Snowflake上でGeminiが呼び出せるようになりました!
データパイプラインへのAI組み込みがさらに便利になりそうなので、試してみます。
サンプルユースケース
AI利用の例として、問い合わせ内容の分類をしてみましょう。
自由記述のテキストデータ(=非構造化データ)は分析が難しく、多くの企業で活用しきれていないのが実情ではないでしょうか。
SQLを用いた従来のアプローチでは、CASE文や正規表現(LIKE '%不具合%')などルールベースで分類を試みますが、表記ゆれや曖昧な表現に対応できず、限界がありました。
この記事では、Snowflake CortexのAI関数(Geminiモデル使用)とTROCCOを組み合わせて、問い合わせデータを毎日自動でAI分類するパイプラインを構築する方法を解説します。
この記事で学べること
- Snowflake Cortex
AI_COMPLETE関数の基本的な使い方 - SnowflakeでのGeminiモデル利用方法
- SQLだけでLLMを呼び出すプロンプト設計
- TROCCOで日次バッチ処理を自動化する方法
従来手法の課題
問い合わせ内容を分類する従来のSQLは、以下のようなものでした。
SELECT
inquiry_id,
inquiry_text,
CASE
WHEN inquiry_text LIKE '%不具合%' OR inquiry_text LIKE '%エラー%' THEN '不具合'
WHEN inquiry_text LIKE '%追加してほしい%' OR inquiry_text LIKE '%要望%' THEN '要望'
WHEN inquiry_text LIKE '%方法%' OR inquiry_text LIKE '%やり方%' THEN '質問'
ELSE 'その他'
END AS category
FROM customer_inquiries;
この方法には以下の問題があります。
| 課題 | 具体例 |
|---|---|
| 表記ゆれに弱い | 「動かない」「止まった」を「不具合」と認識できない |
| 文脈を理解できない | 「エラーの対処法を教えて」を「不具合」ではなく「質問」と判定すべき |
| メンテナンスコスト | 新しい表現が出るたびにCASE文を追加する必要がある |
解決策: Snowflake Cortex AI_COMPLETE
