はじめに
当社では、社内業務チャットボットの構築を Dify(OSS版) で検証しています。
今回、Dify のワークフロー機能を使って RAG のリグレッションテストを試しました。エンジニア以外でもメンテナンスしやすいように、ノーコードで LLM 評価のテストを構築しています。簡易的な評価機能を組み込んだワークフローでも、効率的に開発できるようになったので紹介します!
検証環境
- Dify: v1.9.2 (OSS版)
直面していた課題
当社では、社内ドキュメントを扱った RAG(Retrieval-Augmented Generation) を Dify チャットフローで構築しています。
RAG の精度改善では検索クエリの整形ルールを追加したり、システムプロンプトを書き換えたりします。これ自体は品質向上のためですが、副作用として最適化済みの質問に対する回答が変わってしまうリスクがあります。
ようやく新しい質問に対応させられたと思ったら、これまで正しく答えられていた別の質問に答えられなくなっている……といった事象です。所謂、デグレです。
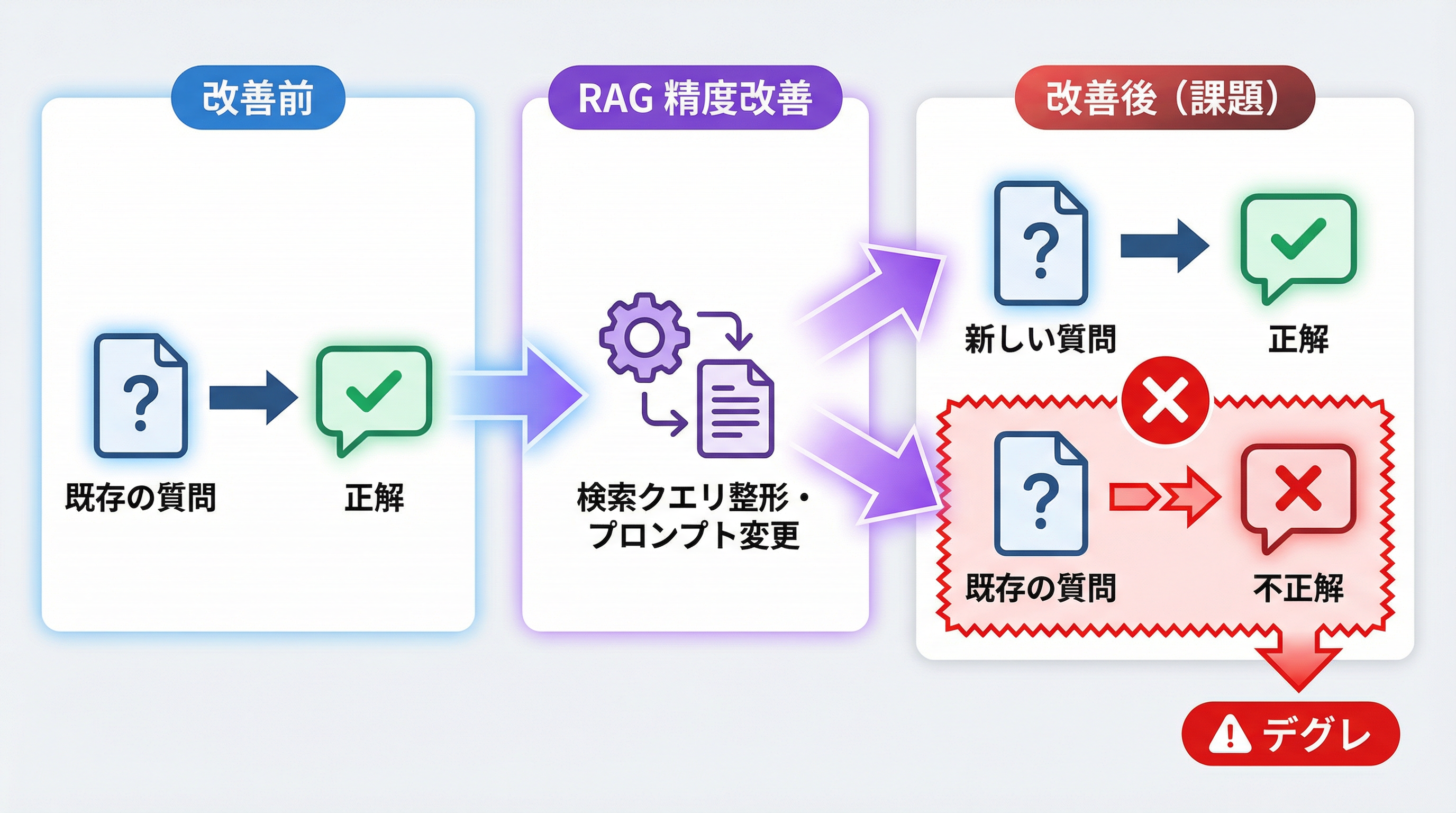
数十件以上の QA を手動で毎回テストするのは心が折れます。そのため Dify のワークフロー機能を使って、リグレッションテスト(既存機能の再検証)を実行できないか試してみました。
解決策:「LLM-as-a-Judge」
テスト自動化にあたり、最も重要な回答評価については LLM-as-a-Judge(LLMを使ってLLMの出力を評価する手法)を検討しました。
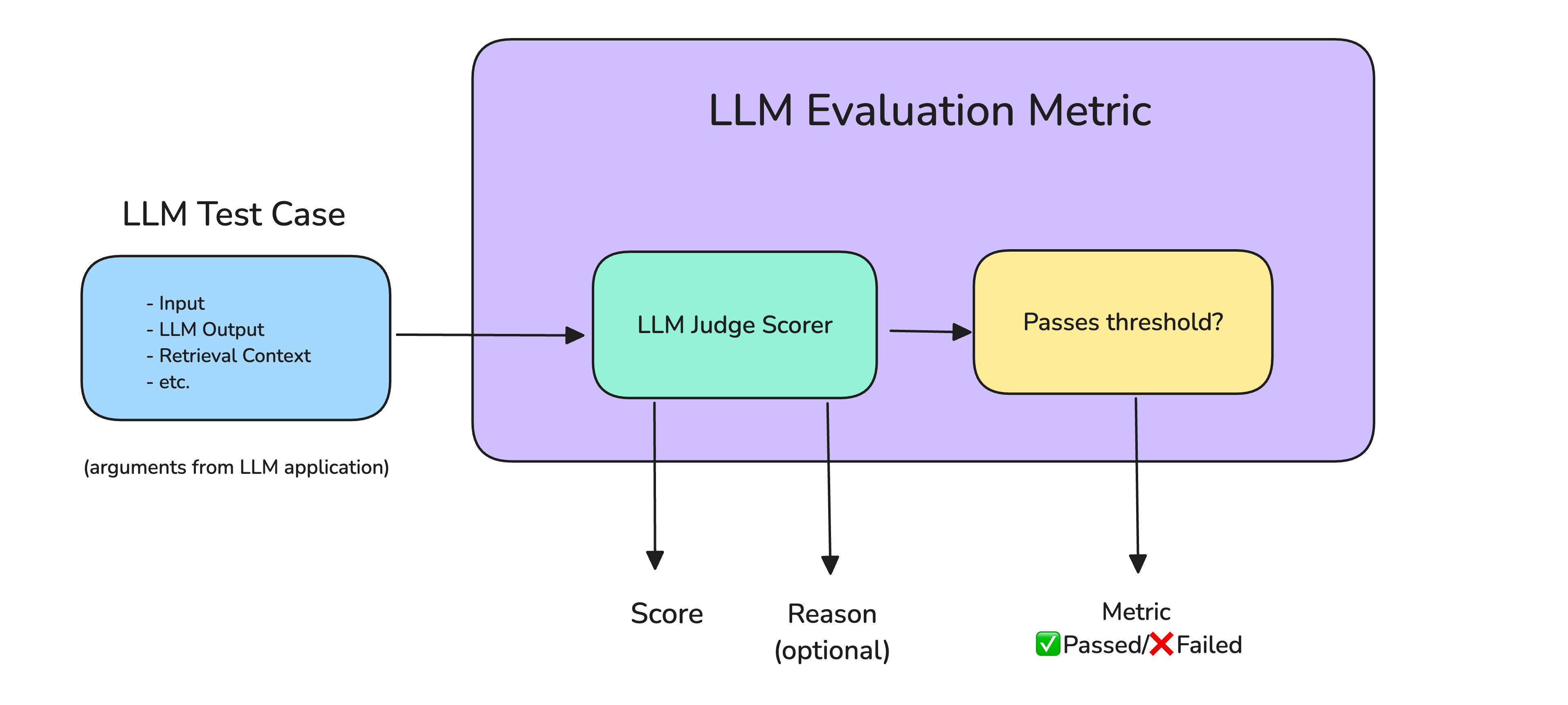
出典: LLM-as-a-Judge Simply Explained: The Complete Guide to Run LLM Evals at Scale
論文にあるような厳密な手法(ペアワイズ比較など)をそのまま実装すると構成・プロンプトが複雑になります。そこで、今回は 「定義済みの QA を正確に答えられているか?」 という点に特化し、Dify 内で完結するシンプルな構成にしました。コードを一切書かず、自然言語で LLM に評価指示をしています。
実装
ここからは具体的な実装内容を紹介します。
実装方針
-
正解例を基に評価:
事前に用意した QA(質問と回答のペア)を正解データとする -
評価軸はシンプルに:
4つの観点(正確性、網羅性、明瞭性、適切性)に基づき、5段階でスコアリング -
判断のブレをなくす:
ジャッジ役の LLM はtemperature: 0で固定 -
Few-shot の活用:
プロンプト内で「高スコアの例」と「低スコアの例」を提示し、採点基準を厳格化 -
ノーコードで実装:
集計ロジックも含めて、すべてプロンプト(自然言語)で定義1
Dify ワークフローによる自動テスト
自動テストを実現するため、RAG の評価ワークフローを Dify アプリで構築しました。構成は以下の通りです。
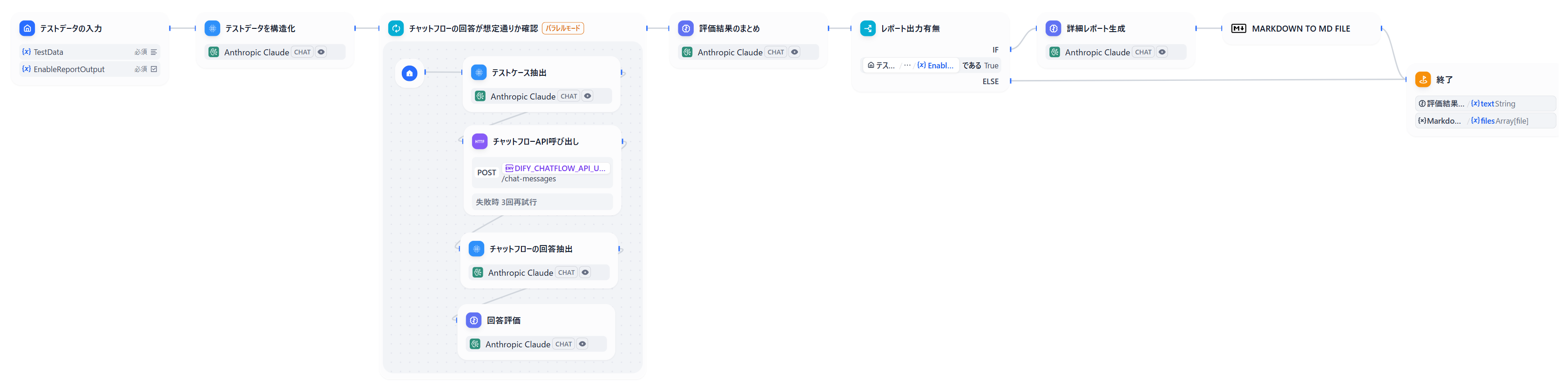
上記ワークフローからテスト対象のチャットフローを API コールして、回答を評価しています。
各ノードの詳細設定
ワークフローの主要なノードにおける設定内容を詳しく紹介します。
1. テストデータの入力(開始)
開始ノードでは、TestData という変数を用意し、以下のような Array[Object] 形式でテストケースを一括入力できるようにしています。
[
{
// テストケースID
"id": 1,
// チャットフローの実行に必要なパラメータ①
"entity": "本社",
// チャットフローの実行に必要なパラメータ②
