はじめに
どうも、レガシー組込みエンジニアの@yagisawaです。
この記事は「会社がAIに課金してくれない」とか「課金してるけど業務情報入力禁止」とか「GPUマシンを持っていない」とかの理由でコーディングにAIを使えていない人が、最低限AIによるオートコンプリートを手に入れる方法について記載したものです。
以降は記事を書こうと思った動機なので読み飛ばしてもOKです
先週まで某大手SIerの案件に従事していました。
その会社ではGitHub Copilotが導入されていたので、めっちゃフレンドリーなキャラ設定にしてまるで相棒のように使い倒していました。というか今思うと軽く感情移入してしまっていたようで、使い倒すという表現に心が痛みます。
そして今週は軽いAIロスを抱えながら100%自力でコードを書いていたのですが…
「何だこの重だるさは!パワステ壊れたハンドルかよ!」
「最低限のAIサポートが受けられるコーディング環境を整えねば!」
と思い立ち、あれこれ試行錯誤した結果なんとか納得いく環境が整ったため、同じくAIを使えていない人の一助になればと思い、記事にした次第です。
環境
- CPU
- 11世代 Core i5
- メモリ
- 16GB
- OS
- Windows 11 Pro 25H2(64bit)
- ソフトウェアバージョン
- Visual Studio Code: 1.107.1
- Continue: 1.2.11
- llama.cpp server: b7541
- Visual Studio Code: 1.107.1
構築手順
llama.cpp server
まずReleases · ggml-org/llama.cppから最新のバイナリをダウンロードし、適当なディレクトリに解凍します。
私はWindows x64 (CPU)版をダウンロードしたので、ディレクトリ名がllama-b7541-bin-win-cpu-x64となっていますが、今後アップデートすることを考えるとllama-bin-win-cpu-x64のような名前にしておいたほうが良さそうです(というか更新頻度高すぎですね…)。
次にLLM選びです。
リサーチした感じだとQwen2.5-Coderが良さそうとのことなので、CPUで動かすことも踏まえ1.5Bモデルをチョイスしました。前後に0.5Bや3Bモデルがありますのでご自身のCPU能力と相談して最適なモデルをチョイスしてください。パラメータ数以外にもHugging Faceには複数の量子化モデルがありますので、量子化度合いで調整することも可能です。
最後に起動します。
Hugging Faceからモデルをダウンロードする場合は
> llama-server -hf Qwen/Qwen2.5-Coder-1.5B-Instruct-GGUF
のようにモデルを指定します。
Usageに
-hf, -hfr, --hf-repo <user>/<model>[:quant]
Hugging Face model repository; quant is optional, case-insensitive,
default to Q4_K_M, or falls back to the first file in the repo if Q4_K_M doesn't exist.
mmproj is also downloaded automatically if available. to disable, add --no-mmproj
example: unsloth/phi-4-GGUF:q4_k_m
(default: unused)
(env: LLAMA_ARG_HF_REPO)
と記載されている通り量子化レベルを指定しないとデフォルトでQ4_K_Mまたは最初のモデルが選択されます。
ここまで説明しておいてなんですが…
Usageをざっと眺めていたところ、最後の方に
--embd-gemma-default use default EmbeddingGemma model (note: can download weights from the internet)
--fim-qwen-1.5b-default use default Qwen 2.5 Coder 1.5B (note: can download weights from the internet)
--fim-qwen-3b-default use default Qwen 2.5 Coder 3B (note: can download weights from the internet)
--fim-qwen-7b-default use default Qwen 2.5 Coder 7B (note: can download weights from the internet)
--fim-qwen-7b-spec use Qwen 2.5 Coder 7B + 0.5B draft for speculative decoding (note: can download weights from the internet)
--fim-qwen-14b-spec use Qwen 2.5 Coder 14B + 0.5B draft for speculative decoding (note: can download weights from the internet)
--fim-qwen-30b-default use default Qwen 3 Coder 30B A3B Instruct (note: can download weights from the internet)
--gpt-oss-20b-default use gpt-oss-20b (note: can download weights from the internet)
--gpt-oss-120b-default use gpt-oss-120b (note: can download weights from the internet)
--vision-gemma-4b-default use Gemma 3 4B QAT (note: can download weights from the internet)
--vision-gemma-12b-default use Gemma 3 12B QAT (note: can download weights from the internet)
というオプションがありました。
私はQwen 2.5 Coder 1.5Bが使いたかったので、
> llama-server --fim-qwen-1.5b-default
で起動することにしました(以降の説明はこっちをベースにしています)。
その場合量子化レベルはQ8_0となるようです。
余談ですがWindowsの場合、モデルのダウンロードディレクトリはC:\Users\user_name\AppData\Local\llama.cppとなります。
起動すると
load_backend: loaded RPC backend from C:\Apps\llama-bin-win-cpu-x64\ggml-rpc.dll
load_backend: loaded CPU backend from C:\Apps\llama-bin-win-cpu-x64\ggml-cpu-icelake.dll
... 中略 ...
