スマブラSPはじめました!
64の初代スマブラ以来なのですが、久しぶりにスマブラをはじめた方も多く、知り合いが増えました!
ということで、スマブラネタで記事を書きたいなと思い、
スマブラの人気キャラをGoogleの検索トレンドをもとに人気度を比較し、Elasticsearch/Kibanaを使って可視化してみました。
記事上のソースコードはgithubで公開しています。
TrendVisualizer
| 環境 | version |
|---|---|
| Python | 3.6.3 |
| Elasticsearch(Elasitc Cloud) | 6.5.4 |
| Kibana(Elasitc Cloud) | 6.5.4 |
データ準備
Wikipediaの参戦ファイター一覧をCSVに加工して、DataFrameとして読み込みました。
絞り込みのために、登場シリーズ、初参戦作品のデータも入れてあります。
name,series,first
マリオ,スーパーマリオシリーズ,初代
ドンキーコング,ドンキーコングシリーズ,初代
ピーチ,スーパーマリオシリーズ,DX
・・・
Googleトレンド取得
Googleトレンドは、期間内の検索ワードのトレンドの推移を取得できるもので、検索ワード同士の比較もできます。
公開されているAPIを利用した、pytrendsを使って取得しました。
実装は「pytrends で Google トレンドの取得結果をマージする」を参考にさせていただきました。他にもたくさん記事はありますね。
PREFIX_WORD = "スマブラ SP "
base_character = "ガノンドロフ"
timeframe_val = '2018-12-07 2018-12-31'
# chunks:キャラクター一覧を4つ区切りに格納したもの
for elems in list(chunks):
