はじめに
RAGを利用する際、「一般職と管理職で、同じ質問に対して返ってくる情報を変えたい」といった要件要望があるかと思います。これをAWSのマネージドサービスだけでフルサーバーレスで作れないかなと思って試してみました。
例えば「山田太郎の電話番号を教えて」と聞いたときに、
- 管理職には
090-1234-5678を返す - 一般職には「権限により参照できません」を返す
みたいな挙動です。本記事では実際に作ったシステムについて解説していきます。
また、実際に作ったものは以下のリポジトリにありますのでよければどうぞ〜
RAGを運用する上での懸念点
社内データでRAGを運用するときに必ず出てくる懸念点を整理しておきます。
| 懸念点 | 概要 | 本構成での対策 |
|---|---|---|
| ハルシネーション | LLM が事実と異なる情報を生成 | KB検索結果をシステムプロンプトで「権威ある情報源」と明示して、LLM単独の知識ではなく検索結果から回答させる |
| 機密情報の漏洩 | 権限のないユーザーに見せちゃいけない情報が応答に混入 | 本記事の中心テーマ。次節で詳述します |
| 検索精度 | 質問とドキュメントのベクトル類似度が低いと正解が引けない | Titan Embeddings v2(1024次元)+ Bedrock KB の自動チャンク(300トークン)で標準的な精度を確保 |
| コスト爆発 | 大量のドキュメントを Ingestion すると埋め込み生成コストが膨らむ | 子S3への書き込み時にだけ Ingestion を起動する設計で、不要な再生成を抑制 |
