1. 概要
セマンティックセグメンテーションを自分でやってみたのですが、その過程でいろいろ調べたことを残しておきます。
データセット
- データセットはVOCを使用します。
- セグメンテーションの場合、正解データも画像になります。
- 正解データには元画像の各画素がどのカテゴリかを表すデータが保存されていますが、それを表現するためにパレットモードというフォーマットで保存されています。
- 正解ラベルが用意されている画像は2913枚です。
VOCデータの中身や、パレットモードについては下記のサイトを参考にさせて頂きました。ありがとうございます。
https://qiita.com/tktktks10/items/0f551aea27d2f62ef708
画像の準備
扱いやすいように事前にVOCの画像を加工します。
- VOCの画像サイズはまちまちなので、各画像を短辺に合わせてクロップしてすべて正方形に揃えます。
- ImageDataGeneratorの機能を利用して簡単にオーグメンテーションするために、画像サイズを512*512にリサイズ(拡大)して揃えます。
- 正解ラベル(画像)も上記の処理を施した後、パレットモードとして保存します
モデル
- モデルはU-Netを使用します。
- 論文ではエンコーダーからデコーダーへバイパスする部分でクロップしていたりしますが、いろいろなサイトのU-Netを参考にして、畳込み層で
padding='same'とすることでクロップしないやり方を採用しました。 - 使用するデータセットは22カテゴリがラベリングされているので、出力層は
filters=22としています。 - 入力は256*256の正方形としました。
2. 画像の準備
概要で書いたように、あとで扱いやすくするために元画像の短辺に合わせて正方形化し、512*512にリサイズします。この処理を下記のような関数にしておきます。
from PIL import Image
import numpy as np
import os
def copy_images(orig, mask, dest):
filename = orig.split('/')[-1].split('.')[0]
dest_orig = dest + '/image/' + filename + '.png'
dest_mask = dest + '/mask/' + filename + '.png'
# 画像を開く
image = Image.open(orig)
mask = Image.open(mask)
# 画像の短辺に合わせて正方形化
image = crop_to_square(image)
mask = crop_to_square(mask)
# 512*512にリサイズ
image = image.resize((512, 512))
mask = mask.resize((512, 512))
# アルファチャネルがあればRGBに変換
if image.mode == 'RGBA':
image = image.convert('RGB')
# マスク画像のインデックス255を21に変更する
np_mask = np.asarray(mask, dtype='uint8') # まずndarrayに変換する
temp_palette = mask.getpalette() # パレットを取得しておく
np_mask = np.where(np_mask == 255, 21, np_mask) # パレットインデックスを変更
mask = Image.fromarray(np_mask, mode='P') # PILオブジェクトに戻す
mask.putpalette(temp_palette) # 保存しておいたパレットを適用
# 画像を書き込み
image.save(dest_orig)
mask.save(dest_mask)
def crop_to_square(image):
size = min(image.size)
left, upper = (image.width - size) // 2, (image.height - size) // 2
right, bottom = (image.width + size) // 2, (image.height + size) // 2
return image.crop((left, upper, right, bottom))
これを正解ラベル(画像)が入手可能な2913枚について行い、最初の100枚をテスト用に、残りを訓練用に別々に保存します。
