はじめに
こんにちは。株式会社ジールの@yakisobapanです。
S3 Tables
Athena Icebergテーブル
どちらもApache Iceberg形式をサポートしていますが、何が違うのかわかっていなかったので、Snowflakeへの連携まで構築してみました。
本記事は、Athenaとの連携編です。
S3 Tablesとの連携編はこちら↓
目次
- アーキテクチャ
- 構築手順
- 動作確認
- 所感
アーキテクチャ

構築手順
S3
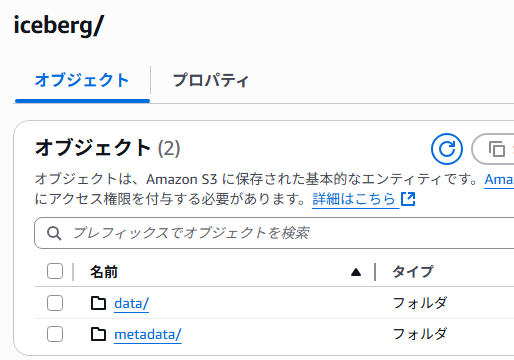
①フォルダを作成
Athena Icebergテーブルが利用するフォルダを用意します。
このフォルダの配下には、テーブル作成したタイミングでdata/とmetadata/というフォルダが自動作成されます。
↓後続で実施する[テーブル作成]後の状態
Athena
①テーブルの作成
Iceberg形式でテーブルを作成します。
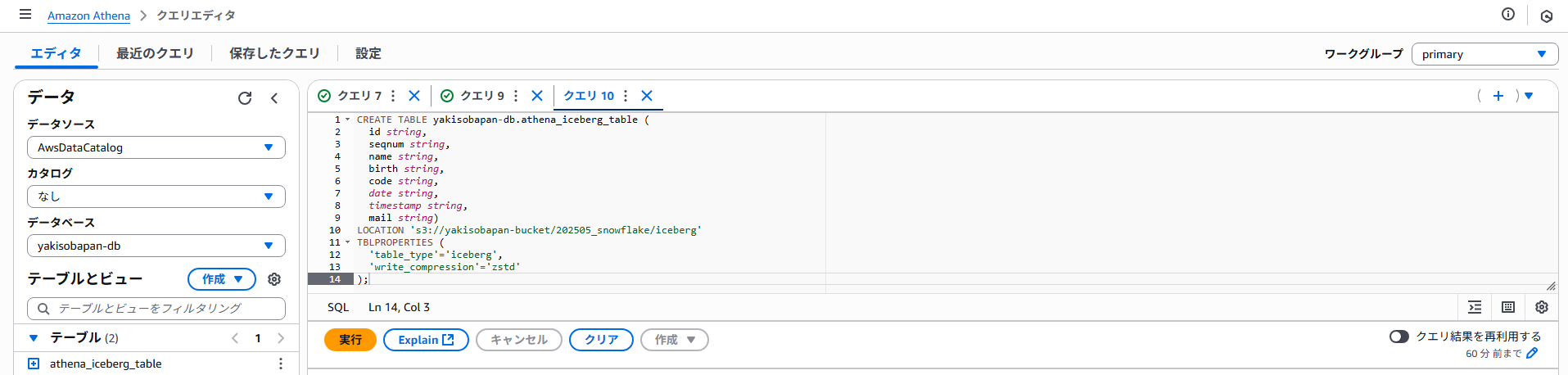
CREATE TABLE yakisobapan-db.athena_iceberg_table (
id string,
seqnum string,
name string,
birth string,
code string,
date string,
timestamp string,
mail string)
LOCATION 's3://yakisobapan-bucket/202505_snowflake/iceberg'
TBLPROPERTIES (
'table_type'='iceberg', --テーブル形式
'write_compression'='zstd' --データ圧縮方式
);
作成後、S3のmetadataフォルダにjsonファイルが作成されます。(ファイルの役割は後述)

②テーブルへデータの投入
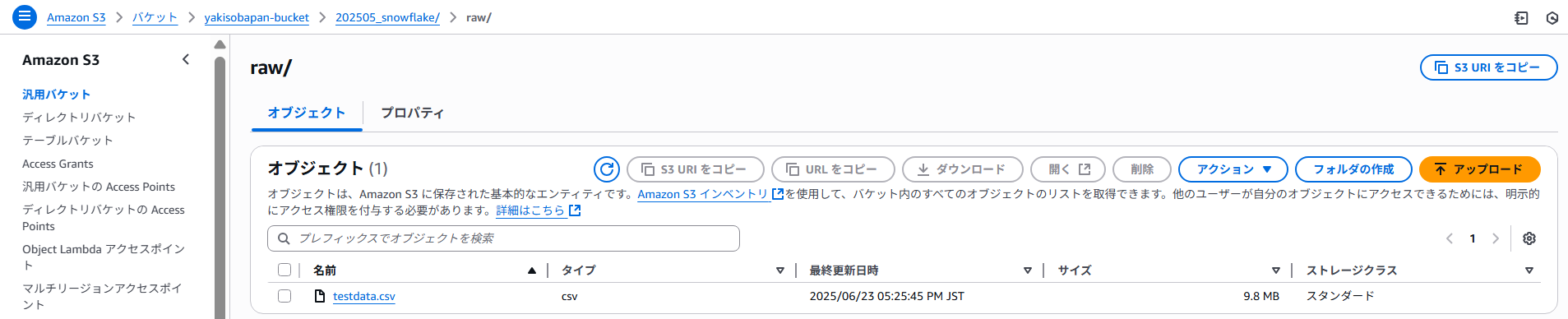
今回は10万行のcsvをS3標準バケットへ配置し、それをAthena上の別データベース内テーブルstaging_tableとして用意し、それをINとしてデータ挿入しました。

