はじめに
AWSからStrands Labsというのが発表されましたね。
色々いじってみたので今回はai-functions中心に記事を書いていきたいと思います。
なお、Strands Labsには他にも以下のプロジェクトがあります。
- Robots:AIエージェントを物理ロボットと連携させるプロジェクト。NVIDIA GR00Tなどのロボットアームと統合
- Robots Sim:物理ロボット不要で動作検証できるシミュレーション環境
どちらも相当面白そうなのですが、物理ロボットが必要なため今回は断念しました。
誰かロボットを入手して試してみてください...!
ai-functionsとは
ai-functionsの公式説明を見てみると:
AI Functions let developers define an agent using natural language specifications instead of code, writing pre and post conditions in Python that validate behavior and generate working implementations.
AI関数により、開発者はコードではなく自然言語仕様を用いてエージェントを定義できます。Pythonで事前条件と事後条件を記述することで動作を検証し、動作する実装を生成します。
つまり、コードの代わりに自然言語でエージェントを定義できる仕組みです。
Pythonで事前条件・事後条件を書くことで動作を検証し、実装はフレームワーク(LLM)が生成してくれます。
もう少し核心的な考え方として、以下のような記述もありました:
A core notion of AI Functions is that programmers should not "prompt-and-pray" for the result returned by the agent to be correct.
AI関数の核心的な概念は、プログラマーがエージェントが返す結果が正しいことを「プロンプトを出し祈る」べきではないという点にある。
「プロンプトしてお祈りするな」というわけです。なかなか刺激的な言い方ですね。
従来のLLM活用では、プロンプトを調整しながら望ましいアウトプットになるよう試行錯誤(まさに"prompt-and-pray")
してきたわけですが、ai-functionsではその発想を否定しています。
代わりにPost-conditionという仕組みを使います。
LLMが返した結果が条件を満たしているかをPythonで検証し、満たしていなければ自動的にフィードバックを与えて
再試行する「自己修正型フィードバックループ」を構築します。
開発者が集中すべきは「どう検証するか」であり、実装はフレームワークに任せる、という考え方です。
ai-functionsを試してみる
セットアップ
仮想化環境での実施が推奨されているので、パッケージをインストール後仮想化をしておきます
pip install strands-ai-functions
uv add strands-ai-functions
その他AWSアカウントやモデルの認証、Strandsのセットアップも必要ですが、それは別途やっている前提で...
実際に試してみる
基本的な使い方:@ai_functionsデコレータ
AI Functionsの核心は@ai_functionデコレータです。
通常のPython関数に付けるだけで、関数のdocstringが自然言語仕様として扱われ、
LLMが実装を生成・実行してくれます。
from ai_functions import ai_function
@ai_function
def translate_text(text: str, lang: str) -> str:
"""
以下のテキストを次の言語に翻訳してください: {lang}.
---
{text}
"""
text = 'It was the best of times, it was the worst of times'
for lang in ['ja']:
translation = translate_text(text, lang=lang)
print(translation)
関数の中身は空でOKです。docstringだけ書けば、あとはLLMが実装してくれます。
Post-conditionで信頼性を担保する
@ai_functionの真価はPost-conditionにあります。
post_conditionsに検証関数を渡すと、LLMが返した結果をPythonで検証し、
AssertionErrorが出た場合はエラーメッセージをフィードバックして自動でリトライしてくれます。
from ai_functions import ai_function
from pandas import DataFrame, api
# Post-condition:返り値のDataFrameの構造を検証する
def check_invoice_dataframe(df: DataFrame):
assert {'product_name', 'quantity', 'price', 'purchase_date'}.issubset(df.columns)
assert api.types.is_integer_dtype(df['quantity']), "quantity must be an integer"
assert api.types.is_float_dtype(df['price']), "price must be a float"