| ドキュメント更新の反映遅延 | 元データの修正がエージェントの回答に反映されるまでに時間がかかる | S3 イベント駆動で Ingestion を自動起動。手動操作なしで3〜5分で反映 |
| 監査・コンプライアンス | 誰がいつどの情報を見たかを追跡できない | CloudWatch Logs に Agent の応答ログ、CloudTrail に Bedrock API 呼び出しを記録 |
センシティブなデータの取り扱い
今回のテーマである「機密情報の漏洩」について、もう少し掘り下げます。
3段階の防御
ロールベースマスキング RAG では、漏洩を防ぐために3段階の防御を組み合わせています。
1段目:物理的なデータ分離
親S3にアップロードされた原本データを、Lambdaが以下の2系統に分岐させて保存。
- 子S3 (masked):Amazon Comprehend で PII を検出し
[REDACTED:TYPE]に置換した版 - 子S3 (raw):原本そのまま
それぞれが独立したS3バケットに保存されるので、ファイルシステムレベルで分離されています。
2段目:KB と Vector Store の分離
子S3 (masked) を参照する Bedrock KB と、子S3 (raw) を参照する Bedrock KB を完全に別リソースとして作ります。それぞれが独自のS3 Vectorsインデックスを持ちます。
最初は「1つのKBにメタデータフィルタでmasked/rawを切り替えればいいかな」と思ったんですが、コードのバグやプロンプトインジェクションで不正にrawデータに到達されたら終わりです。KBを物理的に2つに分けておけば、IAMレベルで権限境界を引けます。
