はじめに
今回はRAGについて徹底的に深掘りして解説する記事にしたいと思います。
今でこそRAGは身近な存在になりつつありますが、いざ中身の詳しい仕組みを解説してくれとなると、少し詰まる方もいるのではないでしょうか。
本記事ではRAGのそういった仕組みをAWSも事例にあげつつ解説していきます。
RAGとは
RAGというのは、検索拡張生成のことです。英語で言うと(Retrieval-Augmented-Generation)の頭文字を取ってRAGとなります。
従来のLLMの課題
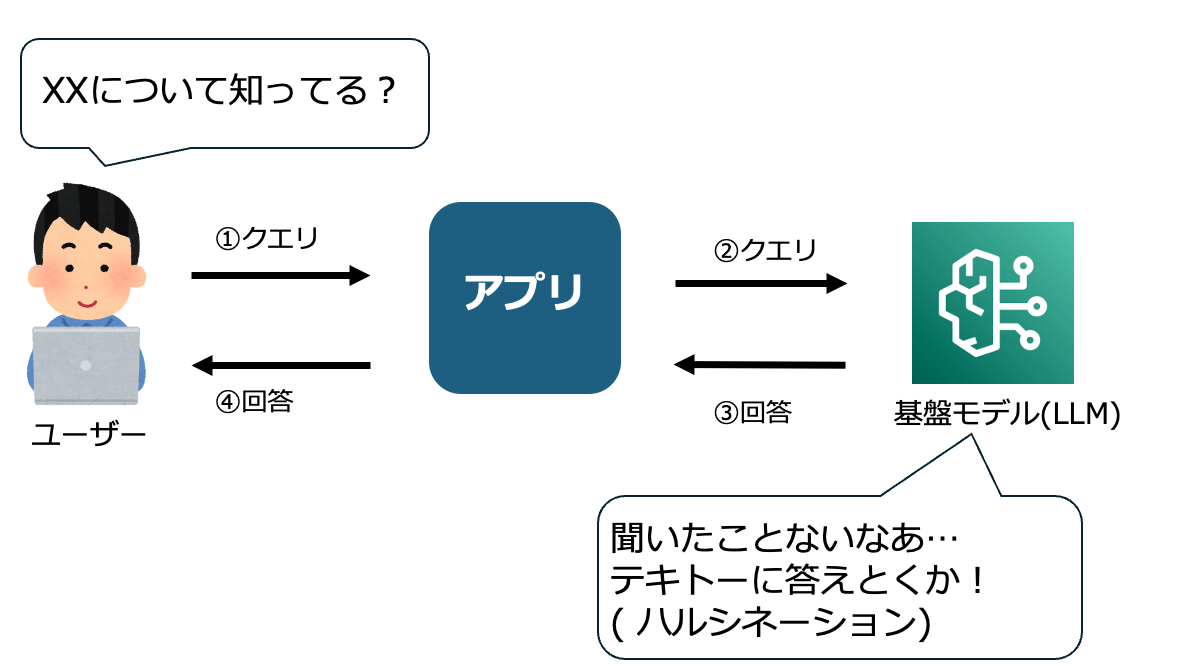
RAGを選択する理由として、従来の単一のLLMの課題として独自データへの対応の難しさがあります。
基盤モデルは学習データに含まれていないような情報は回答できません。
場合によってはハルシネーションを含んだ回答をするケースもあります。
独自データの活用方針
基盤モデルはそのモデルの学習時点での知識しか持っていないため、最新の情報や社内文書などの独自データに対する問い合わせにハルシネーションを起こしてしまうことがあります。
ファインチューニングとRAG
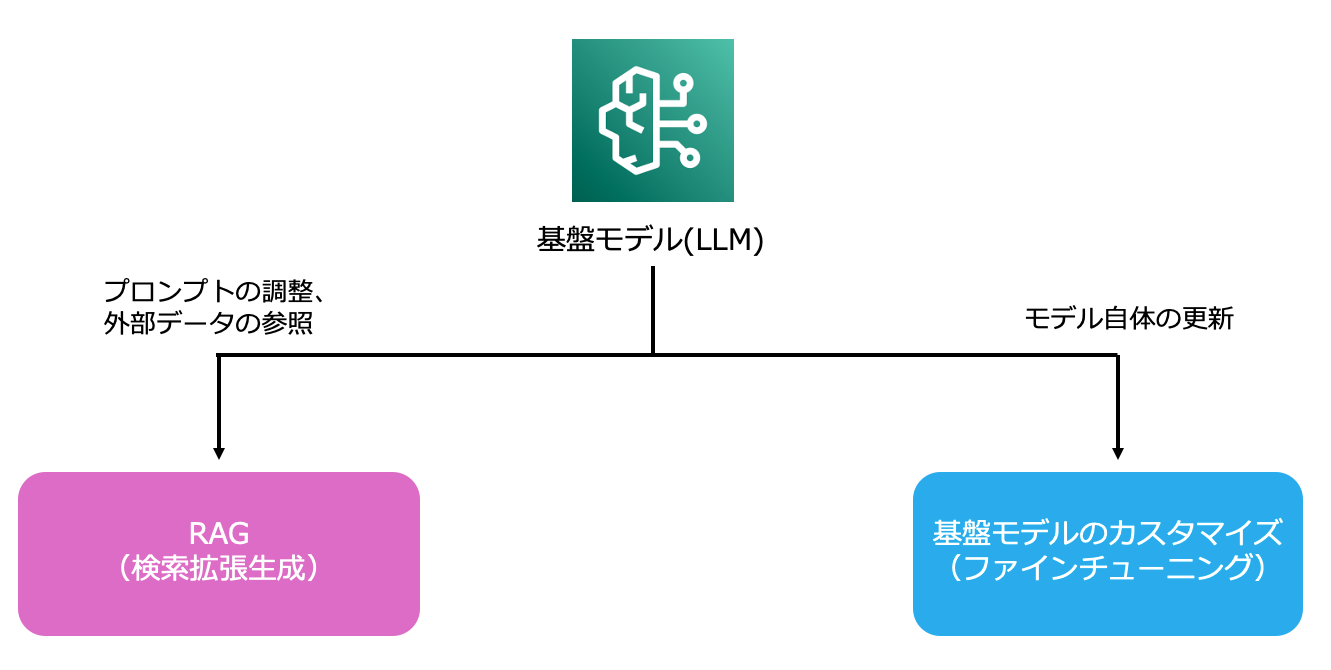
上記のような課題を解決するための手段として以下の2つがあります。
1.ファインチューニング
2.RAG
ファインチューニングは、既存のLLMに追加の学習を行い、特定のドメインや用途に最適化させる方法です。
使い方によっては高い効果があり、たとえば専門用語が多い業界文書や独自ルールがある会社の手順書などに対して、モデルそのものを「その業務に詳しい状態」にできます。
ただし、実際に業務で使おうとすると、いくつかの悩ましいポイントが出てきます。
- 学習データの準備に手間がかかる
- データ更新のたびに再学習が必要
- インフラやコストが重くなることが多い
- モデルが覚えた情報を後から消すことが難しい
つまり、一度学習させると調整や修正が重くなりやすく、運用面での負担が大きくなりがちです。
RAGは、モデルの外側にナレッジ(ドキュメントやデータ)を置き、必要な情報だけを検索で取り出して答えに反映させる仕組みです。
