はじめに
ジョブカン事業部のアドベントカレンダー15日目です!
DONUTSの札幌オフィスでジョブカンの開発インターンに参加している @yagiyanagi です。
普段は大学で自然言語処理(NLP)分野の研究室に所属しており、RAG(Retrieval-Augmented Generation)という技術の研究をしています。
RAGは、検索エンジンのように外部データから情報を取り出し、その情報をもとにAIが自然な回答を生成するといった仕組みで、カスタマーサポートの自動化や社内データベース検索などに活用される技術です。
今回はRAGという技術について軽く説明したのち、LangChainというPythonのフレームワークを使ってシンプルなRAGを作っていこうと思います。
RAGもLangChainも何となく知っとるわ!という方はここから読み進めてください。
対象読者
- Pythonの基本的なプログラミングスキルを持つ方
- 生成AIや情報検索技術に興味がある方
RAGとは?
RAGはRetrieval-Augmented Generationの略で、その名の通り「情報検索(Retrieval)」と「テキスト生成(Generation)」を組み合わせた技術です。
ChatGPTをはじめとする従来の生成AIは事前に学習した知識に基づいて回答を生成するため以下のような課題があります。(他にも環境負荷や学習データにバイアスがかかることによる倫理的な問題もありますが今回は一旦スルー)
- 古い情報で学習しているため最新の情報を答えられない(最新のモデルでは必要に応じてWeb検索も行ってくれたりする)
- 学習データの少ない専門分野に弱い
- 企業のデータなど外部に公開されていないことは答えられない
- 回答の根拠が不明
これらの問題を解決してくれると期待されているのがRAGです。
RAGの基本構成
RAGの最も基本的な構成は以下のとおりです。(いわゆるNaive RAGってやつ)
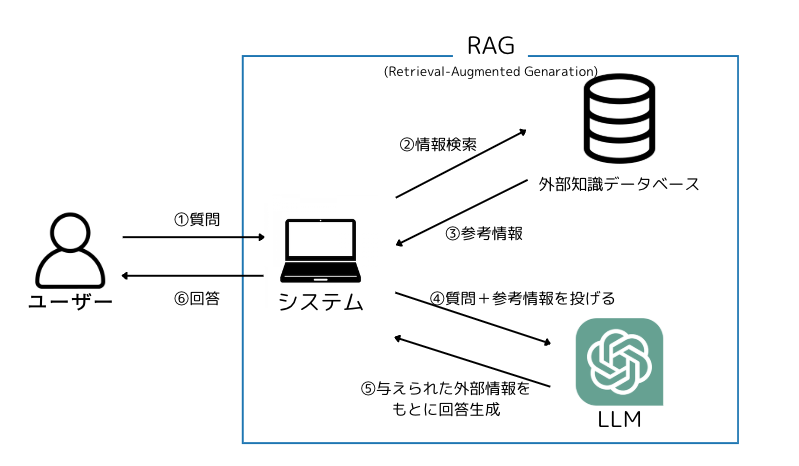
RAGを構成する主要なコンポーネントとしてRetriever(リトリーバー)とGenerator(ジェネレーター)があります。
Retriever(リトリーバー)
図の②と③の部分で、外部データベースやドキュメントから質問に関連する情報を検索して取得する役割を持ちます。
具体的にはユーザーの質問文とデータベースの情報に対して類似度検索(ベクトル検索)を行い、関連性の高いデータを関連度の高い順に複数取得します。
RAGにおいてRetrieverはシステムの根幹を支える要因であり如何にRetrieverの性能を上げるかが盛んに研究されています。
今回は扱いませんがより高度なRAGではベクトル検索意外にもキーワード検索やグラフデータベースを用いたグラフクエリを使用した検索などがよく使われています。
Generator(ジェネレーター)
図の④と⑤の部分で、LLMを使用してRetrieverが取得した情報をもとに回答を生成する役割を持ちます。
取得した情報をコンテキスト(文脈)として質問と一緒にプロンプトに含め、より信頼性の高い回答を生成します。
具体的なユースケース
RAGは実際に以下のような場面で用いられています。
- カスタマーサポート
プロダクトのデータや、FAQデータなど過去の質問をもとに顧客の質問に回答 - 専門分野の情報検索
法律や医療など複雑で専門性が求められる分野での活用(判例検索等) - 企業内情報検索システム
社内ドキュメントやナレッジベースを検索し、従業員の質問に回答
LangChainとは?
