なぜかあまりやっている人を見ない、ディープラーニングを使用した株価の予想をしてみます。
ディープラーニング、Pythonともに初心者です。ライブラリ、実装方法、理論等は殆ど分かっておりません。ツッコミ等お待ちしています。
目標
- 数日分の株価データを使用して、翌日の日経平均株価が「上がる」か「下がる」か「変わらず」かを予想します。(分類)
概要
- 「上がった」か「下がった」か「変わらず」だったかの判断には翌日の終値をベースに判断。
- 入力データは数日前から前日までの「始値」「高値」「安値」「終値」を使用。
- 隠れ層は4つ。
- 入力として上記過去数日分の株価をぶっこんでトレーニングするだけです。
環境
TensorFlow 0.7
Ubuntu 14.04
Python 2.7
AWS EC2 micro instance
内容
準備
可能な限りの日経平均のデータを用意します。今回はYahooファイナンスのデータを使用しました。
実装
日経平均はテキストにしておきます。(毎回取りに行くと面倒なので)
今回は10日分のデータを見て、翌日の株価を予想することにします。
また、翌日の終値が、前日の終値より0.5%以上ならば「上がった」、0.5%以下ならば「下がった」、それ以外ならば「変わらず」としました。この数字の理由は、ちょうどこの3つが33%程度になるためです。
if array_base[idx][3] > (array_base[idx+1][3] * (1.0+flg_range)):
y_flg_array.append([1., 0., 0.])
up += 1
elif array_base[idx][3] < (array_base[idx+1][3] * (1.0-flg_range)):
y_flg_array.append([0., 0., 1.])
down += 1
else:
y_flg_array.append([0., 1., 0.])
keep += 1
データ全体としての割合は下記の通り。
上がった:33.9%
下がった:32.7%
変わらず:33.4%
グラフ作成
コードはこんな感じ。コピペで若干スパゲッティですが、まぁ見やすいのではないでしょうか。(という言い訳)
def inference(x_ph, keep_prob):
with tf.name_scope('hidden1'):
weights = tf.Variable(tf.truncated_normal([data_num * 4, NUM_HIDDEN1]), name='weights')
biases = tf.Variable(tf.zeros([NUM_HIDDEN1]), name='biases')
hidden1 = tf.nn.sigmoid(tf.matmul(x_ph, weights) + biases)
with tf.name_scope('hidden2'):
weights = tf.Variable(tf.truncated_normal([NUM_HIDDEN1, NUM_HIDDEN2]), name='weights')
biases = tf.Variable(tf.zeros([NUM_HIDDEN2]), name='biases')
hidden2 = tf.nn.sigmoid(tf.matmul(hidden1, weights) + biases)
with tf.name_scope('hidden3'):
weights = tf.Variable(tf.truncated_normal([NUM_HIDDEN2, NUM_HIDDEN3]), name='weights')
biases = tf.Variable(tf.zeros([NUM_HIDDEN3]), name='biases')
hidden3 = tf.nn.sigmoid(tf.matmul(hidden2, weights) + biases)
with tf.name_scope('hidden4'):
weights = tf.Variable(tf.truncated_normal([NUM_HIDDEN3, NUM_HIDDEN4]), name='weights')
biases = tf.Variable(tf.zeros([NUM_HIDDEN4]), name='biases')
hidden4 = tf.nn.sigmoid(tf.matmul(hidden3, weights) + biases)
#DropOut
dropout = tf.nn.dropout(hidden4, keep_prob)
with tf.name_scope('softmax'):
weights = tf.Variable(tf.truncated_normal([NUM_HIDDEN4, 3]), name='weights')
biases = tf.Variable(tf.zeros([3]), name='biases')
y = tf.nn.softmax(tf.matmul(dropout, weights) + biases)
return y
x_phが前日までの株価データが入ったプレースホルダ。[1日前の終値, 1日前の始値, 1日前の高値, 1日前の安値, 2日前の終値, ...]と言った具合にデータが入っています。
なお、隠れ層のユニット数は100, 50, 30, 10です。つまり、下記で定義しています。
# DEFINITION
NUM_HIDDEN1 = 100
NUM_HIDDEN2 = 50
NUM_HIDDEN3 = 30
NUM_HIDDEN4 = 10
ちなみにこのユニット数と層数は適当です。多い方がいいんじゃね?くらいのつもりで決めました。
これらの数を決める指針等あるなら教えていただけると幸いですm(__)m
最適化
最適化はADAMを使用しています。詳しくは知りませんが、経験上、勾配降下法(GradientDescentOptimizer)より発散し辛いイメージ。
def optimize(loss):
optimizer = tf.train.AdamOptimizer(learning_rate)
train_step = optimizer.minimize(loss)
return train_step
訓練
訓練は下記のような感じ。バッチサイズは100にしました。大きすぎるとコケます。(メモリ不足で。ケチらなければ大丈夫です)
def training(sess, train_step, loss, x_train_array, y_flg_train_array):
summary_op = tf.merge_all_summaries()
init = tf.initialize_all_variables()
sess.run(init)
summary_writer = tf.train.SummaryWriter(LOG_DIR, graph_def=sess.graph_def)
for i in range(int(len(x_train_array) / bach_size)):
batch_xs = getBachArray(x_train_array, i * bach_size, bach_size)
batch_ys = getBachArray(y_flg_train_array, i * bach_size, bach_size)
sess.run(train_step, feed_dict={x_ph: batch_xs, y_ph: batch_ys, keep_prob: 0.8})
summary_str = sess.run(summary_op, feed_dict={x_ph: batch_xs, y_ph: batch_ys, keep_prob: 1.0})
summary_writer.add_summary(summary_str, i)
評価
訓練後、下記のように評価。基本的にチュートリアルからのコピペです。
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_ph, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x_ph: x_test_array, y_ph: y_flg_test_array, keep_prob: 1.0}))
結果
TensorBoardで見てみると、下記のように収束しているように見える。
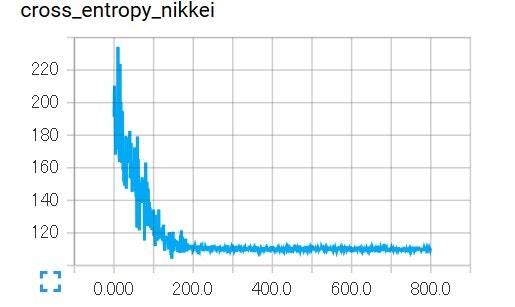
が、正答率を見てみると、
0.3375
惨敗。 ![]()
前述したとおり、各カテゴリ(上がった、下がった、変わらず)の確率が概ね33%なので、当てずっぽうと同じという結果になりました。(笑)
考察
今回の失敗の原因について、原因と考えられるのは下記の通り。
- モデルの構築が不十分?(アドバイスあればお願いします)
- そもそも前日までの株価は翌日の株価に影響を与えない?
- 日経平均は株価の平均なので、そもそもテクニカル的な要素は関係しない?
なお、入力に使う日数、隠れ層の数、ユニット数、活性化関数等を変更して色々試してみましたが、特に結果に変化はありませんでした。 ![]()
所感
行列計算とかディープラーニングとかあまり詳しくありませんが、概要がなんとなく分かってれば、TensorFlowを使ってなんとなくそれらしいことが出来るっぽい! ![]()
参考にしたサイト、ページ、文献
公式チュートリアル
TensorFlow でポケモンの名前から種族値とタイプを予測させる遊び
深層学習 (機械学習プロフェッショナルシリーズ)