モデル自体を変えないため、データの差し替えが簡単で、情報の鮮度を保ったまま回答に反映できます。
特に以下のような点が、実務で強い武器になります。
- ドキュメントを更新するだけで改善できる
- 機密データをモデル内部に学習させないので安全性が高い
- 目的や扱う情報が変わっても柔軟に組み替えられる
- コストと開発スピードのバランスが良い
といった比較をしてみるとRAGはコスパよく正確な回答を得られるようカスタマイズできるようになっています。
なぜRAGを選択するのか
RAG(Retrieval-Augmented Generation)は、LLMが本来持っている知識だけに依存せず、外部のデータソースを参照しながら回答を生成する仕組みです。
一般的なワークフローは次の図のようになっており、LLM単体ではカバーしきれない質問にも、独自データを用いて柔軟に対応できます。
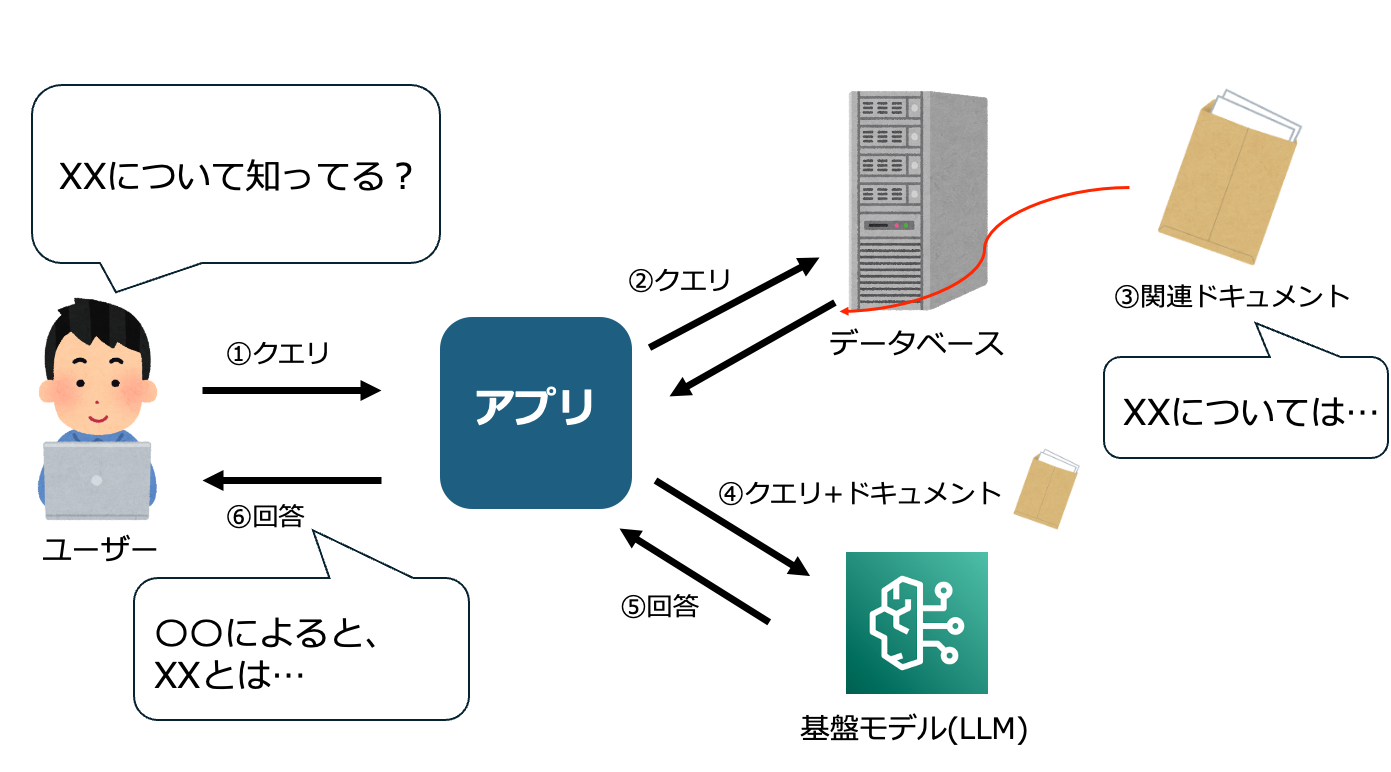
RAGを採用するメリットとして、特に次の3点が大きく効いてきます。
1.ハルシネーション(幻覚)の低減
LLMが推測で答えてしまうのではなく、外部データベースから取得した正確な情報をもとに回答を組み立てます。
もちろん完全にゼロにはできませんが、誤回答のリスクを大幅に下げられます。
2.社内固有の知識への対応
一般的なLLMには当然、企業固有の情報は学習されていません。
しかしRAGであれば、
- 社内文書
- 内部Wiki
- マニュアル
- 規定・ルール
などをデータベースに登録しておくことで、自社特有の文脈に沿った回答が可能になります。
3.最新情報への対応
LLMの学習は過去のタイミングで固定されますが、RAGはデータを更新すれば即反映されます。
- 最新のガイドライン
- 変更された規定
- 更新されたマニュアル
- 毎日増える業務データ
など、学習後に発生した情報にも柔軟に対応できます。
RAGはこのように、LLMの「得意なところ」を活かしつつ、「苦手なところ」を補うアーキテクチャです。