INSERT INTO
"AwsDataCatalog"."yakisobapan-db"."athena_iceberg_table"
SELECT * FROM
"AwsDataCatalog"."yakisobapan-db"."staging_table";
作成後、S3のmetadataフォルダにjsonとavroファイルが作成されます。(ファイルの役割は後述)

(参考)投入データの配置
・S3
・Athena
※表示データはランダム生成した10万件のデータです。

各フォルダに格納されるファイルの役割について簡単に説明すると、
・data配下に作成されるparquet(データファイル)
⇒実データ
・metadata配下に作成されるavro(マニフェスト、マニフェストリストファイル)
⇒マニフェスト:実データのメタデータ(ファイルパス、レコード数...)
⇒マニフェストリスト:マニフェストファイルの一覧
・metadata配下に作成されるjson(スナップショット、メタデータファイル)
⇒テーブル全体のメタデータ(テーブル履歴、バージョン、スキーマ定義、パーティション...)
という感じです。
詳細はIcebergの公式ドキュメントに説明がありますのでご参照ください。
IAM
①IAMロールを作成
Snowflakeが引き受けてGlue Data Catalogを参照するためのロールを作成します。
[信頼されたエンティティ]については、後ほどSnowflakeの設定値を設定するため、このタイミングでは適当でOKです。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::[カタログがあるアカウントID]/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::[カタログがあるアカウントID]",
"Condition": {
"StringLike": {
"s3:prefix": [
"*"
]
}
}
},
{
"Effect": "Allow",
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:CreateTable",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:ap-northeast-1:[カタログがあるアカウントID]:catalog",
"arn:aws:glue:ap-northeast-1:[カタログがあるアカウントID]:database/*",
"arn:aws:glue:ap-northeast-1:[カタログがあるアカウントID]:table/*"
]
}
]
}
Snowflake
①CATALOG INTEGRATIONを作成
CATALOG INTEGRATIONは複数用意されていますが、CREATE CATALOG INTEGRATION (AWS Glue)を作成します。
CREATE OR REPLACE CATALOG INTEGRATION athena_catalog_integration
CATALOG_SOURCE=GLUE
CATALOG_NAMESPACE='yakisobapan-db'
TABLE_FORMAT=ICEBERG
GLUE_AWS_ROLE_ARN='arn:aws:iam::[カタログがあるアカウントID]:role/role_snowflake_to_glue_datacatalog'
GLUE_CATALOG_ID='[カタログがあるアカウントID]'
GLUE_REGION='ap-northeast-1'
ENABLED=TRUE
;
②作成した統合がIAMロールを引き受けられるようにする
作成した統合を確認し、以下情報を取得します。
API_AWS_IAM_USER_ARN:SnowflakeがホストされているAWSアカウントのIAMユーザーarn
API_AWS_EXTERNAL_ID:AWS外部ID
DESC CATALOG INTEGRATION athena_catalog_integration;
(AWSで作業)取得した2項目を、IAMロールの[信頼されたエンティティ]へ設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::[SnowflakeのAWSアカウントID]:[SnowflakeのIAMユーザー]"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId":"AWS外部ID"
}
}
}
]
}
③外部ボリュームの作成
SnowflakeをIcebergテーブル用の外部クラウドストレージ(今回だとS3)に接続するために使用します。
CREATE OR REPLACE EXTERNAL VOLUME vol_athena_iceberg
STORAGE_LOCATIONS =
(
(
NAME = 's3-ap-northeast-1'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://yakisobapan-bucket/202505_snowflake/iceberg/'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::[カタログがあるアカウントID]:role/role_snowflake_to_glue_datacatalog'
ENCRYPTION=(TYPE='AWS_SSE_S3')
)
)
ALLOW_WRITES = false
;
④Icebergテーブルの作成
カタログ統合を使って、Snowflakeにテーブルを作成します。
CREATE OR REPLACE ICEBERG TABLE athena_iceberg_table
EXTERNAL_VOLUME='vol_athena_iceberg' --外部ボリューム
CATALOG='athena_catalog_integration' --カタログ統合
CATALOG_TABLE_NAME='athena_iceberg_table' --テーブル名
;
動作確認
Athena Icebergテーブルに存在するデータが参照できています。
※表示データはランダム生成した10万件のデータです。

所感
Snowflakeは一度公式チュートリアルを触っただけですので、試行錯誤しながらでしたがAWSとの連携方法の一つとして理解することができました。
S3 Tablesを連携元とした方法にも言えますが、Icebergの特長について深掘りしてみたい、そんな興味がわきました。
今回はデータ連携という観点で試してみましたが、機能の追及を今後行いたいと思います。
例)
・パーティションの有無によるクエリ実行スタイルの変化
・ACIDトランザクションを試してみる
・Athenaのカタログ統合について、AWS Glue版の統合を使用したが、Apache Iceberg REST版を使用した場合、どのような挙動になるのか(そもそも使用できるのか)
参考
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: