作ろうと思ったキッカケ
現在開発中のシステムの裏で定期的に動かしているバッチ(こちらも開発中)が落ちてもCloudWatchのログを見にいくまで分からない そもそも見にいくのすらめんどいからエラーが起きたら通知してもらえばいいじゃん! って魂胆
ほとんどこちらの方の記事の受け売りになります!
最初よく読まないままコードコピペしてもなんとなく動いたので質の良いコードを残して頂けた先人に感謝です
https://qiita.com/onooooo/items/f59c69e30dc5b477f9fd
実現方法
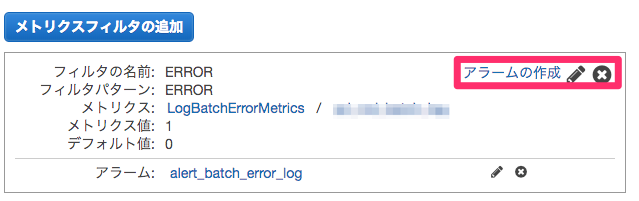
CloudWatchの通知したいロググループに対してメトリクスフィルタを作成する
-
通知させたいロググループを選択し、メトリクスフィルタの作成を押す
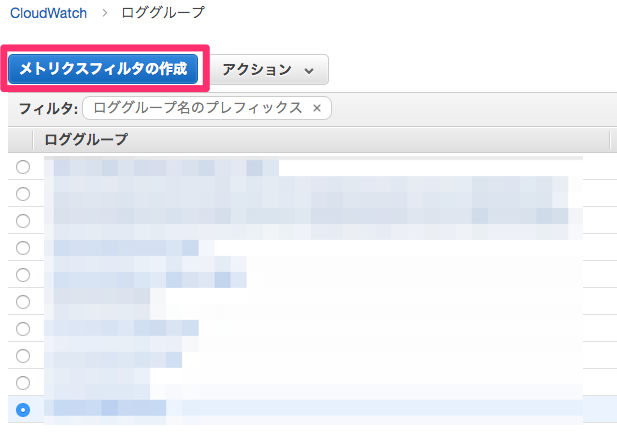
-
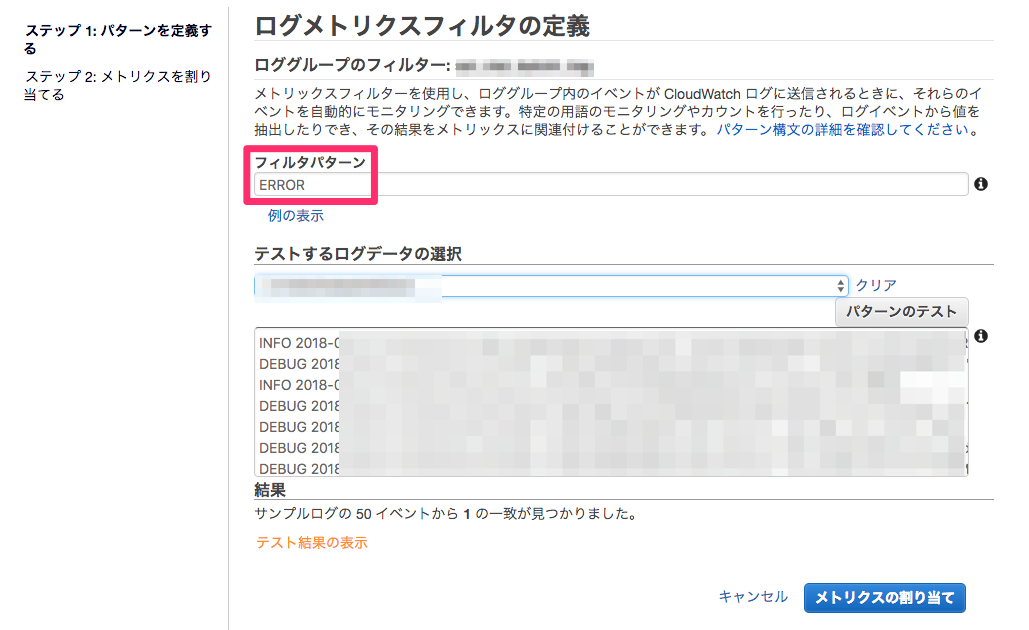