特に、正確性が求められる企業システムにおいては、最新情報・固有情報に基づく回答ができる点から、RAGは欠かせない技術となりつつあります。
そして、RAGの中核となるのが、データソースから“意味的に近い情報”を取り出すための仕組みです。
この「似ている情報を引っ張ってくる」仕組みにベクトル検索というものが使われています。
ベクトル検索の仕組みについて
RAGの中核となるのが、ユーザーの質問に“意味的に近い”文書を取り出すための仕組みである ベクトル検索です。
通常の検索(キーワード検索)は「文字列が一致しているか」で探しますが、ベクトル検索は意味の近さを数値として扱える のが最大の特徴です。
イメージしやすいように、まずは図で見てみます。
ベクトル検索の基本イメージ
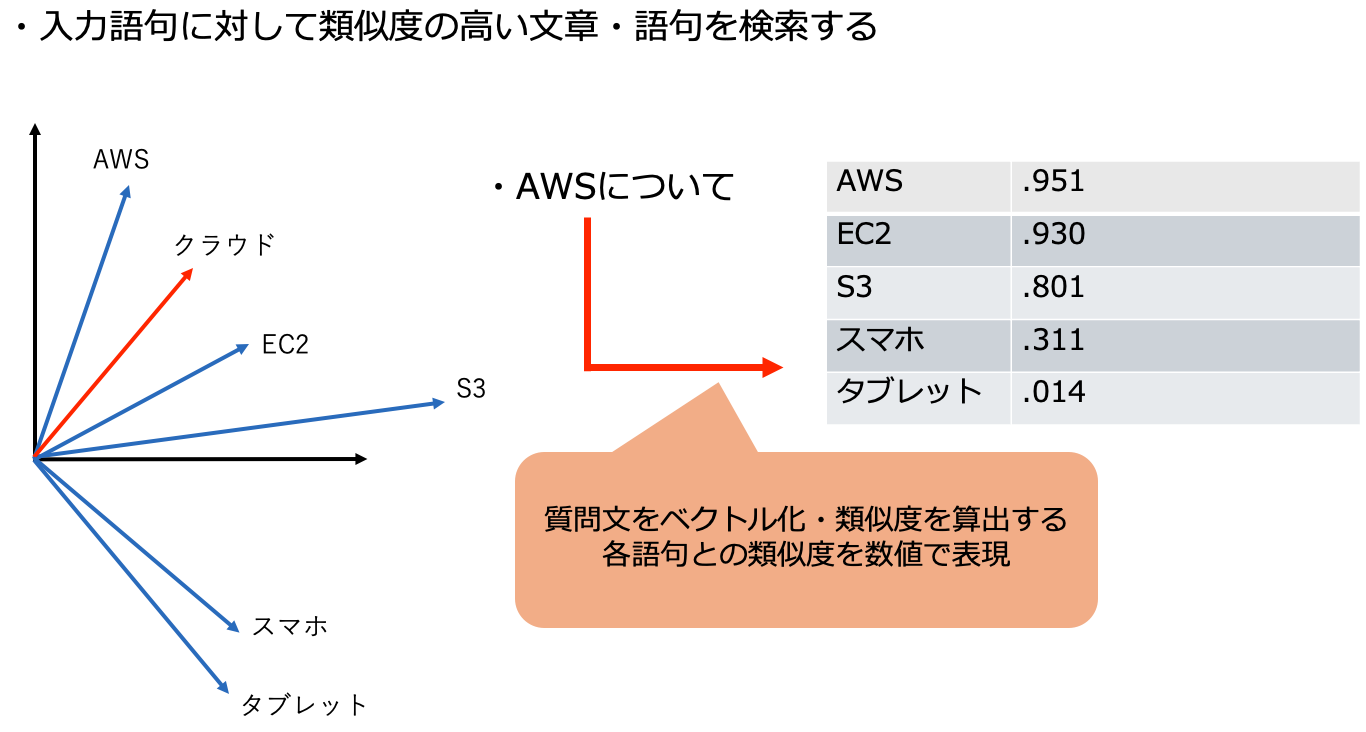
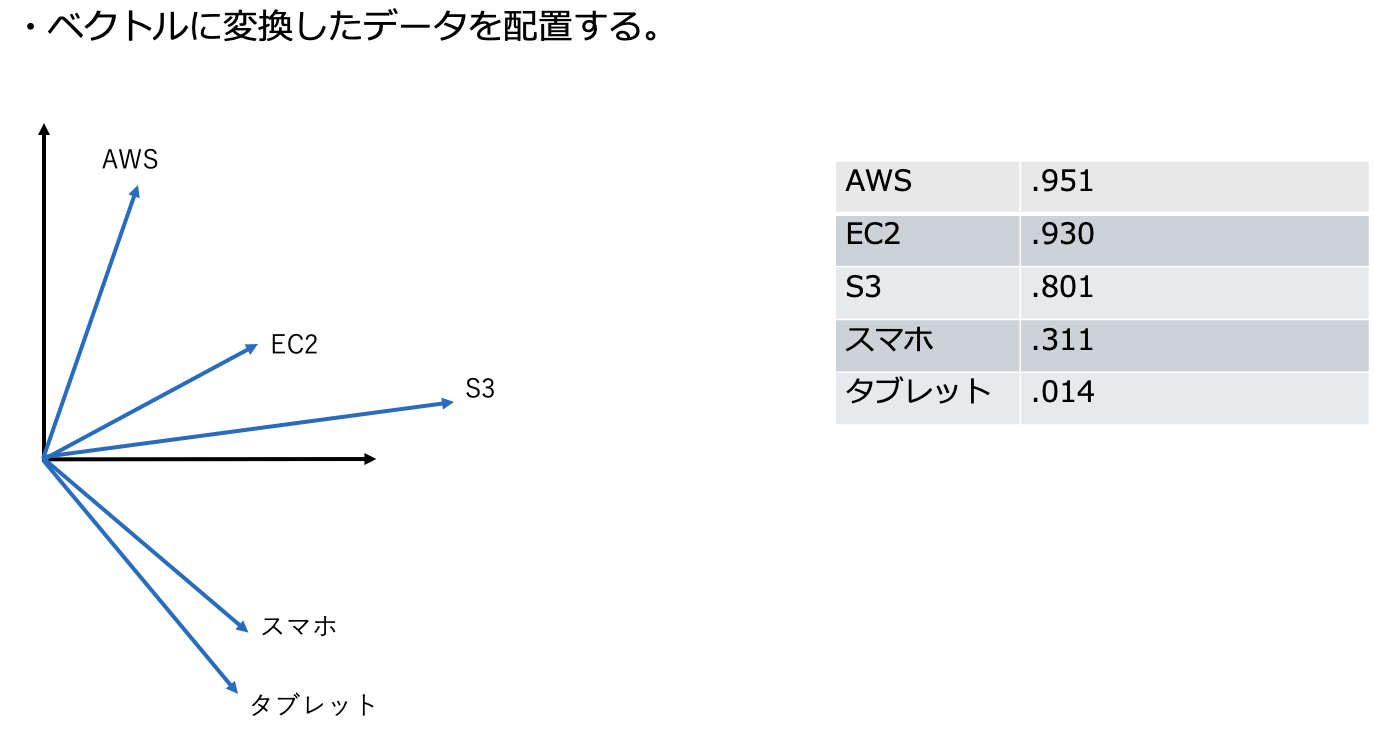
以下は、文章や単語を「ベクトル(数値の集合)」として空間にマッピングした図です。
例:
「AWS」「クラウド」「EC2」など関連する単語が近く、
無関係なものは階層的に離れた場所に配置される。
1. 文章を「ベクトル」に変換する
まず、文書やテキストはそのままでは計算できません。
そのため、Embedding(埋め込みモデル) を使って文章を数値ベクトルに変換します。
「EC2とは仮想サーバーのことです」
↓ 埋め込み変換
[0.12, -0.88, 0.34, ... , 0.03] ← 数百〜数千次元のベクトル
LLMとは別に、埋め込み専用のモデルがあり、文章の意味を捉えた数値を返します。
2. ベクトルをデータベースに保存する
変換されたベクトルは、OpenSearchやS3 Vectors、Pineconeなどの
ベクトルデータベース に保存されます。
図で表すと、次のように似通った文章が近い座標に点として空間に配置されます。
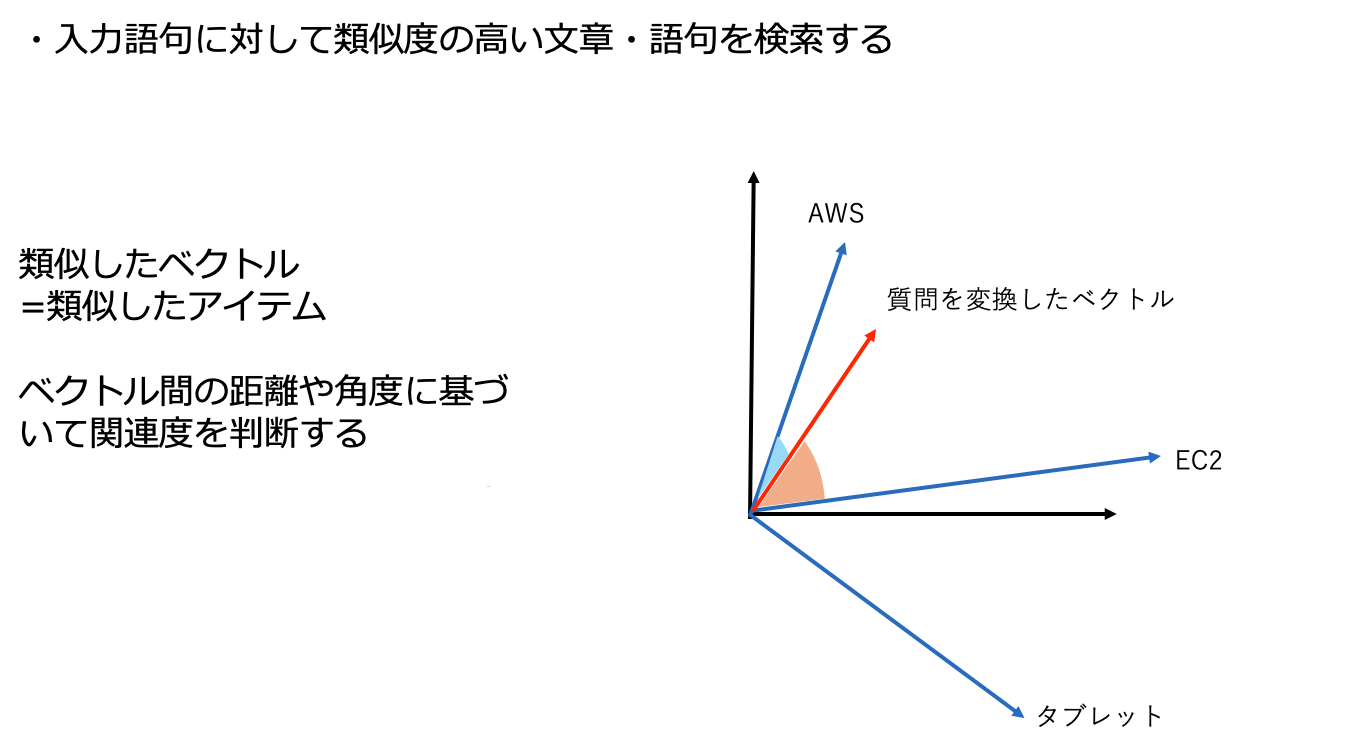
3. ユーザークエリもベクトル化し、「距離」を測る
ユーザーが質問すると、その質問も同じようにベクトルに変換されます。