import glob
def available_images():
# ダウンロードしたVOCデータ
dir_orig = './VOCdevkit/VOC2012/JPEGImages'
dir_mask = './VOCdevkit/VOC2012/SegmentationClass'
# 正解ラベル(画像)ファイル一覧
paths_mask = glob.glob(dir_mask + '/*'
# 対応する元画像のパスを生成
filenames = list(map(lambda path: path.split(os.sep)[-1].split('.')[0], path_mask))
paths_orig = list(map(lambda filename: dir_orig + '/' + filename + '.jgp', filenames))
return paths_orig, paths_mask
# マスク画像が入手可能な画像ペアを取得
paths_orig, paths_mask = available_images()
# テスト用に100ペアを準備
for i in range(100):
copy_images(paths_orig[i], paths_mask[i], './VOC-test')
# 残りは訓練用
for i in range(100, len(paths_orig)):
copy_images(paths_orig[i], paths_mask[i], './VOC-train')
3. ImageDataGeneratorを準備
kerasを使ってスッキリ実装するためにImageDataGeneratorを使います。
前項で画像はすべて512*512に揃えていますが、
- このままのサイズを入力するU-Netを作ると学習可能パラメータ数が膨大になる
- ラベル付きデータセット数が2913個と少なめ
の2つの理由により、512512の元画像を256256サイズで切り出し、切り出し中心を元画像の中央256*256の範囲でランダムにサンプリングする、という方法をとりました。これに加えて水平方向のミラーリングによるオーグメンテーションも行います。
これらのオーグメンテーションはすべてImageDataGeneratorでやってくれます。楽チンですね。
セグメンテーションの場合、クラス分類とは異なり、1つのImageDataGeneratorで画像と正解ラベルを供給できないので、画像と正解ラベルで別個で、かつシンクロしたImageDataGeneratorを作ります。しかし、fit_generator()に渡すときには元画像と正解ラベルをペアで返すジェネレータが必要なので、画像と正解ラベルの2つのImageDataGeneratorを1つのジェネレータにまとめます。
さらに、ImageDataGeneratorはマスク画像もパレットモードではなく、通常のRGB画像として扱ってしまうので、自分で(batch_size, 256, 256, 22)のone-hot化したndarrayに変換する必要もあります。
以上を実装すると次のようになります。
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
# 22カテゴリ分のパレットの色を事前に取得したもの
def get_palette():
palette = [
[0, 0, 0],
[128, 0, 0],
[0, 128, 0],
[128, 128, 0],
[0, 0, 128],
[128, 0, 128],
[0, 128, 128],
[128, 128, 128],
[64, 0, 0],
[192, 0, 0],
[64, 128, 0],
[192, 128, 0],
[64, 0, 128],
[192, 0, 128],
[64, 128, 128],
[192, 128, 128],
[0, 64, 0],
[128, 64, 0],
[0, 192, 0],
[128, 192, 0],
[0, 64, 128],
[128, 64, 128]]
return np.asarray(palette)
# 元画像は正規化し、マスク画像はone-hot化する
def adjustData(img, mask):
# 元画像の方は255で割って正規化する
if np.max(img) > 1:
img = img / 255.
