はじめに
2018年からサーバーリプレース作業(Windows Server 2008R2 → Windows Server 2016)でデータベースを Oracle 11g から PostgreSQL 9.6 に移行作業をし、コロナ禍で出張が延期になるなど影響がありましたが、1年(月1〜3拠点)かけて全国25箇所の導入作業が2020年9月に完了しました。
OracleからPostgreSQL移行について
主に2拠点にてPostgreSQLのログを調べると1日1回くらいタイムアウトエラーが出ていました。運用的にはリトライ処理が入っているため、遅いと思われたかも知れませんが正常動作している。
※クライアントのタイムアウトエラーはデフォルト30秒となっている。
調査
PostgreSQLのログやアプリケーションのエラーログやIISログなどとDBデータを時系列に一覧化してみたところ、ほぼ1日内で実行するSQLの初回クエリーでタイムアウトエラーになっていることが分かりました。リトライ処理で2回目以降は1秒超と速いのです。ほぼ1日間隔なので何らかのタイミングで何かがリセットされてしまいます。
2回目以降が速い理由
初回はアクセス対象のハッシュテーブルが作られキャッシュ(共有メモリ)します。
2回目以降が速いのは初回のキャッシュされた結果を利用しているからです。
※PostgreSQLの共有メモリのサイズは、postgresql.confのshared_buffersパラメータで指定する。
共有メモリは、各backendプロセスがテーブルやインデックスなどのオブジェクトに接続した際のデータをページ単位でキャッシュし、以後同一ページへのアクセスの際にはキャッシュから取り出してデータを取得できることによってデータへのランダムアクセス応答時間を大幅に低減する。(中略)
PostgreSQLでは、共有バッファを使い切ると利用されていないページをバッファから追い出す(Clocksweepアルゴリズム)ため、追い出されたデータを再読込する場合は処理性能が落ちる。(中略)
仮にshared_buffersから追い出されても、追い出された直後のデータはOSのディスクキャッシュに残っている可能性があるため、バッファへの再読込は比較的高速に行える
PostgreSQL その55 共有メモリ使用量
【2025/04/21追記】
当時はshared_buffersに512MBを指定していました。次記事により4GBに変更しました。
社内による再現方法
問題発生しているSQLに共通しているテーブルがあり、ある列にインデックスを貼ればタイムアウトエラーが改善する見込みはあったのですが、インデックスを貼ると更新処理などに影響があり、本番環境で直接試すわけにはいかないので調査用に問題発生している拠点のPostgreSQLのバックアップを社内のPostgreSQLに復元してみました。
しかし、該当のSQLを実行するのですがタイムアウトエラーになるほど遅くなりません。というか、初回クエリーをどうすれば実現できるのかが分からないのです。
ネットで「PostgreSQL FirstQuery」で検索して見つけたのが下記サイトになります。
Postgresが使用する「キャッシュ」には2つのレベルがあります。
- OSファイルキャッシュ
- 共有バッファ
キャッシュをクリアーすれば初回クエリーを実現できそうです。
キャッシュクリアー
ネットで「PostgreSQL キャッシュクリアー」で検索すると、PostgreSQLを再起動しただけでは共有プールに残されたDBキャッシュのみクリアされて、ファイルシステムに残されたファイルキャッシュは残されるとのこと。
OSファイルキャッシュまでクリアーする方法が下記になります。
Windows
Windowsでは、Micorsoftのサイトから「RAMMap v1.60」をダウンロードして使用します。
下記の3つのファイルが含まれています。
- RAMMap\Eula.txt
- RAMMap\RAMMap.exe
- RAMMap\RAMMap64a.exe ・・・ ARM64アーキテクチャー
RAMMap.exeを実行したら、メインメニューで"Empty"->"Empty Standby List"をクリックします。