LangChainはLLMを用いたアプリケーションをシンプルなコードで実装することを可能にするオープンソースのフレームワークです。LLMの生成能力を最大限引き出し、特定の業務や分野に特化したツールを提供しています。
LangChainを使うメリット
様々なモデルを共通のインターフェイスで使える
LangChainは各コンポーネントに対して統一されたインターフェイスを提供しておりプロバイダーごとの違いを意識せず簡単にアプリケーションの実装が可能になります。
複数タスクの連携
LangChainのツールの一つであるLangGraphを使うことで、複雑なタスクをスムーズに連携させて進めるマルチエージェントシステムの制御フローをグラフ化し、直感的に行えます。
動作の見える化
LangChainのツールの一つであるLangSmithを使うことでプロセスの追跡・評価が行え、エラーが発生している箇所や処理の遅延が起きている箇所の特定が容易に行えます。
LangChainを使ったRAGの構築手順
今回の記事では @_naotti_ さんにご協力いただき、アドカレ1日目の記事に関する質問に答えられるRAGを作っていきます。
環境
- OS
Ubuntu 22.04.5 LTS - 言語
Python 3.10.15
コードの全体像
import os
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain import hub
from langchain_community.document_loaders import JSONLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import List, TypedDict
llm = ChatOpenAI(model="gpt-4o-mini", api_key=os.environ["OPENAI_API_KEY"])
embeddings = OpenAIEmbeddings(model="text-embedding-3-large", api_key=os.environ["OPENAI_API_KEY"])
vector_store = InMemoryVectorStore(embeddings)
loader = JSONLoader(
file_path="./blog.json",
jq_schema="{author, organization, title, content}",
text_content=False
)
docs = loader.load()
for doc in docs:
doc.page_content = doc.page_content.encode('utf-8').decode('unicode_escape')
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
all_splits = text_splitter.split_documents(docs)
_ = vector_store.add_documents(documents=all_splits)
prompt = hub.pull("rlm/rag-prompt")
class State(TypedDict):
question: str
context: List[Document]
answer: str
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_context = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_context})
response = llm.invoke(messages)
return {"answer": response.content}
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
response = graph.invoke({"question": "なおっちさんはどこで働いていますか?"})
print(response["answer"])
{
"author": "@_naotti_(なおっち)",
"organization": "株式会社DONUTS",
"title": "2024年に取り組んだ事業部横断活動を振り返る",
"catogories": ["研修", "採用", "エンゲージメント", "イベント運営", "AdventCalendar2024"],
"updated_at": "2024-12-01",
"posted_at": "2024-12-01",