# マスク画像の方はOne-Hotベクトル化する
# パレットカラーをndarrayで取得する
palette = get_palette()
# パレットとRGB値を比較してマスク画像をOne-hot化する
onehot = np.zeros((mask.shape[0], 256, 256, 22), dtype=np.uint8)
for i in range(22):
# 現在カテゴリのRGB値を[R, G, B]の形で取得する
cat_color = palette[i]
# 画像が現在カテゴリ色と一致する画素に1を立てた(256, 256)のndarrayを作る
temp = np.where((mask[:, :, :, 0] == cat_color[0]) &
(mask[:, :, :, 1] == cat_color[1]) &
(mask[:, :, :, 2] == cat_color[2]), 1, 0)
# 現在カテゴリに結果を割り当てる
onehot[:, :, :, i] = temp
return img, onehot
def trainGenerator(image_folder, batch_size=20, save_to_dir=[None, None]):
# 2つのジェネレータには同じパラメータを設定する必要がある
data_gen_args = dict(
width_shift_range=64, # 元画像上でのシフト量128にzoom_ratioをかけてint型で設定する
height_shift_range=64, # 同上
zoom_range=[0.5, 0.5], # 512*512の元画像上で256*256分を等倍で切り出したい
horizontal_flip=True,
rescale=None # リスケールはadjustData()でやる
)
seed = 1 # Shuffle時のSeedも共通にしないといけない
# ImageDataGeneratorを準備
image_datagen = ImageDataGenerator(**data_gen_args)
mask_datagen = ImageDataGenerator(**data_gen_args)
# ジェネレータを準備
image_generator = image_datagen.flow_from_directory(
directory=image_folder,
classes=['image'], # directoryの下のフォルダを1つ選び、
class_mode=None, # そのクラスだけを読み込んで、正解ラベルは返さない
target_size=(256, 256),
batch_size=batch_size,
seed=seed,
save_to_dir=save_to_dir[0]
)
mask_generator = mask_datagen.flow_from_directory(
directory=image_folder,
classes=['mask'],
class_mode=None,
target_size=(256, 256),
batch_size=batch_size,
seed=seed,
save_to_dir=save_to_dir[1]
)
for (img, mask) in zip(image_generator, mask_generator):
img, mask = adjustData(img, mask)
yield img, mask
次のように動作確認してみると、元画像とマスク画像がちゃんとペアで選択され、切り出し位置もシンクロしていることが確認できます。
if __name__ == '__main__':
temp_gen = trainGenerator('./VOC-test', batch_size=1, save_to_dir=['./deleteme/image', './deleteme/mask'])
count = 0
for img, mask in temp_gen:
print(img.shape, mask.shape)
count += 1
if count == 3:
break
VOCの画像には人物や乗り物など、上下反転させると現実に合わないサンプルが多数あるのでhorizontal_flipのみ有効にしています。
オーグメンテーションの設定は下記のサイトを参考にさせて頂きました。ありがとうございます。
https://qiita.com/takurooo/items/c06365dd43914c253240
