新型コロナウイルス関連のニュース記事を対象として、TF-IDF分析によりこの一年をふり返ります。
⑴ ドキュメントの作成
1. データソース
- データのリソースとして多言語情報発信サイト「nippon.com」を利用させて頂きました。
- 日本の政治・経済・社会及び文化に関する情報が、日本語、英語、中国語簡体字、中国語繫体字、フランス語、スペイン語、ロシア語の7ヵ国語で配信されています。
2. データ取得と前処理
- WebサイトからTF-IDF分析に用いるデータを作成するには、➊HTMLデータを取得して必要部分を抽出し、➋ノイズを除去し、➌形態素解析によって任意の品詞のみ抽出して単語のリストを作成します。
- そうした処理を経て、すでにローカルPCにダウンロードしてあるテキストファイルを用います。詳しくはこちら 3. Pythonによる自然言語処理 3-4. TF-IDFでふり返るコロナの一年[データ作成] にまとめました。
- 年初から直近までの新型コロナウイルスに関するニュース記事を抽出したところ、1/16付~12/19付の全1216件となりました。各月の主な出来事とともに内訳を以下に示します。
| 月 | 記事 件数 |
主な出来事 |
|---|---|---|
| 1 | 64 | 1/6 厚労省が注意喚起「中国武漢で原因不明の肺炎」 1/16 日本国内で初めて感染者を確認、武漢渡航の中国籍男性 |
| 2 | 210 | 2/3 乗客の感染が確認されたクルーズ船、横浜入港 2/13 国内で初めて感染者死亡、神奈川県在住の80代女性 |
| 3 | 88 | 3/9 専門家会議が「3密」回避を呼びかけ 3/24 東京五輪の延期を決定 |
| 4 | 320 | 4/7 首都圏 及び大阪・兵庫・福岡の7都府県に緊急事態宣言 4/16 緊急事態宣言を全国拡大 |
| 5 | 357 | 5/4 緊急事態宣言を5月31日まで延長 5/25 緊急事態宣言を全面解除 |
| 6 | 65 | 6/19 都道府県またぐ移動自粛を全国で緩和 6/29 世界の死者50万人超 |
| 7 | 35 | 7/3 国内1日の感染者2ヵ月ぶりに200人超 7/22 GoToトラベル開始 / 国内1日の感染者795人過去最多 |
| 8 | 18 | 8/17 4-6月期GDPが年率27.8%減 8/20 対策分科会が「流行はピークに達した」と見解 |
| 9 | 7 | 9/5 WHO「ワクチン分配開始は来年中頃」の見通し示す 9/18 GoToトラベル東京発着の予約を解禁 |
| 10 | 12 | 10/1 GoToイート開始 10/12 ヨーロッパで感染急拡大 |
| 11 | 25 | 11/19 国内感染者数が2日連続で過去最多を更新 11/20 政府分科会がGoTo見直しを政府に求める提言 |
| 12 | 15 | 12/14 GoToトラベル全国一斉停止 12/17 東京都1日の新規感染822人、最も高い警戒レベルに |
| 計 | 1216 |
3. テキストファイルをアップロード
- Google Colaboratory 上にテキストファイルを12ヵ月分まとめてアップロードします。
from google.colab import files
uploaded = files.upload()

- アップロード操作用のUIが現れて[ファイル選択]をクリックするとダイアログが表示されますので、ファイルを選択して[開く]でアップロードが開始されます。
4. テキストファイルの読み込み
# 1~12までの等差数列を0埋め2桁にする
months = ['{0:02d}'.format(i) for i in range(1,13,1)]