assert api.types.is_datetime64_any_dtype(df['purchase_date']), "purchase_date must be a datetime64"
assert not df.duplicated(subset=['product_name', 'price', 'purchase_date']).any(), \
"The combination of product_name, price, and purchase_date must be unique"
@ai_function(
code_execution_mode="local", # LLM生成コードのローカル実行を明示的に許可
code_executor_additional_imports=["pandas.*", "sqlite3", "json"], # 使用を許可するパッケージの許可リスト
post_conditions=[check_invoice_dataframe], # ← ここでPost-conditionを指定
)
def import_invoice(path: str) -> DataFrame:
"""
The file `{path}` contains purchase logs. Extract them in a DataFrame with columns:
- product_name (str)
- quantity (int)
- price (float)
- purchase_date (datetime)
"""
ここで重要なのはcode_executor_additional_importsです。
LLMが生成したコードが使用できるパッケージを許可リスト形式で制限しており、
意図しないパッケージが実行されるリスクを抑えるためのセキュリティ設計になっています。
未知のフォーマットファイルを読み込む
私が使っていて最も面白かったのはこのユースケースです。
従来、未知フォーマットのファイルを読み込む処理を書こうとすると、以下のようなことを全部自分でやる必要がありました。
- ファイルの拡張子や中身を見てフォーマットを判定する
- フォーマットごとに変換ロジックを書く(JSON用、CSV用、Excel用…)
- LLMを使う場合はプロンプトを組み立て、レスポンスをパースし、失敗時のリトライも実装する
これが数十行のコードになりがちで、しかも想定外のフォーマットが来ると対応できません。
表にまとめると以下のイメージです。
| 従来のアプローチ | ai-functions | |
|---|---|---|
| フォーマット判定 | 自前で実装 | LLMが自動判定 |
| カラム名の揺れ吸収 | 自前でマッピング定義 | LLMが意味を解釈して対応 |
| 金額・日付のクリーニング | フォーマットごとに実装 | LLMが自動生成 |
| リトライ制御 | 自前で実装 | フレームワークが自動実施 |
| 正しさの保証 | プロンプト調整で祈る | Post-conditionで検証 |
| 新フォーマット対応 | コード追加が必要 | 原則そのまま動く |
こちらも実際に検証してみました。用意したのは以下の3ファイルです。意図的にカラム名をバラバラにしています。
| ファイル | フォーマット | カラム名 | 金額表記 | 日付形式 |
|---|---|---|---|---|
invoice_varied.csv |
CSV |
item_name, qty, PriceUSD, purchased_at
|
$9.25 |
2024/01/09 |
invoice_jp.json |
JSON |
商品名, 数量, 値段, 購入日
|
45,000 / ¥5.25
|
2024-01-11 |
invoice_excel.xlsx |
Excel |
Product, Count, Amount(USD), Date
|
$0.15 |
01-01-2024 |
これらバラバラのカラム名のデータを最終的にはすべてproduct_name, quantity, price, purchase_dateに統一したDataFrameとして受け取ることが目標です。
データの準備と実施
以下のような構成で実施しています。agent.pyを実行するとdata以下に自動的に_create_data.pyも実行され、読み込みデータも作成されます。
.
├── src/
│ └── agent.py
└── data/
└── _create_data.py
_create_data.pyでは列名ゆれ・金額表記・日付形式がそれぞれ異なる3ファイルを生成しています。
import json
import os
from pathlib import Path
import pandas as pd
def create_demo_files(data_dir: str | Path) -> list[Path]:
"""
data_dir 配下に、列名ゆれ&中身バラバラのデータファイルを生成する。
- CSV: 英語カラム揺れ(item_name, qty, PriceUSD, purchased_at)
- JSON: 日本語カラム(商品名, 数量, 値段, 購入日)
- Excel: 別名カラム(Product, Count, Amount(USD), Date)+シート名 purchases
"""
data_dir = Path(data_dir)
data_dir.mkdir(exist_ok=True)
csv_path = data_dir / "invoice_varied.csv"
json_path = data_dir / "invoice_jp.json"
xlsx_path = data_dir / "invoice_excel.xlsx"