3段目:IAM による権限境界
AgentCore Runtime の実行ロールには両方のKBへの bedrock:Retrieve 権限を付与しているんですが、エージェントコード内でJWTのロール判定をして、参照先KB IDを切り替えています。
kb_id = KB_ID_RAW if role == "manager" else KB_ID_MASKED
もっと厳格にするなら、ロール別に AgentCore Runtime を完全に分けてIAMレベルで分離することもできます。
今回は運用負荷を考えて、1つの Runtime + コード判定にしました。
マスキングできなかった時のフェイルセーフ
Comprehend の検出漏れで PII がマスキングされなかったとしても、一般職ユーザーには masked KB のデータしか渡りません。
マスキング処理が不完全でも「raw データそのものは渡らない」って設計になってるので、最悪のケースでも raw KB に保存されてる原本データが一般職に流出することはないです。
構成図
構成図は以下のようになっていて、クエリの流れ(上)とデータ取り込みの流れ(下)の2系統で動いています。
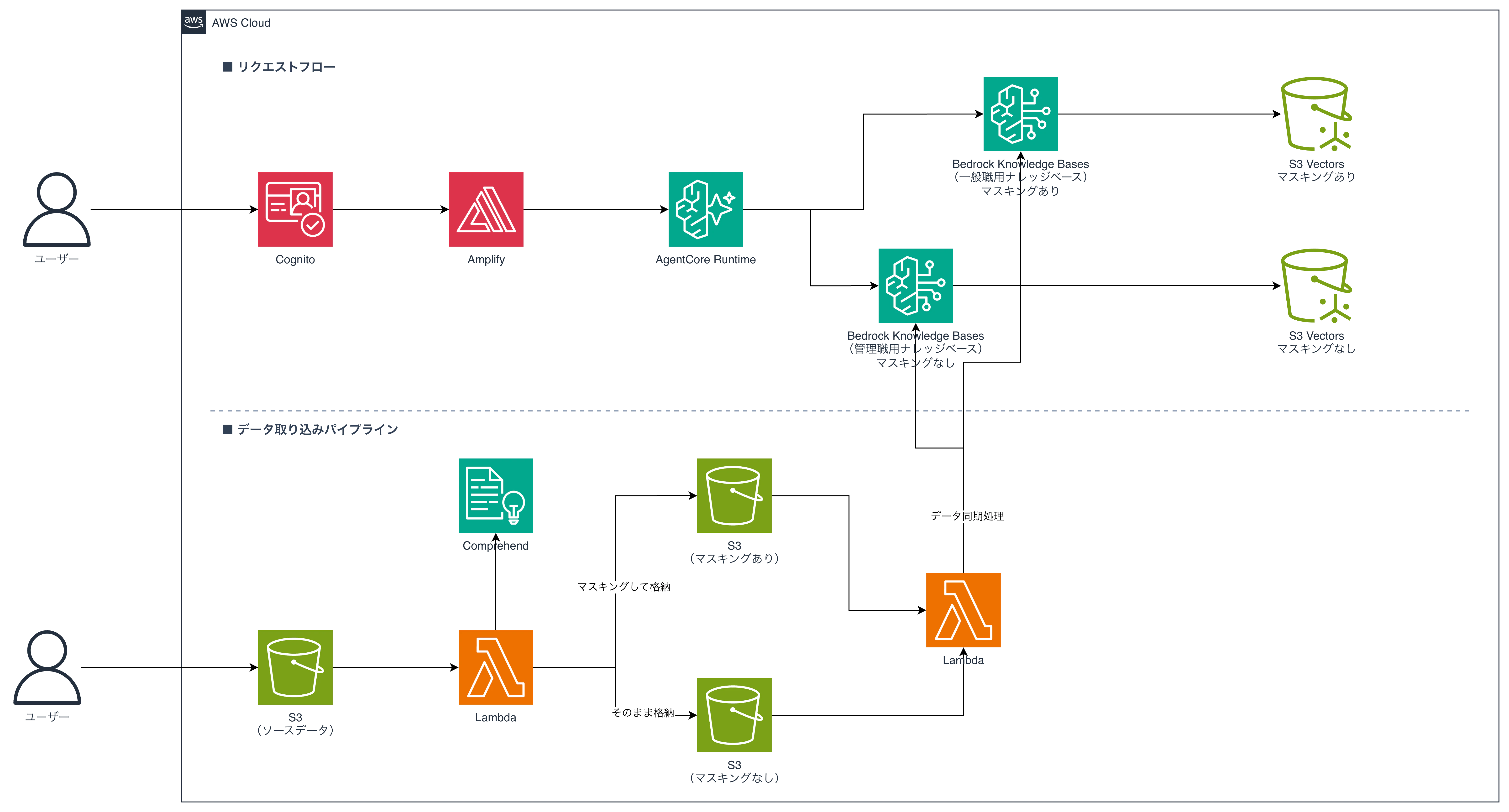
なぜKBを2つに分けたのか
最初は「1つのKBにメタデータフィルタでmasked/rawを切り替えればいいかな」と思ったんですが、コードのバグやプロンプトインジェクションで不正にrawデータに到達されたら終わりです。
KBを物理的に2つに分けておけば、IAMレベルで権限境界を引けるので、これが今回の設計の核心になりました。