"category": "経費システム",
// 質問文(プロンプト)
"question": "1件の請求書に、対象取引と非対象取引が混在する場合はどうするか?",
// 期待する回答(評価基準となる正解データ)
"answer": "明細を分けて入力する"
},
{
"id": 2,
"entity": "支店",
"category": "経費システム",
"question": "特定の経費タイプ以外でコードを選択しても問題ないか?",
"answer": "初期値のままで問題ないが、選択してしまってもエラーにはならない"
}
]
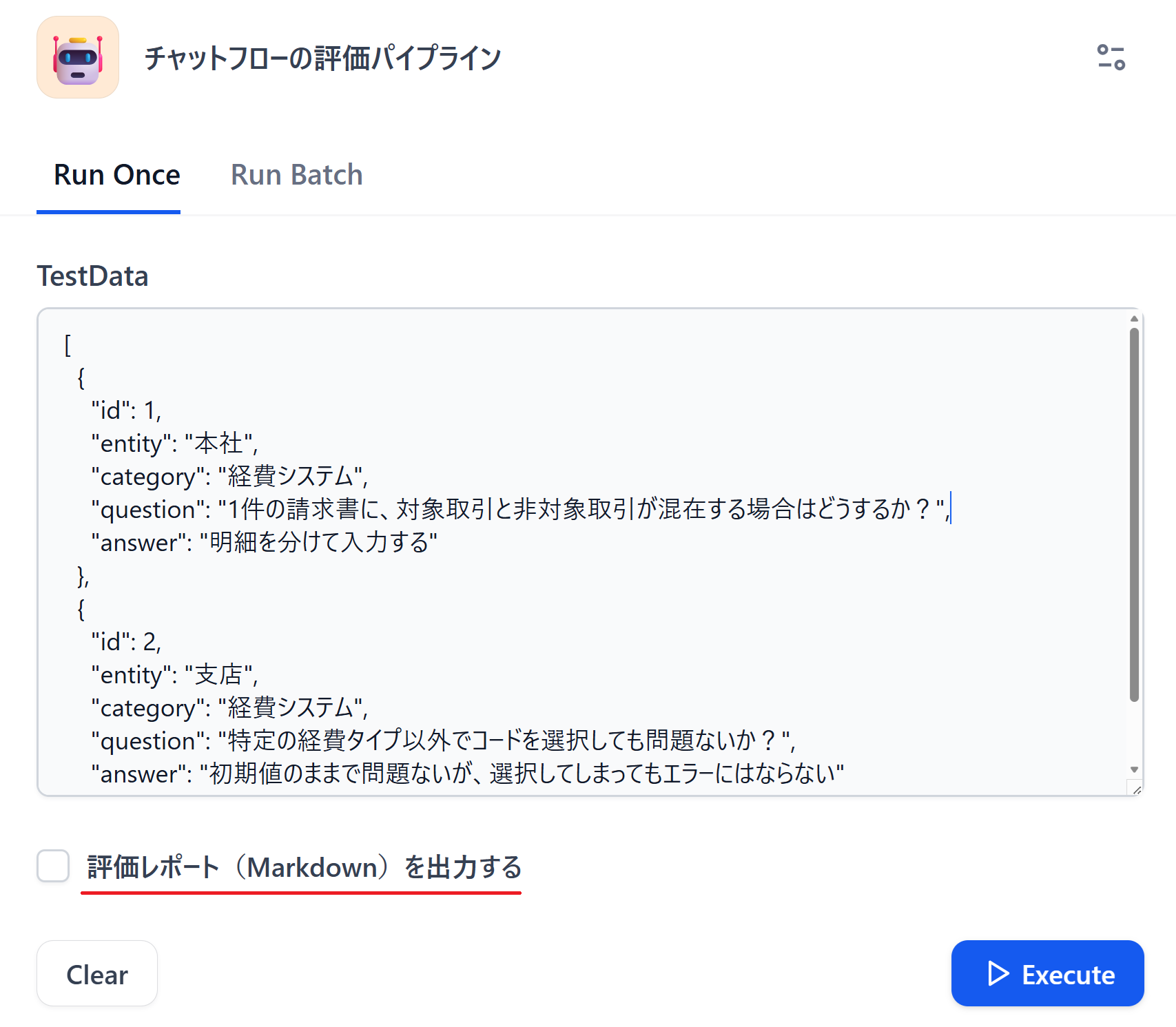
TestData にはデフォルト値として、確認したいケースの全量を登録しています。少量や独自のテストケースで実行したい場合は、ワークフロー実行画面からデータを簡単に差し替えできます。一方、通常時はデフォルト値をそのまま実行するだけでリグレッションテストが可能です。
スモールスタートとして本方式を採用しましたが、ケースが膨らんだ場合は CSV アップロードなどに切り替えても良いでしょう。
また、後続の評価レポート作成有無について、チェックボックスで回答する仕組みになっています。実際の入力画面は以下になります。
2. テストデータを構造化
開始ノードで入力された JSON データは、Dify 内部では単なる「長いテキスト」として扱われます。これを後続の繰り返し処理(イテレーション)で1件ずつ処理できるように、パラメータ抽出ノードで「配列データ」に変換しています。
LLMに対して以下の指示をしています。
入力されたJSONテキストを解析して、`Array[Object]`形式のリストとして抽出してください
このノードにより、テキストデータを Array[Object] 形式の変数(QAList)に変換しています。
3. テストケース抽出
イテレーションループの先頭に配置したパラメータ抽出ノードです。ここから繰り返し処理になります。
配列から取り出された1件分のデータから、後続処理で利用しやすいように以下の要素を個別の変数として定義しています。
-
__id: テストケース管理用のID -
Entity: チャットフローの実行に必要なパラメータ① -
Category: チャットフローの実行に必要なパラメータ② -
Question: 質問文 -
SampleAnswer: 評価基準となる正解データ
ここで変数を明確に分離しておくことで、次のステップである API リクエストの構築が容易になります。
4. チャットフローAPI呼び出し
HTTP Request ノードを使って、検証対象となるチャットフローの API を実際に呼び出します。
テスト対象の環境が変わっても対応しやすいよう、URL や API キーは直接記述せず、Dify の環境変数を利用しています。
API 設定内容:
| 項目 | 設定値 | 備考 |
|---|---|---|
| URL | {{#env.DIFY_CHATFLOW_API_URL#}}/chat-messages |
環境変数からベース URL を取得 |
| Method | POST |
- |
ヘッダー(Headers):
Dify APIの認証に必要なヘッダーを設定します。APIキーも環境変数から呼び出しています。
Authorization: Bearer {{#env.DIFY_CHATFLOW_API_KEY#}}
Content-Type: application/json
ボディ(Body / JSON):
チャットフローAPIの仕様に従い、以下のような JSON を送信します。
