本当にざっくりした説明です
機械学習とは
- 短時間の学習で、大量のデータから正確な結果を導く
- データから反復的に学習し、そこに潜むパターンを探し出す
参考:
Pythonで動かして学ぶ!あたらしい機械学習の教科書
AIの3大手法
現在のAIの主な手法は
- 教師あり学習:人が正解(正解ラベル)を示す
- 教師なし学習:人が正解を示さない AIが自動で分類する
- 強化学習:教師なし学習に近いが、AIに経験を積ませより良い解を導き出させる 例:ロボットアームの最適化
である
現在注目されている「ディープラーニング」は、3つの手法全てに適用できる「手段」である
ディープラーニング
-
神経を模したニューラルネットワークを構築する
人体で
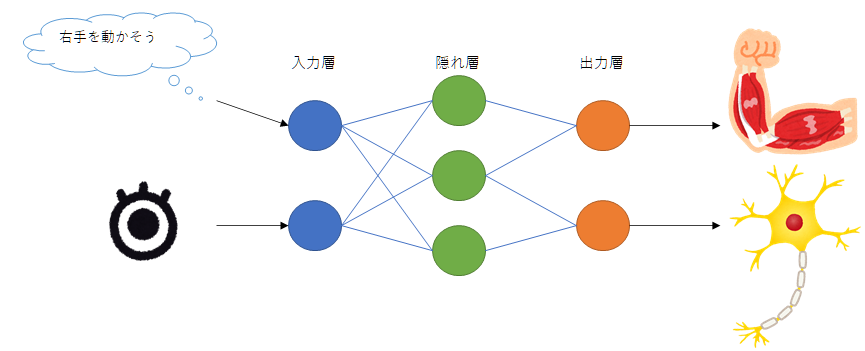
と個々の筋肉や刺激量を意識しないのと同様に
と、入力から推論した出力となるネットワークを構築する
-
学習時に、特徴を細かに指定しなくてよい ⇔ 学習用データの量を確保するとともに、データの質を精査しておく必要がある
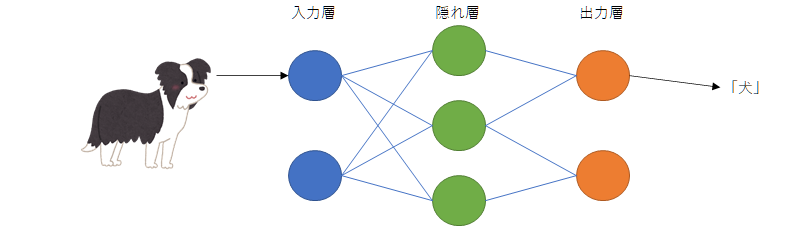
ニューラルネットワークとは
自分でニューラルネットワークを作ろう
演算ユニットは質より量
-
CPUの演算ユニットは個々の計算を高速で切り替えることで(見た目の)並立演算を実装している
⇒ いくら高性能なCPUでも、演算ユニットの総数は多くない
⇒ ・ 並行演算に見えても実際には直列演算なので総学習時間は余り短縮できない
・ 並行演算を実現する多コア化も、採算ライン面では問題があると考える -
高性能なAIでも、タイムリーかつコストを抑えて開発できなければ商業ベースには乗せにくいと考える
⇒ GPUCPUでの並行処理を活用する
演算ユニット数(CUDAコア数)の比較
| CPU | GPU |
|---|---|
| ≒ コア数 | 3584 |
-
Alpha碁の場合、
GPUCPU利用: 1日分の学習 ≒ CPUのみ: 30日の学習
であった
AIに学習用させる
参考( というより結論 ):
機械学習のデータセットの重要性
過学習を防ぐために
過学習を起こすと、実際の運用での正解率が低くなってしまう
- 過学習を緩和するために学習用データを多数用意する
- ドロップアウト等他の手法はAWSのアルゴリズムに実装されているので、今回は実装に関する問題は考慮しない
学習用データ数の目安
学習用データの拡張
- 学習用データは多いほうがよいが、十分な数を揃えるには限界がある
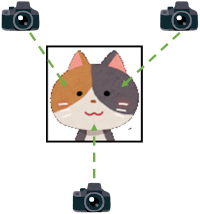
- 画像学習用データ拡張の例
-
撮影方向の多角化
-
画像の一部切取

-
画像の一部マスク

-
画像の回転

-
学習用データの正規化
学習用データ画像のレベルを正規化する
学習結果の活用
- 時間をかけてニューラルネットワークを構築・学習させても学習結果が出力されなければ意味がない
以降でAWSでの例を見ていく