「EC2の料金の仕組みを教えて」
↓ Embedding
[0.11, -0.91, 0.40, ... , 0.00]
次に、質問ベクトルに最も近い文書ベクトルを探す という処理が行われます。
4. 意味が近い文書を取得する(類似度計算)
ベクトル同士の距離(類似度)は、コサイン類似度などで計算されます。
- 距離が近い → 内容が似ている
- 距離が遠い → 内容が違う
図のように、質問に近い位置にある文書が検索結果として返されます。
5. LLM が検索結果を踏まえて回答を生成する
取得した関連文書をLLMに渡し、回答の材料として利用します。
ユーザー質問
+
関連ドキュメント(ベクトル検索で取得)
↓
LLMが根拠に基づいた回答を生成
RAGがLLMの限界を補えるのは、ベクトル検索によるこの意味検索が実現できるからです。
Amazon Bedrock Knowledge Basesについて
ここまで説明してきたように、RAG では「データの収集 → ベクトル化 → 検索 → 回答生成」という一連の流れを自前で構築する必要があります。
しかし、実際にはこの仕組みをゼロから作るのはかなり手間がかかります。
- 埋め込みモデルの選定
- ベクトルデータベースの構築
- データの同期(更新検知・再インデックス)
- セキュリティやIAM設定
- LLMとの統合まわりの実装
これをすべて自社で運用するのは、時間もコストも大きくなりがちです。
ですが、Amazon Bedrock Knowledge Basesを使うと、これまで紹介したRAGの仕組みをフルマネージドに簡単に利用することができます。
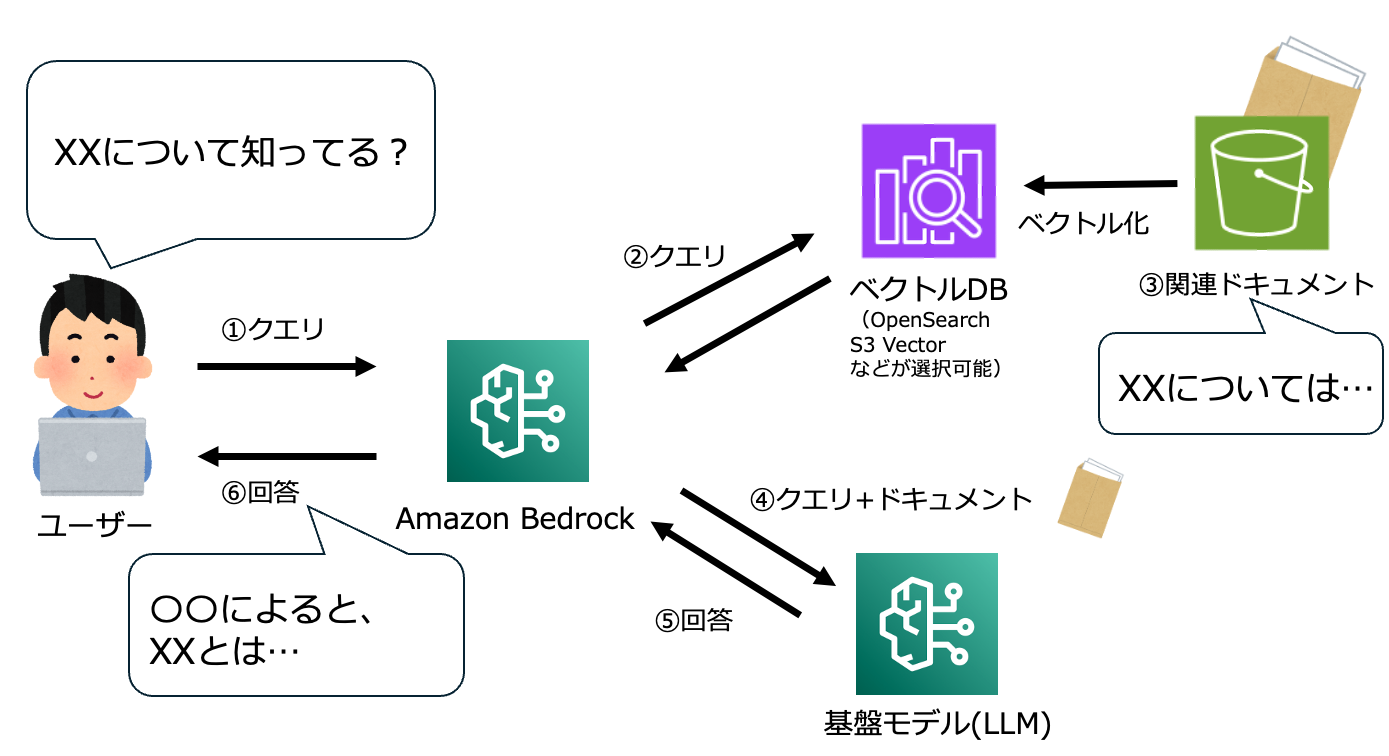
Amazon Bedrock Knowledge Basesの動作イメージ
Amazon Bedrock Knowledge Basesを利用することで、以下のように、LLMと独自データソースを組み合わせたRAG (検索拡張⽣成)をフルマネージドに実現可能になります。
デモ
Amazon Bedrock Knowledge Basesはコンソールから数クリックで簡単に構築が完了し、利用が可能になります。