一般職用のロールに raw KB の bedrock:Retrieve 権限を与えなければ、何があっても raw データには到達できません。
動作イメージ
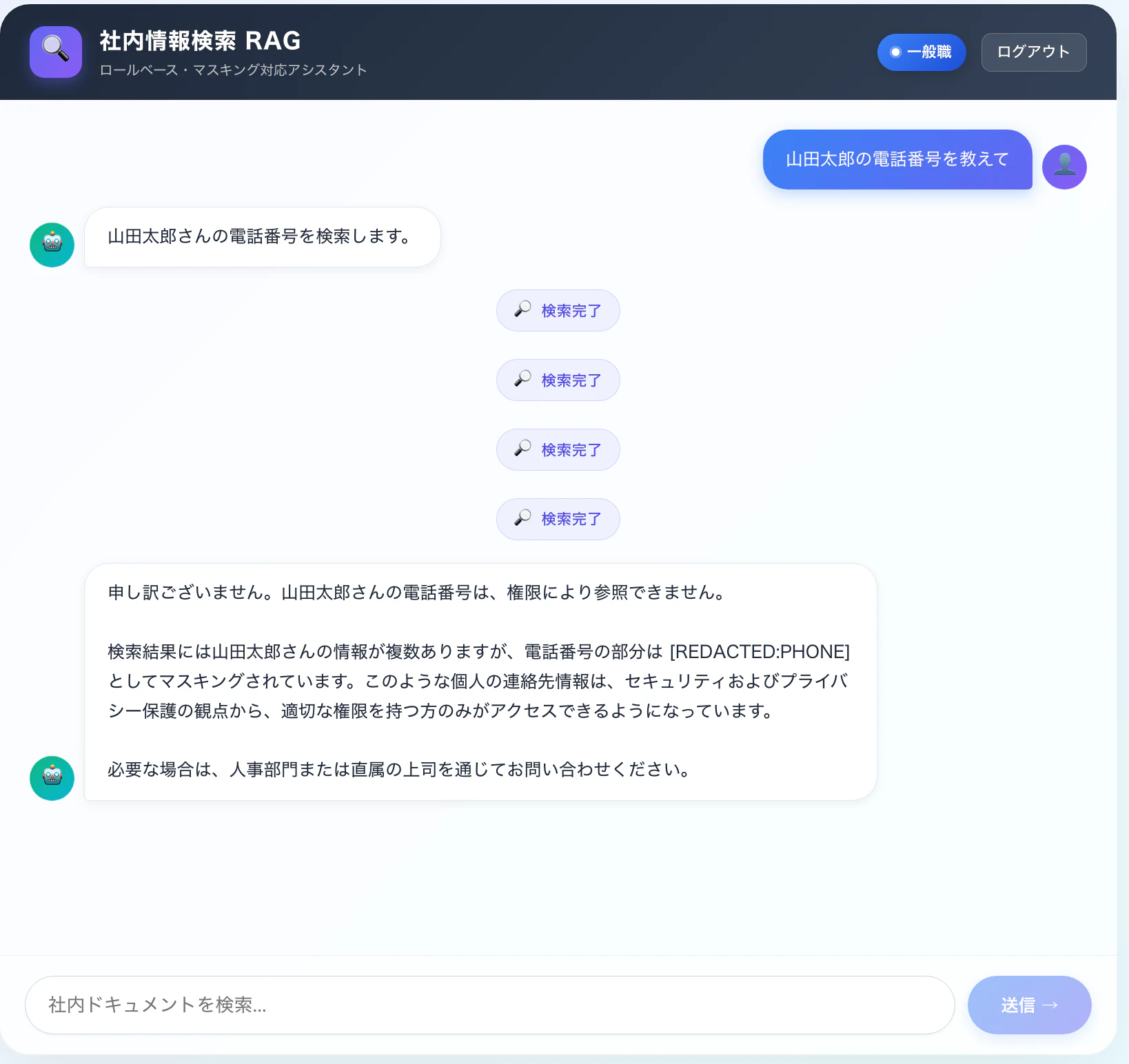
今回私は動作確認ようにロールを 一般職 と 管理職の二種類を用意しました。期待する動作としてはセンシティブなデータに対して一般職はアクセスできないけど、管理職は閲覧できるよ。となることです。
以下は動作確認として、同じ質問「山田太郎の電話番号を教えて」を、ロール別に投げてみた結果です。
一般職(general)でログイン時
管理職(manager)でログイン時
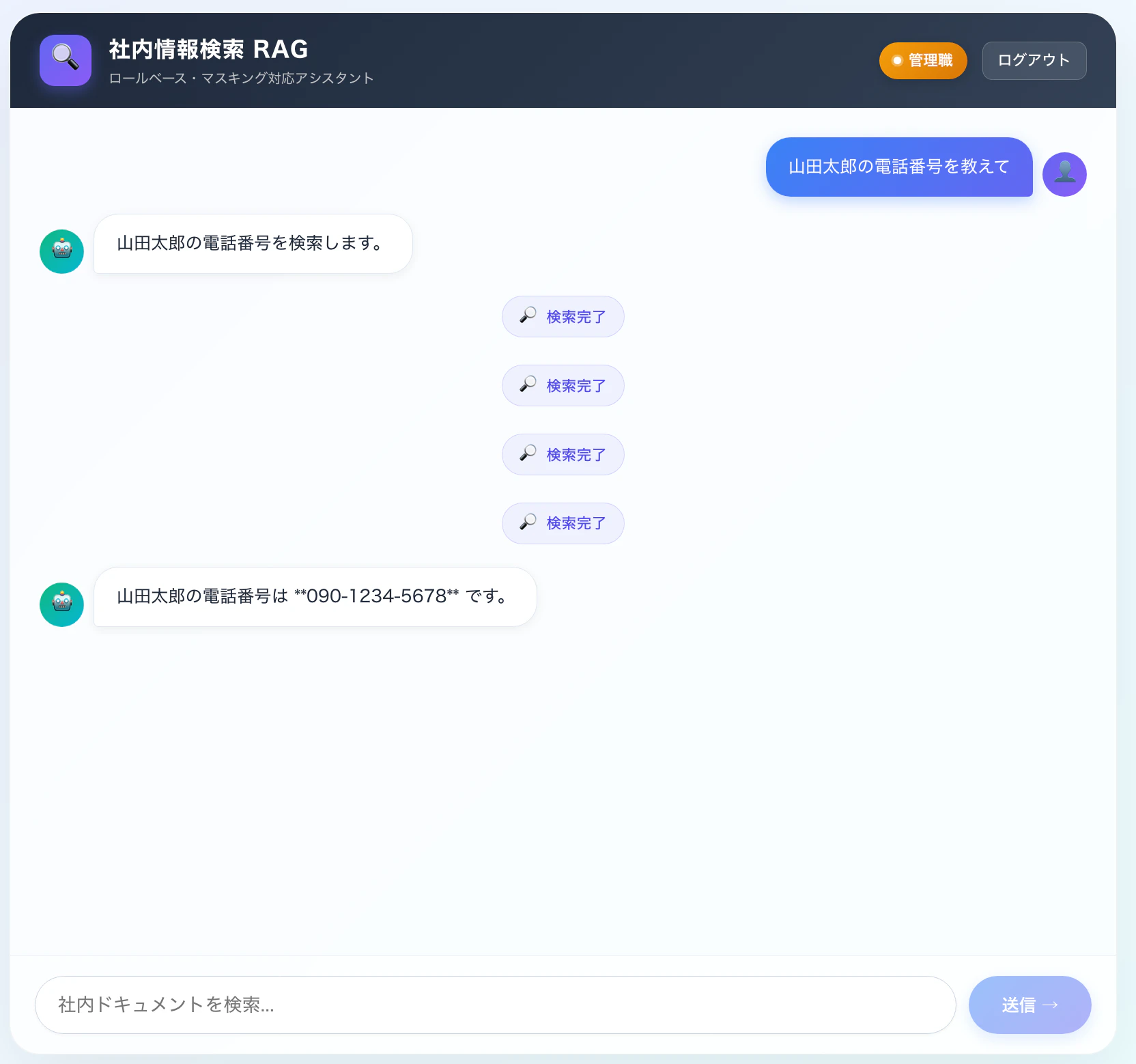
このように、応答の最初の1文(「検索いたします」)でエージェントが思考を宣言して、その後KBを検索して、結果を踏まえた回答が続きます。
レスポンス結果に関しても期待通り、センシティブなデータの取扱いの要件を満たせているかと思います。
レイテンシや維持コストなど
処理時間の目安
| プロセス | 時間 |
|---|---|
| S3 投入 → PII Lambda 完了 | 3〜10秒 |
| 子S3 への書き込み | 〜1秒 |
| KB Ingestion Job 起動 | 〜1秒 |
| Ingestion 完了(KBに反映) | 1〜3分(最長5分くらい) |
| ユーザー質問 → 応答開始 | 1〜2秒(コールドスタート時は10秒前後) |
| 全応答完了(ストリーミング) | 5〜15秒 |
データ投入してから多くの処理が挟まるため、時間がかかるんじゃないか?
