- Qiita Advent Calendar 2020 「自然言語処理」22日目の「TF-IDFでふり返るコロナの一年」で用いたデータの作成手順をまとめます。
- ⑴スクレイピング、⑵クレンジング、⑶形態素解析という3つのステップになります。
⑴ スクレイピングによるデータ取得
1. ニュース毎のURLを収集
- 2020年1月~12月(12/20)を対象期間として、この間に報じられたコロナ関連のニュース記事のURLを収集します。
- リソースとして、多言語情報発信サイト『nippon.com』のアーカイブ「新型コロナウイルス」を利用させていただきました。また、それ以前の期間(3/13以前)については、同じく nippon.com のニュースアーカイブからコロナ関連という視点で抽出しています。
- URLはすべて
https://www.nippon.com/ja/+hoge/hoge012345/の形式となっていますので、+ 以下をリストにまとめたものが以下、例として6月分を示しますが、著作権に配慮して一部を掲載するにとどめます。
# covid-19_2020-06
pagepath = ["japan-topics/bg900175/",
"in-depth/d00592/",
"news/p01506/",
"news/p01505/",
"news/p01501/",
# 中略
"news/fnn2020060147804/",
"news/fnn2020060147795/",
"news/fnn2020060147790/"]
2. HTMLデータの取得、必要部分の抽出
import requests
from bs4 import BeautifulSoup
-
requestsは、PythonのHTTP通信ライブラリで、スクレイピング対象の URL にリクエストを送り HTML データを取得します。 -
BeautifulSoupは HTML パーサライブラリで、取得した **HTML データを解析して必要部分のみ抽出(=パース処理)**を行ないます。 - ➊
requestsでHTMLを丸ごと取得してきて、➋BeautifulSoupでそれを整形した上で必要部分を抽出する条件を判断し、➌selectでその条件によって必要部分を抜き出す、という手順です。
docs = []
for i in pagepath:
# ➊ HTMLデータを取得
response = requests.get("https://www.nippon.com/ja/" + str(i))
html_doc = response.text
# ➋ パース処理
soup = BeautifulSoup(html_doc, 'html.parser')
# ➌ <div class="editArea"> 直下の <p>タグ部分を抽出
target = soup.select('.editArea > p')
# <p>タグで括られた文章ごとにテキストのみ抽出
value = []
for t in target:
val = t.get_text()
value.append(val)
# リスト内の空データを削除
value_ = filter(lambda str:str != '', value)
value_ = list(value_)
# 全角空白にあたる「\u3000」を削除
doc = []
for v in value_:
val = v.replace('\u3000', '')
doc.append(val)
docs.append(doc)
- 抽出された必要部分
docsは次のとおりです。

- 参考までに、以上の処理を段階的に見ておきます。
まず➊ requests によりHTMLデータを取得し、テキストに変換して格納された段階。
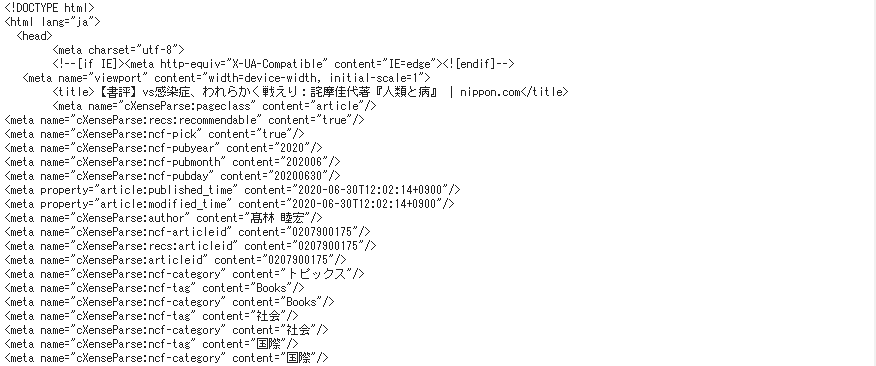
➋ 次いで BeautifulSoup オブジェクトを生成し、print(soup.prettify())により文字列を整形して出力した段階です。ここから必要部分を取得するための条件を見定めます。

➌ 次はselectに抽出条件を渡して必要部分だけを取り出した段階であり、ここから本文テキストだけを取り出した結果がdocsになります。

⑵ テキストのクレンジング
- 分析上ノイズとなる文字や語句などをテキストから除去するための関数として
cleansingを定義します。
1. クレンジング処理の関数を定義
- Pythonの正規表現モジュール
reと併せて日本語文を標準化するモジュール neologdnを利用します。
!pip install neologdn===0.3.2
- 削除ないし置換の条件式を指定します。例えば句読点やカッコなど標準的なもののほか、試験的に1~6月の半年分について形態素解析までを行なった結果から適宜追加したものとなっています。
import re
import neologdn
def cleansing(text):
text = ','.join(text) #カンマ区切りで平坦化
text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", text) #URL削除
text = neologdn.normalize(text) #アルファベット・数字:半角、カタカナ:全角
text = re.sub(r'[0-9]{4}年', '', text) ##日付を削除(yyyy年)
text = re.sub(r'[0-9]{2}年', '', text) ##日付を削除(yy年)
text = re.sub(r'\d+月', '', text) #日付を削除(何月)
text = re.sub(r'\d+日', '', text) #日付を削除(何日)
text = re.sub(r'\d+時', '', text) #時間を削除(何時)
text = re.sub(r'\d+分', '', text) #時間を削除(何分)
text = re.sub(r'\d+代', '', text) #年代を削除
text = re.sub(r'\d+人', '', text) #人数を削除(何人)
text = re.sub(r'\d+万人', '', text) #人数を削除(何万人)
text = re.sub(r'\d+\.\d+\%', '', text) #パーセントを削除(小数)
text = re.sub(r'\d+\%', '', text) #パーセントを削除(整数)
text = re.sub(r'\d+\.\d+%', '', text) #パーセントを削除(小数)
text = re.sub(r'\d+%', '', text) #パーセントを削除(整数)
text = re.sub(r'\d+カ月', '', text) #月数を削除(何カ月)
text = re.sub(r'\【.*\】', '', text) #【】とその中身を削除
text = re.sub(r'\[.*\]', '', text) #[]とその中身を削除
text = re.sub(r'、|。', '', text) #句読点を削除
text = re.sub(r'「|」|『|』|\(|\)|\(|\)', '', text) #カッコを削除
text = re.sub(r':|:|=|=|/|/|~|~|・', '', text) #記号を削除
# ニュースソース
text = text.replace("アフロ", "")
text = text.replace("時事通信", "")
text = text.replace("時事", "")
text = text.replace("テレビ西日本", "")
text = text.replace("関西テレビ", "")
text = text.replace("フジテレビ", "")
text = text.replace("FNNプライムオンライン", "")
text = text.replace("ニッポンドットコム編集部", "")
text = text.replace("unerry", "")
text = text.replace("THE PAGE", "")
text = text.replace("THE PAGE Youtubeチャンネル", "")
text = text.replace("Live News it!", "")
text = text.replace("AFP", "")
text = text.replace("KDDI", "")
text = text.replace("ぱくたそ", "")
text = text.replace("PIXTA", "")
# 慣用句・慣用的なフレーズ
text = text.replace("バナー写真", "")
text = text.replace("写真提供", "")
text = text.replace("資料写真", "")
text = text.replace("下写真", "")
text = text.replace("バナー画像", "")
text = text.replace("画像提供", "")
text = text.replace("筆者撮影", "")
text = text.replace("筆者提供", "")
text = text.replace("元記事・動画はこちら", "")
text = text.replace("元記事はこちら", "")
text = text.replace("掲載", "")
text = text.replace("撮影", "")
text = text.replace("出所", "")
text = text.replace("映像", "")
text = text.replace("提供", "")
text = text.replace("報道局", "")
# 不要なスペース・改行
text = text.rstrip() #改行・スペース削除
text = text.replace("\xa0", "")
text = text.upper() #アルファベット:大文字
text = re.sub(r'\d+', '', text) ##アラビア数字を削除
return text
2. クレンジング処理の実行
docs_ = []
for i in docs:
text = cleansing(i)
docs_.append(text)

