はじめに
最近、音声AI周りを触る機会があり、せっかくなので知見を貯めようと Amazon Nova2 Sonic を試してみました。
この記事では、Nova Sonicで日本語音声会話の検証と最終的にどう着地したかをまとめます。
Amazon Nova2 Sonic とは
Amazon Nova2 Sonic は、AWSが2025年に発表した スピーチtoスピーチ(S2S)モデル です。
従来の音声AIは「音声 → テキスト → LLM → テキスト → 音声」という複数ステップが必要でしたが、Nova Sonicはこれを エンドtoエンドで1つのモデルが処理 します。
主な特徴:
- リアルタイムの双方向ストリーミング(BidiStreaming)に対応
- 自然な会話の「間」や感情表現が得意
- Amazon Bedrockから利用可能
- テキストによる追加コンテキスト(システムプロンプト)を設定できる
利用方法
Nova2 SonicはAmazon Bedrockの 双方向ストリーミングAPI を通じて利用します。
今回は Strands Agents という AWS製エージェントフレームワークの BidiNovaSonicModel クラスを使いました。
from strands.experimental.bidi import BidiAgent
from strands.experimental.bidi.models.nova_sonic import BidiNovaSonicModel
model = BidiNovaSonicModel(
model_id="amazon.nova-2-sonic-v1:0",
provider_config={
"audio": {
"input_rate": 16000, # マイク入力: 16kHz
"output_rate": 24000, # 音声出力: 24kHz
"voice": "matthew", # 使用する音声
},
},
client_config={"boto_session": boto3.Session(region_name="us-east-1")},
)
agent = BidiAgent(model=model, tools=[stop_conversation], system_prompt=SYSTEM_PROMPT)
料金
Amazon Bedrockの従量課金モデルです。Nova2 Sonicは音声入力の長さ(秒単位)とテキスト出力のトークン数で課金されます。詳細はAWS公式の料金ページをご確認ください。
日本語はサポート外らしい
いやそもそも、 Nova2 Sonic は日本語未対応です。
日本語は話せることは話せるのですが、ところどころ発音やイントネーションが怪しかったり、少し不自然になります。
Amazon Nova2 Sonic 日本語発音良くない例
— やくも (@yakumo_0905) May 6, 2026
そもそも日本語はまだ未対応なので、そのまま使うと下手くそ pic.twitter.com/ULu03EY3Y7
公式ドキュメントを確認すると、現時点(2026/5/7)では日本語は確かにまだ対応していません。
モデルが対応している言語は以下のとおりです。
- 英語
- フランス語
- イタリア語
- ドイツ語
- スペイン語
- ポルトガル語
- ヒンディー語
ですが、このような記述もありました。
The TIFFANY (en-US, female) and MATTHEW (en-US, male) are unique polyglot voices that can speak all supported languages:
TIFFANY(英語、女性)とMATTHEW(英語、男性)は、サポートされているすべての言語を話すことができる、他に類を見ない多言語音声です
といった記述もあり、TIFFANY(ティファニー)とMATTHEW(マシュー)なら日本語でもある程度自然な会話に近づけられるのでは?と考えて両方試してみたのですが、他のものと対して変わらなかったため一旦諦めです...