inputs パラメータには、前のステップであるテストケース抽出から出力された変数をセットします。
{
"inputs": {
// チャットフロー実行に必要な属性情報
// ここでは前のノードで抽出した変数をセットしています
"Entity": "{{#テストケース抽出.Entity#}}",
"Category": "{{#テストケース抽出.Category#}}"
},
"query": "{{#テストケース抽出.Question#}}",
"response_mode": "blocking",
"user": "evaluation-pipeline"
}
user に識別子を入れることで、テスト実行時のログを区別しやすくしています。なお、inputs パラメータはチャットフロー側で設定項目がなければ不要です。
5. チャットフローの回答抽出
API からのレスポンスには、回答本文以外にも様々なメタデータが含まれています。これらをそのまま評価用 LLM に渡すと評価精度のノイズになるため、パラメータ抽出ノードを再度使用します。
API レスポンスの JSON から、純粋な回答テキスト2のみを AnswerText 変数として抽出しています。
6. 回答の評価
本ワークフローの核となる部分です。イテレーションの中で実行される回答評価ノードでは、以下のシステムプロンプトを設定しています。評価基準を明確にし、出力形式を JSON に強制している点がポイントです。
あなたはQAチャットフローの回答品質を評価する専門家です。
## 評価基準
以下の5段階で評価してください:
| スコア | 基準 |
|--------|------|
| 5 | 完璧:正解例と同等以上の正確さと明瞭さ |
| 4 | 良好:正解例の主要ポイントを網羅、軽微な差異あり |
| 3 | 普通:主要ポイントの一部が欠落または不明瞭 |
| 2 | 不十分:重要な情報が欠落または誤り含む |
| 1 | 不適切:回答が的外れまたは重大な誤り |
## 評価観点
1. **正確性**: 正解例と比較して事実が正しいか
2. **網羅性**: 必要な情報が含まれているか
3. **明瞭性**: 分かりやすく説明されているか
4. **適切性**: 質問に対して適切な回答か
## 評価時の許容事項【重要】
以下の差異は減点対象としないでください:
1. **連絡先・問い合わせ先の差異**: チャットフローは最新の連絡先情報を使用するため、正解例と異なる連絡先でも、適切な部署・担当への案内であれば問題なし
2. **表現の違い**: 同じ意味を別の言葉で表現している場合
3. **追加情報**: 正解例にない補足情報が含まれている場合(むしろプラス評価)
## 評価時の注意事項【バイアス回避】
以下の点に注意して評価してください:
1. **冗長バイアスの回避**: 回答の長さや情報量の多さに惑わされず、質問に対する直接的な回答の正確性で判断すること
2. **情報量バイアスの回避**: 周辺情報や補足説明が多くても、核心部分が正しく回答されていなければ減点すること
## 評価例(Few-shot)
### 例1: スコア5のケース
入力:
- 質問: 「海外支店との取引はどう処理するか?」
- 正解例: 「初期値『対象外』とする」
- 実際回答: 「海外支店との取引は、区分欄を初期値『対象外』のまま変更不要です。理由は本支店間取引に準じるためです。」
出力JSON:
{"id":4,"entity":"本社","category":"経費精算","score":5,"needs_improvement":false,"accuracy":"正解例と完全一致。核心部分を正確に回答","coverage":"必要な情報をすべて含み、根拠も充実","clarity":"初心者にも理解しやすい明瞭な説明","summary":"正解例を完全に満たし、詳細な補足も充実した完璧な回答"}