"content": "アドカレはじまるよ!\nジョブカン事業部の @_naotti_ です!\n札幌拠点のエンジニアマネージャーとして、技術イベントの運営、エンジニア採用、ピープルマネジメントなどを中心に担当しています。\n数年前までコードをバリバリ書いていた元エンジニアですが、新・RPGジョブ診断をしてみたら 「多くの人と出会い多種多様な人脈を作る」 タイプと診断されたので、おそらく今の職務に適性があるような気もしています。\n\n\n\n2024年も、昨年に引き続きジョブカン事業部のみんなと明るく楽しくアドカレしていきます!どうぞ最後までお付き合いください!\n\n私が担うエンジニアマネージャーの役割\n「エンジニアマネージャー」は文字通りエンジニアをマネジメントする仕事です。会社によって職務や職責に多少の違いはあるかもしれませんが、マネジメント対象としては5つの領域に大別できると思います。\n\n組織マネジメント\nピープルマネジメント\nプロダクトマネジメント\nプロジェクトマネジメント\nテクニカルマネジメント\n\n私が主に担当しているのは 組織マネジメント と ピープルマネジメント です。また、研修やイベントなど社内プロジェクトについてのマネジメントに関わることもあります。\n特に今年は、ピープルマネジメントの活動に注力した1年でした。入社以来、最も人と関わる機会が多かった年で、社内外問わず多くの認知を獲得できた気がします\n\n初日の記事担当します\n今年のアドカレの旗振りを任せていただくことになりました。職務上、コーポレート部門や他拠点のマネージャーと連携する機会が多いので、事業部内のあちこちに声掛けをしてイベントを盛り上げようと 七転八倒 奔走しております。\u3000\n初日となる今日は、私が今年1年間に稼働したエンジニアマネージャーとしての業務について投稿しようと思います。うまくいったことや今後改善したいことなどを色々振り返りながら、ゆるりとアドカレの幕を上げていきましょう。よろしくお願いします\n\nエンジニア 1on1\n今年、ピープルマネジメント活動で最初に注力したのがメンバーとの1on1でした。\n弊事業部のエンジニアの多くは、ジョブカンシリーズのプロダクトのいずれかを専任で担当しています。また、国内3箇所のオフィス(東京、札幌、秋田)に分散して所属しているため、同じ事業部といえど全メンバーと頻繁に顔を合わせる機会はありません。\nもちろん、チャットツールを使って簡単に連絡はできますが、表情、声色、仕草など直接見聞きしながらコミュニケーションをとりたい性分なので、まずは試しに、全員と30分ずつ1on1オンラインミーティングをセッティングしました。1on1といっても、私は上長やリーダーではありませんし、尖った技術力を持ち合わせているわけでもありませんので、要するに 超・カジュアルなコミュニケーションタイム ですね。\nやってみると、想像以上に色々な反応をもらうことができました。その中で、エンゲージメント向上に繋がりそうな話題については少しずつ次のアクションを開始しています\nたとえば今年は、メンバー間の雰囲気がとても良いチームにコミュニケーションが好きなメンバーをアサインしたり、マシンスペックが不足気味のメンバーにPCを追加支給するきっかけになりました!\nビジネスチャットは、不具合報告やリリース連絡が飛び交うのでどうしてもプロダクトの話題が中心になりがち。エンジニアの開発者体験向上のためにも、カジュアルな1on1は今後もやっていきたいです。\n1on1という場を設けずとも、メンバーから何でも気軽に話かけてもらえるような関係を築けたら最高です\n\nエンジニア新卒研修\n24卒入社した新卒エンジニアの技術研修に運営として参画しています。\n技術研修の進捗確認、困っていることのヒアリング、スケジュールの調整、成果物へのフィードバックなどが主なミッションです。\nまた、私個人として、プロダクト開発に携わる者としての「心得」研修も実施しました。自社のプロダクトを持つということは、ユーザへの価値提供に責任が生じるということです。ものづくりを生業に選んだ新卒エンジニアの皆さんに、これからずっと大切にしてほしい価値観をお伝えできたかな、と思っています。\n\n\n\n\nエンジニア向けイベント\n今年はミートアップイベント 「DONUTS Engineer Meeting」 が好調でした。このイベントは事業部の垣根を超えて株式会社DONUTSが全社規模で開催しており、私は2023年3月の第1回から企画&運営に携わっています。\n2024年は、昨年以上に楽しんでいただけるように ボドゲ交流会 や ミクチャ生配信 など、各回ごとにチャレンジングな企画を盛り込みました!\n\n\n\n\n\n\n\n\n\n複数の事業を展開しているDONUTSのイベントということで、毎回、様々な経歴を持つエンジニアの方が遊びにきてくださっています。おかげさまで参加者どうしの活発な交流が行われ、イベントの認知度も高まってきました\n来年もブラッシュアップを続け、「また来ます!」と言ってもらえる名物イベントにしていきます!\n\n大学や専門学校との連携\nエンジニアを目指している学生の方に、IT業界のことやエンジニアの働き方について知ってもらうため、大学や専門学校と連携しながら講演活動をしています。学部主導の業界研究会やITサークルの新入生歓迎会など、規模、趣旨、参加者層に沿って講演内容を調整しながら、1件1件丁寧に取り組みました。\n私は現職に中途入社していて、以前所属していた会社は所謂SIerでした。