Snowflake Cortexを使えば、データを外部に出さず、SQLだけでLLMを呼び出せます。
AI_COMPLETE関数の基本構文
SELECT SNOWFLAKE.CORTEX.AI_COMPLETE(
'モデル名',
'プロンプト'
) AS result;
問い合わせ分類の実装例
以下のSQLで、問い合わせ内容を4つのカテゴリに自動分類できます。
SELECT
inquiry_id,
inquiry_text,
TRIM(SNOWFLAKE.CORTEX.AI_COMPLETE(
'gemini-2.5-flash',
'以下の問い合わせ内容を「不具合」「要望」「質問」「その他」のいずれか1つに分類してください。
カテゴリ名のみを出力してください。
問い合わせ内容: ' || inquiry_text
)) AS ai_category
FROM customer_inquiries
WHERE created_at >= CURRENT_DATE - 1;
出力例
| inquiry_id | inquiry_text | ai_category |
|---|---|---|
| 1001 | アプリが突然落ちるようになりました | 不具合 |
| 1002 | ダークモードを追加してほしいです | 要望 |
| 1003 | ログインできないのですがどうすればいいですか | 不具合 |
TRIM()でLLMの出力から余分な空白や改行を除去しています。
Snowflake上で動作確認します。
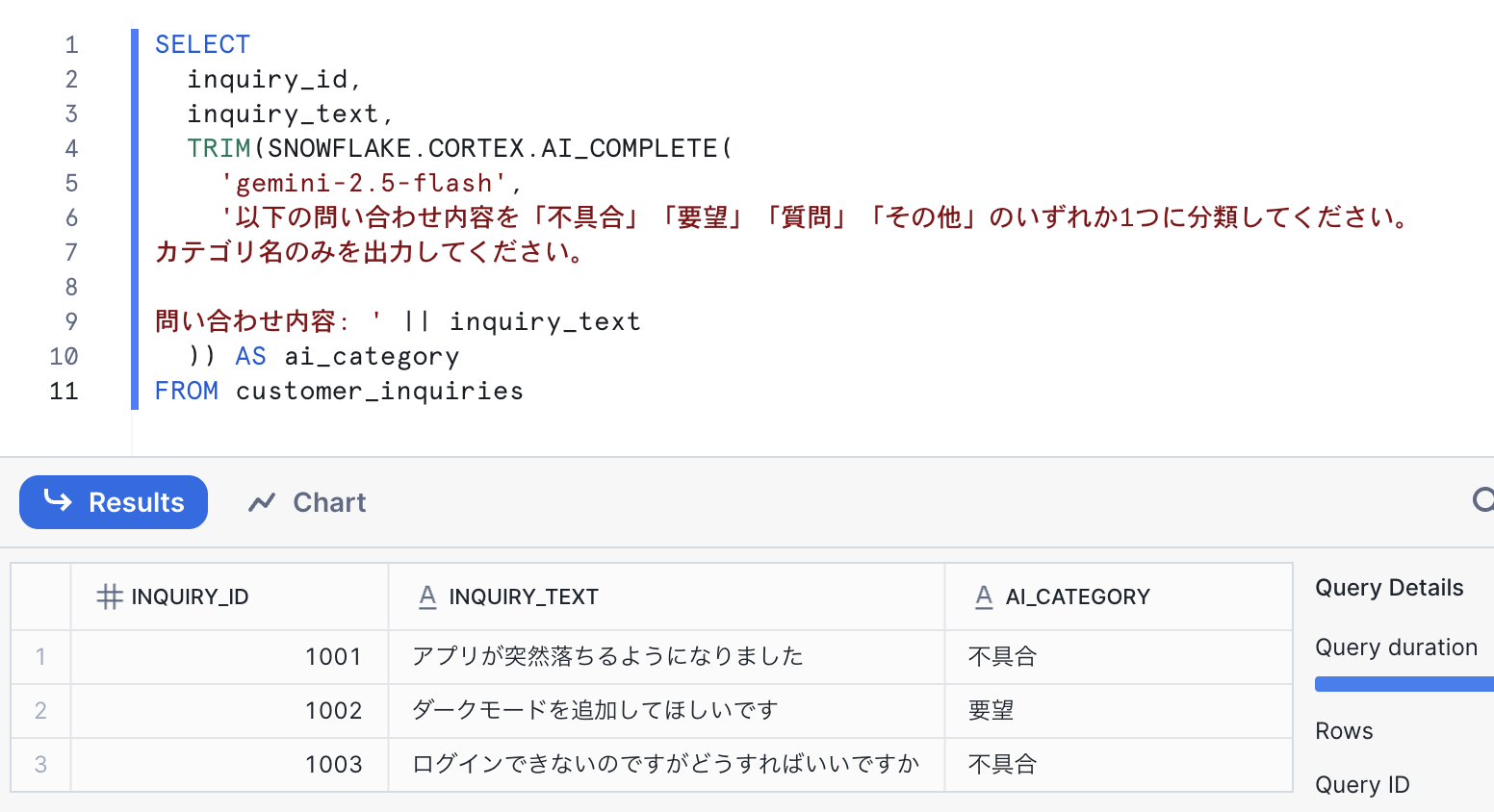
プロンプト設計のポイント
先ほどの出力例で、「ログインできないのですがどうすればいいですか」という問い合わせが「不具合」と分類されていましたが、本来は「質問」と分類するのが適切そうです。
LLMに明確な指示を与えることで、分類精度の向上を図ってみます。
-- より詳細なプロンプト例
SELECT
inquiry_id,
inquiry_text,
TRIM(SNOWFLAKE.CORTEX.AI_COMPLETE(
'gemini-2.5-flash',
'## タスク
以下の問い合わせ内容を分類してください。
## カテゴリ定義
- 不具合: 製品の動作不良、エラー、クラッシュに関する報告
- 要望: 新機能の追加や改善の提案
- 質問: 使い方や仕様に関する問い合わせ