# 既存ファイル削除
for p in [csv_path, json_path, xlsx_path]:
if p.exists():
os.remove(p)
# ----------------------------
# 1) CSV(英語揺れ + 余計な列あり)
# ----------------------------
csv_rows = [
# item_name, qty, PriceUSD, purchased_at, note(余計)
["MCU-ESP32-DEVKIT-V2", "8", "$9.25", "2024/01/09", "promo"],
["LED-5MM-RED-20MA", "200", "0.10", "2024-01-06", ""],
["CAP-ELEC-100UF-25V", "50", "0.25", "2024-01-02", "bulk"],
]
df_csv = pd.DataFrame(csv_rows, columns=["item_name", "qty", "PriceUSD", "purchased_at", "note"])
df_csv.to_csv(csv_path, index=False)
# ----------------------------
# 2) JSON(日本語カラム + 金額のカンマ/通貨文字 + 余計な列あり)
# ----------------------------
json_data = [
{"商品名": "SBC-RPI4-4GB-MODEL-B", "数量": "3", "値段": "45,000", "購入日": "2024-01-11", "通貨": "JPY"},
{"商品名": "PROTO-BB-830-TIE-PT", "数量": 20, "値段": "3.50", "購入日": "2024/01/14", "メモ": "for lab"},
{"商品名": "WIRE-JMP-MM-65PCS-KIT", "数量": "10", "値段": "¥5.25", "購入日": "2024-01-15"},
]
with open(json_path, "w", encoding="utf-8") as f:
json.dump(json_data, f, ensure_ascii=False, indent=2)
# ----------------------------
# 3) Excel(別名カラム + 日付が混在 + 余計な列あり)
# ----------------------------
excel_rows = [
# Product, Count, Amount(USD), Date, Supplier(余計)
["MCU-ARDUINO-UNO-R3-v2", 7, "24.00", "2024-01-05", "ACME"],
["TRANS-NPN-2N2222A-TO92", "150", "$0.15", "2024/01/10", "PartsCo"],
["RES-CF-10K-0.25W-5%", 100, "0.05", "01-01-2024", "Resistive Inc."],
]
df_xlsx = pd.DataFrame(excel_rows, columns=["Product", "Count", "Amount(USD)", "Date", "Supplier"])
with pd.ExcelWriter(xlsx_path, engine="openpyxl") as writer:
df_xlsx.to_excel(writer, index=False, sheet_name="purchases")
return [csv_path, json_path, xlsx_path]
実際のエージェントコードは以下です。docstringに「ファイル形式は3種類のどれか」「カラム名が異なる可能性がある」「正規化ルール」を書いておくだけで、LLMがファイルの中身を検査してフォーマットを判断し、変換コードを動的に生成してくれます。
"""
標準的なプログラミング手法では実現が難しいタスクを、
Python連携のAI Functionsを使って解決する例です。
AI Functionは、未知の形式のファイルを入力として受け取り、
動的にコードを書いて実行し、DataFrameへ変換します。
生成されたDataFrameの構造は、ワークフローの後続処理と
互換性があることを保証するため、ポストコンディション(事後条件)で検証されます。
"""
from __future__ import annotations
from pathlib import Path
from pandas import DataFrame, api
from ai_functions import ai_function
def check_invoice_dataframe(df: DataFrame):
"""ポストコンディション:DataFrameの構造を検証する。"""
# 必須カラムが含まれていることを確認
assert {"product_name", "quantity", "price", "purchase_date"}.issubset(df.columns)
# 各カラムのデータ型を確認
assert api.types.is_integer_dtype(df["quantity"]), "quantity は整数型である必要があります"
assert api.types.is_float_dtype(df["price"]), "price は浮動小数点型である必要があります"
assert api.types.is_datetime64_any_dtype(
df["purchase_date"]
), "purchase_date は datetime64 型である必要があります"
# product_name・price・purchase_date の組み合わせが一意であることを確認
assert (
not df.duplicated(subset=["product_name", "price", "purchase_date"]).any()
), "product_name・price・purchase_date の組み合わせは一意である必要があります"
@ai_function(
post_conditions=[check_invoice_dataframe],
code_execution_mode="local",
# CSV / JSON / Excel を読み込むための最低限の設定(Excelはopenpyxlが必要)
code_executor_additional_imports=["pandas", "sqlite3", "openpyxl"],
code_executor_kwargs={"timeout_seconds": 10},
)
def import_invoice(path: str) -> DataFrame:
"""
`{path}` にあるファイルには、CSV・JSON・Excel(.xlsx)のいずれか形式の購入ログが含まれています。
ファイルごとにカラム名や形式は異なる可能性があります。
タスク:
- ファイル形式に応じて読み込む。
- カラム名が異なっていても、以下の正規フィールドに対応する列を特定すること:
- product_name
- quantity
- price
- purchase_date
- 最終的に以下のカラムを持つDataFrameを返すこと:
['product_name','quantity','price','purchase_date']
正規化ルール:
- product_name: 文字列型
- quantity: 整数型(必要に応じて型変換・クリーニングする)
- price: 浮動小数点型(通貨記号やカンマを除去して変換する)
- purchase_date: datetime64型(一般的な日付形式を解析する)
- 上記4フィールドにマッピングできない行は削除する
- (product_name, price, purchase_date) の組み合わせが重複する場合は最初の1件のみ残す
"""
def _project_root() -> Path:
# src/agent.py → 親ディレクトリが src → さらにその親がプロジェクトルート
return Path(__file__).resolve().parents[1]
def _data_dir() -> Path:
# プロジェクトルート配下の data ディレクトリを返す
return _project_root() / "data"
if __name__ == "__main__":
import sys
# data/_create_data.py を import できるように、プロジェクトルートを sys.path に追加
root = _project_root()
if str(root) not in sys.path:
sys.path.insert(0, str(root))
from data._create_data import create_demo_files
data_dir = _data_dir()
data_dir.mkdir(exist_ok=True)
# data/ 配下にデモ用データ(csv / json / xlsx)を生成
filenames = create_demo_files(data_dir)
# 生成したファイルを順に読み込む
results: list[DataFrame] = []
for filename in filenames:
print(f"===== {filename.name} からデータを読み込み中 =====")
df = import_invoice(str(filename))
results.append(df)
# 結果を表示
for filename, df in zip(filenames, results):
print(f"\n===== {filename.name} の解析結果 =====")
print(df)
結果
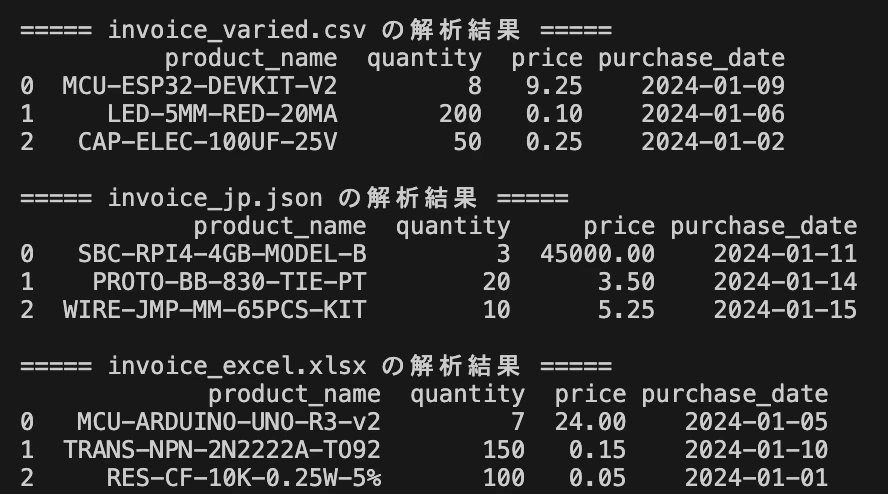
なんといい感じにぜーーんぶ変換してくれました。すごい。
以下にエージェントの実際の処理の様子をそのまま貼り付けておきます(長いので折りたたんでいます。)
ファイルをそれぞれ読み込んでよしなに処理してくれているのがわかるかと思います。
実際の処理の様子はこちら
(ai-functions) yakumoshinnosuke@yakumoshinnosukenoMacBook-Air src % uv run agent.py
===== invoice_varied.csv からデータを読み込み中 =====
ファイルを読み込んで、指定された形式に正規化したDataFrameを作成します。まず、ファイルの形式を確認して適切に読み込み、カラム名のマッピングと型変換を行います。
Tool #1: python_executor
ファイルが正常に読み込まれました。カラム名を確認すると、以下のマッピングが必要そうです:
- `item_name` → `product_name`
- `qty` → `quantity`
- `PriceUSD` → `price`
- `purchased_at` → `purchase_date`
次に、カラム名のマッピングと型変換を行います。
Tool #2: python_executor
素晴らしい!すべての必要なフィールドがマッピングできました。次に、データの型変換とクリーニングを行います。
Tool #3: python_executor
データのクリーニングが完了しました!次に、無効な行の削除と重複の処理を行います。
Tool #4: python_executor
完璧です!データの正規化が完了しました。最終的なDataFrameを返します。
Tool #5: python_executor
===== invoice_jp.json からデータを読み込み中 =====
ファイルを読み込んで、指定された正規フィールドにマッピングしてDataFrameを作成します。まず、ファイルの形式を確認して適切に読み込み、その後データの正規化を行います。
Tool #1: python_executor
JSONモジュールが利用できないので、pandasを使ってJSONファイルを読み込みます。
Tool #2: python_executor
データが読み込めました。日本語のカラム名があることが分かります。次に、各カラムを正規フィールドにマッピングして、データの正規化を行います。
Tool #3: python_executor
素晴らしい!すべてのフィールドがマッピングできました。次に、データの正規化を行います。
Tool #4: python_executor
データの正規化を進めます。価格と日付の形式を変換する必要があります。
Tool #5: python_executor
Tool #6: python_executor
Tool #7: python_executor
Tool #8: python_executor
===== invoice_excel.xlsx からデータを読み込み中 =====
ファイルを読み込んで処理を開始します。まず、ファイル形式を確認してから適切な方法で読み込み、データを正規化します。
Tool #1: python_executor
データを確認できました。各カラムを正規フィールドにマッピングして正規化を行います。
Tool #2: python_executor
価格のカラムが正しく特定できませんでした。マッピングロジックを修正します。
Tool #3: python_executor
良好です!全てのフィールドがマッピングできました。次に、データの正規化を行います。
Tool #4: python_executor
素晴らしいです!データが正規化されました。次に、データのクリーニングと重複除去を行います。
Tool #5: python_executor
データの処理が完了しました!最後に、product_nameが正しく文字列型になるように調整してから結果を返します。
Tool #6: python_executor
===== invoice_varied.csv の解析結果 =====
product_name quantity price purchase_date
0 MCU-ESP32-DEVKIT-V2 8 9.25 2024-01-09
1 LED-5MM-RED-20MA 200 0.10 2024-01-06
2 CAP-ELEC-100UF-25V 50 0.25 2024-01-02
===== invoice_jp.json の解析結果 =====
product_name quantity price purchase_date
0 SBC-RPI4-4GB-MODEL-B 3 45000.00 2024-01-11
1 PROTO-BB-830-TIE-PT 20 3.50 2024-01-14
2 WIRE-JMP-MM-65PCS-KIT 10 5.25 2024-01-15
===== invoice_excel.xlsx の解析結果 =====
product_name quantity price purchase_date
0 MCU-ARDUINO-UNO-R3-v2 7 24.00 2024-01-05
1 TRANS-NPN-2N2222A-TO92 150 0.15 2024-01-10
2 RES-CF-10K-0.25W-5% 100 0.05 2024-01-01
特に効いていると感じたのは以下の点です。
- JSONの
値段→price、商品名→product_nameといった日本語カラム名の意味解釈 -
"45,000"→45000.0、"$9.25"→9.25といった金額表記のクリーニング -
2024/01/09・2024-01-06・01-01-2024といった混在する日付形式の統一 - Excelの
Amount(USD)→priceのような意味から判断したマッピング
これらをすべて自前で書こうとすると何パターンも処理の分岐を用意することになるため、相当な量になりますが、これを使えばdocstringに「正規化ルール」を書いておくだけで処理してくれるのでとっても便利です。
ということで、この今回の検証は個人的にかなり有意義で印象的なものになりました。
この機能は他にも色々活用方法がありそうで面白いと思います。
さいごに
ai-functionsを触ってみて感じたことですが、「プロンプトしてお祈りする」時代からの脱却という方向性は非常に面白いと感じました。
内部的に詳細な処理がどうなっているのかというのが気にはなりますが、成果物の精度だけ大まかに決めてそこに向けて検証を重ねながら、エージェントのループをガンガン回すのはStrandsの思想に合っていそうです。
今後もアップデートに期待しつつ色々試していこうかなと考えています!
参考