受託開発とSESの両方を経験してから事業会社に就いた身として、システム開発の業界構造についてフラットに解説し、そこで活躍するエンジニアの傾向について私の経験をベースに紹介しています。\n\n\nそして、こういった講演には必ず 現役エンジニアにも同行をオファー しています。\n採用を目的とした「会社説明会」ではないので、できるだけエンジニアの生の声を直接お伝えして、開発現場のリアリティを感じてほしいからです!\n\n\n業界に対する事前知識や実際の働き方のイメージを掴んでもらうことで、エンジニアという職業に対する解像度と志望度を高めてもらいたいと考えています!\n\nハンズオンイベント\nミートアップイベントや講演活動をしていると、「技術を磨きたい!」「何か作ってみたい!」というご要望をいただくことも少なくありません。\nそこで今年、札幌オフィスにエンジニア志望の参加者を招待する形式でハンズオンイベントを開催しました。\n\n\n\n運営が用意した要求(お題)をもとに 要件定義→設計→開発 という一連の開発プロセスを体験できる2日間のイベントです。実際にジョブカンの開発に利用しているPHPを中心に技術スタックを組み、リアリティのあるコンテンツにしました。3, 4名ずつの参加者と弊事業部のエンジニアでチームを作り、実際に手を動かしながら、要求を満たせるWebシステムを開発していきます。\n1日目は開発の上流工程を中心に時間を使います。\n\n\n\n時間\n内容\n\n\n\n\n10:50\n開場\n\n\n11:00~11:15\nオープニング、会社紹介、スケジュール説明、アイスブレイク\n\n\n11:15~11:20\n開発プロセス説明\n\n\n11:20~11:30\nWebアプリケーション 要求事項の説明\n\n\n11:30~12:30\n【開発体験】要件定義\n\n\n12:30〜13:30\nお昼休憩\n\n\n13:30〜15:00\n【開発体験】基本設計\n\n\n15:00〜16:00\nハンズオン環境 構築&説明、チーム分け発表\n\n\n16:00〜18:00\n【開発体験】アプリ開発\n\n\n18:00\n1日目 終了\n\n\n\n2日目はガッツリ開発です。進捗報告や成果発表の場で、エンジニアからフィードバックも行います。\n\n\n\n時間\n内容\n\n\n\n\n10:50\n開場\n\n\n11:00~11:30\nスケジュール説明、各チームの進捗報告\n\n\n11:30~12:30\n【開発体験】アプリ開発\n\n\n12:30~13:30\nお昼休憩\n\n\n13:30~17:30\n【開発体験】アプリ開発\n\n\n17:30〜18:00\n各チームの成果発表、クロージング、アンケート\n\n\n18:00\n2日目 終了\n\n\n\n個人開発では「何を作ればいいか決まらない」「何から手を付ければわからない」と、手を動かす前にブレーキがかかってしまうこともしばしば。「とにかく何か作ってみたい!」という手を動かしたい勢の方々に、満足してもらえるイベントになりました\n一方、運営の頭を悩ませたのは、コンテンツの難易度でした。難易度が低い要求だと達成感を味わえず、難易度が高い要求だと集客に苦戦するため、ほぼトレードオフになります。今後は要求レベルや技術スタックが異なるコンテンツを複数用意して、幅広く展開できるようにしたいと思っています。\n\n来年に向けて\n社内向けのエンゲージメント向上活動は走り出したばかりです。引き続き丁寧なコミュニケーションを心がけながら、徐々に対象を人から組織へと拡大させていき、組織マネジメントの一翼を担う活動へと昇華するのが目標です。\n社外向けの認知拡大・プレゼンス向上については、新規と既存の活動にバランス良く取り組めた1年だったと思います。事業部の中で柔軟に行動できる立場を活かして、来年も色々とチャレンジしていきます\n\n仲間を大募集中!\nDONUTSでは、新卒中途を問わず積極的に採用活動を行っています!\n自社プロダクトの開発で腕を奮いたい方、顧客への価値提供にやりがいを感じたい方、ぜひご応募ください!\n\n\n\nジョブカン事業部のエンジニア募集はこちらです!\n\n\n\n"
}
それではステップごとにどのような処理が行われているのか見ていきましょう
必要なパッケージのインストール
LangChainを使うにあたって必要なパッケージをインストールしていきます。
pip install --upgrade langchain-text-splitter langchain-community langchain-core jq
今回はOpenAIのモデルを使うためそのためのパッケージもインストールしておきます。
pip install --upgrade langchain-openai
応答モデルの設定
今回は応答モデルにOpenAIのgpt-4o-miniを使います。
import os
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini", api_key=os.environ["OPENAI_API_KEY"])