docs = []
for month in months:
# ファイル名を生成
file_name = "nipponcom_covid19_2020-" + month + ".txt"
# テキストとして読み込み
with open(file_name, mode='rt', encoding='utf-8-sig') as f:
text = f.read()
docs.append(text)

- TF-IDFに用いるデータ
docsは、月単位の12ヵ月分、名詞のみ半角スペース区切りになっています。
⑵ データを概観する
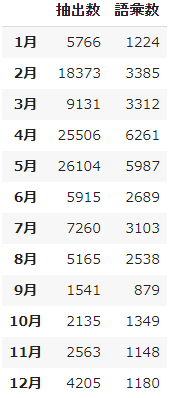
- まず、定量的にデータを概観します。月毎の要素数、及びユニークの語彙数をカウントします。
1. 月毎の抽出数 及び語彙数
import pandas as pd
metrics = []
for doc in docs:
value = []
# 空白を区切り文字として分割
words = pd.Series(doc.split(" "))
# 要素の個数をカウント
value.append(len(words))
# 一意の要素数をカウント
value.append(words.nunique())
metrics.append(value)
# データフレームに整形
names = ["抽出数", "語彙数"]
months = ['{0}月'.format(i) for i in range(1, 13, 1)]
pd.DataFrame(metrics, columns=names, index=months)
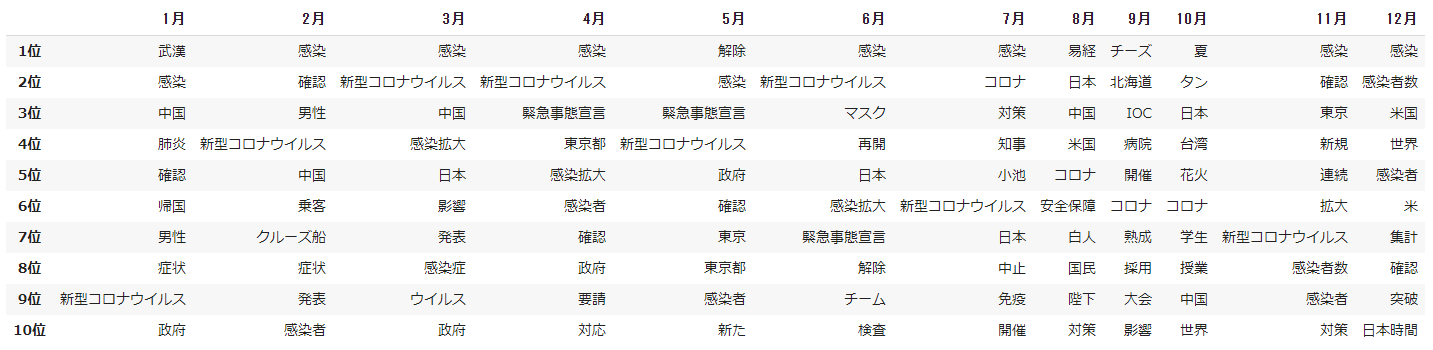
2. 月毎の出現頻度 上位10語
- 月毎に出現頻度の高い順で上位の10語を取得します。
from collections import Counter
rank_frequency = []
for doc in docs:
value = []
# 空白を区切り文字として分割
words = pd.Series(doc.split(" "))
# ユニークの語彙数をカウント
cnt = Counter(words)
v = cnt.most_common(10) #上位
value.append(v)
rank_frequency.append(value)
rank_frequency

- データフレームにまとめます。
import numpy as np
# 各月上位10語を取得
ranking = []
for a in rank_frequency:
temp = []
for i in a:
for n in range(0,10,1):
j = i[n]
temp.append(j[0])
ranking.append(temp)
# データフレーム化
data = np.array(ranking).T
rank = ['{0}位'.format(i) for i in range(1, 11, 1)]
pd.DataFrame(data, columns=months, index=rank)
⑶ TF-IDF分析
- scikit-learnの
TfidfVectorizerを利用して$tfidf$スコアを計算します。
from sklearn.feature_extraction.text import TfidfVectorizer
