ストリーミング処理とは、大量のデータをロードしながら順番に処理していく処理方法です。
非同期に順番に処理していくだけなので、論理的にはできそうだけど可用性やスケール性を考えるとなかなか難しい領域です。
そんなストリーミング処理を、DatabricksというSparkのプラットフォーム上で、Spark Structured Streamingを使って実現する方法をまとめていきます。

Databricksは、Apache Sparkを作った人が創業した会社で、AWSやAzureといったクラウド上に、Spark環境を自動的に構築してくれるサービスです。
昨年約430億円調達し、バリュエーションが6700億円というみたこともない金額になっているらしいです。
参考記事
会社名をあまり聞いたことがない方も多いかもしれませんが、Spark&AI Summitを主催するなど、データエンジニアリング界隈では、世界的には非常に期待値の高い企業です。
さて、Databricksのサービスですが、Databricksの管理画面からクラスタなどの設定を行いIAMなどのを設定すると、自動的にスポットインスタンスを買い付けてクラスタを構築してくれます。
Sparkは(僕もそうですが)環境を作るのにとてつもない苦労をしましたが、これは危険なほど楽です。
Spark Structured Streaming
ようやく本題ですが、このDatabricksを活用してSpark Structured Streamingを構築してみたいと思います。
ストリーミング技術は、Akka Streamなどのリアクティブストリーム実装や、Apache Flinkなどいろいろありますが、Spark Structured Streamingは、大きく2つの特徴があります。
- DataFrameなどSparkの技術が使える
- 自動リトライ、自動復旧など、Sparkの安定性がそのまま活用できる
Sparkは、これまで構築や運用に専門技術が必要とされる印象がありましたが、Databricksを活用することで構築も運用も楽になり、ビッグデータのストリーミング処理においては、十分選択肢のひとつになると思われます。
ざっくり理論
今回はあまり理論をがっつり説明するつもりはありませんが、全体的に日本語の説明ページが少ない気がするので、軽く触れておこうと思います。
Spark Structured Streamingは、基本的にはマイクロバッチ方式です。
Spark2.3以降、Continuous Processingというさらにリアルタイム性の高い方法も出てきましたが、今回はオーソドックスなマイクロバッチで説明します。
マイクロバッチの概念自体はさして難しくありません。
1秒や数秒単位でデータを細かく分け、ETL等のバッチ処理と同じようにデータを順番に処理していきます。