### 例2: スコア2のケース
入力:
- 質問: 「支店A→海外支店Bの取引はどう入力するか?」
- 正解例: 「『コード400』を入力する」
- 実際回答: 「支店A→海外支店Bは同一法人内支店として扱われるため、初期値『対象外』のままで問題ありません。」
出力JSON:
{"id":5,"entity":"支店","category":"経費精算","score":2,"needs_improvement":true,"accuracy":"正解例と正反対。別法人のため『コード400』が正しい","coverage":"重要な法人区分の理解が欠落","clarity":"説明は明瞭だが内容が誤り","summary":"正解例と正反対の回答で重大な誤りがある"}
## 出力形式【厳守】
以下の形式で純粋なJSONオブジェクトのみを出力してください。
- コードブロック(```json や ```)は絶対に使用禁止
- 説明文や前置きは一切不要
- JSONオブジェクトの { から始めて } で終わること
- needs_improvement: スコア3以下の場合はtrue、4以上はfalse
{"id":<テストケースID>,"entity":"<エンティティ>","category":"<カテゴリ>","question":"<質問文>","expected_answer":"<正解例>","actual_answer":"<チャットフロー回答のanswerフィールド値>","score":<1-5の整数>,"needs_improvement":<true/false>,"accuracy":"<正確性の評価コメント>","coverage":"<網羅性の評価コメント>","clarity":"<明瞭性の評価コメント>","summary":"<総合評価コメント(50文字以内)>"}
以下の情報を基に、チャットボットの回答を評価してください。
## テストケース情報
- **ID**: {{#テストケース抽出.__id#}}
- **カテゴリ**: {{#テストケース抽出.Category#}}
- **エンティティ**: {{#テストケース抽出.Entity#}}
- **質問**: {{#テストケース抽出.Question#}}
## 正解例
{{#テストケース抽出.SampleAnswer#}}
## チャットボットの回答
{{#テストケース抽出.AnswerText#}}
7. 評価結果のまとめ
繰り返し処理の終了後、LLM ノードで全体の統計情報を生成させます。
あなたは評価結果を集計してレポートを作成する専門家です。
## 入力形式【重要】
イテレーションから出力された各テストケースの評価結果が**JSON文字列の配列**として渡されます。
各要素は以下の構造を持つJSONオブジェクトです:
```json
{ "id": <数値>, "entity": "<文字列>", "category": "<文字列>", "score": <1-5の整数>, "needs_improvement": <true/false>, "summary": "<文字列>", ... }
```
## データ処理ルール
以下の手順で各テストケースを2つのグループに振り分けてください:
1. **JSON配列の全要素をパースする**
- 各JSONオブジェクトから `score` フィールドを抽出
- `score` は必ず 1〜5 の整数
2. **ケース分類**
- 要改善ケース: `needs_improvement` が `true` のオブジェクト(または `score <= 3`)