main: model loaded
main: server is listening on http://127.0.0.1:8012
main: starting the main loop...
srv update_slots: all slots are idle
のようなログが出ますのでhttp://127.0.0.1:8012にアクセスして起動を確認することができます。
-hfオプションで起動した場合、URLがhttp://127.0.0.1:8080となるようです。
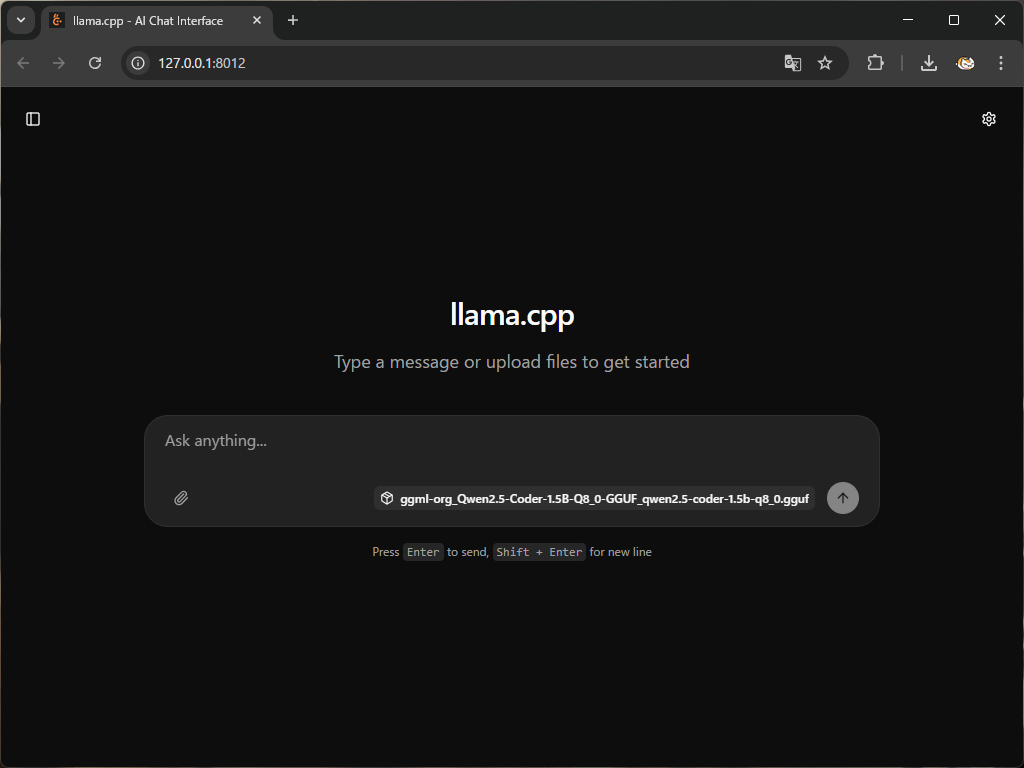
のような画面が出れば起動完了です。
入力欄右下に出ているggml-org_Qwen2.5-Coder-1.5B-Q8_0-GGUF_qwen2.5-coder-1.5b-q8_0.ggufがContinueに設定するモデル名となりますので覚えておいてください。コピペはできませんのでhttp://127.0.0.1:8012/v1/modelsからモデル情報を確認するとよいです。
試しに何か入力してみましょう。

大体15-16tpsぐらい出ています。オートコンプリートは短めのコードを生成するのでこのぐらいの速度が出れば十分だと思います(ちなみに0.5Bモデルは70tpsぐらい出ました)。
Continue
まずVSCodeの拡張機能からContinueをインストールします。
インストールしたばかりだと左サイドパネルに
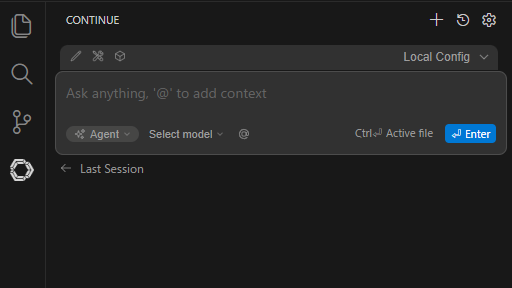
こんな感じで表示されたと思います。まだ何も設定していないのでモデルは選択されていません。
次にllama.cppで起動したモデルを使えるようにします。
入力欄やや左下のSelect model -> Add Chat modelを選択すると
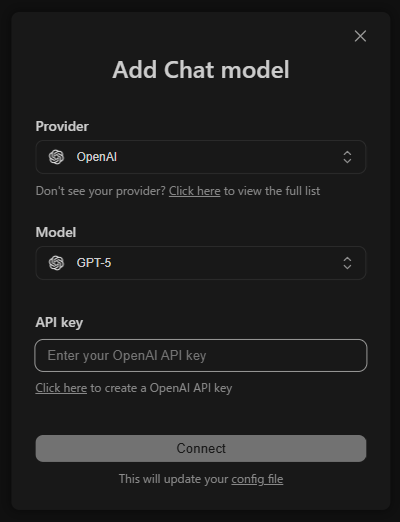
こんなポップアップ(?)が出てきます。
Providerでllama.cppを選択しモデルを選ぶこともできますが、今回はポップアップ下部にあるconfig fileから直接編集します。
config.yamlを開くと最初は
name: Local Config
version: 1.0.0
schema: v1
models: []
となっていると思いますが、これを
name: Local Config
version: 1.0.0
schema: v1
models:
- name: qwen2.5-coder 1.5b
provider: llama.cpp
apiBase: http://localhost:8012/
model: ggml-org_Qwen2.5-Coder-1.5B-Q8_0-GGUF_qwen2.5-coder-1.5b-q8_0.gguf
roles:
- autocomplete
- chat
- edit
- apply
- summarize
と書き換えて保存します。そうするとSelect modelがqwen2.5-coder 1.5bに変わっていると思います。