width_shift_range / height_shift_rangeのところで実例が示されていますが、画像の端が引き延ばされたようになっています。こういうのも不自然で訓練に害を及ぼさないのか気になるところです。
今回の実験ではこういう引き延ばしが発生しないようなzoom_rangeとxxx_shift_rangeを設定しました。
4. モデルを準備
U-Netの詳細は論文を参照していただきたいのですが、論文のFig.1が非常に分かりやすいので下記に示します。
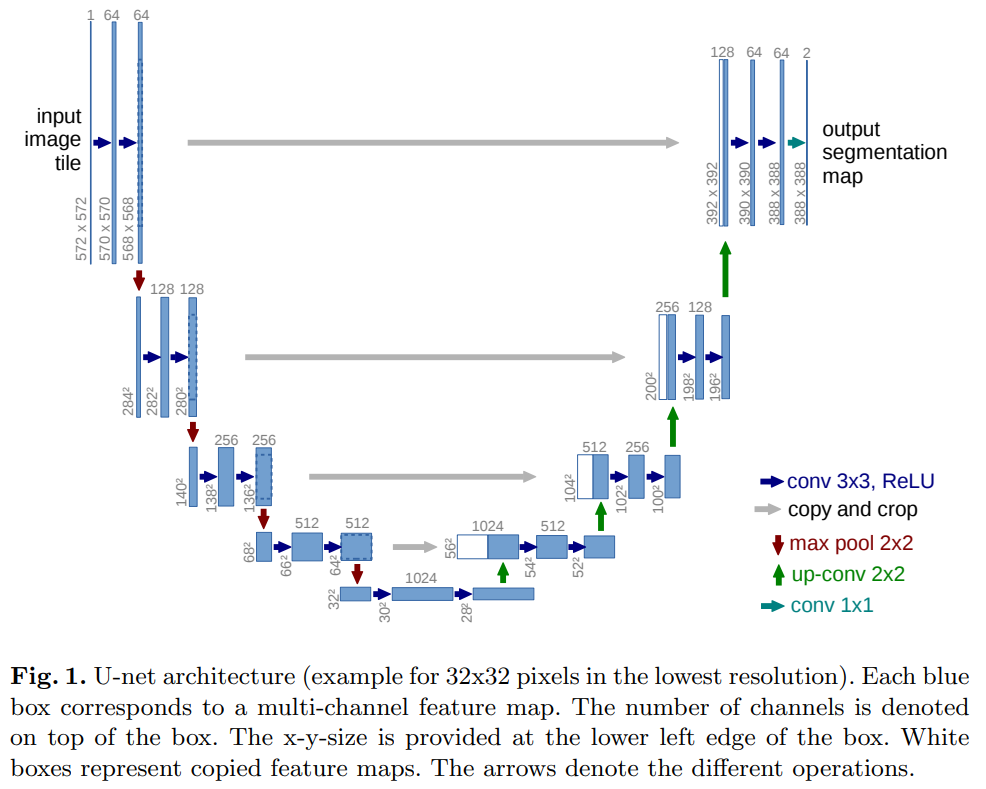
大まかな流れとして、max pool層を経る度に画像サイズは1/2倍に、up-conv層を経る度に2倍に変化していますが、畳込み層でもPaddingしていない分少しずつ画像が小さくなっています。そのため、エンコーダーからデコーダーへのバイパスのところで、エンコーダー側の画像を破線で示されるようにクロップする必要があります。また出力画像サイズも元画像より小さくなっています。
今回は畳込み層でpadding='same'と指定して元画像と同じサイズの出力画像が得られるようにしました。
その他に、各畳込み層の下とconcat層の下にはBatchNorm層を入れています。
VOCは22クラスの多クラス単一ラベル分類なので、出力層のフィルター数は22、活性化関数はsoftmax、損失関数はcategorical_crossentropyを使用しています。
from keras.models import Model
from keras.layers import Input, MaxPooling2D, Concatenate, BatchNormalization
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras import regularizers
from keras.optimizers import *
def create_conv(input, filters, l2_reg, name):
x = Conv2D(filters=filters,
kernel_size=3, # 論文の指定通り
activation='relu', # 論文の指定通り
padding='same', # sameにすることでConcatする際にContracting側の出力のCropが不要になる
kernel_regularizer=regularizers.l2(l2_reg),
name=name)(input)
x = BatchNormalization()(x)
return x
def create_trans(input, filters, l2_reg, name):
x = Conv2DTranspose(filters=filters,
kernel_size=2, # 論文の指定通り
strides=2, # このストライドにより出力サイズが入力の2倍に拡大されている
activation='relu', # 論文の指定通り
padding='same', # Concat時のCrop処理回避のため
kernel_regularizer=regularizers.l2(l2_reg),
name=name)(input)
x = BatchNormalization()(x)
return x
def unet():
l2_reg = 0.0001
input = Input((256, 256, 3))
conv1_1 = create_conv(input, filters=64, l2_reg=l2_reg, name='conv1c_1')
conv1_2 = create_conv(conv1_1, filters=64, l2_reg=l2_reg, name='conv1c_2')
pool1 = MaxPooling2D(pool_size=(2, 2), strides=2, name='pool1')(conv1_2)
conv2_1 = create_conv(pool1, filters=128, l2_reg=l2_reg, name='conv2c_1')
conv2_2 = create_conv(conv2_1, filters=128, l2_reg=l2_reg, name='conv2c_2')
pool2 = MaxPooling2D(pool_size=(2, 2), strides=2, name='pool2')(conv2_2)