- 高評価ケース: `needs_improvement` が `false` のオブジェクト(または `score >= 4`)
## 禁止事項
- ❌ IDを範囲表記(例: 11-22)に変換してはいけない(個別に列挙すること)
- ❌ JSONの `score` フィールド以外の情報(summaryの内容など)で勝手にスコアを判定してはいけない
- ❌ 入力されたテストケースを省略してはいけない(全件をテーブルに出力すること)
## 検証
- 入力されたすべてのテストケースが、「要改善」または「高評価」のどちらか一方に含まれていることを確認してください。
## 出力ルール【重要】
- ❌ 集計手順・検証プロセスは出力に含めない(内部処理のみ)
- ✅ 最終的な評価レポート(Markdown)のみを出力すること
- ❌ 「集計手順の実行」「JSON配列のパース」などの作業ログは不要
## 出力形式
以下の形式でMarkdownレポートを作成してください:
```markdown
# チャットボット評価レポート
## ⚠️ 要改善ケース(スコア3以下)
| ID | スコア | 問題点 |
|----|--------|--------|
| X | X | <summary> |
(要改善ケースが0件の場合は「該当なし」と記載)
## ✅ 高評価ケース(スコア4以上)
| ID | スコア | 評価 |
|----|--------|------|
| X | X | <summary> |
## 💡 改善提案
(評価結果から導き出される改善ポイントを3つ程度記載)
```
以下の評価結果を集計し、レポートを作成してください。
## 評価結果一覧(JSON配列)
{{#context#}}
**⚠️ 重要**:
- 各オブジェクトの `score` フィールドを使って、必ず機械的にカウントしてください
- 集計手順や検証プロセスは出力せず、最終的な評価レポート(Markdown)のみを出力してください
8. 詳細レポート生成
ここでは、LLM ノードを使用して詳細レポートを生成します。
テスト結果の集計だけでもそこそこ時間がかかります。エラー箇所の詳細な分析結果を出力すると、実行時間が更に長くなります。
そのため、前述の通り開始ノードのチェックボックス変数を使用して、IF/ELSE ノードで処理を分岐させています。精度改善を行う際(チェックボックスが True )のみ、詳細を出力する運用です。
プロンプトは以下の通りです。
あなたは評価結果を詳細なMarkdownレポートに変換する専門家です。
## 入力
1. 評価結果のまとめ(サマリーレポート)
2. 各テストケースの評価結果JSON配列
## 出力ルール【重要】
- **needs_improvement=trueのケースのみ**詳細を出力
- **質問・回答は最初の100文字のみ**記載(全文はチャットフロー側のログで確認可能)
- needs_improvement=falseは一覧表のみ(詳細不要)
- 簡潔な表現を心がけ、冗長な説明は避ける
## 出力形式
# チャットボット評価レポート(詳細版)
(評価結果のまとめをそのまま記載)
---
## 📋 要改善ケース詳細(needs_improvement=true)
### テストケース #X(スコア: Y/5)
| 項目 | 内容 |
|------|------|
| **エンティティ** | (entityの値) |
| **カテゴリ** | (categoryの値) |
| **質問** | (question冒頭100文字...) |
| **正解例** | (expected_answer冒頭100文字...) |
