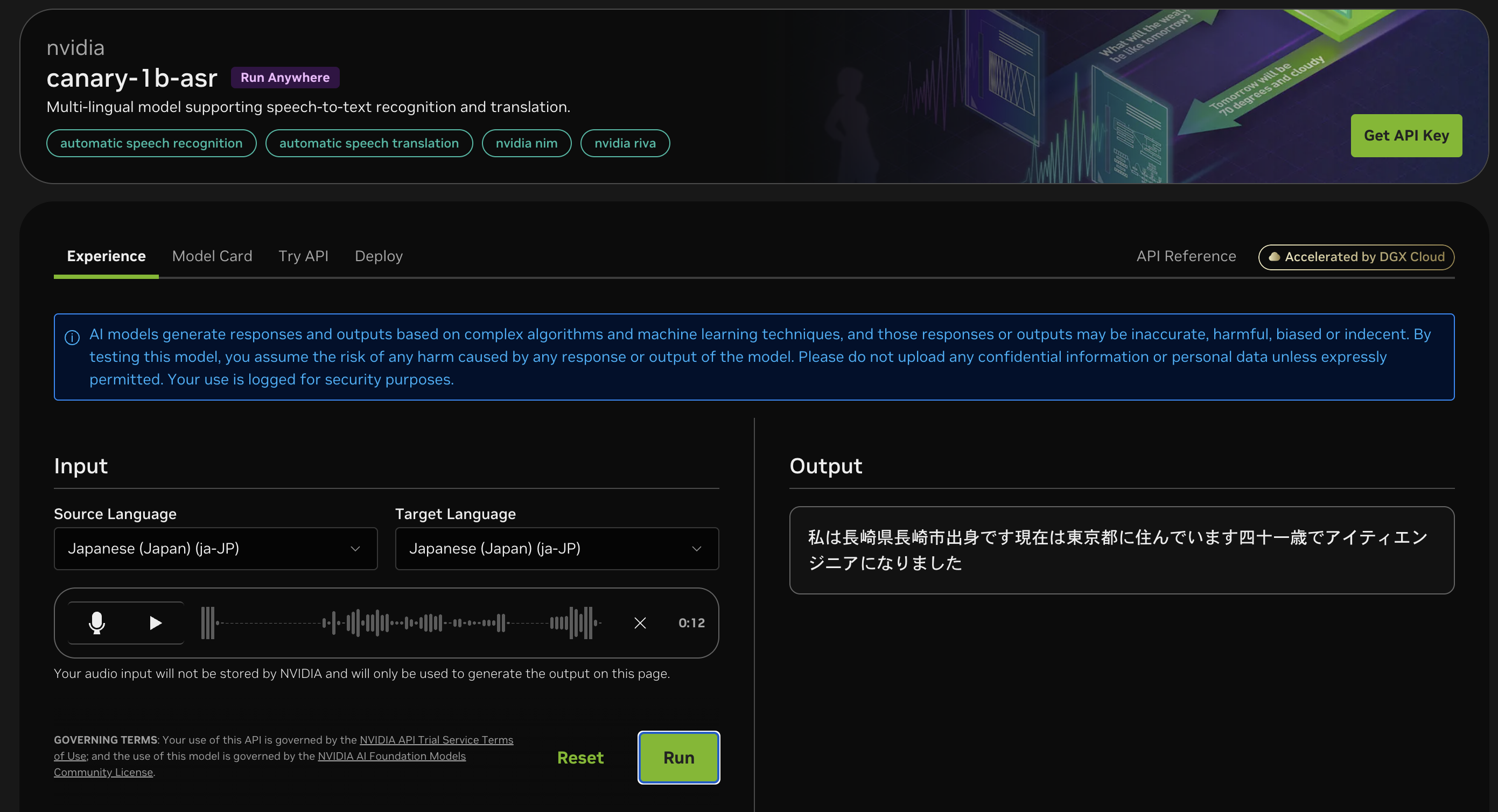
漢字変換も概ねできていますが、文章と文章の切れ間がないのと、
四十一歳
アイティエンジニア
のように変換がうまくできていないところも見られました。
これについては、仕様の関係もあると思われますが、インプットした後、マイクのアイコンを選択し、「Run」を選択したら、数秒で一気に出力されました。
このモデルについて録画したものが以下のものになります。
OpenAI whisper-large-v3
OpenAIが提供する多言語対応Speach to Textモデルです。
対応言語は、NVIDIA canary-1b-asrとほぼ同じで英語、日本語等に対応しています。
このモデルは、発声した言語を文字起こしするか、英訳するかを選択できます。
英訳のみですが、翻訳機能も持っているというモデルです。
上記前提条件のもと、出力された結果は以下のとおりです。
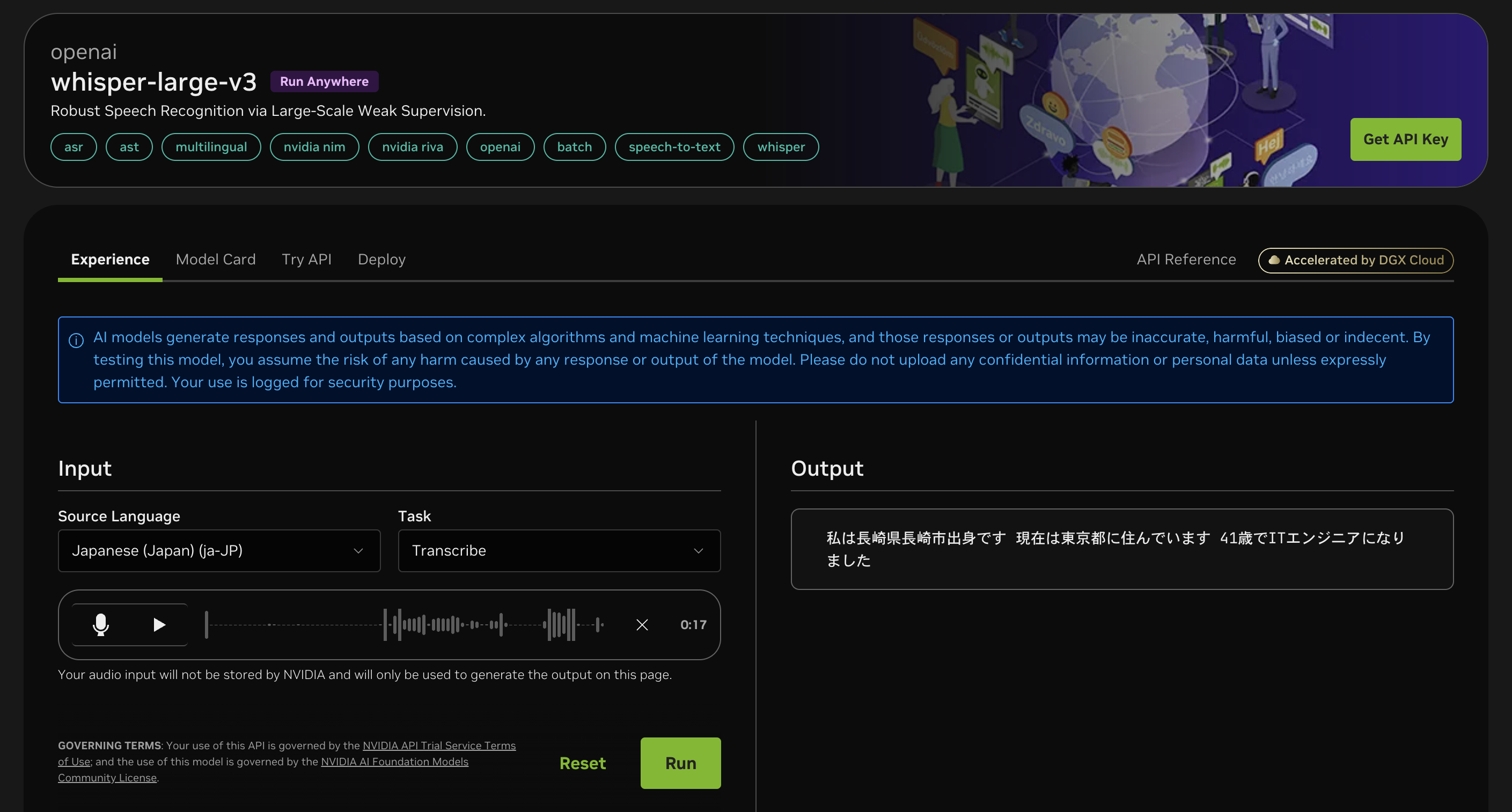
まず、漢字変換が正確でした。
文章と文章の間もきちんと分かれており、41歳、ITエンジニアというところも正確に変換されていました。
これについても、仕様の関係もあると思われますが、インプットした後、マイクのアイコンを選択し、「Run」を選択したら、数秒で一気に出力されました(体感ではNVIDIA canary-1b-asrよりも少しだけ出力が早い?)
このモデルについて録画したものが以下のものになります。
終わりに
3つのモデルを比較してみましたが、「日本語対応STTモデルではwhisperがひとつ抜けている」という前評判通り、OpenAI whisper-large-v3が日本語の文字起こしモデルとしては総合的にひとつ抜けている印象を受けました。
先日、AlibabaがQwen-TTSをOSSとして提供しましたが、各社音声AIについて競争が激化しており、音声AIからも目が離せません。
最後まで読んでいただきありがとうございました。