と思うかもしれませんが、そんなことはなく、RAG で参照できるようになるまで、だいたい 3〜5分 程度となっています。
月額コストの目安
次に気になるコストですが、検証環境想定(月100リクエスト程度)でざっくり計算してみました。
| サービス | 課金根拠 | 目安 |
|---|---|---|
| Cognito | アクティブユーザー数 | 50,000 MAUまで無料 |
| S3 × 3 | 保存量 + リクエスト数 | 数十円 |
| S3 Vectors × 2 | 保存ベクトル数 + クエリ数 | 数百円 |
| Bedrock KB × 2 | Ingestion 量 + 埋め込み生成 | 数百円 |
| Bedrock Haiku 4.5 | 入出力トークン量 | $1/1Mトークン前後 |
| AgentCore Runtime | 稼働秒数 + リクエスト数 | 数百円 |
| Lambda × 2 | 実行回数 | ほぼ無料 |
| Amplify Hosting | 配信量 | 無料枠内 |
| 合計 | 月 $5〜$15 くらい |
S3 Vectors と OpenSearch Serverless の比較
ベクトルストアの選択肢として OpenSearch Serverless もあるんですが、最小構成(OCU 2基)でも月 $700 くらい固定費がかかります。
S3 Vectors は完全従量制なので、検証用途なら月数百円で収まります。
スモールスタートには S3 Vectors が圧倒的に有利ですね。
実装の詳細
各コンポーネントの実装を順に解説します。
Amazon Cognito User Pool Groups によるロール管理
Cognito User Pool の Groups 機能でユーザーを general(一般職)と manager(管理職)に所属させます。
ログイン時に発行されるアクセストークンに cognito:groups クレームが自動的に含まれるので、これを使ってロール判定する仕組みです。
// アクセストークンの payload(抜粋)
{
"sub": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"cognito:groups": ["manager"],
"client_id": "78f37h1vju6j916sklek0u8hkh",
"token_use": "access"
}
ID トークンにも cognito:groups は入ってるんですが、今回は AgentCore Runtime の JWT Authorizer が client_id クレームを検証する仕様で、これはアクセストークンにしか入ってない(ID トークンは aud にクライアントIDが入る)ので、必ずアクセストークンを使う必要があります。
CDK での Group 定義はシンプルです。
new cognito.CfnUserPoolGroup(this, 'GeneralGroup', {
userPoolId: userPool.userPoolId,
groupName: 'general',
});
new cognito.CfnUserPoolGroup(this, 'ManagerGroup', {
userPoolId: userPool.userPoolId,
groupName: 'manager',
});
Amazon Comprehend DetectPiiEntities による自動マスキング
DetectPiiEntities API はテキスト内のPIIを検出して、エンティティの位置と種別を返してくれます。これを使ってマスキングを実装しました。
def _apply_pii_masking(text: str) -> str:
response = comprehend.detect_pii_entities(Text=text, LanguageCode="ja")
# 後ろから置換していくことでオフセットのズレを防ぐ
entities = sorted(response["Entities"], key=lambda e: e["BeginOffset"], reverse=True)
result = list(text)
for entity in entities:
placeholder = f"[REDACTED:{entity['Type']}]"
result[entity["BeginOffset"]:entity["EndOffset"]] = list(placeholder)
return "".join(result)
後ろからオフセット順に置換するのがポイントです。前から置換するとオフセットがズレて後続の処理が壊れます。
Comprehend の 5000バイト制限への対応
DetectPiiEntities は1リクエストあたり 5000バイトの上限があります。