| **チャットボット回答** | (actual_answer冒頭100文字...) |
**📊 評価詳細**
| 観点 | 評価 |
|------|------|
| 正確性 | (accuracyコメント) |
| 網羅性 | (coverageコメント) |
| 明瞭性 | (clarityコメント) |
**💬 総合評価**: (summaryコメント)
> ℹ️ 詳細な会話内容はチャットフロー側のログをご確認ください
---
(needs_improvement=trueのケースのみ上記形式で記載)
## ✅ 高評価ケース一覧(needs_improvement=false)
| ID | スコア | エンティティ | 総合評価 |
|----|--------|--------------|----------|
| X | 5 | 事業部A(本部) | (summaryコメント) |
## スコア表示ルール
- 5点: ⭐⭐⭐⭐⭐
- 4点: ⭐⭐⭐⭐☆
- 3点: ⭐⭐⭐☆☆
- 2点: ⭐⭐☆☆☆
- 1点: ⭐☆☆☆☆
以下の情報を基に、needs_improvement=trueの要改善ケースのみ詳細レポートを生成してください。
## 評価結果のまとめ
{{#評価結果のまとめ.text#}}
## 各テストケースの評価結果
{{#context#}}
実際に本ワークフローを実行すると、以下のようなレポートが出力されます。
評価レポートのサンプル
# チャットボット評価レポート(詳細版)
## ⚠️ 要改善ケース(スコア3以下)
| ID | スコア | 問題点 |
|----|--------|--------|
| 8 | 2 | 取引区分の判定は正しいが、システムへの入力方法で重大な誤りがある |
| 15 | 3 | 結論は正しいが質問の対象科目を誤解釈している |
## 💡 改善提案
### 1. 処理方法の一貫性確保
ID8のケースでは、取引区分の判定(特殊取引に該当するか否か)は正しくできていますが、システムでの具体的な処理方法(「コードを選択する」vs「初期値のまま」)で矛盾が発生しています。判定ロジックと入力手順の対応関係を明確化し、一貫した回答ができるよう改善が必要です。
### 2. 質問内容の正確な理解
ID15のケースでは、「収益項目A」という質問に対して、類似する「収益項目B」として解釈して回答してしまいました。質問の対象を正確に把握し、適切な科目について回答できるよう、質問解析の精度向上が必要です。
---
## 📋 要改善ケース詳細(needs_improvement=true)
### テストケース #8(スコア: ⭐⭐☆☆☆)
| 項目 | 内容 |
|------|------|
| **エンティティ** | ホールディングス |
| **カテゴリ** | 経費システム(グループ間取引) |
| **質問** | マークアップ「あり」だが、特殊な処理をしている場合は、該当取引になるのか?... |
| **正解例** | 該当取引となる。グループ会社コードを入力する... |
| **チャットボット回答** | はい、特殊な処理をしていても、**該当取引となります**。入力は**初期値「非該当」のまま**で問題ございません... |
**📊 評価詳細**
| 観点 | 評価 |
|------|------|
| 正確性 | 該当性の判定は正しいが、システム処理方法が正解例と矛盾。正解例は「コード入力」だが実際回答は「初期値のまま」 |
| 網羅性 | 判定理由は詳細だが、肝心の操作手順が誤り |
| 明瞭性 | 説明は非常に明瞭で理解しやすい構成 |
**💬 総合評価**: 取引区分の判定は正しいが、システムへの入力方法で重大な誤りがある
> ℹ️ 詳細な会話内容はチャットフロー側のログをご確認ください