フィルタパターンを定義し、メトリクスを割り当てます。
現在のプロジェクトでは、バッチがエラーを吐いた際のログは全て「ERROR」から始まるため、図のように定義しています。
正規表現等は使用できず、完全一致のみ引っ掛けてくれるみたいです。
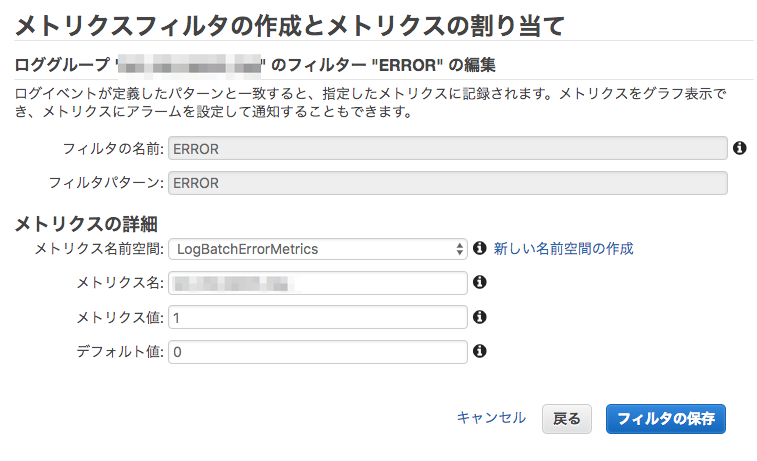
メトリクス値:1
デフォルト値:0
にしている理由は後ほど説明します。
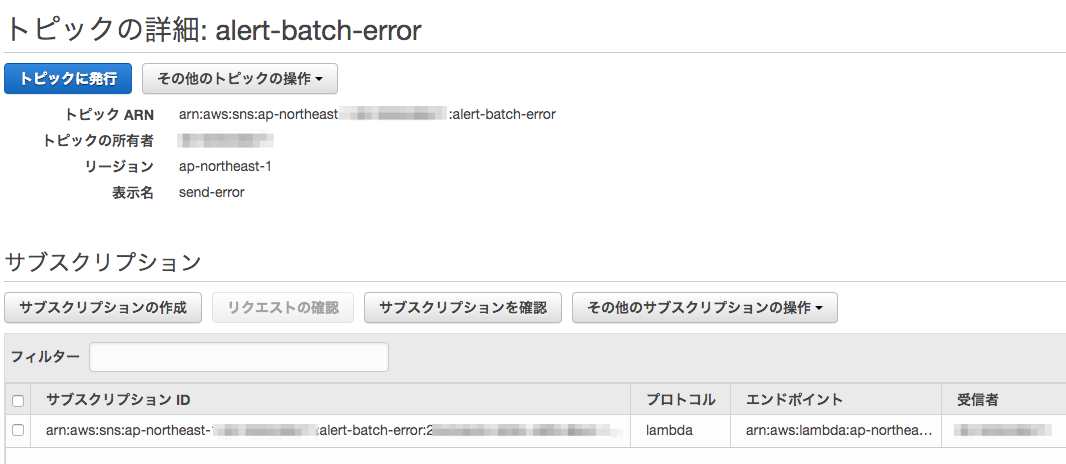
SNSのトピックを作成しましょう
任意の名前でサクッと作ります
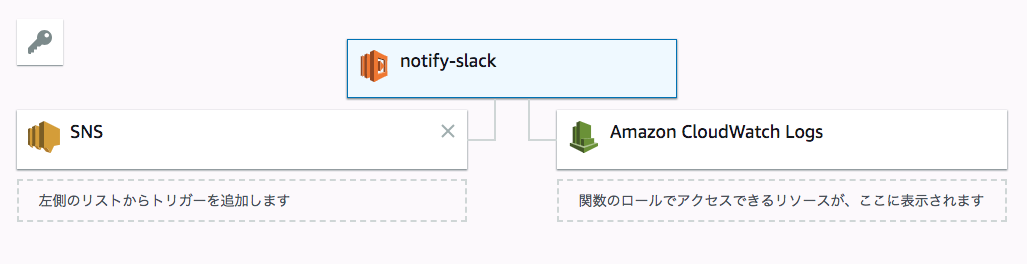
投稿処理を行うLambdaを作成しましょう
構成はこんな感じ
Lambda自体のログを出すかどうかはお好みで
先ほど作成したSNSにサブスクリプションを割り当てます
こんな感じになればOKです
後はLambdaの処理をゴリゴリ書いて行くだけ!