conv3_1 = create_conv(pool2, filters=256, l2_reg=l2_reg, name='conv3c_1')
conv3_2 = create_conv(conv3_1, filters=256, l2_reg=l2_reg, name='conv3c_2')
pool3 = MaxPooling2D(pool_size=(2, 2), strides=2, name='pool3')(conv3_2)
conv4_1 = create_conv(pool3, filters=512, l2_reg=l2_reg, name='conv4c_1')
conv4_2 = create_conv(conv4_1, filters=512, l2_reg=l2_reg, name='conv4c_2')
pool4 = MaxPooling2D(pool_size=(2, 2), strides=2, name='pool4')(conv4_2)
conv5_1 = create_conv(pool4, filters=1024, l2_reg=l2_reg, name='conv5m_1')
conv5_2 = create_conv(conv5_1, filters=1024, l2_reg=l2_reg, name='conv5m_2')
trans1 = create_trans(conv5_2, filters=512, l2_reg=l2_reg, name='trans1')
concat1 = Concatenate(name='concat1')([trans1, conv4_2])
conv6_1 = create_conv(concat1, filters=512, l2_reg=l2_reg, name='conv6e_1')
conv6_2 = create_conv(conv6_1, filters=512, l2_reg=l2_reg, name='conv6e_2')
trans2 = create_trans(conv6_2, filters=256, l2_reg=l2_reg, name='trans2')
concat2 = Concatenate(name='concat2')([trans2, conv3_2])
conv7_1 = create_conv(concat2, filters=256, l2_reg=l2_reg, name='conv7e_1')
conv7_2 = create_conv(conv7_1, filters=256, l2_reg=l2_reg, name='conv7e_2')
trans3 = create_trans(conv7_2, filters=128, l2_reg=l2_reg, name='trans3')
concat3 = Concatenate(name='concat3')([trans3, conv2_2])
conv8_1 = create_conv(concat3, filters=128, l2_reg=l2_reg, name='conv8e_1')
conv8_2 = create_conv(conv8_1, filters=128, l2_reg=l2_reg, name='conv8e_2')
trans4 = create_trans(conv8_2, filters=64, l2_reg=l2_reg, name='trans4')
concat4 = Concatenate(name='concat4')([trans4, conv1_2])
conv9_1 = create_conv(concat4, filters=64, l2_reg=l2_reg, name='conv9e_1')
conv9_2 = create_conv(conv9_1, filters=64, l2_reg=l2_reg, name='conv9e_2')
output = Conv2D(filters=22, # VOCのカテゴリ数22
kernel_size=1, # 論文の指定通り
activation='softmax', # 多クラス単一ラベル分類なのでsoftmaxを使う
name='output')(conv9_2)
model = Model(input, output)
model.compile(optimizer=Adam(lr=0.001),