Bedrockのコンソールから「ナレッジベース」を選択し、「ベクトルストアを含むナレッジベース」新規作成します。
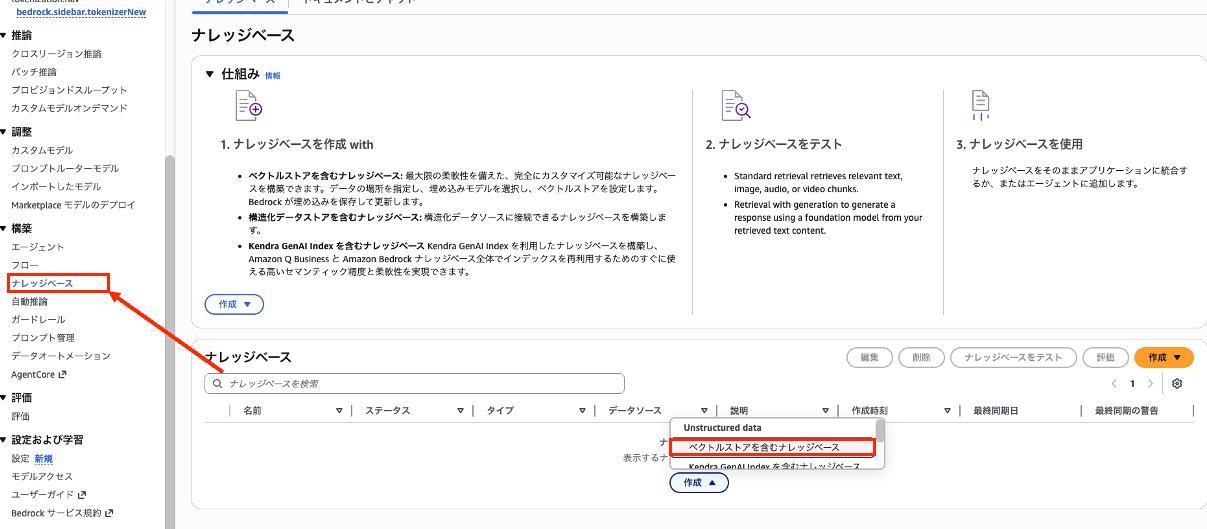
今回S3に対象データを追加するため、データソースにS3を選択します。
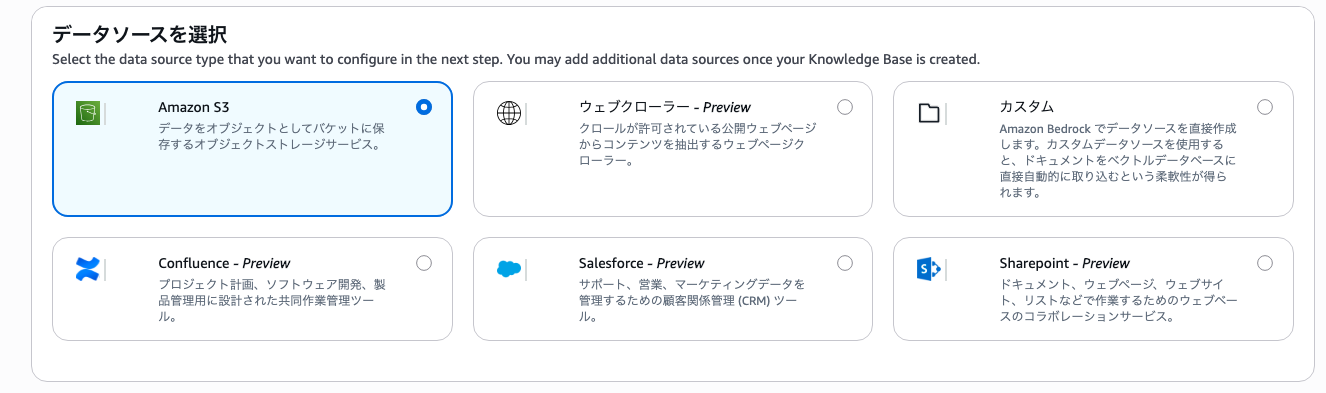
埋め込みに利用する埋め込みモデルを選択します。
基本的にどれを選んでも大きな差異はありません。
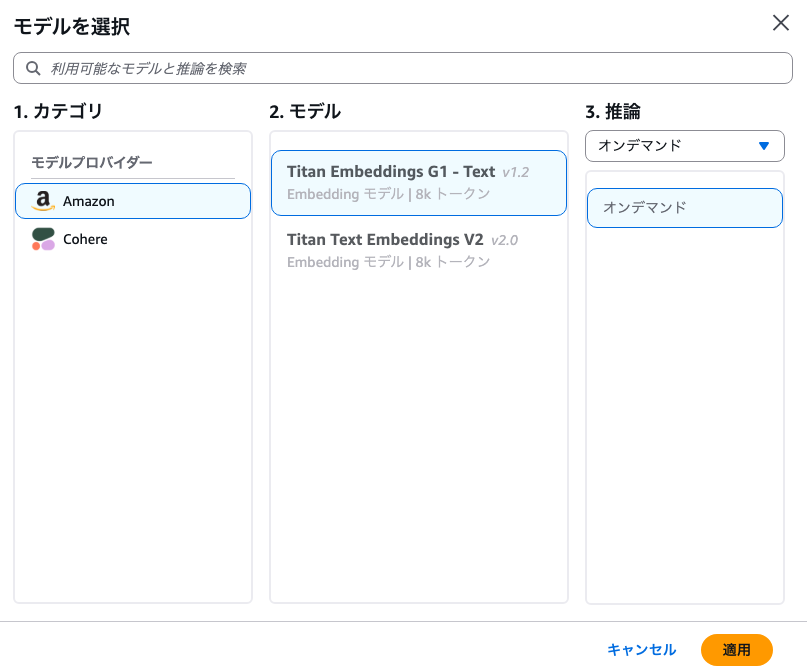
データソースを変換したベクトルデータを保存するベクトルDBを選択します。
従来はOpenSearchを選ぶことが多かったですが、最近になりS3 Vectorsが選択可能になりました。
レスポンススピードはOpenSearchに劣りますが、S3依存のコストでとりあえず試すくらいならS3 Vectorsで問題ないと言えます。
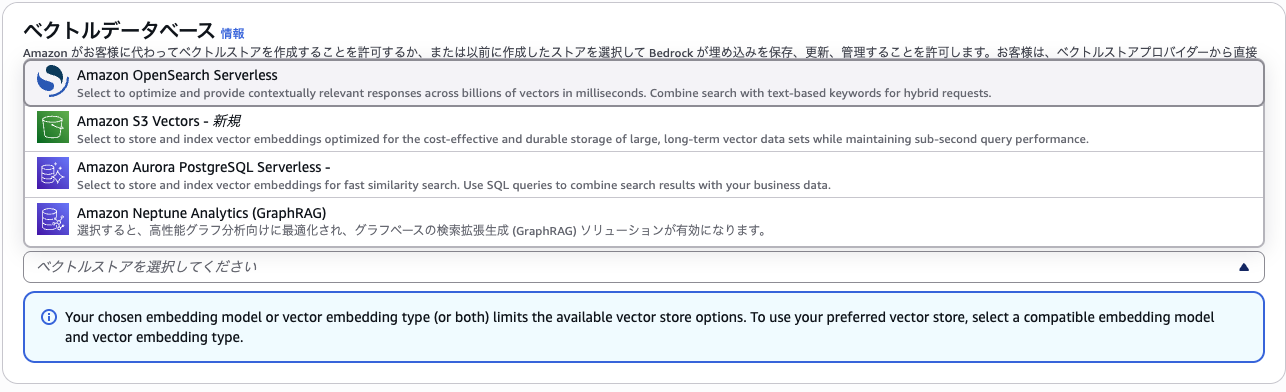
ナレッジベースの動作イメージは過去記事に書いているのでよければご覧ください。
応用:リランキング、チャンキングについて
RAGでは、単に「大量の文書をそのままベクトル化&検索 → LLM に投げる」というだけでは、以下のような問題が起こりやすいです:
- ドキュメントが長すぎると、一部分しか関連しないのに “余計な文脈” が混じってしまい、ノイズの多いコンテキストで回答される
- 質問と “部分的には関連する複数のチャンク” が検索されて返ってきてしまい、どれを根拠にすべきか判断があいまい
- ベクトル検索だけだと「ある程度似ている」チャンクが取れても、実際の“質問への最適な答え”とはズレがある
つまり、「どう文書を切り分けて検索対象にするか(チャンキング)」「取得したチャンクのなかからどれを重視するか(リランキング)」 を工夫しないと、RAGの精度は思ったほど上がらない可能性があります。 
チャンキングの仕組み