最初に貼った記事に詳しく書かれているのとほぼ同じなのでここは割愛
コードだけ載せて起きます。
例外処理とかもLambda側の例外時に特に通知することはないので落ちとけばいいじゃんってノリで特になし
追加で考慮したのは、複数件検出されたら個々に通知するようにしたくらいです。
(slack上で個々に通知がくるとスタンプでこっちは対応済みとか出来て便利)
TIME_FROM_MINはアラームの間隔よりちょっと長めに設けておいたほうが良さそう?
import json
import logging
import os
import datetime
import calendar
import slackweb
import boto3
# slackの設定
HOOK_URL = os.environ['HOOK_URL']
slack = slackweb.Slack(url=HOOK_URL)
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# 抽出するログデータの最大件数
OUTPUT_LIMIT=5
# 何分前までを抽出対象期間とするか
TIME_FROM_MIN=5
def lambda_handler(event, context):
logger.info("Event: " + str(event))
message = json.loads(event['Records'][0]['Sns']['Message'])
logs = boto3.client('logs')
# MetricNameとNamespaceをキーにメトリクスフィルタの情報を取得する。
metricfilters = logs.describe_metric_filters(
metricName = message['Trigger']['MetricName'] ,
metricNamespace = message['Trigger']['Namespace']
)
logger.info("Metricfilters: " + str(metricfilters))
#ログストリームの抽出対象時刻をUNIXタイムに変換(取得期間は TIME_FROM_MIN 分前以降)
#終了時刻はアラーム発生時刻の1分後
timeto = datetime.datetime.strptime(message['StateChangeTime'][:19] ,'%Y-%m-%dT%H:%M:%S') + datetime.timedelta(minutes=1)
u_to = calendar.timegm(timeto.utctimetuple()) * 1000
#開始時刻は終了時刻のTIME_FROM_MIN分前
timefrom = timeto - datetime.timedelta(minutes=TIME_FROM_MIN)
u_from = calendar.timegm(timefrom.utctimetuple()) * 1000
# ログストリームからログデータを取得
response = logs.filter_log_events(
logGroupName = metricfilters['metricFilters'][0]['logGroupName'] ,
filterPattern = metricfilters['metricFilters'][0]['filterPattern'],