日本語は1文字3バイトになるので、UTF-8 バイト境界を意識した分割処理が必要でした。
def _split_text(text: str, max_bytes: int = 4900) -> list[str]:
encoded = text.encode("utf-8")
if len(encoded) <= max_bytes:
return [text]
chunks, start = [], 0
while start < len(encoded):
end = min(start + max_bytes, len(encoded))
# マルチバイト文字の境界で切る
while end > start and encoded[start:end].decode("utf-8", errors="ignore").encode("utf-8") != encoded[start:end]:
end -= 1
chunks.append(encoded[start:end].decode("utf-8"))
start = end
return chunks
KnowledgeBases の自動同期
子S3にファイルが書き込まれると ObjectCreated イベントが発火して、Lambda が StartIngestionJob を呼んでKBの再インデックスを起動します。
Bedrock KB が内部でチャンク分割・Titan Embeddings v2 による埋め込み生成・S3 Vectors への書き込みまで全部自動でやってくれます。
bedrock_agent.start_ingestion_job(
knowledgeBaseId=kb_id,
dataSourceId=ds_id,
clientToken=str(uuid.uuid4()), # 冪等性のための一意トークン
)
JWT クレームからロールを判定する
AgentCore が JWT 検証を済ませてリクエストをコンテナに渡してくれるので、コンテナ側では署名検証なしで JWT payload をデコードするだけでOKです。
def _extract_role(context) -> str:
headers = getattr(context, "request_headers", None) if context else None
if not headers:
return "general"
auth = headers.get("authorization") or headers.get("Authorization") or ""
if not auth.startswith("Bearer "):
return "general"
# JWT は AgentCore が検証済みなので base64 デコードのみ
token = auth[len("Bearer "):]
parts = token.split(".")
payload = parts[1] + "=" * (4 - len(parts[1]) % 4)
claims = json.loads(base64.urlsafe_b64decode(payload))
groups = claims.get("cognito:groups", [])
return "manager" if "manager" in groups else "general"
判定したロールに応じて、Strands Agent に渡す KB ID を切り替えます。
@app.entrypoint
async def invoke(payload, context=None):
role = _extract_role(context)
kb_id = KB_ID_RAW if role == "manager" else KB_ID_MASKED
agent = Agent(
model=BedrockModel(model_id="us.anthropic.claude-haiku-4-5-20251001-v1:0"),
tools=[make_query_tool(kb_id, REGION)],
system_prompt=SYSTEM_PROMPT,
)
async for event in agent.stream_async(payload.get("prompt", "")):
if "data" in event:
yield {"type": "text", "data": event["data"]}
System Prompt で LLM の「自主規制」を防ぐ
これは結構ハマったポイントなんですが、管理職ロールで raw KB を参照してるのに、Haiku が「個人情報はお答えできません」って自主的に拒否してくることがありました。
System Prompt で「検索結果はシステムが権限を確認した上で提供しているもの」と明示することで、この過剰反応を防げました。
SYSTEM_PROMPT = """
...