※RAMMapはコマンドラインを使用できます。 例 RAMMap.exe -Et
Solving Memory issues with RAMMAP.exe command line
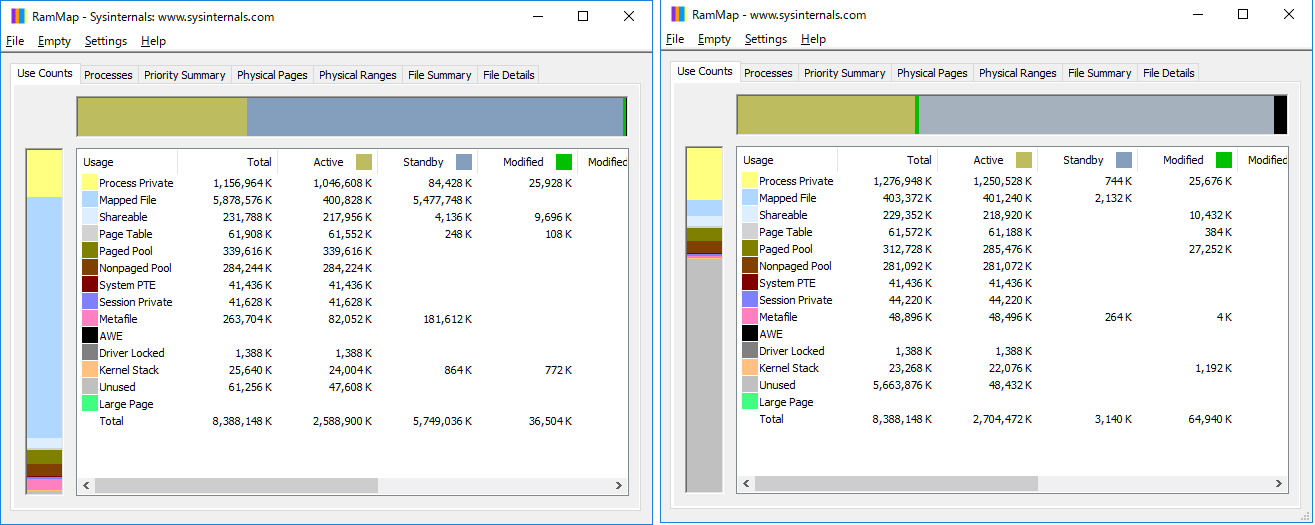
左側が実行前、右側が実行後
Seq Scan on mastertable (cost=0.00..173067.70 rows=1 width=50) (actual time=844.785..844.785 rows=0 loops=1)
Filter: ((ab)::text = 'B0123458'::text)
Rows Removed by Filter: 6053381
Planning time: 14.552 ms
Execution time: 844.805 ms
Seq Scan on mastertable (cost=0.00..173067.70 rows=1 width=50) (actual time=4407.677..4407.677 rows=0 loops=1)
Filter: ((ab)::text = 'B0123458'::text)
Rows Removed by Filter: 6053381
Planning time: 1.482 ms
Execution time: 4407.693 ms
844msが4407msと確かに遅くはなりましたが、タイムアウトエラーになるまでは遅くはなりませんでした。
Linux
#!/usr/bin/sudo bash
service postgresql stop
sync
echo 3 > /proc/sys/vm/drop_caches
service postgresql start
今回はWindowsなので試してないのですが、記事によると「最初に19秒かかり、その後の試行で2秒未満のクエリでテストしました。このスクリプトを実行した後、クエリは再び19秒かかりました。」とのことです。
対応
キャッシュをクリアーすることで初回クリアーが遅くはなりましたが、タイムアウトエラーになるまでは遅くなることはありませんでした。
上長に再現はできないことを伝え、インデックスを貼れば効果があることとインデックスを貼っても更新にそれほど影響が無いことを確認してもらい、本番環境にインデックスを貼ることの許可を頂きました。
インデックスを貼ってから一週間ほどログ等を観察しましたが、タイムアウトエラーは発生しなくなりました。
別件
今回のとは別のアプリケーションでASP.NETを使用しているものがあるのですが、これも初回クエリーが遅いです。最初、ASP.NETだから初回アクセスが遅いのだろうと思っていたのですが、初期化するタイミングはIISとPostgreSQLで違うことがあるわけです。
問題のSQLは複雑ではあるのですが、それなりにインデックスも貼ってありますし何が悪いのか分からないのです。初回クエリー以外は問題ない速度になっているのですから。
Oracleのときはヒント句やバインド変数をリテラルに置き換えて対応したかな。
【Oracle】クエリパラメータ(バインド変数)を使うとパフォーマンスが悪くなることもあるバインドピーク問題
今回は遅いSQLを実行する専用ページを作成して、タスクスケジューラーで朝方1回実行することで初回クエリーの遅さを解消するようにしています。
最後に
拠点では autovacuum はしているものの、メンテナンス以外のタイミングでPostgreSQLサービスの再起動もしていないですし、PC再起動もしていません。
他の拠点ではタイムアウトエラーになっておらず、発生拠点と他の拠点との違いは該当テーブルのデータ件数の違いくらいです。
データベースを復元しても再現しなかったのは、データ件数以外にも何か別の問題があるんだろうな。
今回の調査で、EXPLAINのBUFFERSオプションや「コールドキャッシュ」の問題を解決することを目的とした拡張機能「pg_prewarm」、キャッシュ(shard_buffers)に載っているオブジェクトを確認する拡張機能「pg_buffercache」などがあることが分かったので、何か問題があった時に利用したいです。
EXPLAIN (ANALYZE, BUFFERS) SELECT ...