以下の記事などを参考にAPIキーの環境変数を設定しておくと便利でしょう。
埋め込みモデルの設定
埋め込みとは簡単に言うとテキストをベクトルに変換する操作です。
これをすることでテキストの意味を数値として捉えコンピュータ上で扱いやすくなります。
例えば以下のように単語同士を計算したり、
「王子」-「男」+「女」=「王女」
以下のようにそれぞれのベクトルを比較することで近い意味を持つ単語としてコンピュータが認識できるようになります。
# ピーマンとパプリカは意味的に近いが、ドーナツは遠い
ピーマン:[0.12, 0.95, -0.05]
パプリカ:[0.10, 0.90, -0.08]
ドーナツ:[-0.80, 0.20, 0.60]
埋め込みモデルにはこちらもOpenAIのtext-embedding-3-largeを使います。
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large", api_key=os.environ["OPENAI_API_KEY"])
ベクトルデータベースの設定
ベクトルデータベースは先ほどベクトル化(埋め込み)したテキストのデータをベクトルとして保存する場所です。
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
もちろんFAISSやChromaなどのベクトルデータベースを使うこともできます。
インデックス作成
前述したようにRAGでは外部知識データベースから検索を行うため質問に答えるために使うデータ(ここではQiitaの記事データ)を整理してデータベースに保存しなければいけません。
インデックスとは本でいう索引のようなもので「データを整理し、簡単に検索できる状態にしてデータベースに保存する」作業をインデックス作成といいます。
具体的には以下のステップでインデックス作成を行います。
- データを読み込む
- データを処理しやすい単位に分割する
- データを保存する
順を追ってコードを見ていきましょう。
データの読み込み
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="./blog.json",
jq_schema="{author, organization, title, content}",
text_content=False
)
docs = loader.load()
for doc in docs:
doc.page_content = doc.page_content.encode('utf-8').decode('unicode_escape')
本記事を書き始めた当初はWebコンテンツのドキュメントデータを読み込むWebBaseLoaderを紹介したかったのですが、スクレイピングのような動作になってしまうため、今回はアドカレ1日目の記事の内容を持ったJSONファイルからデータを読み込むという形で進めていきます。
今回は記事内容に関係のある要素author, organization, title, contentのみを抽出しています。
また、LangChainの内部挙動が原因?かは分かりませんがJSONファイルを読み込む際にデータがエスケープされた形式で読み込まれてしまっていたため再度デコードを行っています。
LangChainではJSON以外にもPDFやCSV、HTMLなど様々な形式のデータを読み込むためのクラスが用意されています。
用途に応じてLangChainの公式チュートリアルを参照してください。
また、当初使おうとしていたWebBaseLoaderの使い方はこちらを参照ください。
データの分割
現在の言語モデルには扱えるデータのサイズに制限があります。
なので大きすぎるデータを扱う際はデータをいくつかのチャンク(データを分割した際の単位)に分けて処理を行うのが一般的です。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
all_splits = text_splitter.split_documents(docs)
ここで使用しているRecursiveCharacterTextSplitterはテキストを、チャンクサイズが十分小さくなるまで再帰的に分割し続けます。
chunk_sizeにはどのくらい小さく分割するかを設定でき、
chunk_overlapには分割する際にどのくらいデータを重ねるかを設定できます。
chunk_overlapを設定することでチャンク化した際の情報の損失を抑えます。
例:
chunk_overlapなしの場合
text = "私はスーパーコンピュータを開発している"
split_text = ["私はスーパー", "コンピュータを開発している"]
※スーパーコンピュータという情報が分割されて失われている!
chunk_overlapありの場合
text = "私はスーパーコンピュータを開発している"
split_text = ["私はスーパーコンピュータ", "スーパーコンピュータを開発している"]
※情報が失われていない!