- その他: 上記に該当しないもの
## ルール
- カテゴリ名のみを1つ出力すること
- 迷った場合は「その他」を選択
## 問い合わせ内容
' || inquiry_text
)) AS ai_category
FROM customer_inquiries;
指示を詳細化することで、出力が改善されました。

TROCCOで日次バッチ処理を自動化
単発の実行ではなく、毎日新しい問い合わせを自動分類するためにTROCCOを活用します。
なぜTROCCOを使うのか
| 観点 | メリット |
|---|---|
| 環境構築 | Python環境やAPIキー管理が不要 |
| スケジュール | 画面上から柔軟に実行タイミングを設定 |
| 監視 | 実行履歴とエラー通知が標準装備 |
| 依存管理 | 前処理→AI分類→後処理をワークフロー化 |
構成イメージ
[データソース] → [TROCCO転送] → [Snowflake生データ]
↓
[TROCCOデータマート/クエリ実行]
(AI_COMPLETEを含むSQL)
↓
[分類済みテーブル]
設定手順
ステップ1: データマート定義を作成
TROCCOの「データマート定義」で、AI分類SQLを登録します。
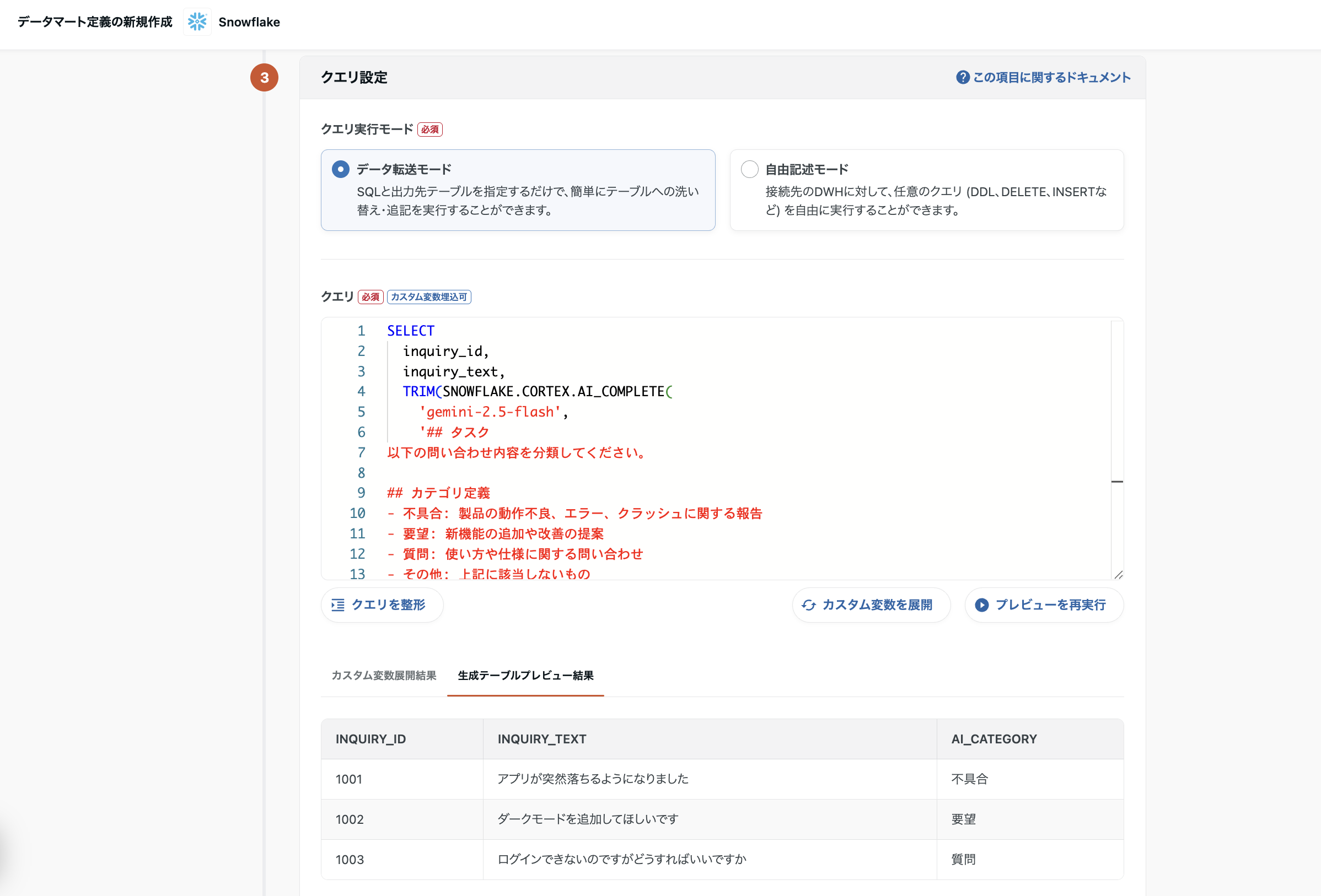
-- TROCCOに登録するSQL
SELECT
inquiry_id,
inquiry_text,
TRIM(SNOWFLAKE.CORTEX.AI_COMPLETE(
'gemini-2.5-flash',
'## タスク
以下の問い合わせ内容を分類してください。
## カテゴリ定義
- 不具合: 製品の動作不良、エラー、クラッシュに関する報告
- 要望: 新機能の追加や改善の提案
- 質問: 使い方や仕様に関する問い合わせ
- その他: 上記に該当しないもの
## ルール
- カテゴリ名のみを1つ出力すること
- 迷った場合は「その他」を選択
## 問い合わせ内容: ' || inquiry_text
)) AS ai_category,
CURRENT_TIMESTAMP() AS classified_at
FROM <DATABASE>.<SCHEMA>.customer_inquiries
-- 初回実行時は以下の行を削除して実行
WHERE created_at >= CURRENT_DATE - 1
