はじめに
会社でVB.NET環境でSeleniumを使用しWebサイトからスクレイピングを行う業務の保守にあたっているんですが、最近HTTPのConnectionFailureで処理が落ちてしまうことが多いので原因を探ってみました。
僕自身はVBよりはPythonの方が慣れているのでPythonで確認しています。
今回は検証作業の記録をアップすることを目的としているので、何か気付いたことがあればご指摘いただければありがたいです。
もしSeleniumの使い方やDockerでの環境構築について知りたい方は前回、前々回の記事をご覧になってみてください。 ⇨ [Python] Dockerコンテナでseleniumを使ってみる
目的
前提
僕が保守しているプログラムについては大まかに以下の機能を備えています。
・ChromeDriverでChromeを起動
・必要なWebページにログインする
・ページ内テキストを取得しテキストアプリに保存する
・ログインやテキストの取得といった処理を非同期で行なっている。
調査内容
色々調べていると前提で記載した機能の中の非同期という箇所が悪さしているのではと思えたのでそこに焦点を当てて探ってみます。
具体的には、
・webdriverとのコネクションを確立する
・メインスレッドでwebサイトにアクセスしページのURLを取得する
・別のスレッドを立ち上げそこからwebサイトにアクセスしページのURLを取得する
といったことをやってみます。
検証
メインスレッドだけで実施してみる
まずは念のためメインスレッドだけで上記内容の処理を実行してみます。
from selenium import webdriver
# webdriverのオプションを設定
options = webdriver.ChromeOptions()
options.add_argument('--headless')
print('Connect remote browser...')
# webdriverのインスタンスを生成
driver = webdriver.Remote(command_executor='172.21.0.2:4444/wd/hub', options=options)
print('remote browser connected...')
# mainから呼び出すメソッド
def test_threading():
try:
# ブラウザでWebページを開く
driver.get('https://google.com')
print('current URL: ', driver.current_url)
# ブラウザでWebページを開く
driver.get('https://www.yahoo.co.jp/')
print('current URL: ', driver.current_url)
except Exception as e:
print('Exception: ', e)
finally:
# リモートサーバーとの接続を終了する
print('Connection stop...')
driver.quit()
if __name__ == '__main__':
print('Start')
test_threading()
内容は、webdriverインスタンスを生成し、get()メソッドでGoogleのページとyahooのページにアクセスし、それぞれのURLを取得しています。
それでは実行してみます。
root@682e97bc5f22:/work# python3 test_threading.py
Connect remote browser...
remote browser connected...
Start
current URL: https://www.google.com/
current URL: https://www.yahoo.co.jp/
Connection stop...
問題なく正常終了していますね。
同一スレッドだと特に問題はないようです。
別のスレッドで実行してみる
次にpythonの標準ライブラリのthreadingを使用しメインスレッドとは別のスレッドを立ち上げて実行してみます。
import threading
from selenium import webdriver
# webdriverのオプションを設定
options = webdriver.ChromeOptions()
options.add_argument('--headless')
print('Connect remote browser...')
# webdriverのインスタンスを生成
driver = webdriver.Remote(command_executor='172.21.0.2:4444/wd/hub', options=options)
print('remote browser connected...')
# 新しいスレッドで実施する内容を記述するメソッド
def worker_1():
print(threading.currentThread().getName(), 'start')
# ブラウザでWebページを開く
driver.get('https://www.yahoo.co.jp/')
print('current URL: ', driver.current_url)
print(threading.currentThread().getName(), 'end')
# mainから呼び出すメソッド
def test_threading():
try:
# ブラウザでWebページを開く
driver.get('https://google.com')
print('current URL: ', driver.current_url)
# 別スレッドを立ち上げる
thread_1 = threading.Thread(target=worker_1)
thread_1.start()
except Exception as e:
print('Exception: ', e)
finally:
# リモートサーバーとの接続を終了する
print('Connection stop...')
driver.quit()
if __name__ == '__main__':
print('Start')
test_threading()
簡単に内容を解説すると、
・webdriverのコネクションを確立した後、test_threading()関数内でget()メソッドでGoogleのページを取得します。
・その後threadingライブラリを使用し別スレッドを立ち上げ処理を移します。
・その新しいスレッド内でget()メソッドでyahooのページを取得します。
・新しく作成されたスレッドで実行する処理はworker_1()関数に記述しています。
実行結果
root@682e97bc5f22:/work# python3 test_threading.py
Connect remote browser...
remote browser connected...
Start
current URL: https://www.google.com/
Thread-1 start
Connection stop...