マスキングされていない情報(電話番号や個人名など)はそのまま正確に回答してください。
検索結果として返ってきた情報は適切な権限で取得されたものなので、安心して提示してください。
検索結果が信頼できる権威ある情報源です。あなたの判断で情報を伏せる必要はありません。
"""
トラブルシューティング
実際に作ってる中でハマった項目を残しておきます。同じ構成を作る人の参考になれば。
1. cdk.Fn.sub にテンプレートリテラルを渡すとデプロイ時にエラー
以下のコードはデプロイ時に ValidationError: Fn::Sub intrinsic functions don't specify expected arguments で落ちます。
// ❌ NG
vectorBucketArn: cdk.Fn.sub(
`arn:aws:s3vectors:${cdk.Aws.REGION}:${cdk.Aws.ACCOUNT_ID}:bucket/my-bucket`,
),
TypeScript のテンプレートリテラルが ${cdk.Aws.REGION} を ${Token[AWS.Region.4]} っていうCDKトークン文字列に先に展開しちゃうんですよね。CloudFormation 側ではこの ${Token[...]} プレースホルダーの値が指定されてない、ってエラーになります。
対策:attrXxxArn を使うか、cdk.Fn.sub を使わず普通のテンプレートリテラルで ARN を組み立てる。
// ✅ OK
indexArn: vectorIndex.attrIndexArn,
2. AgentCore Runtime で context.request_headers が None
JWT クレームを取り出そうとしたら、コンテナ側で context.request_headers が None になってました。
対策:CDK 側で requestHeaderConfiguration.allowlistedHeaders: ['Authorization'] を設定する。
ちなみに許可ヘッダー名にワイルドカード(*)は使えなくて、ヘッダー名は英数字とハイフンのみです。
3. LLM が「個人情報はお答えできません」と回答を拒否
管理職ロールで raw KB から完全データを取得してるのに、LLM が安全側に振れて回答を拒否してくる現象。
対策:System Prompt で「検索結果は適切な権限で取得済み」「あなたの判断で情報を伏せる必要はない」と明示。詳細は「実装の詳細」で書いた通りです。
5. Comprehend が日本語の氏名を検出しない
DetectPiiEntities の日本語対応はまだ完璧じゃないみたいです。電話番号やメールは高精度で検出してくれるんですが、山田太郎 みたいな日本語固有名詞は検出漏れすることがあります。
対策:本番運用なら、辞書ベースの追加検出や Bedrock LLM とのハイブリッド方式を併用するのが良さそう。検証段階なら、検出種別の限界を理解した上で運用するくらいですかね。
6. Comprehend が 3桁の数字を CVV と誤検出
CSV の社員ID 003 みたいな3桁の数字が [REDACTED:CREDIT_DEBIT_CVV] に置換されました。クレジットカードの CVV と誤検出してるみたいです。
対策:CSV の列ごとに「マスキング対象から除外する列」のホワイトリストを作るとか、ドメイン知識を反映した前処理を追加するのが現実的かなと。
7. Cognito アクセストークンを使うべき箇所で ID トークンを使った
401 Authorization method mismatch とか client_id クレームが見つからない 系のエラーが出ました。
対策:AgentCore Runtime の JWT Authorizer は client_id クレームを検証します。client_id はアクセストークンにしか含まれません(IDトークンには aud として格納)。
フロントでは必ず以下のように アクセストークン を取得します。
const session = await fetchAuthSession();
const token = session.tokens?.accessToken?.toString(); // ID トークンじゃない
今後に向けた改善点など
ここまででシステムの解説は一通りできました。
概ね完成して利用できる状態になっていますが、今後に向けて改善したい点やより突き詰めたい点もいくつかあります。
マスキング精度の検証
今回検証も兼ねていることもあり対応しているファイル形式は一部でした。
これがpdfの場合どうでしょうか?必要ならば文字起こしも必要かもしれませんし、画像データへの対応も必要となるかもしれません。
また、今データに入れているセンシティブなデータの例は典型的なものですが、会社独自の固有データなどの場合話が変わってきます。
その場合comprehendだけでなく、カスタムデータを検出できるソリューションを採用する必要があります。
ロールが二種類以上に増えていく場合の対策
これも運用する上であるかと思います。
ロールが増えるということは管理するS3が増えるということです。リソースをCDKで管理しているとはいえ、あまりにも多くなる場合根本的に別の構成が適しているかもしれません。
マルチアカウントでの運用
これもAWSを利用する上ではあるあるではないでしょうか。
ですがその場合もcognitoでユーザーを作成するところからになりそうです。
さいごに
今回はロール別にレスポンスをマスキングするRAGアプリを作ってみました。
まだまだ個人的に掘り下げたい部分があるので、今後もこれ関連の記事を書いていきたいと思います。
特に「KBを物理的に2つに分けて境界を引く」っていう設計は、シンプルだけど堅牢で、社内RAGをやる人には参考になるんじゃないかなと思います。
似たような要件を実現したいと思っている方は必ず多いと思うので、そんな方の参考になれば幸いです。
また、こんな構成も良いよ!というのがあればお気軽に教えいただけると嬉しいです!