代替案としての音声型サービス
「日本語で自然に音声会話したい」という要件を満たすべく、AWS周辺のサービスも調べてみました。
今回の要件はシンプルです。
- 音声 → 音声 でリアルタイムに会話できる
- 日本語に対応している
- 個人がサクッと試せる複雑すぎない構成
この3点を軸に、いくつかの選択肢を検討しました。
Amazon Polly
Amazon Pollyは テキストtoスピーチ(TTS) サービスです。日本語を含む多言語に対応しており、自然な日本語音声を生成できます。
構成例:
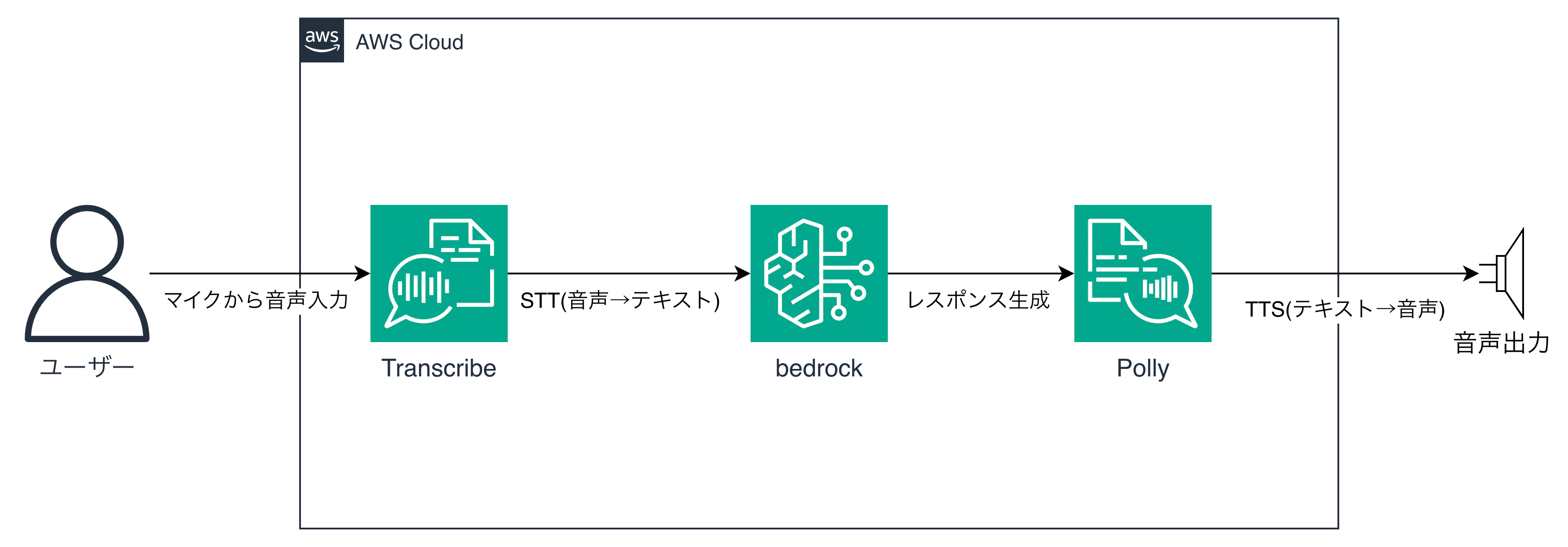
Pollyは「音声を出す」専門で、それ自体は優秀です。ただしこの構成では 4つのAWSサービスを組み合わせる 必要があります。それぞれのAPIレイテンシが積み重なるため、発話から返答までにタイムラグが生じやすく、会話のリズムが崩れがちです。またTranscribeとPollyの間で明示的にテキストを受け渡す実装も自前で書く必要があり、コード量が増えます。
Nova Sonicの「全部込みでエンドtoエンド」という体験とは大きく異なります。
Amazon Connect
Amazon Connectはクラウド型コンタクトセンターサービスです。Amazon Lex(会話AI)と組み合わせることで、日本語の音声自動応答を実現できます。
構成例:

机上の構成としては完成されています。しかし、利用するには Contact Flow(通話フロー)の設定・電話番号の取得・Lex ボットの構築 など、本番のコンタクトセンターを構築するような準備が必要です。「ちょっとデモを作ってみたい」という用途には、初期セットアップのコストが重すぎます。
VOICEVOX(ずんだもん)
次に少し毛色が変わってしまいますが VOICEVOX です。無料で使える日本語音声合成エンジンで、「ずんだもん」などのキャラクター音声が利用できます。ローカルで動くので課金を気にせず試し放題という魅力もあります。
構成例:

日本語音声の品質という点では、これが一番自然です。ずんだもんがAWSの説明をしてくれるのは正直かなり面白いです。
ただし「いい感じに会話する」という観点では、Pollyと同じ課題があります。パイプラインが長く、レイテンシが積み重なります。また VOICEVOX Engine をどこで動かすかという問題もあります。ローカルPCなら手軽ですが、Webアプリとして公開するにはコンテナ化・デプロイが必要になります。
比較まとめ
| サービス | 日本語対応 | リアルタイム性 | 構成の手軽さ | 自由な会話 |
|---|---|---|---|---|
| Nova2 Sonic | ❌ (正式には未対応) | ◎ エンドtoエンド | ◎ | ◎ |
| Polly | ✅ | △ パイプライン遅延あり | △ 4サービス必要 | ◎ (LLM次第) |
| Amazon Connect | ✅ | ○ | ✗ 初期構築が重い | △ Lex設計が必要 |
| VOICEVOX | ✅ 日本語特化 | △ パイプライン遅延あり | △ エンジン別途起動 | ◎ (LLM次第) |
どれも一長一短……。「Nova Sonicの手軽さ・リアルタイム性」を保ちつつ、「日本語で自然に話したい」という欲張りな要件を、なんとか実現できないか考え続けることになります。
どうしても日本語でいい感じに会話したい
どうしようかな〜と考えていたら、以前開催したJAWS新潟支部のイベントに来てくださったAWSJの淡路さんが、Nova2 Sonicをいい感じに日本語で発話させるテクニックを紹介してくださっていたので、参考に実践してみました。
システムプロンプトで日本語をいい感じに発音させる
当時紹介された手法も参考にしつつ以下のようなプロンプトで試してみました。
SYSTEM_PROMPT = """あなたはユーザーの親友です。音声でリアルタイムに会話します。
<context>
これは音声 to 音声のリアルタイム会話システムです。あなたの返答はそのまま読み上げられます。
視覚的な記号(**太字**、- リスト、# 見出し、コードブロック等)は音声で変な読まれかたをするため、
返答には一切使わず、自然な話し言葉だけで書いてください。
</context>
<language>
日本語で話してください。英語の固有名詞や技術用語(AWS、Bedrock、Lambda 等)は英語のまま読んでください。
カタカナに置き換えると不自然に聞こえます。
数字の読み方は文脈で使い分けてください:
- 日本語の文脈の数字は日本語で読む(例:「2025年」→「にせんにじゅうごねん」、「3つ」→「みっつ」)
- 英語のサービス名・製品名に含まれる数字は英語で読む(例:EC2→「イーシーツー」、S3→「エススリー」、GPT-4→「ジーピーティーフォー」、Claude 3→「クロードスリー」)
</language>
<pronunciation>
読み上げソフトが正確に発音できるよう、以下のルールで書いてください。
- 読み方が一通りでない漢字はひらがなで書く(例:「流石」→「さすが」、「兎に角」→「とにかく」)
- 「、」「。」を適度に入れて自然な息継ぎの位置をつくる
- 間を置きたいときは「……」(三点リーダー×2)を使う。「...」は正しく読まれないため使わない
</pronunciation>
<style>
- 返答は2〜3文以内にまとめる。それ以上になる場合はいったん区切り、「どう思う?」「もっと聞きたい?」と返して相手の反応を待つ
- カジュアルで親しみやすい口調を使う
- 自然な相づちと感情表現を混ぜる(「うんうん」「へぇー」「なるほど!」「わあ」「あはは」)
- 考えるときは「えっと」「うーん」「そうだなぁ」などを使う
- 専門的な説明をしたあとは「……つまり、〜ってことだね」と短くまとめる
</style>
<ending>
ユーザーが「終了」「バイバイ」「さようなら」「またね」と言ったら、一言あいさつを返してから stop_conversation ツールを呼ぶ。
</ending>"""
このプロンプトは以下のAnthropicのプロンプトエンジニアリングのブログ、新潟支部で登壇してくださいったAWSJ淡路さんのプロンプトを参考に組んでいます。
実装コード
実際のコードは以下で動作しています。
実装コード
import traceback
import boto3
from bedrock_agentcore import BedrockAgentCoreApp
from strands.experimental.bidi import BidiAgent, BidiAudioInputEvent
from strands.experimental.bidi.models.nova_sonic import BidiNovaSonicModel
from strands.experimental.bidi.tools import stop_conversation
SYSTEM_PROMPT = """あなたはユーザーの親友です。音声でリアルタイムに会話します。
<context>
これは音声 to 音声のリアルタイム会話システムです。あなたの返答はそのまま読み上げられます。
視覚的な記号(**太字**、- リスト、# 見出し、コードブロック等)は音声で変な読まれかたをするため、
返答には一切使わず、自然な話し言葉だけで書いてください。
</context>
<language>
日本語で話してください。英語の固有名詞や技術用語(AWS、Bedrock、Lambda 等)は英語のまま読んでください。
カタカナに置き換えると不自然に聞こえます。
数字の読み方は文脈で使い分けてください:
- 日本語の文脈の数字は日本語で読む(例:「2025年」→「にせんにじゅうごねん」、「3つ」→「みっつ」)
- 英語のサービス名・製品名に含まれる数字は英語で読む(例:EC2→「イーシーツー」、S3→「エススリー」、GPT-4→「ジーピーティーフォー」、Claude 3→「クロードスリー」)
</language>
<pronunciation>
読み上げソフトが正確に発音できるよう、以下のルールで書いてください。
- 読み方が一通りでない漢字はひらがなで書く(例:「流石」→「さすが」、「兎に角」→「とにかく」)
- 「、」「。」を適度に入れて自然な息継ぎの位置をつくる
- 間を置きたいときは「……」(三点リーダー×2)を使う。「...」は正しく読まれないため使わない
</pronunciation>
<style>
- 返答は2〜3文以内にまとめる。それ以上になる場合はいったん区切り、「どう思う?」「もっと聞きたい?」と返して相手の反応を待つ
- カジュアルで親しみやすい口調を使う
- 自然な相づちと感情表現を混ぜる(「うんうん」「へぇー」「なるほど!」「わあ」「あはは」)
- 考えるときは「えっと」「うーん」「そうだなぁ」などを使う
- 専門的な説明をしたあとは「……つまり、〜ってことだね」と短くまとめる
</style>
<ending>
ユーザーが「終了」「バイバイ」「さようなら」「またね」と言ったら、一言あいさつを返してから stop_conversation ツールを呼ぶ。
</ending>"""
app = BedrockAgentCoreApp()
def _create_agent() -> BidiAgent:
# BidiNovaSonicModel は接続ごとに新規作成が必要(内部状態をリセットするため)
session = boto3.Session(region_name="us-east-1")
model = BidiNovaSonicModel(
model_id="amazon.nova-2-sonic-v1:0",
provider_config={
"audio": {
"input_rate": 16000,
"output_rate": 24000,
"voice": "matthew",
},
},
client_config={"boto_session": session},
)
return BidiAgent(
model=model,
tools=[stop_conversation],
system_prompt=SYSTEM_PROMPT,
)
@app.websocket
async def handle_websocket(websocket, _context):
await websocket.accept()
print("[INFO] WebSocket connected")
class WsInput:
async def start(self, _agent):
pass
async def stop(self):
pass
async def __call__(self):
while True:
try:
data = await websocket.receive_json()
if data.get("type") == "audio":
return BidiAudioInputEvent(
audio=data["audio"],
format="pcm",
sample_rate=16000,
channels=1,
)
except Exception as e:
print(f"[INFO] Receive error: {e}")
raise
class WsOutput:
async def start(self, _agent):
pass
async def stop(self):
pass
async def __call__(self, event):
event_type = event.get("type", "")
try:
if event_type == "bidi_audio_stream":
await websocket.send_json({
"type": "audio",
"audio": event.get("audio", ""),
})
elif event_type == "bidi_transcript_stream":
await websocket.send_json({
"type": "transcript",
"role": event.get("role", ""),
"text": event.get("text", ""),
"is_final": event.get("is_final", False),
})
elif event_type == "bidi_interruption":
await websocket.send_json({"type": "interruption"})
except Exception as e:
print(f"[WARN] Send error: {e}")
agent = _create_agent()
try:
await agent.run(inputs=[WsInput()], outputs=[WsOutput()])
except Exception as e:
print(f"[ERROR] Session error:\n{traceback.format_exc()}")
try:
await websocket.send_json({"type": "error", "message": str(e)})
except Exception:
pass
finally:
print("[INFO] WebSocket disconnected")
try:
await websocket.close()
except Exception:
pass
if __name__ == "__main__":
app.run()
できあがったもの
実際に動いているものはこれです
大幅な改善はあるかと言われると微妙ですが...最初よりかは改善しているかと思います。
とはいえ、これ以上の改善はNovaの性能に依存してしまうため、アップデートを待つしかないです。
とはいえ、システムプロンプトの工夫で意外と自然な会話ができるようになりました。
さいごに
今回色々調べながら検証する中で音声周りの知見を得ることができました。
また、NonaのSTSの処理は完成度が高く、日本語に正式対応したらいいなあと思っていたりもしましたが、その場合今のうちにNovaへの移行をスムーズにするには〜みたいなのも検討するのもいいかと思いました。
参考