Exception in thread Thread-1:
Traceback (most recent call last):
File "/usr/lib/python3.8/threading.py", line 932, in _bootstrap_inner
self.run()
File "/usr/lib/python3.8/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "test_threading.py", line 19, in worker_1
print('current URL: ', driver.current_url)
File "/usr/local/lib/python3.8/dist-packages/selenium/webdriver/remote/webdriver.py", line 908, in current_url
return self.execute(Command.GET_CURRENT_URL)['value']
File "/usr/local/lib/python3.8/dist-packages/selenium/webdriver/remote/webdriver.py", line 418, in execute
self.error_handler.check_response(response)
File "/usr/local/lib/python3.8/dist-packages/selenium/webdriver/remote/errorhandler.py", line 243, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.InvalidSessionIdException: Message: invalid session id
新しくスレッドを立ち上げたworker_1()内のget()メソッドの部分で例外が発生して処理がストップしています。
新しいスレッドではwebdriverとのsessionに問題があり例外が発生しているようです。
3秒スリープを入れて再度実行
もしかしたらプログラムの処理が早くてdriverの処理が追いついていないのかもしれないので、同じくpython標準ライブラリのtimeのsleep()で3秒待ってみます。
import threading
import time
from selenium import webdriver
# webdriverのオプションを設定
options = webdriver.ChromeOptions()
options.add_argument('--headless')
print('Connect remote browser...')
# webdriverのインスタンスを生成
driver = webdriver.Remote(command_executor='172.21.0.2:4444/wd/hub', options=options)
print('remote browser connected...')
# 新しいスレッドで実施する内容を記述するメソッド
def worker_1():
print(threading.currentThread().getName(), 'start')
# ブラウザでWebページを開く
driver.get('https://www.yahoo.co.jp/')
print('current URL: ', driver.current_url)
print(threading.currentThread().getName(), 'end')
# mainから呼び出すメソッド
def test_threading():
try:
# ブラウザでWebページを開く
driver.get('https://google.com')
print('current URL: ', driver.current_url)
# 3秒待つ
time.sleep(3)
print('3 minutes passed...')
# 別スレッドを立ち上げる
thread_1 = threading.Thread(target=worker_1)
thread_1.start()
except Exception as e:
print('Exception: ', e)
finally:
# リモートサーバーとの接続を終了する
print('Connection stop...')
driver.quit()
if __name__ == '__main__':
print('Start')
test_threading()
とりあえず別のスレッドを立ち上げる前に3秒スリープを入れてみました。
実行してみます。
root@682e97bc5f22:/work# python3 test_threading.py
Connect remote browser...
remote browser connected...
Start
current URL: https://www.google.com/
3 minutes passed...
Thread-1 start
Connection stop...
Exception in thread Thread-1:
Traceback (most recent call last):
File "/usr/lib/python3.8/threading.py", line 932, in _bootstrap_inner
self.run()
File "/usr/lib/python3.8/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "test_threading.py", line 24, in worker_1
print('current URL: ', driver.current_url)
File "/usr/local/lib/python3.8/dist-packages/selenium/webdriver/remote/webdriver.py", line 908, in current_url
return self.execute(Command.GET_CURRENT_URL)['value']
File "/usr/local/lib/python3.8/dist-packages/selenium/webdriver/remote/webdriver.py", line 418, in execute
self.error_handler.check_response(response)
File "/usr/local/lib/python3.8/dist-packages/selenium/webdriver/remote/errorhandler.py", line 243, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.InvalidSessionIdException: Message: invalid session id
同じくwebdriverとのsessionに問題があり例外が発生しています。
Seleniumの処理速度については関係なさそうです。
スレッド毎にwebdriverインスタンスを生成してみる
スレッドが変わるとwebdriverとのsessionで問題が発生しているようなので、スレッド毎にwebdriverとの接続を確立してみます。
import threading
import time
from selenium import webdriver
# webdriverのオプションを設定
options = webdriver.ChromeOptions()
options.add_argument('--headless')
# 新しいスレッドで実施する内容を記述するメソッド
def worker_1():
try:
print(threading.currentThread().getName(), 'start')
print('Connect remote browser_2...')
# webdriverのインスタンスを生成
driver_2 = webdriver.Remote(command_executor='172.21.0.2:4444/wd/hub', options=options)
print('driver_2 remote browser connected...')
# ブラウザでWebページを開く
driver_2.get('https://www.yahoo.co.jp/')
print('driver_2 current URL: ', driver_2.current_url)
print(threading.currentThread().getName(), 'end')
except Exception as e:
print('driver_2 Exception: ', e)
finally:
# リモートサーバーとの接続を終了する
print('driver_2 Connection stop...')
driver_2.quit()
# mainから呼び出すメソッド
def test_threading():
try:
print('Connect remote browser_1...')
# webdriverのインスタンスを生成
driver_1 = webdriver.Remote(command_executor='172.21.0.2:4444/wd/hub', options=options)
print('driver_1: remote browser connected...')
# ブラウザでWebページを開く
driver_1.get('https://google.com')
print('driver_1 current URL: ', driver_1.current_url)
# 3秒待つ
time.sleep(3)
print('3 minutes passed...')
# 別スレッドを立ち上げる
thread_1 = threading.Thread(target=worker_1)
thread_1.start()
except Exception as e:
print('Exception: ', e)
finally:
# リモートサーバーとの接続を終了する
print('Connection stop...')
driver_1.quit()
if __name__ == '__main__':
print('Start')
test_threading()
これまでwebdriverインスタンスをメインスレッドに持っていて全てのスレッドから参照しようとしていましたが、各スレッド内でwebdriverインスタンスの生成と終了を実行するようにしてみました。
具体的にはメインスレッドのwebdriverインスタンス(driver_1)とは別に、新しいスレッドを立ち上げているworker_1()関数内でwebdriverインスタンス(driver_2)の生成と終了処理を行なっています。
では実行してみます。
root@682e97bc5f22:/work# python3 test_threading.py
Start
Connect remote browser_1...
driver_1: remote browser connected...
driver_1 current URL: https://www.google.com/
3 minutes passed...