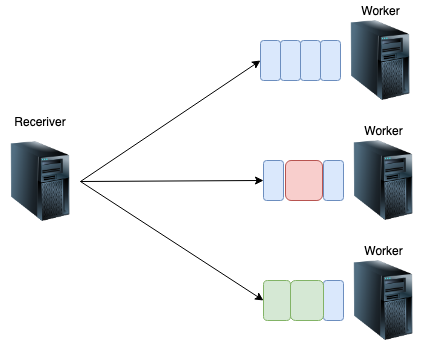
Sparkでは、クラスタを管理するドライバノード(Reciever)と、処理を実行するワーカーノードがあります。
ドライバノードは各ワーカーの処理状況に応じてバランシングします。
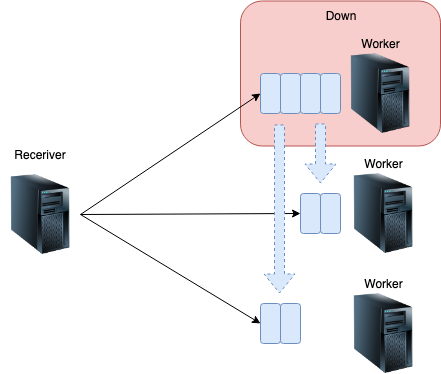
では、スポットインスタンスの期限切れや何らかのネットワーク断により、ひとつのワーカーノードがお亡くなりになったときはどうするのでしょうか?
ドライバノードは失敗した処理を別のワーカーに再度振り分けます。
そのため、途中まで処理して失敗したケースなど、一部のデータが重複して処理される可能性はありますが、自動的に失敗はリトライされます。
リトライ上限を超えた場合、ジョブは失敗となります。
実装
Databricksは、契約していなくてもCommunity Editionなら無料で試すことができます。
画面のキャプチャはCommunity Editionではないですが、ほぼ機能的には変わりません。
サンプルで使うデータ
まずはサンプルで使うデータについて説明します。
配信ログ
広告を配信したログです。表示(imp)とクリック(click)があります。
キャンペーンとは、広告を配信する単位です。
| カラム名 | 型 | 説明 |
|---|---|---|
| device_id | String | ログのユーザーID |
| event_type | String | ログの種別。imp / click |
| campaign_id | Int | キャンペーンID |
| time | Long | イベント発生時間(Unixtimestamp) |
実際に試すために、Kinesisにデータを投入するシェルを作りました。
このような感じでサンプルデータを入れています。
そのため、普通ならimp→clickという流れができますが、そのへんはランダムなデータです。
Kinesisにデータを投入するシェル
users=()
for i in `seq 10`
do
users+=( `uuidgen` )
done
campaigns=()
for i in `seq 2`
do
campaigns+=( "$i" )
done
while :
do
userIndex=$(($RANDOM % 10))
userId=${users[$userIndex]}
index=$(($RANDOM % 2))
campaignId=${campaigns[$index]_}
time=`date +%s`
rand=$(($RANDOM % 2))
if [ $rand -eq 0 ]; then
eventType="imp"
else
eventType="click"
fi
row="{\"device_id\":\"${userId}\",\"event_type\":\"${eventType}\",\"campaign_id\":${campaignId},\"time\":${time}}"
echo $row
rowdata=`echo "$row"`
aws kinesis put-record --stream-name sample-streaming --partition-key `uuidgen` --data $rowdata > /dev/null
done
キャンペーンマスタデータ
キャンペーンのマスタデータです。
本来は予算とか期間とかいろいろ設定するものがありますが、今回はシンプルにするためにこの3つだけです。
なお、キャンペーンをまとめる注文(order)という概念があることとします。
| カラム名 | 型 | 説明 |
|---|---|---|
| campaign_id | Int | キャンペーンID |
| name | String | キャンペーン名 |
| order_id | Int | 注文ID。キャンペーンの上位概念 |
シンプルなストリーミング処理
さて、ではKinesisからストリーミング処理を実装してみましょう。
まずは、超シンプルなストリーミング処理です。
まず、DatabricksのWorkspaceからNotebookを作ります。
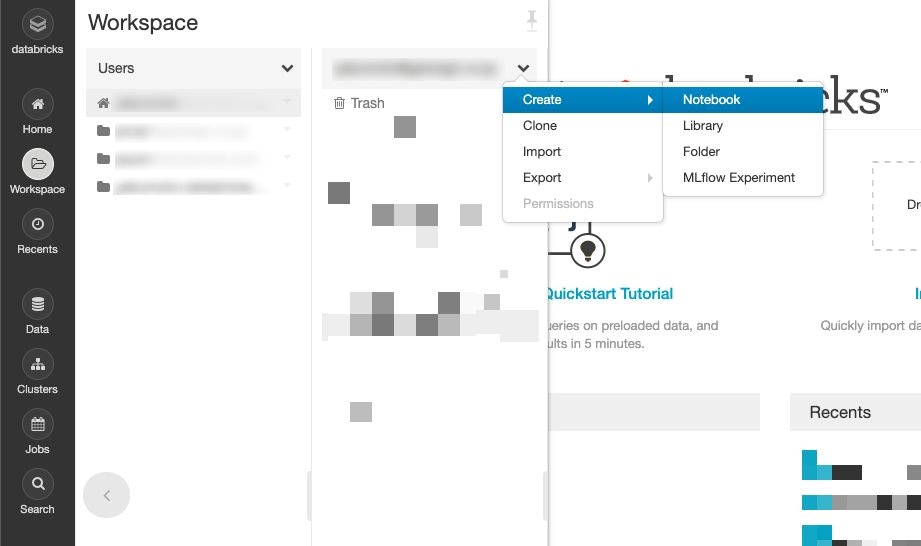
そしてKinesisとの接続を設定します。
アクセスキー、シークレットキー、ストリーム名はなどは適宜差し替えてください。
val inputStream = spark.readStream
.format("kinesis")
.option("streamName", kinesisStreamName) // Kinesisストリーム名
.option("region", "ap-northeast-1") // Kinesisのリージョン
.option("initialPosition", "TRIM_HORIZON") // Kinesisの読み込み方法
.option("awsAccessKey", awsAccessKeyId)
.option("awsSecretKey", awsSecretKey)
.load()
次に、読み込んだデータをパースして構造化します。
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.catalyst.ScalaReflection
import org.apache.spark.sql.functions._
// データの構造を定義
case class UserEvent(
device_id: String,
event_type: String,
campaign_id: Int,
time: Long
)
// case classの定義からスキーマ作成
val testSchema = ScalaReflection.schemaFor[UserEvent].dataType.asInstanceOf[StructType]
// パース
val structuredStream = inputStream
.select(from_json(col("data").cast("string"), testSchema).as("data"))
.select(
col("data.device_id").as("device_id"),
col("data.event_type").as("event_type"),
col("data.campaign_id").as("campaign_id"),
col("data.time").as("time")
)
この状態で、display(structuredStream)などをすると、このようにKinesisからリアルタイムにデータが取得できていることがわかります。