ナレッジベースはドキュメント取り込み時に、自動的にチャンク(小さなテキスト単位)に分割してから埋め込み、ベクトルデータベースに登録します。これを チャンキング と呼びます。
様々なチャンキング戦略
Bedrock では以下のような戦略が選べます。
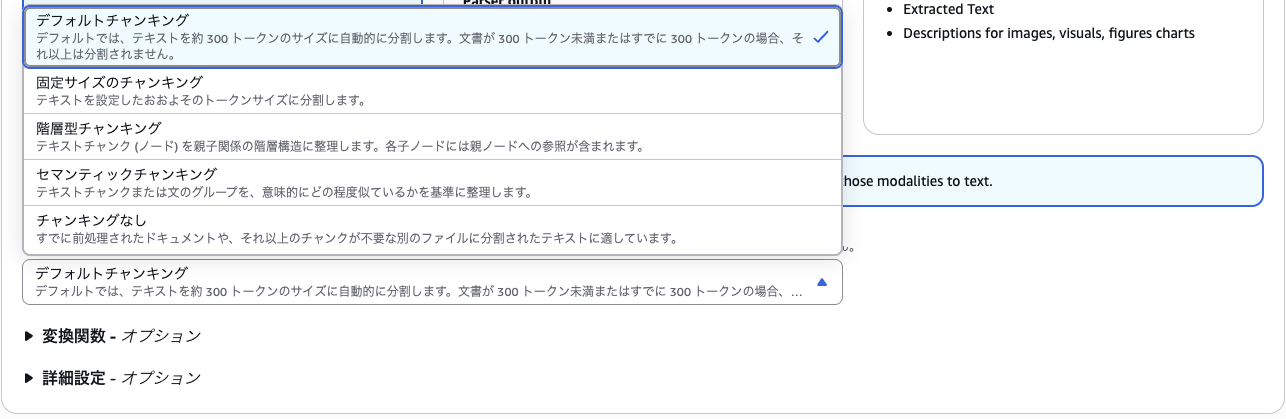
検索の精度を向上させるためには、適切なチャンクサイズとオーバーラップの設定が重要です。
長いドキュメントを適切に分割し、重なりを持たせることで、より精度の高い検索結果を得ることができます。
チャンクとオーバーラップについて解説しておきます。
チャンク
RAG では、長いドキュメントをそのまま検索対象にすると精度が落ちるため、まず 適切な大きさのテキスト断片(チャンク)に分割する 必要があります。
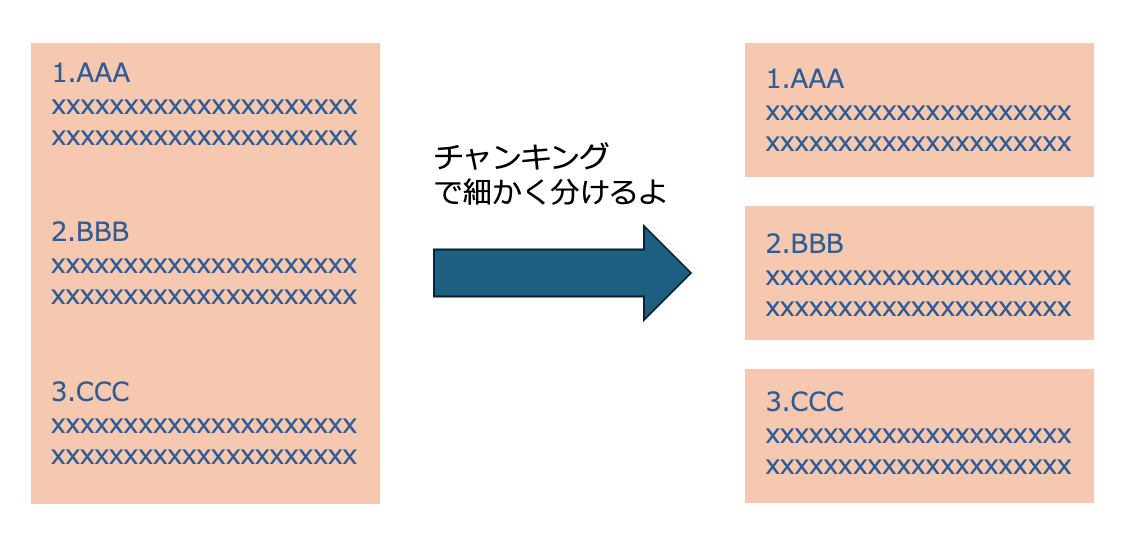
チャンクは LLM に渡す「根拠の最小単位」であり、これが正しく設計できていないと、検索にノイズが混ざったり、必要な情報が切り落とされたりしてしまいます。
この区切る範囲(チャンク数)が大きすぎると、LLMに渡す文章内容が広くなりすぎ、検索時に関係ない内容までも引っかかってしまいます。
逆に小さすぎると文脈のまとまりが失われ、LLMが正しい判断をしづらくなります。
オーバーラップ
チャンク分割の際、前のチャンクの末尾部分を次のチャンクに少し重ねて含める ことがあります。これをオーバーラップ と呼びます。
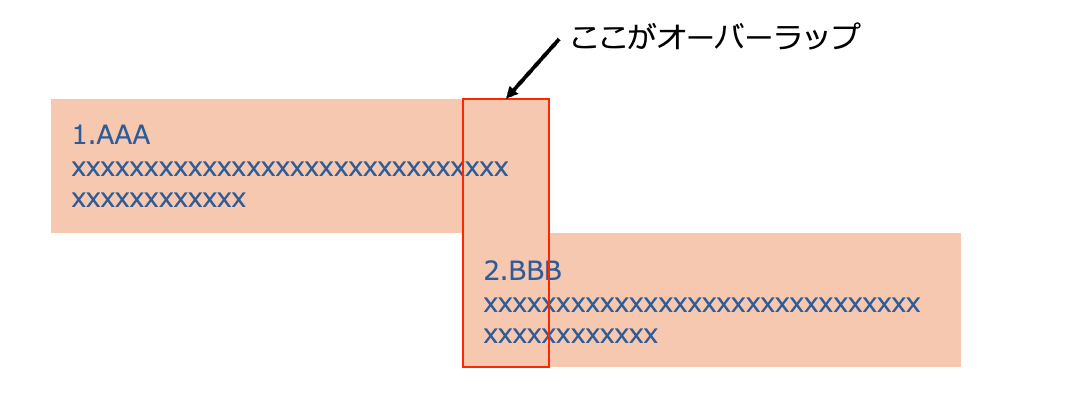
文章は必ずしも「区切った場所」で意味がきれいに分かれるわけではないため、オーバーラップを入れることで次のような効果があります:
- 文脈の連続性を保てる
- 文の途中で分断されても、両方のチャンクに必要な情報が残る
- 質問との類似度検索で “落ち漏れ” が減る
Bedrock Knowledge Basesで高い精度を出すには、このようなチャンキング設定が重要になってきます。
各チャンキング戦略の概要
Bedrockでサポートされているチャンキング戦略ですが、以下のようなものがあります。