AND inquiry_id NOT IN (SELECT inquiry_id FROM <DATABASE>.<SCHEMA>.classified_inquiries)
ステップ2: 初回実行
初回の手動実行を実施し、テーブル生成と初期データ投入を同時に行います。
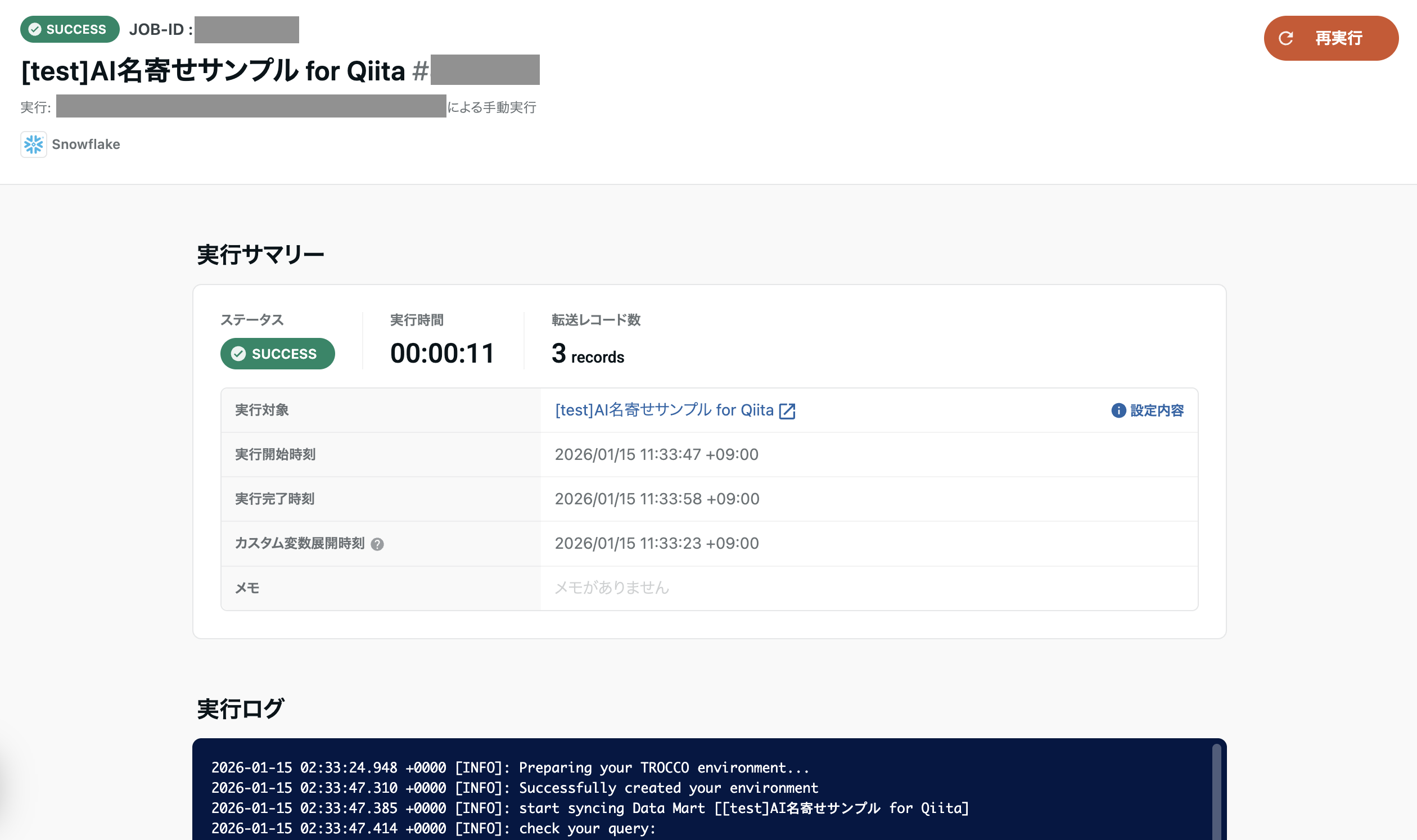
ステップ3: ワークフロー作成(スケジュール/通知設定)
定期実行のために、ワークフローから連携ジョブを呼び出す設定を追加します。
また、エラー発生時にSlackへ通知するよう設定しておくと、運用が楽になります。

運用Tips
コスト管理
Snowflake Cortexの利用にはクレジットが消費されます。大量データを処理する前に、サンプルで動作確認することをおすすめします。
-- まず10件でテスト
SELECT
inquiry_id,
TRIM(SNOWFLAKE.CORTEX.AI_COMPLETE('gemini-2.5-flash', '...')) AS ai_category
FROM customer_inquiries
LIMIT 10;
分類結果の検証
定期的に分類精度を確認し、プロンプトを改善するサイクルを回しましょう。
-- 分類結果の分布を確認
SELECT
ai_category,
COUNT(*) AS count,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (), 1) AS percentage
FROM classified_inquiries
WHERE classified_at >= CURRENT_DATE - 7
GROUP BY ai_category
ORDER BY count DESC;
応用例
問い合わせ分類以外にも、同じ手法でさまざまなテキストデータにラベル付けできます。ここでは実務でよくあるユースケースを紹介します。
応用1: 求人データへの職種ラベル付け
求人サイトから収集したデータに、統一された職種カテゴリを付与する例です。
-- 求人タイトルと説明文から職種を推定
SELECT
job_id,
job_title,
TRIM(SNOWFLAKE.CORTEX.AI_COMPLETE(
'gemini-2.5-flash',
'## タスク