# モデルを生成
vectorizer = TfidfVectorizer(smooth_idf=False)
X = vectorizer.fit_transform(docs)
# データフレーム化
values = X.toarray()
feature_names = vectorizer.get_feature_names()
month_num = ['{0:02d}'.format(i) for i in range(1,13,1)]
df_score = pd.DataFrame(values, columns = feature_names, index=month_num)
print(df_score)
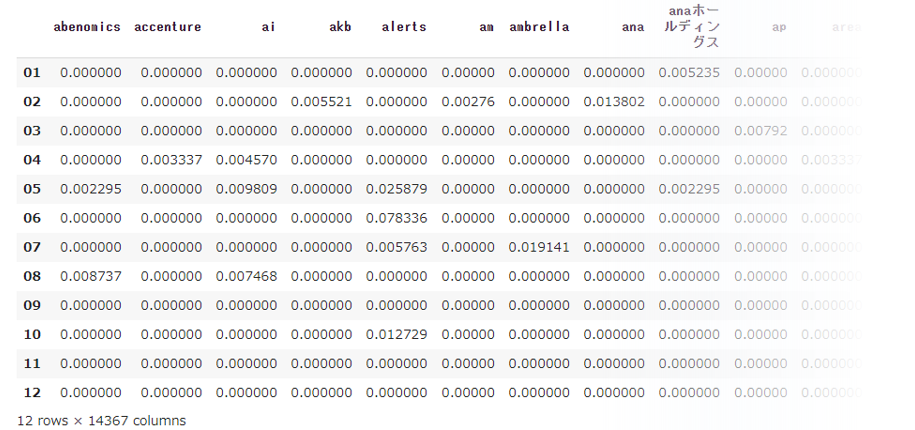
- 12 rows × 14367 columns となっており、12ヵ月間全体では「abenomics」に始まる14367語が抽出されています。
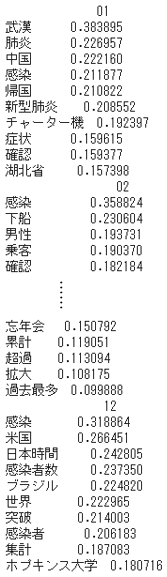
- $tfidf$スコアにもとづく各月の上位10語を取得してみます。
for i in range(0,12,1):
monthly_rank = []
df_score_ = df_score[i:i+1].T
df_score_sorted = df_score_.sort_values(month_num[i], ascending=False)
print(df_score_sorted.head(10))
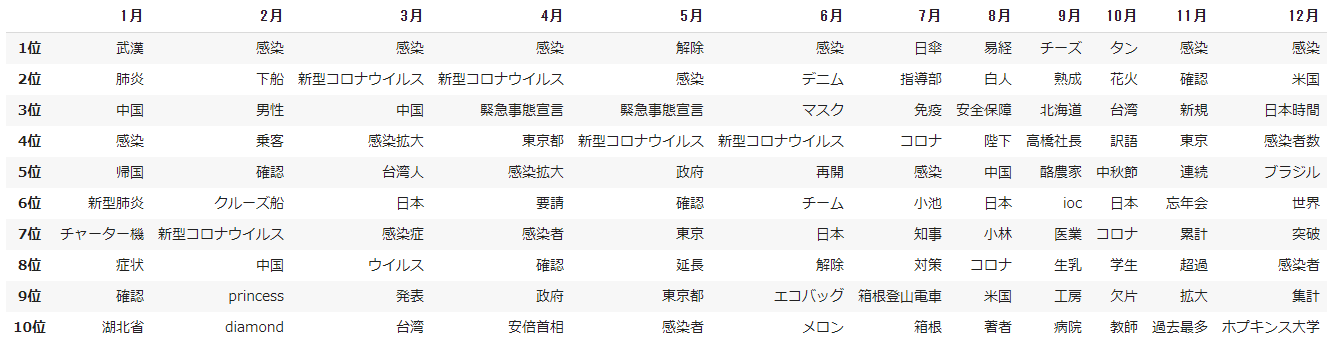
- データフレームにまとめます。
result = []
for i,j in zip(range(0,12,1), month_num):
test = df_score[i:i+1].T
# 上位10語を取得
test_sorted = test.sort_values(j, ascending=False)
test_rank = test_sorted.head(10)
# 名詞ラベルのみ抽出
r = test_rank.index
result.append(r)
pd.DataFrame(result,columns=rank,index=months).T
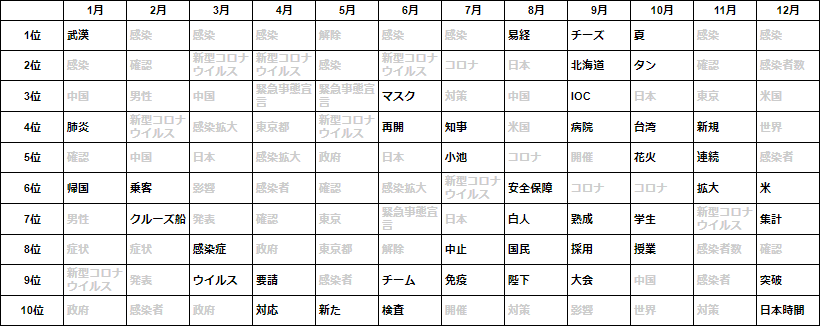
⑷ 出現頻度とTF-IDF分析の比較
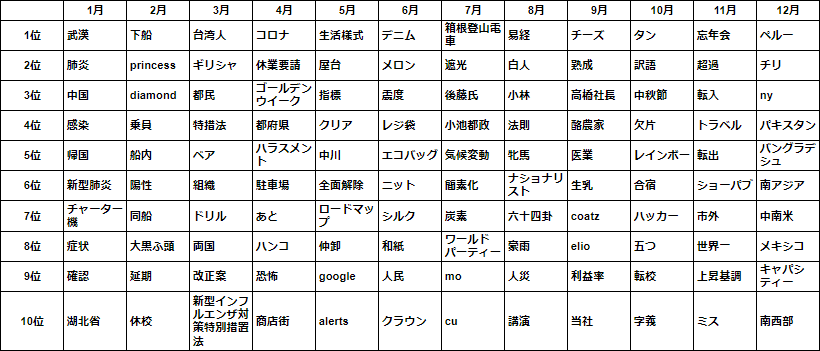
- 出現頻度の上位10語と TF-IDF の上位10語とを比較対照します。それぞれ複数の月に重複して登場する語をグレーアウトし、月毎に特徴的な語を見ていきます。
出現頻度上位10語
TF-IDF上位10語
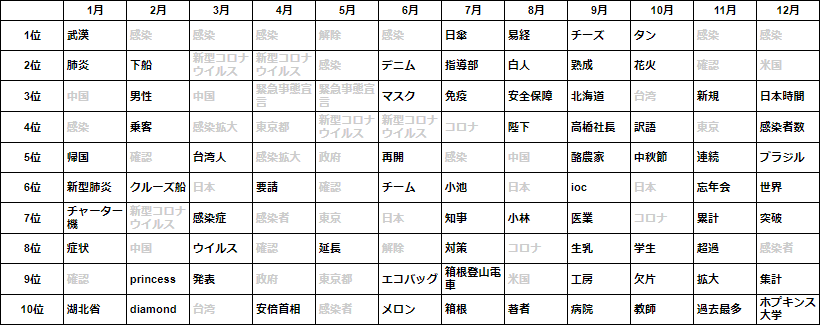
- 一見して TF-IDF の方は重複する語がより少なく、特徴的な語がランクインしていることから各月の主題がわかりやすくなっています。
- 例えば、1月は武漢に渡航歴のある中国人男性が国内初の感染者として確認され、つづく2月は乗客に感染が確認されたクルーズ船をめぐる動静が注目されていました。
- 3月から5月にかけては感染拡大とそれによる緊急事態宣言の発出から解除に至る期間にあたり、この間月々を特徴づける語は少なくなっています。
- 第1波をやり過ごした6月以降は再び特徴語が目立つようになりますが、記事の件数も大幅に減少することもあり、内容的にはリソースによって異同が出てくるものと推察されます。