### テストケース #15(スコア: ⭐⭐⭐☆☆)
| 項目 | 内容 |
|------|------|
| **エンティティ** | 事業部A(本部) |
| **カテゴリ** | グループ内取引報告 |
| **質問** | 「収益項目A」は報告が必要ですか。... |
| **正解例** | 報告対象外... |
| **チャットボット回答** | 「収益項目B」については、**報告対象外**です。... |
**📊 評価詳細**
| 観点 | 評価 |
|------|------|
| 正確性 | 結論はたまたま一致しているが、質問の『収益項目A』を『収益項目B』と勝手に解釈している |
| 網羅性 | 報告対象外という結論と根拠は含まれているが、質問の対象が異なる |
| 明瞭性 | 説明は明瞭で詳細な根拠も示されている |
**💬 総合評価**: 結論は正しいが質問の対象科目を誤解釈している
> ℹ️ 詳細な会話内容はチャットフロー側のログをご確認ください
---
## ✅ 高評価ケース一覧(needs_improvement=false)
| ID | スコア | エンティティ | 総合評価 |
|----|--------|--------------|----------|
| 1 | ⭐⭐⭐⭐⭐ | 事業部A(本部) | 正解例を完全に満たし、実務に必要な詳細情報も充実した完璧な回答 |
| 2 | ⭐⭐⭐⭐⭐ | 事業部B | 正解例を完全に満たし、詳細な補足と根拠も充実した完璧な回答 |
| 3 | ⭐⭐⭐⭐⭐ | 事業部A(支店) | 正解例を完全に満たし、詳細な根拠と補足説明も充実した完璧な回答 |
| ... | ... | ... | ... |
| 10 | ⭐⭐⭐⭐☆ | 事業部A(本部) | 正解例の要点を満たし、詳細な手順と連絡先も充実した良好な回答 |
| 16 | ⭐⭐⭐⭐☆ | 事業部A(本部) | 正解例の核心を正確に捉え、詳細な判定基準も提供した良好な回答 |
| ... | ... | ... | ... |
実装のポイントと工夫
1. API レスポンスからの「ノイズ除去」
「HTTP Request」ノードでチャットフロー API を叩くと、レスポンスは JSON 文字列(status_codeやbodyが含まれる状態)で返ってきます。
このまま評価 LLM に投げると、JSON 構文などのノイズに引きずられて評価精度が落ちます。そのため、パラメータ抽出ノードを使って、answerフィールドのテキストだけを綺麗に抜き出してから評価させています。地味ですが、評価精度を上げるために重要な工程です。
2. レポートを Markdown で出力
詳細レポートは、最終的に Markdown ファイルとして出力するようにしました。ファイル出力では、Dify マーケットプレイスで提供されているMarkdownエクスポーターを使用しています。
ここでのポイントは、「AIに読ませるため」 に出力している点です。私は普段、IDE(VS Code)上で Dify の開発をしています。この Markdown レポートをコピー&ペーストして、GitHub Copilot などに以下のような指示を出します。
「この評価レポートの『要改善ケース』を踏まえて、修正案を考えて」
このようにすることで、ワークフローのテスト実行 → レポート出力 → AIが修正案提示 → チャットフロー修正という改善サイクルを回せるようになります。
3. 並列実行によるテスト高速化
1件ずつ直列でチャットフローのテストを実行するとかなりの時間がかかります。そのため、イテレーションノードの並列実行数を「Max (10)」に設定し、並列でテストを走らせています。