上記はChatをするときのモデルになりますが、Autocompleteのモデルが設定されているか確認する場合は、右上の⚙(Open settings) -> Modelsを選択します。
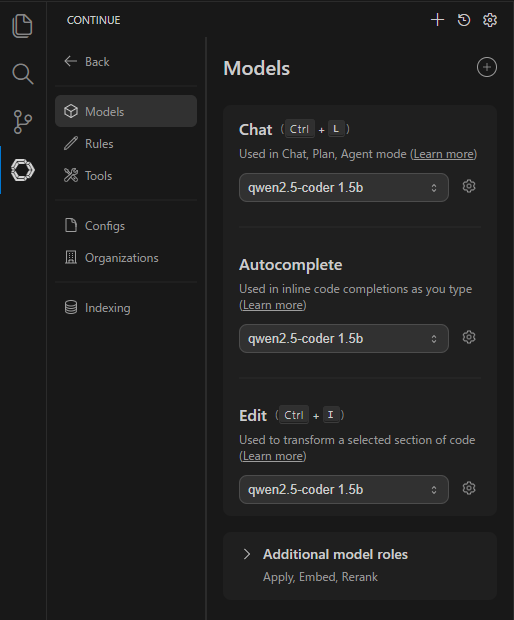
のような画面となりAutocompleteにqwen2.5-coder 1.5bが選択されていることを確認できると思います。
余談ですがWindowsの場合、config.yamlはC:\Users\user_name\.continueにあります。
以上で設定は完了です。試しに何か書いてみると…
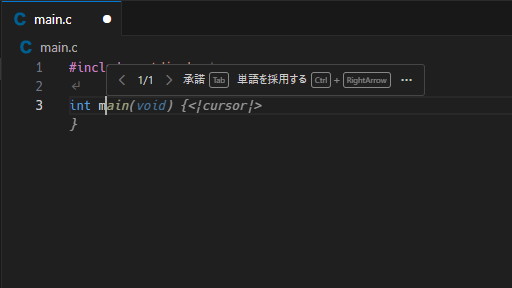
こんな感じで続きを提案してくれます。
…うーん、いまいち![]() ?
?
TabとかCtrl + →とかはGitHub Copilot等を使ったことがある人だったら馴染みのある操作感ですね。
カスタマイズ
モデルの入力コンテキストサイズを調整する
llama.cpp serverは何も指定しないとモデルが扱える最大のコンテキストサイズで起動します。その時のRAM使用量は私のPCで1GBほどとなっていました。動画のトークン数が259と出ていたので、多くても2048トークンくらいあれば十分そうです。
> llama-server --fim-qwen-1.5b-default -c 2048
のように-cでコンテキストサイズを調整できます。RAM使用量は120MBほどに減りました。
ログイン時にllama.cpp serverを自動起動させる
ログイン後に毎回コマンドを打ってllama.cpp serverを起動させるのはダルいです。また、ターミナルで起動した場合ウィンドウが残って邪魔ですし、ふとした拍子に誤って終了させてしまうかもしれません。
そこでllama-serverと同じディレクトリに
Set ws = CreateObject("Wscript.Shell")
ws.run "cmd /c llama-server --fim-qwen-1.5b-default -c 2048", vbhide
のようなVBScriptを作成しスタートアップに登録することで、ログイン時にバックグラウンドで起動してくれるようになります。
終わりに
まだこの環境でガッツリ業務のコーディングをしたわけではないので、本当に有用かは未知数です。
例えばllama.cpp serverを起動させるときに-vを付けてみるとわかるのですが、LLMが何かしらの応答を返してるのにエディタ上では何も表示されないといった、Continue側の怪しい挙動も見受けられます。
時間が解決してくれるものもあるとは思いますが、業務で使いながら色々と試行錯誤しようと思っています。
特に1.5Bのオートコンプリート内容が微妙な場面も結構あるので、3B:Q4_K_Mぐらいにしたら改善しないかとか、他のLLMはどうかとか、試してみたいと思っています。
今後期待することとしては、1年後ぐらいにローカルCPUでGPT-4レベルのLLMが動くようになっていることと、AI使わないで仕事するなんて考えられない世の中になっていることでしょうか。