以下の求人情報から職種カテゴリを判定してください。
## 職種カテゴリ
- エンジニア: ソフトウェア開発、インフラ、データ分析など技術職
- 営業: 法人営業、個人営業、インサイドセールスなど
- マーケティング: 広告運用、PR、ブランディングなど
- バックオフィス: 経理、人事、総務、法務など
- その他: 上記に該当しないもの
## ルール
- カテゴリ名のみを1つ出力すること
## 求人タイトル
' || job_title
)) AS job_category
FROM job_postings
WHERE job_category IS NULL;
出力例:
| job_id | job_title | job_category |
|---|---|---|
| 2001 | Webアプリケーションエンジニア(React/Python) | エンジニア |
| 2002 | カスタマーサクセス責任者候補 | 営業 |
| 2003 | SNSマーケター / TikTok運用担当 | マーケティング |
応用2: 商品レビューの感情・トピック分類
ECサイトのレビューを複数の観点で分類する例です。
-- 感情とトピックを同時に抽出
SELECT
review_id,
review_text,
TRIM(SNOWFLAKE.CORTEX.AI_COMPLETE(
'gemini-2.5-flash',
'## タスク
以下の商品レビューを分析してください。
## 出力形式(JSON)
{"sentiment": "positive/negative/neutral", "topic": "品質/価格/配送/サポート/その他"}
## ルール
- 必ず上記JSON形式で出力すること
- sentimentとtopicの両方を判定すること
## レビュー内容
' || review_text
)) AS analysis_json
FROM product_reviews
WHERE analyzed_at IS NULL;
JSON形式で出力させる場合、TRY_PARSE_JSON()で安全にパースすることをおすすめします。
-- JSONをパースして個別カラムに展開
SELECT
review_id,
review_text,
TRY_PARSE_JSON(analysis_json):sentiment::STRING AS sentiment,