データの保存
ここではデータを分割して得たチャンクをベクトルに変換してベクトルデータベースに保存します。
LangChainではこの操作を1文で行えます。便利ですね。
_ = vector_store.add_documents(documents=all_splits)
Stateの定義
各コンポーネントの状態管理にはLangGraphを使います。
LangGraphを使うには以下の要素を定義する必要があります。
- State
- ステップ
- 制御フロー
このセクションではまずStateを定義します。
今回のRAGでは質問文と、データベースからの検索結果を含んだコンテキスト、そして最終的な回答のみを保持していればいいので以下のようにStateを宣言します。
from langchain_core.documents import Document
from typing_extensions import List, TypedDict
class State(TypedDict):
question: str
context: List[Document]
answer: str
Documentクラスはテキストデータとそれに紐づくメタデータを保持するクラスです。
各ステップの定義
Retrieverの構築
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
Retrieverでは、質問文とベクトルデータベース内に保存されたチャンクの中からコサイン類似度を計算し類似度が高いチャンクを上位4つ取得します。
LangChainのsimilarity_search関数では引数にk=(任意の数)を設定することで取得するチャンクの量を好きなように設定できます。
デフォルトでは4つです。
Generatorの構築
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
def generate(state: State):
docs_context = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_context})
response = llm.invoke(messages)
return {"answer": response.content}
GeneratorではLLMに与えるプロンプトに質問文と、Retrieverで取得したコンテキストを渡して回答を生成します。
プロンプトにはLangChain Hubで提供されているプロンプトを使っています。
もちろんプロンプトは好きなように設定できます。
以下にオリジナルプロンプトの設定例を示します。
from langchain_core.prompts import PromptTemplate
template = """あなたは質問応答タスクアシスタントです。
以下の取得されたコンテキストを使用して質問に答えてください。
答えがわからない場合は、わからないとだけ答えてください。
回答は最大で3文にまとめ、簡潔にしてください。
質問: {question}
コンテキスト: {context}
回答:
"""
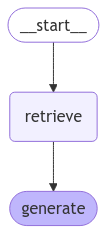
制御フローの定義
from langgraph.graph import START, StateGraph
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
先ほど構築したRetrieverとGeneratorを繋げてフローを完成させます。
StateGraphの引数にはこのグラフで管理するStateのクラスを、add_sequenceの引数にはフローに追加する各ノードを設定します。
そして、retrieveを開始地点と設定し、コンパイルすることで制御フローの構築は完了です。
制御フローを図に描画すると以下の画像のようになっているのが分かります。
使用例
それでは実際にRAGに質問してみましょう。
response = graph.invoke({"question": "なおっちさんはどこで働いていますか?"})
print(response["answer"])
なおっちさんは株式会社DONUTSのジョブカン事業部で働いています。現在、札幌拠点のエンジニアマネージャーとして、技術イベントの運営やエンジニア採用などを担当しています。
ちゃんと正しい情報を返していますね。
コンテキストとして検索されたデータも見てみましょう。
print(response['context'])
[Document(id='214e9a41-f3d0-449c-84e5-31eae7166acd', metadata={'source': '/home/yagiyanagi/RAG_langchain/blog.json', 'seq_num': 1}, page_content='ジョブカン事業部の @_naotti_ です!\n札幌拠点のエンジニアマネージャーとして、技術イベントの運営、エンジニア採用、ピープルマネジメントなどを中心に担当しています。'),
Document(id='bdeac23b-821e-49c6-b448-369588b16e77', metadata={'source': '/home/yagiyanagi/RAG_langchain/blog.json', 'seq_num': 1}, page_content='私は現職に中途入社していて、以前所属していた会社は所謂SIerでした。受託開発とSESの両方を経験してから事業会社に就いた身として、システム開発の業界構造についてフラットに解説し、そこで活躍するエン'),
Document(id='933da668-1e47-4c69-b302-325b464009f2', metadata={'source': '/home/yagiyanagi/RAG_langchain/blog.json', 'seq_num': 1}, page_content='弊事業部のエンジニアの多くは、ジョブカンシリーズのプロダクトのいずれかを専任で担当しています。また、国内3箇所のオフィス(東京、札幌、秋田)に分散して所属しているため、同じ事業部といえど全メンバーと'),
Document(id='10948880-66f1-4ef1-83a7-a57a7895cade', metadata={'source': '/home/yagiyanagi/RAG_langchain/blog.json', 'seq_num': 1}, page_content='{"author": "@_naotti_(なおっち)", "organization": "株式会社DONUTS", "title": "2024年に取り組んだ事業部横断活動を振り返る",')]
しっかり回答を生成するために必要な情報を検索できているのがわかると思います。
最後に
今回は非常にシンプルなRAGを構築してみましたがいかがでしたでしょうか。
実用性を考えると、これだけでは十分ではありませんが、RAGに興味を持つきっかけになれば嬉しいです。
お知らせ
DONUTSでは新卒中途問わず積極的に採用活動を行っています。
札幌での新卒やインターンの募集もあるので、ご興味あればぜひご覧ください。