startTime = u_from,
endTime = u_to,
limit = OUTPUT_LIMIT
)
# メッセージを整形しつつslackに通知
for event in response['events']:
postText = '''
{logStreamName}
{message}
'''.format( logStreamName=str(event['logStreamName']),
message=str(event['message'])).strip()
response = slack.notify(text=postText)
logger.info("Response: " + str(response))
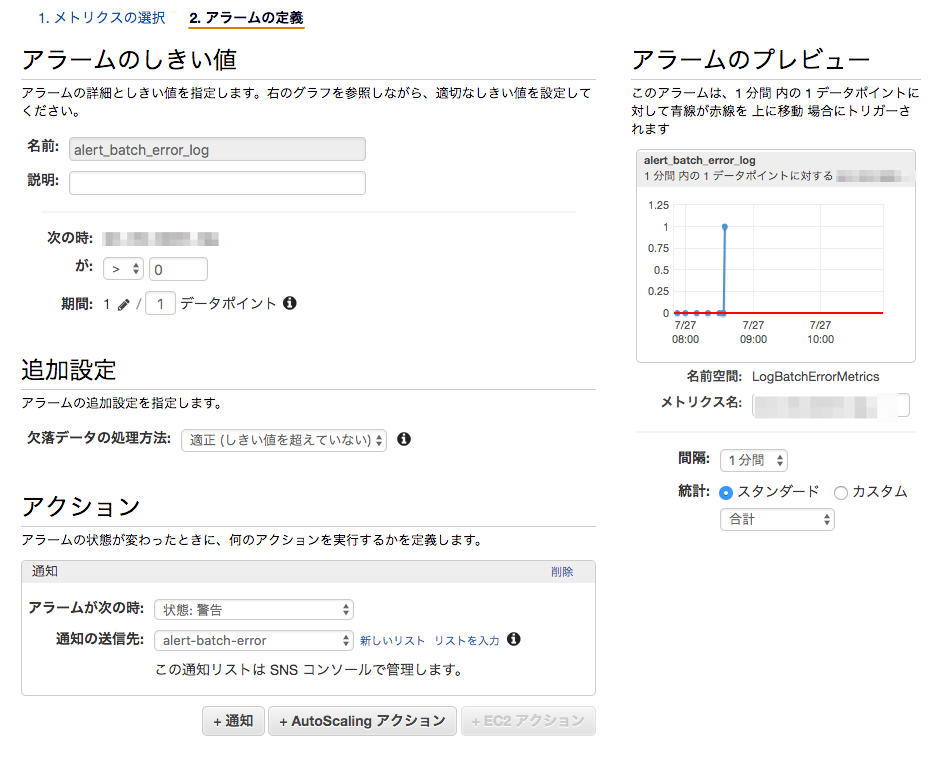
最後にアラームを設定してあげます
図では既にアラームが設定されているのですが、先ほど作成したメトリクスフィルタを確認しに行くとこんな感じの画面に辿り着くと思うのでそこから設定していきます
図のように設定しました
注意したいのは欠落データの処理方法で、欠落時は適正を選択してあげることです。
このアラームで通知処理が走るのは、あくまでもアラームの状態が適正→警告になったときのみなので、
これをしないとバッチの間隔が開いていて、前のバッチが落ちて次のバッチも落ちましたってなったときにアラームが適正内に戻ってくれてないので、通知が来なくなります。
また、メトリクスフィルタ作成時にデフォルト値に0を設定したのは、エラー時以外のログ出力の際はグラフに0をプロットしてもらうためです。
図では1分間隔での検出ですが、Amazonさんに追加課金すればもっと短い間隔での検出も可能です。
Lambda側のコードを見れば分かると思いますが、検出間隔が広いからといってエラーログの検出漏れが起こることはありません
ここまでやってめでたくエラーの検出が自動化されました。
完成したらバッチがエラー吐いた時にこんな感じに煽ってきてくれます

課題ってか知ってる人がいたら教えて
個人的にはこのアラームの設定をすると状態がOK→ALARMになった後、1分後には0がプロットされて適正に戻るのかなと思っていたのですが、ALARM→OKになるまでに大体5〜6分程度かかっちゃいます(たまに1分で戻ってることもあって謎)
1分以上メトリクスからのデータが来なかったら欠落データとして適正内に戻るかなと思っていたのですが、どうやらそうじゃないみたいです
そうなるとALARM状態中に追加でエラーが発生した際にそれが通知されない場合が出てくるかもしれません。
公式ドキュメント 読み漁ってもよく分からなかった...

↑何となくわかった
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data
と
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/FilterAndPatternSyntax.html#changing-default-increment-value
の
xxx分の間にログが取り込まれても一致が見つからない場合は、デフォルト値に設定された値 (存在する場合) が報告されます。ただし、xxx分の間に取り込まれたログイベントがない場合は、値は報告されません。
のせいでエラー多発時の発生タイミングによってはすり抜けが出てくる
課金して高解像度アラームにすると大幅に取りこぼし率を減らせる
課金は正義