TRY_PARSE_JSON(analysis_json):topic::STRING AS topic
FROM (
-- 上記のSELECT文
);
応用3: 社内ドキュメントの部門タグ付け
社内Wikiやナレッジベースの記事に、自動で部門タグを付与する例です。
SELECT
doc_id,
doc_title,
TRIM(SNOWFLAKE.CORTEX.AI_COMPLETE(
'gemini-2.5-flash',
'## タスク
以下の社内ドキュメントのタイトルと概要から、関連する部門を判定してください。
## 部門一覧
- 開発部: システム開発、技術仕様、リリースノートなど
- 営業部: 提案資料、顧客情報、商談管理など
- 人事部: 採用、評価、研修、福利厚生など
- 経理部: 経費精算、請求、予算管理など
- 全社共通: 社内規定、セキュリティ、ITツールなど
## ルール
- 最も関連性の高い部門名を1つだけ出力すること
## ドキュメント情報
タイトル: ' || doc_title || '
概要: ' || doc_summary
)) AS department_tag
FROM internal_documents;
応用のポイント
これらの応用例に共通するベストプラクティスをまとめます。
| ポイント | 説明 |
|---|---|
| カテゴリ定義を明確に | 曖昧なカテゴリは分類精度を下げる。各カテゴリの境界を具体例で示す |
| 出力形式を限定 | 「カテゴリ名のみ」「JSON形式」など、パースしやすい形式を指定する |
| 複数項目は段階的に | 一度に多くの情報を抽出しようとせず、必要なら複数回に分ける |
| エラーハンドリング |
TRY_PARSE_JSON()やCOALESCEで、想定外の出力に対応する |
まとめ
Snowflake Cortex とTROCCO を組み合わせて、問い合わせデータをAI自動分類するパイプラインを構築する方法を解説しました。
- Snowflake Cortex を使えば、SQLだけでLLMを呼び出せる
- プロンプト設計次第で分類精度をチューニングできる
- TROCCO と組み合わせれば、日次バッチ処理を簡単に自動化できる
定性データ(自由記述)を定量データ(カテゴリ)に変換することで、分析の幅が大きく広がります。
ぜひ、あなたのデータパイプラインでも試してみてください。