elems = list(filterfalse(p, elems))
# 基準となるワードを追加する。
elems.append(PREFIX_WORD + base_character)
# トレンドを取得する。
pytrends.build_payload(elems, timeframe=timeframe_val, geo='JP')
df = pytrends.interest_over_time()
# 標準ワードで正規化する
df = df.div(df[PREFIX_WORD + base_character].max(), axis=0)
記事に記載されているように、一度実行した結果から平均的なワードとして「ガノンドロフ」を選択しました。
また、単純に「マリオ」などと指定すると、スマブラに関係ない意図での検索も含まれてしまうので、「スマブラ SP <キャラクター名>」となるようにしてデータを取得し、以下のようなデータとなりました。
date スマブラ SP マリオ スマブラ SP リンク ・・・
2018-12-07 0.568182 1.681818 ・・・
2018-12-08 1.727273 1.159091 ・・・
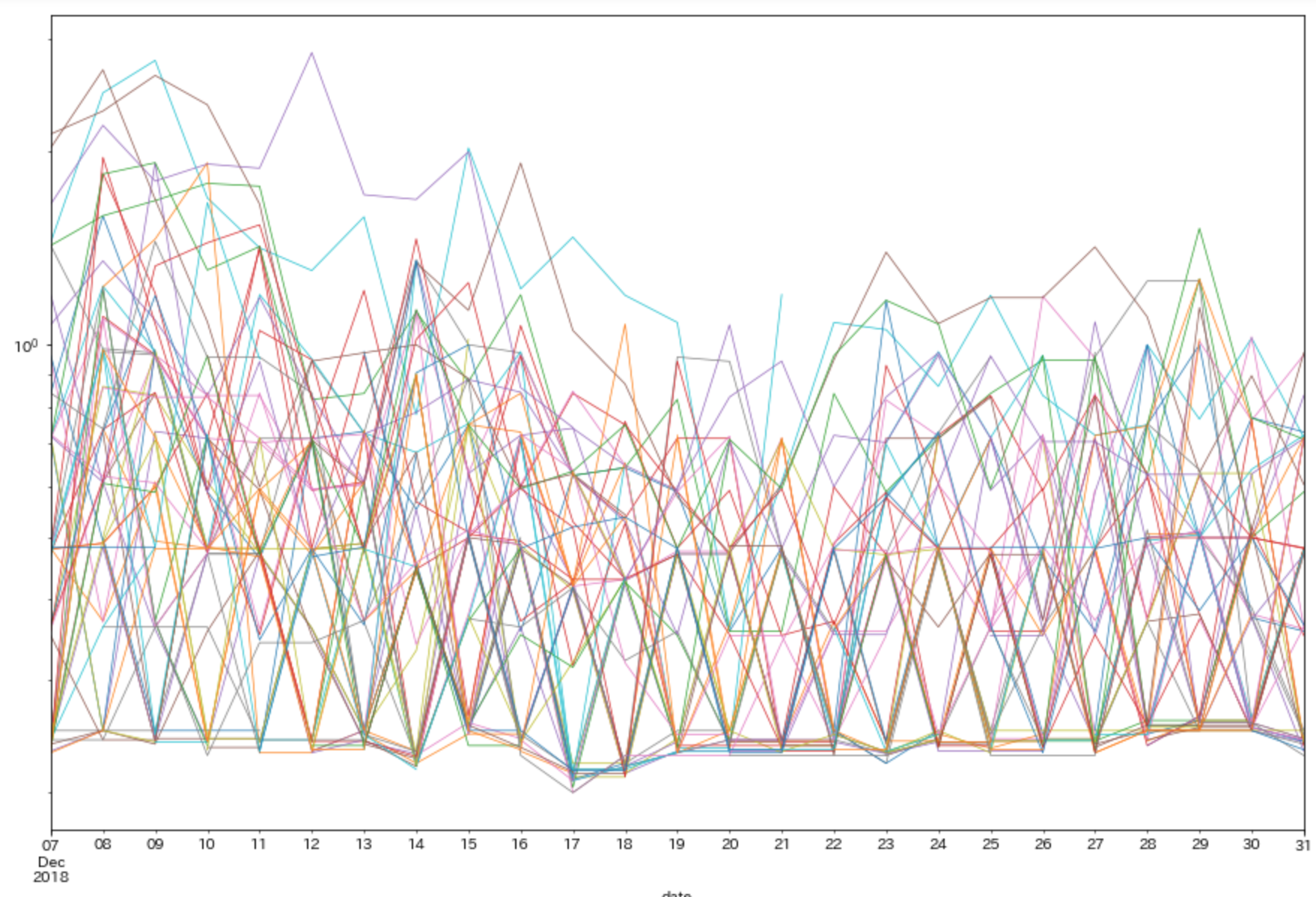
MatplotLibでとりあえず可視化してみましたが、データがありすぎて、よくわかりません。
Elasticsearchへ投入
取得したデータを見やすく、またいろいろな観点で分析できるように、Elasticsearchに投入し、Kibanaで可視化していきます。
取得したトレンドのデータをjsonに変換してElasticsearchのPythonAPIを使って、Elasticsearchへデータを投入します。