- そして11月に入ると第3波の急速な昂進となり、同時に世界的な感染の再拡大を背景として日本も例外ではない状況がつづいています。
⑸ 新出語の変遷
- TF-IDFを応用して、試みに**「新出語」**という概念を導入します。
- 前月までに出現した語(既出語)を除外して、その月に初めて出現した語(新出語)に注目します。月を追うごとに出くわした新しい情報や局面を表すものといえます。
- 以下、10月を対象として、まず9月までの既出語を取得して
word_listとします。
import itertools
# 10月を指定
n = 10
word_list = []
for i in range(0,n,1):
df = df_score[i:n-1]
df = df.loc[:, (df != 0).any(axis=0)]
word = list(df.columns)
word_list.append(word)
# 1次元に平坦化
word_list = list(itertools.chain.from_iterable(word_list))
len(word_list)
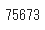
- 9月までに出現した語は75673語となっています。
- 10月に出現した語から9月までの既出語を除いて、tfidfスコアによる上位10語を求めます。
- なお、ここで用いる
df_scoreは1~10月までのデータで別途算出したものです。
# 当月のみを抽出
df_current = df_score[n-1:n]
df_current = df_current.loc[:, (df_current != 0).any(axis=0)]
# 既出語の除去
for i in word_list:
if i in df_current:
df_current = df_current.drop(i, axis=1)
# TF-IDF上位10語を抽出
df_current = df_current.T
df_sorted = df_current.sort_values(str(n), ascending=False)
df_sorted.head(10)
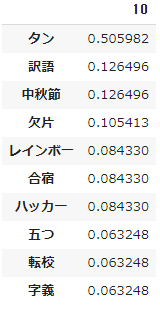
- 以上の処理を12ヵ月分行ない、各月における新出語を抽出して下表にまとめました。
- 1月には前月までの既出語がないので、先のTF-IDFの上位10語と変わりがありません。
- 1月の時点で既に「新型コロナウイルス」の呼称はありましたが**「肺炎」「新型肺炎」の語が目立ちます。先のとおり2月から3月にかけて感染拡大に伴い「新型コロナウイルス」の呼称は定着しますが、4月には「コロナ」**の略称が一般化する様子がうかがえます。
- また、10月の第1位「タン」とは、台湾のIT大臣 オードリー・タンさんの「タン」です。彼女がオンラインコミュニティに呼びかけて、ごく短期間でマスクマップアプリを完成させて「マスクが買えない」という状況を解消したことで一躍注目されました。
- アプリ開発の始動が2月4日午後、翌5日早朝 政府のデータフォーマット公開を受けて、明けて6日午前10時に正式リリースされました。その後、在庫データの更新サイクルが短縮され、一方さまざまなマスクマップアプリが開発されて、4月30日以降マスクの需給は均衡して当該アプリはその役目を終えたといいます。
時に日本では、いわゆるアベノマスクの異物混入やカビが取り沙汰されていた頃でした。 - ご興味のある方は『Au オードリー・タン 天才IT相7つの顔』(文藝春秋)をご覧いただければ幸いです。