loss='categorical_crossentropy', # 多クラス単一ラベル分類
metrics=['accuracy'])
return model
5. コールバックを準備
チェックポイントを保存するコールバックを準備します。
from keras import callbacks
def callbacks_01(cp_dir):
cp_path = cp_dir + '/' + '/my_model_{epoch:03d}-{val_loss:.4f}-{val_acc:.4f}.h5'
callbacks_list = [
# エポック毎に現在の重みを保存する
callbacks.ModelCheckpoint(
filepath=cp_path,
monitor='val_loss',
save_best_only=True)]
return callbacks_list
6. 学習
学習にはfit_generator()を使用します。
import model
import data_gen
import callbacks
import matplotlib.pyplot as plt
# モデルを構成する
model = model.unet()
model.summary()
# ImageDataGeneratorを準備する
train_gen = data_gen.trainGenerator('./VOC-train', batch_size=20)
validation_gen = data_gen.trainGenerator('./VOC-test', batch_size=20)
# コールバックを設定する
callbacks_list = callbacks.callbacks_01('./cp')
# モデルの訓練
history = model.fit_generator(
generator=train_gen,
steps_per_epoch=500,
epochs=430,
callbacks=callbacks_list,
validation_data=validation_gen,
validation_steps=10
)
# 学習履歴を保存する
import pickle
with open('./train_hist/hist', 'wb') as file_pi:
pickle.dump(history.history, file_pi)
# 訓練時の軌跡をプロット
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
7. 結果
訓練履歴は下図のようになりました。
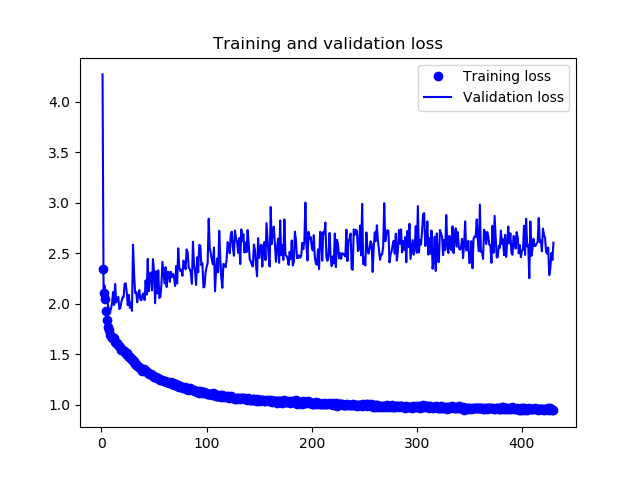
30エポックくらいから過学習が始まっているようです。
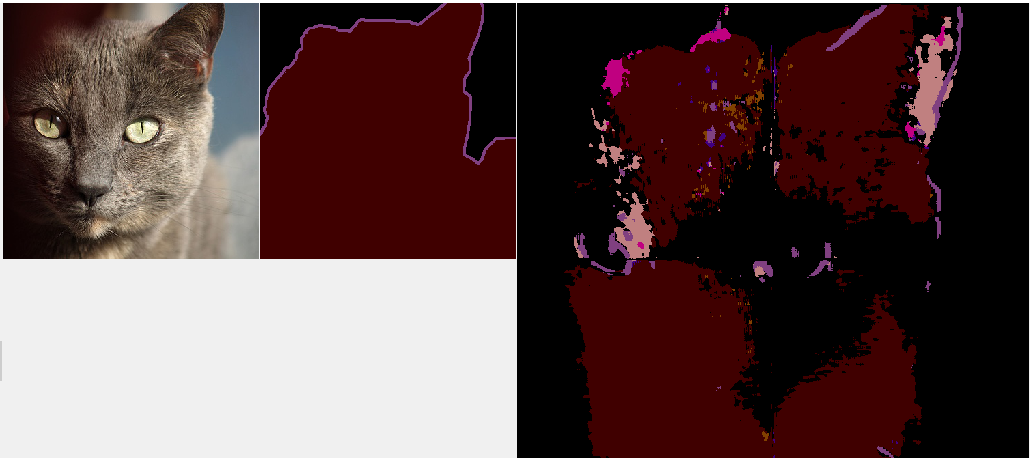
29エポック目でvalidation_lossが最低の1.9292となり、この時のチェックポイントを使って実際にどういうマスクを生成するのか見てみました。左から元画像、正解マスク、推定マスクです。



部分的には一致しているのは多数見られましたが、外しているとこのほうが多く、1枚の画像としてみると精度は高いとは言えない感じです。全然かすりもしていないものも多数ありました。
あと、テーブルや椅子といったクラスは推定結果にはほとんど出てこなかったりする一方、人物や飛行機はよく出てきたりと、クラスによっても出やすいものと出にくいものがあるようです。
上記の結果はモデルの入力は256256なので、512512の元画像をリサイズしてモデルに入力しています。
これに対し、訓練時と同じように元画像をリサイズせずに、4分割して判定させて、張り合わせる方法で推定したのが下図です。精度的には大差ない感じです。
この結果を見ていると、生成されるマスクの全面が一様に同じ精度というわけではなく、マスク面の中央ほど精度が出ている傾向がありそうです。
8. まとめ
kerasを使ってセグメンテーションをやる中で、つまづいたところを中心にメモしました。
結果としてはあまり精度は出ませんでしたが、早い段階で過学習に陥っているので、過学習対策としてデータ数を増やすことができれば精度向上の余地はありそうです。
今回、3000枚弱の画像で約3100万個のパラメータを持つモデルを学習しようとしたので、データ数の不足が最も大きな敗因ではないかと思います。
9. 参考
下記のサイトを参考にさせて頂きました。ありがとうございます。