- デフォルトチャンキング — おおむね 300 トークン前後のチャンクに分割
- 固定サイズチャンキング — 任意のトークン数(例:500/1000など)でチャンクを切る
-
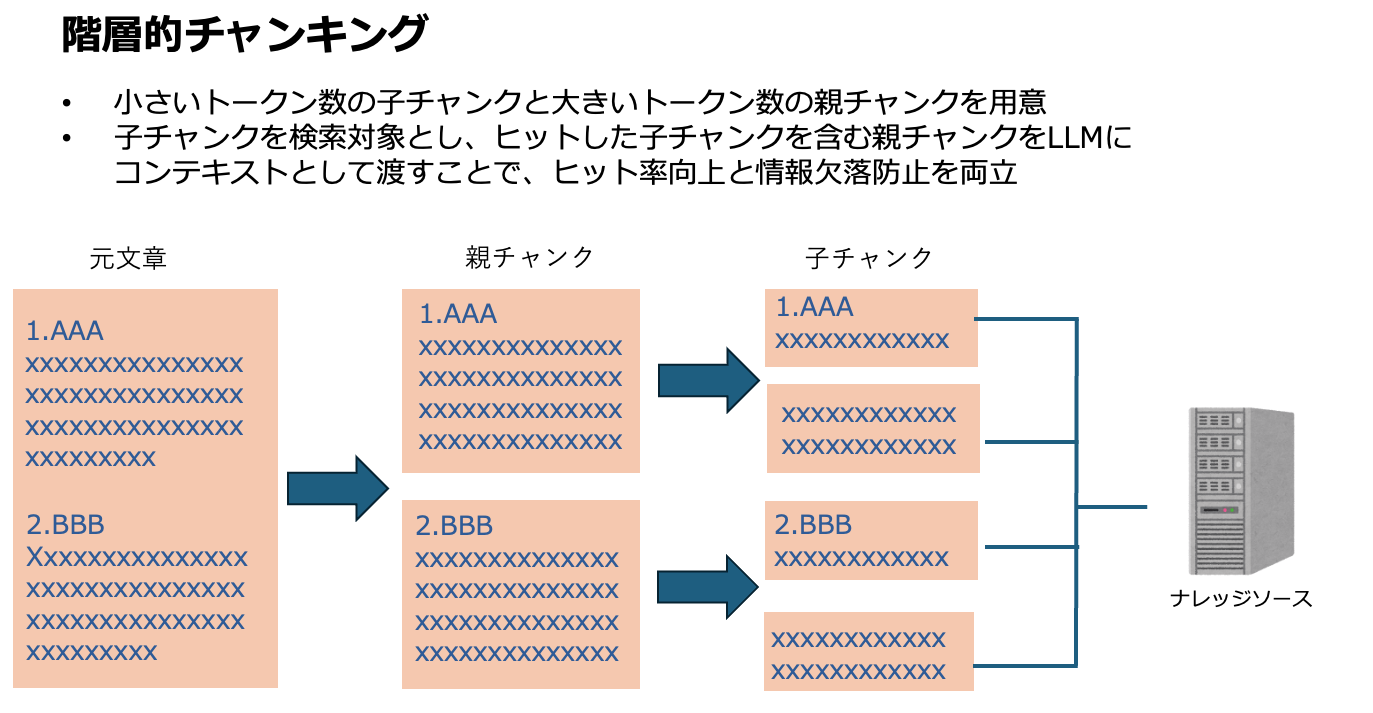
階層的チャンキング — 「親チャンク/子チャンク」の二段構造で分割。検索対象としては“子チャンク”、しかしLLMに渡すときは“親チャンク”を使う、というスタイルで、“関連性” と “文脈のまとまり” のバランスをとることができます。
また、親チャンクと子チャンクのトークン数を個別に設定することもできます。
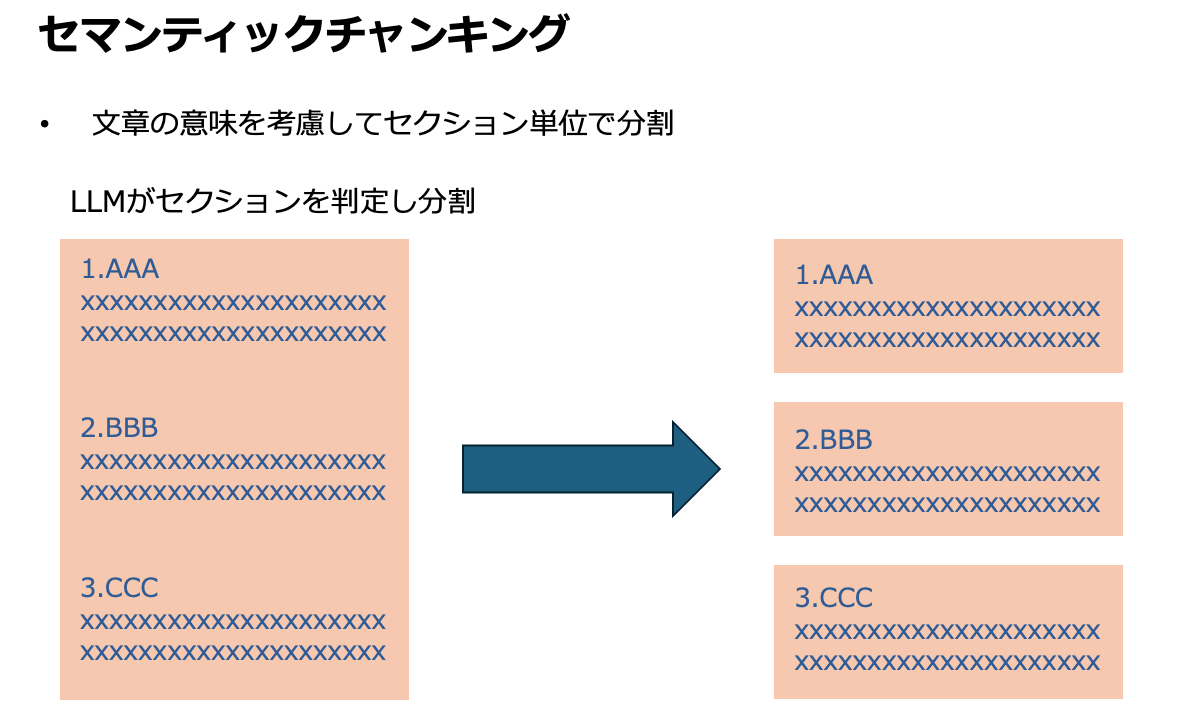
- セマンティック(意味的)チャンキング — 単に文字数/トークン数ではなく、LLMが内容の意味・構造に応じて「意味のまとまり」でチャンクを切る方式。文章を文ごとに分割 → 近い意味の文をまとめる、などの方法。 
チャンキングを工夫する理由
RAG の精度は「文書をどう分割するか」に大きく影響されます。
チャンクが適切でないと、検索精度が落ちたり、LLM に渡す情報がノイズだらけになったりします。
チャンキングを工夫する主な理由は次のとおりです。
- 適切にチャンク化することで、「検索対象を小さく・精度良く」できる → 検索のノイズを減らす 
- 長文ドキュメントでも、「必要な部分だけ」を効率良く取り出せる
- 階層型などを使えば、「細かいチャンクで検索 → 文脈保持のために親チャンクを渡す」といった柔軟な構成が可能
つまりチャンキングは、「検索の正確さ」を決める土台となる重要な工程です。
適切なチャンク設計ができていれば、その後のリランキングや RAG 全体の品質も大きく向上します
リランキングとは
チャンキング以外にもリランキングといった手法もあります。
ベクトル検索のみを使うと、たとえ「意味的に近い」チャンクが上位に来ても、必ずしも「質問にとって最適な根拠」になっている保証はありません。
リランキングは、最初の検索で得られたチャンク候補を、さらに “重要度/関連度の観点で再評価して順序を付け直す” 処理です。これにより、LLMが受け取る「根拠コンテキスト」の品質を上げられます。