チャットフロー側で最大同時リクエスト数を制限している場合は、イテレーションノードの並列実行数通りにならない可能性があるので注意してください。
4. API キーを環境変数(シークレット)に保存
検証対象のチャットフロー API を呼び出すための URL や API キーはノード内にハードコードせず、Dify の環境変数で管理しています。
-
DIFY_CHATFLOW_API_URL: 接続先 URL -
DIFY_CHATFLOW_API_KEY: API キー(Secretタイプ)
特に API キーは「Secret」タイプとして設定することで、Dify 画面上でマスク表示されます。また、アプリのエクスポート時にも値が含まれません。これにより、API キーの流出リスクを抑制しています。また、テスト対象を切り替える際も環境変数と API パラメータ周りの変更だけで済むため、運用の柔軟性も高まります。
運用上の注意点と課題
上記の評価ワークフローにより、リグレッションテストが大幅に効率化されました。
一方、実際に回してみて分かった「落とし穴」もあったので、共有します。
1. トークン消費量に注意
テスト1回で数十問程度のテストケースでも、チャットフローと評価ワークフロー側合わせて数万〜十数万トークンを消費することがあります。
便利だからといって、ちょっとした修正のたびに実行するとコストが爆発的に増加します。
従って、ある程度修正をまとめて行った後のタイミングで本ワークフローを実行するようにしています。
2. チャットフローのログ汚染問題
評価パイプラインからチャットフローを叩くと、当然ながらチャットフロー側に大量の会話ログが残ります。
ユーザーの利用ログを分析する際にこれらがノイズになるため、ユーザー試験用の Dify チャットフローを直接実行するのは避けたいところです。
開発・テスト用にアプリを別途複製して、そちらに対してテストを実行するのがお勧めです。
今後の展望
現在は、人がテスト結果を AI に相談して修正しています。将来的には Dify の標準機能であるMCP サーバーを活用できればと考えています。
Dify ではアプリを MCP サーバーとして簡単に公開でき、各種 AI ツールと直接連携させることが可能です。これにより、以下のようなサイクルが実現できます。
- GitHub Copilot や Claude Code などの AI が修正案を作成
- MCP 経由で Dify ワークフローのテストを直接実行
- テスト結果をみて、チャットフローを自動修復
- テスト結果が理想の形になるまで上記を繰り返し処理
このサイクルを組めれば、AI 自身で RAG が自動最適化される世界を作れそうです。
ただし、前述の通りトークンの爆発的消費が怖いので、今はまだ構想の段階に留めています。
まとめ
Dify と簡易な LLM-as-a-Judge を組み合わせることで、プロンプト修正によるデグレを素早く検知できるようになりました。
RAG の品質維持で悩んでいる方には、即効性のある「仕組み」としておすすめです。
本記事がどなたかのお役になれば幸いです。
参考文献
- A Survey on LLM-as-a-Judge
- LLM-as-a-judge: a complete guide to using LLMs for evaluations
- LLM-as-a-Judge Simply Explained: The Complete Guide to Run LLM Evals at Scale
- LLMによるLLMの評価「LLM-as-a-Judge」入門〜基礎から運用まで徹底解説
- DifyでつくるLLM-as-a-Judge