マスタデータとのJOIN
つづいて、マスタデータとJOINしてみます。
マスタデータは、普通はRDBから読み込んだりすると思いますが、今回はめんどくさいのでNotebookで作ります。
マスタデータをこのように作ります。
Seqで定義して、DataFrameに変換するだけです。
val masterData = Seq(
(1 , "campaign1" , 1),
(2 , "campaign2" , 1),
(3 , "campaign3" , 1),
(4 , "campaign4" , 1),
(5 , "campaign5" , 1),
(6 , "campaign6" , 2),
(7 , "campaign7" , 2),
(8 , "campaign8" , 2),
(9 , "campaign9" , 2),
(10, "campaign10", 2)
).toDF("campaign_id", "name", "order_id")
display(masterData) とすると作成できていることがわかります。

マスタデータが作成できたらJOINします。
これだけで、リアルタイムに流れてくるデータをマスタデータとJOINできます。
val aggrigatedStream =
structuredStream.as("t")
.join(masterData.as("m"), Seq("campaign_id"))
joinの第二引数は、join元も先も同じカラム名なのでこの記述方法で良いですが、もう少し複雑な結合方法を書きたい場合は、このように記述できます。
val aggrigatedStream =
structuredStream.as("t")
.join(masterData.as("m"), col("t.campaign_id") === col("m.campaign_id"))
これでdisplay(aggrigatedStream)を実行してみると、リアルタイムにJOINされていることがわかります。

ちなみに、裏では全てのノードにマスタデータをコピーして、それぞれのノードでhash joinする処理が行われています。
このjoin方法を、Broadcast hash joinといいます。
ストリーム同士のJOIN
では、さらに突っ込んで、リアルタイムにimpとclickをjoinしてみましょう。
impとclickを結合すると、どのimpがどのclickに紐づいたかがわかります。
val impStream = structuredStream
.filter(col("event_type") === "imp")
val clickStream = structuredStream
.filter(col("event_type") === "click")
val streamJoinStream = impStream.as("i")
.join(
clickStream.as("c"),
col("i.campaign_id") === col("c.campaign_id")
and
col("i.device_id") === col("c.device_id")
)
これでdisplay(streamJoinStream) すると、このように表示されます。
リアルタイムにJOINできています!

内部的な挙動はこちらのブログに詳しく書いてありますが、
簡単に言うと、一時的にデータをメモリ上に保持しておき、結合でき次第出力するという方法です。
そのため、当然ずっとデータを持ち続けていればメモリがパンクします。
このバッファ期間は、WaterMarkと結合条件で制御できます。
こちらが、WaterMarkと結合条件で制御したコードです。
(若干条件も変わってる)
val streamWithTime = structuredStream
.withColumn("dt", to_timestamp(from_unixtime(col("time"))))
val impStream = streamWithTime
.filter(col("event_type") === "imp")
.withWatermark("dt", "1 minutes")
val clickStream = streamWithTime
.filter(col("event_type") === "click")
.withWatermark("dt", "1 minutes")
val streamJoinStream = impStream.as("i")
.join(
clickStream.as("c"),
col("i.campaign_id") === col("c.campaign_id")
and
col("i.device_id") === col("c.device_id")
and
col("c.dt") > col("i.dt")
and
col("c.dt") <= expr("i.dt + interval 1 minutes")
)
まず、これまでtimeカラムにunixtimestampをLong型で持っていましたが、これをto_timestamp(from_unixtime(col("time"))) でtimestamp型に変換します。
そして、それぞれのストリームでWaterMarkを設定します。
このサンプルでは、1分間だけデータをキャッシュしておきます。
これで1分間だけデータをバッファリングするようになります。
そして、時間の条件を追加します。
前の例ではチェックしていませんでしたが、表示のクリックが発生することはあり得ないので、
col("c.dt") > col("i.dt")
を追加します。
そして、表示の後1分以内だけクリックと紐づけられるようにするために
col("c.dt") <= expr("i.dt + interval 1 minutes")
の条件を加えます。
こうすると、表示してから1分以内に発生したクリックだけを出力できます。
このように表示されます。

まとめ
このように、単純なストリーム処理からマスタデータとのJOIN、ストリーム同士のJOINまで簡単にできてしまいます。
プラットフォーム構築はDatabricksで簡単にでき、実際書いているコードはSQLの延長線上のようなコードなので、ストリーミング処理のハードルが多少下がったのではないでしょうか。
もしよかったら、試してみてください。
参考文献
Introducing Stream-Stream Joins in Apache Spark 2.3
https://databricks.com/blog/2018/03/13/introducing-stream-stream-joins-in-apache-spark-2-3.html