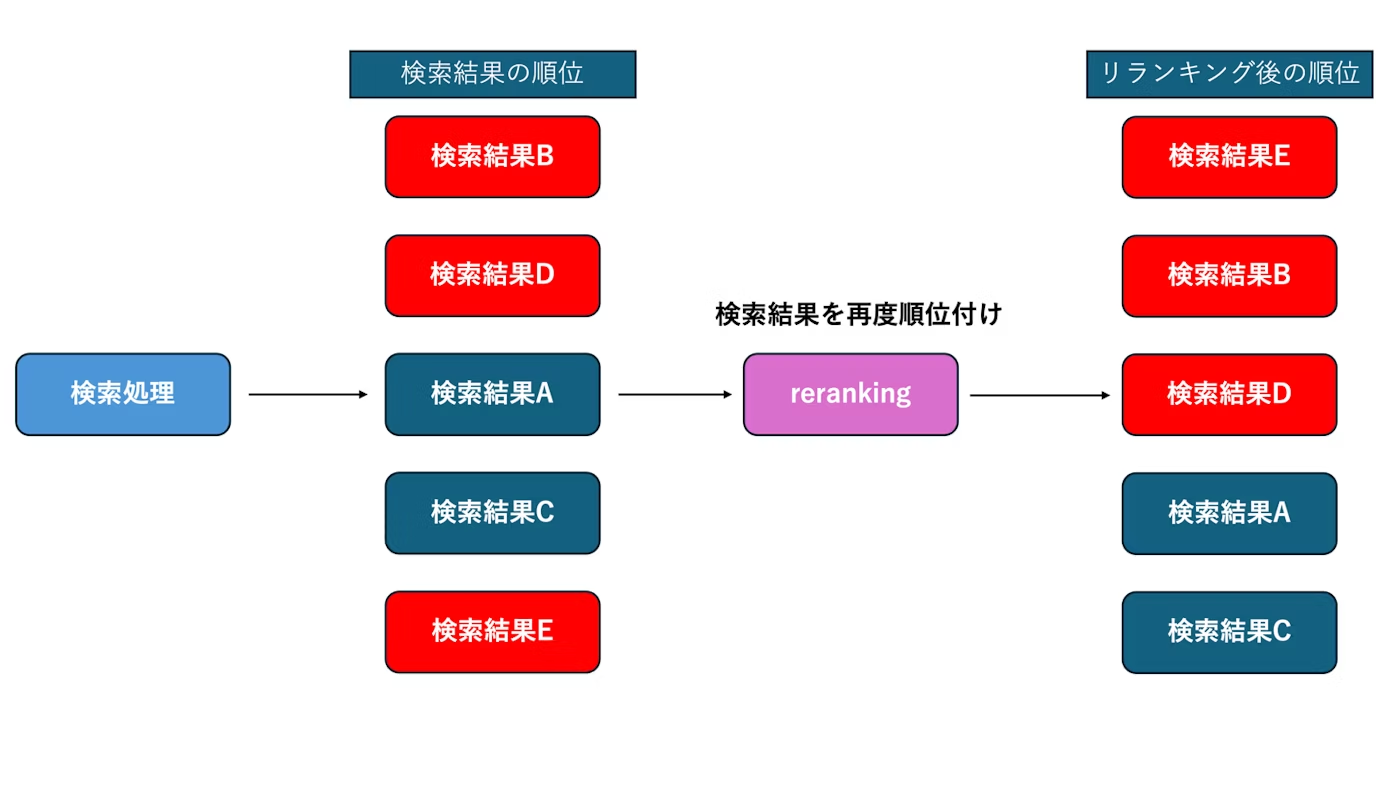
具体的なイメージは上の図のようになります。:
1.ベクトル検索で Top-K(上位何件か) のチャンクを取得
2. 各チャンクに対して “どれが質問に最も適しているか” を評価するリランキングモデルを使って順序付け
3. 上位チャンクのみを選び、LLM に渡す
こうすることで、不要な情報を削ぎ落とし、より関連性が高く、ノイズの少ないコンテキスト を使って回答生成できます。
チャンキング+リランキングを実施する価値とは
特に企業ドキュメント・マニュアル・規定など「正確性が求められる情報」を扱う場合、この工程をしっかり設計することはとても重要です。
1. チャンキングの価値:必要な部分だけを正確に検索できる
文書を適切なサイズに分けることで、
- 検索が細かくなり、関連する部分を正しく取り出せる
- LLM に渡すコンテキストからノイズが減る
といったメリットが生まれます。
特に企業文書のように長い資料では、チャンキングが精度の土台になります。
2. リランキングの価値:検索結果から“本当に必要な根拠”を選べる
ベクトル検索だけでは「似ているけれど回答に最適ではない」チャンクが混ざることがあります。リランキングは取得したチャンクを再評価し、
- 最も回答に役立つ順に並び替える
- 不要なチャンクを排除する
ことで、LLM に渡す情報の質を高めます。
3. セットで使うことで回答の安定性が大きく向上
- チャンキングで 検索対象を適切な粒度に整理
- リランキングで 最適な根拠だけを選択
この2つが組み合わさることで、
誤回答が減り、根拠に基づいた安定した回答を返せるようになります。
Bedrock Knowledge BasesでもRAGの精度向上において非常に重要なステップとなっています。
さいごに
今回はRAGそのものの解説から、AWSにおけるナレッジベースの解説まで踏み込んで行いました。
これから入門する方や、改めて確認しておきたい方の役に立てば嬉しいです。
参考