ES_URL = config["elasticsearch.url"]
USE_SSL = config["use.ssl"]
USER = config["elasticsearch.user"]
PW = config["elasticsearch.pass"]
es = Elasticsearch(
ES_URL,
http_auth=(USER, PW),
use_ssl=USE_SSL,
ca_certs=certifi.where(),
sort="time:asc", timeout=30)
def bulk_insert(index_name, json_list: []):
actions = []
for insert_data_json in json_list:
actions.append({
"_index": index_name,
"_type": "_doc",
"_source": insert_data_json
})
# bulk insert
helpers.bulk(es, actions)
KibanaでのGET _cat/indices の実行結果

1ヶ月分のデータで約1900ドキュメント、ちゃんと入っていますね。
このくらいのデータなら、投入は一瞬で終わります。
Kibanaで可視化
いよいよ投入したデータをkibanaで可視化してみます。
今回は以下のグラフをまとめてダッシュボードにしました。
- 推移がわかるようにLineChart
- 割合がわかるようにPieChart
- ランキングが視覚的にわかるようにTagCloud
- 絞り込みができるようにControls
 全キャラ中の人気としては「ゼルダ」が一番でした。作品名でもありますし、検索のしやすさなどもあるのかもしれません。ファントム強いですよね。
全キャラ中の人気としては「ゼルダ」が一番でした。作品名でもありますし、検索のしやすさなどもあるのかもしれません。ファントム強いですよね。
続いて「リンク」「スネーク」と続きました。スネークは意外でしたが、特殊なキャラのため、調べる人が多いのかもしれませんね。
次はSPで初参戦となったキャラクターで絞り込んでみます。絞り込みはControlsで簡単に行えます。
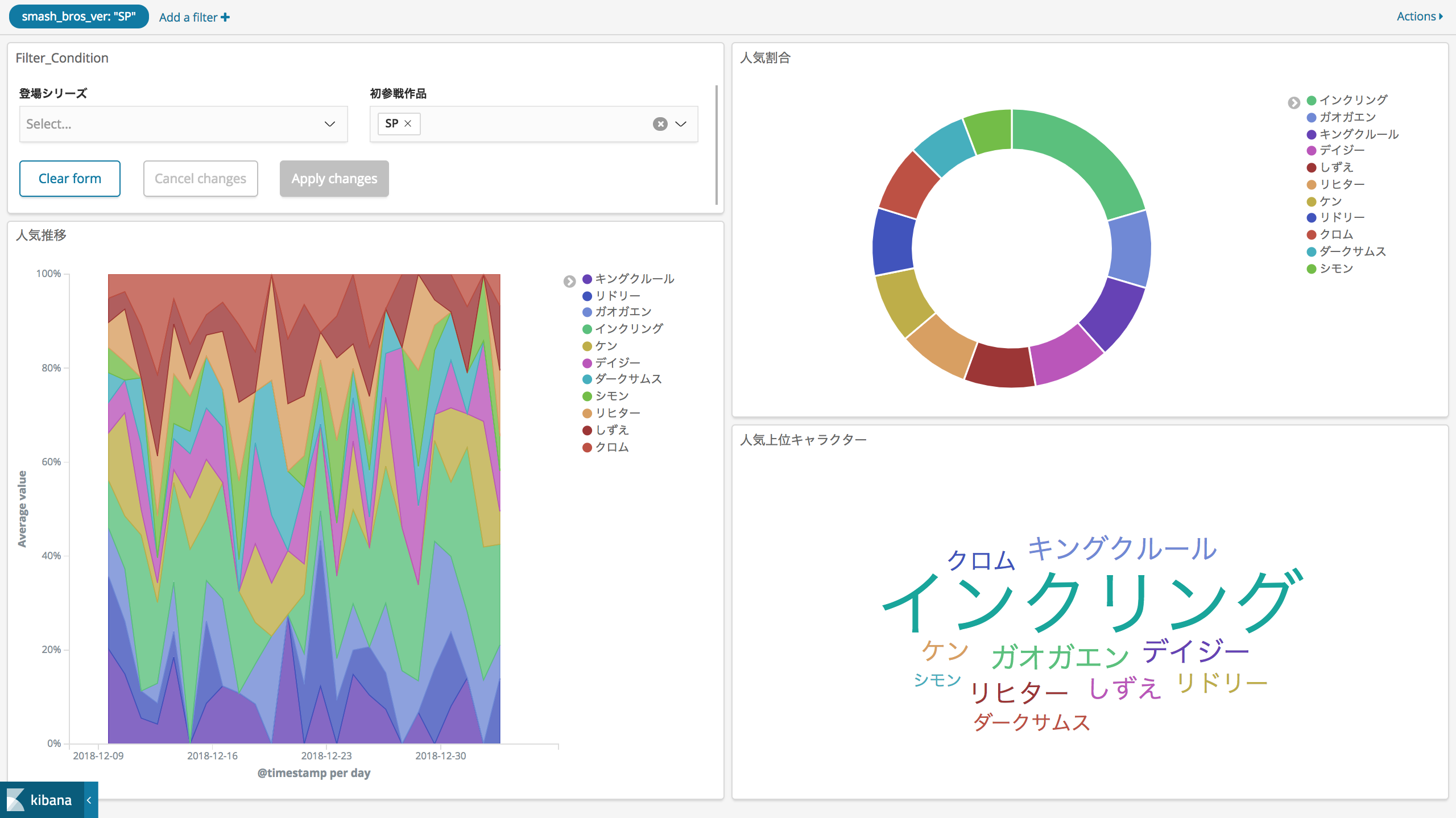
強いと噂の「インクリング」「キングクルール」がやはり人気のようです。オンライン対戦していてもよく出会います。
最後に「ゼルダの伝説」シリーズのキャラクターで絞り込んでみます。
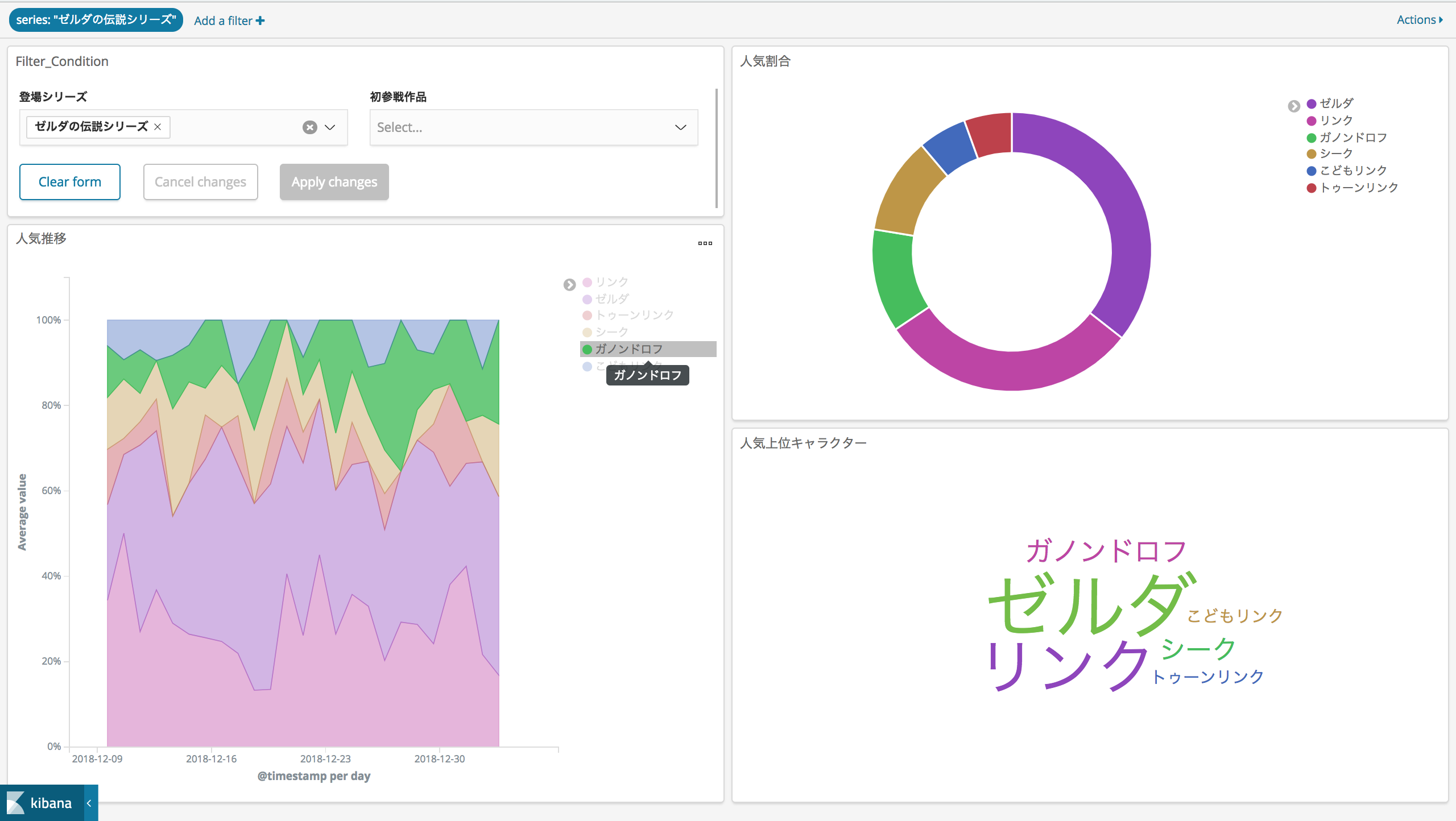
ガノンドロフの推移(緑)に注目すると、参戦する順番が遅いこともあり(?)発売直後はあまり人気がなくても、徐々に人気がでてきたことがわかります。火力が魅力です。
このように、様々な観点で絞り込んでいくことができました。
改善したいところ
検索ワードの表記揺れ
「ドンキーコング」→「ドンキー」、「ロゼッタ&チコ」→「ロゼチコ」
のように略称などで検索されることが多いと思いますが、この考慮ができていません。
そのため、「ロゼッタ&チコ」は検索数が少なく、トレンドのデータがありません。。
同義語を設定できるようにし、それらの検索数の和で検証して見るとまた結果が変わってくるかもしれませんね。
まとめ
特に技術的に新しい内容はなかったですが、
ある程度、強いと言われているキャラが上位にくる結果になりました。
ElasaticsearchとKibanaで可視化すると、いろんな視点で切り分けができてわかりやすいです。
他にもいろいろなデータを可視化してみようと思います。
参考にさせていただいた記事
それではよいスマブラライフを!