Thread-1 start
Connection stop...
Connect remote browser_2...
driver_2 remote browser connected...
driver_2 current URL: https://www.yahoo.co.jp/
Thread-1 end
driver_2 Connection stop...
正常に終了出来ました。
やはりHTTPのsessionはスレッドを分けて生成しないとダメみたいですね。
Seleniumのsessionについて
webdriverの仕組み
いちおう今回発生していたsessionの問題はなぜ発生していたのかざっくり検証してみます。
下はSeleniumにおけるwebdriverの仕組みです。(Selenium公式より引用)
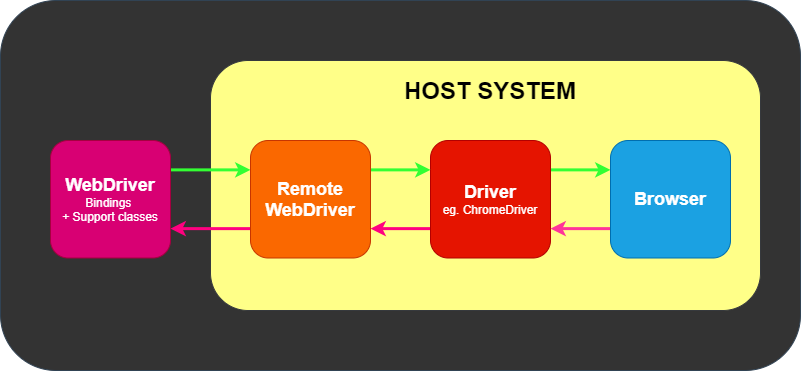
Seleniumのwebdriverは直接ブラウザを操作するわけではありません。
プログラムコードでwebdriverに指示されたコマンドはwebdriverでバインドされHTTP通信でJson形式でremote webdriver(ないしはdriver)に送信され、driverがブラウザを操作します。
webdriverがremote webdriverと通信する際、最初にsessionを確立しsessionIDを取得します。
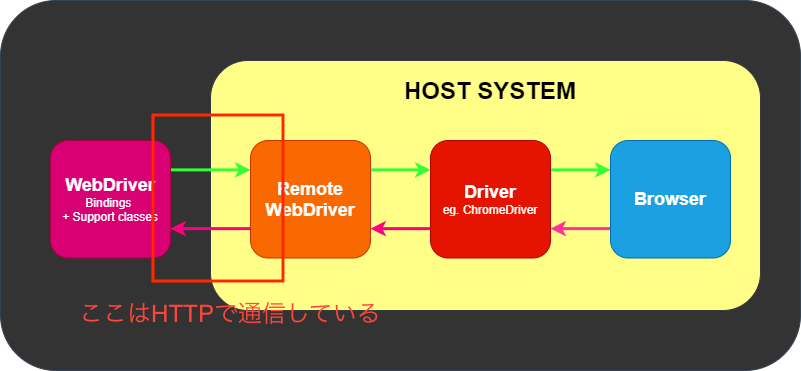
今回のように途中でスレッドが変わると新しいスレッドにはsessionID情報がないため、エラーとなっていたと考えられます。(もし僕の認識に誤りがあればすみません。。)
なので、Seleniumを使用中にスレッドなりプロセスなりが変わりそうであれば随時webdriverインスタンスを生成し処理した方が良さそうですね。
おわりに
はじめに書きましたが実際にエラーが発生しているのはVB.NET環境でAsync,Awaitで非同期を行なっている処理なので今回検証した内容とは若干異なるかもしれませんが、HTTP通信を異なるスレッドで動かそうとするとsessionの問題が発生することが分かりました。
たぶんスレッド間でのsession情報をやり取りする方法はあるかと思いますが、これは後々の課題にしたいと思います。
Seleniumを使う時というかHTTPプロトコルを使用して通信を行うときはどのスレッドやプロセスで実行しているか注意した方が良さそうですね。
もし僕と同じようにSeleniumのHTTP関連のエラーで悩んでいる方の参考になれば嬉しいです。
参考サイト
手を動かしながら学ぶSeleniumWebDriverの仕組み
webdriverの仕組みについてかなり参考になりました。ありがとうございます。
bashでWebブラウザ(Selenium WebDriver)を動かした話
webdriverとremoteの通信をcurlコマンドで実施しているサイトです。
実際にJsonでどのような内容を送っているのか参考になりました。ありがとうございます。
現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
Udemy, Youtube, Twitterで活躍中の酒井潤さんのpython入門。
内容が濃くかつ教え方が丁寧ですごく分かりやすいので、pythonについて学びたい方は一度は見た方が良いお勧めの動画です。
今回threadingライブラリを使用するにあたりかなり参考にしました。ありがとうございます。