⑶ ストップワードの検討と指定
- ストップワードを指定するに先立って、アルファベットの熟語・成句にどのようなものが挙がっているかを念の為 確認しました。
1. アルファベット語句を取得
-
re.findall()の引数は(検索したい語形パターン, 検索対象の文字列, re.ASCII)となっていて、第三引数のre.ASCIIは「ASCII文字(半角英数字・記号・制御文字など)にのみ合致」という指定です。
alphabets = []
for i in docs_:
alphabet = re.findall(r'\w+', i, re.ASCII)
if alphabet:
alphabets.append(alphabet)
print(alphabets)

2. 出現頻度 上位10語を取得
-
itertoolsは、とかく時間のかかる
for文のループ処理を、より効率的に実行するイテレータ生成関数を集めたモジュールです。 - その
chain.from_iterableで多次元リストに含まれる全ての要素を平坦化し、一つのリストにまとめます。 - Python標準ライブラリ
collectionsで単語ごとの出現回数を取得し、さらにcollections.Counterで出現回数上位10語を取得します。
import itertools
import collections
from collections import Counter
import pandas as pd
# 多次元配列の平坦化
alphabets_list = list(itertools.chain.from_iterable(alphabets))
# 出現回数の取得
cnt = Counter(alphabets_list)
# 上位10語を取得
cnt_sorted = cnt.most_common(10)
# データフレーム化
pd.DataFrame(cnt_sorted, columns=["英単語", "出現回数"])
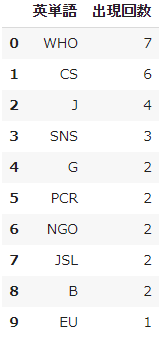
- 例えばニュース提供元のクレジットなど、ニュース本文には含まれない単語が高頻度に挙がっていないかどうかを確認しました。
3. ストップワードの指定
- 単体では具体的な意味を示さない語を、ストップワードとして除外対象とします。
stopwords = ["一", "二", "三", "四", "五", "六", "七", "八", "九", "〇", # 漢数字
"どれ", "どちら", "どっち", "どこ", "どなた", "誰", "何", "いつ", # 不定詞
"これ", "それ", "あれ", "こちら", "そちら", "あちら", # 指示詞
"こっち", "そっち", "あっち", "ここ", "そこ", "あそこ",
"私", "僕", "俺", "あなた", "君", "彼", "彼女", #人称代名詞
"個", "件", "回", "度", "戸", "面", "基", "階", "軒", "棟", # 助数詞
"台", "枚", "割", "周年", "人", "円", "年", "時", "者", "万",
"数", "便", "目", "億", "歳", "計", "点", "期", "日",
"の", "もの", "こと", "よう", "さま", "さ", "ため", "あたり", # 被修飾名詞
"はず", "ほか", "わけ", "ぶり", "ところ", "うち", "なか", "ん",
"次", "場", "限り", "辺", "方", "用",
"上", "中", "下", "前", "後", "左", "右", "以上", "以下", # 接尾辞
"以外", "以内", "以降", "以前", "化", "間", "感", "調", "的",
"派", "症", "頃", "市", "氏", "大", "減", "比", "率",
"ごろ", "がち", "そう", "たち", "ら", "さん",
"©", "◎", "○", "●", "▼", "*"] # 記号
⑷ 形態素解析によるデータ作成
- 形態素解析エンジン MeCab 及び辞書 mecab-ipadic-NEologd を用いて一文毎に形態素解析を行ない、ストップワードを除いた名詞だけのリストを作成します。
1. MeCab、mecab-ipadic-NEologdのインストール
# MeCab
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!pip install mecab-python3 > /dev/null
# mecab-ipadic-NEologd
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
- 辞書のパスを確認します。
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
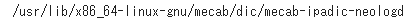
import MeCab
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
m_neo = MeCab.Tagger(path)
- 出力モードに
pathすなわち mecab-ipadic-NEologd を指定してインスタンスを生成しました。
2. 形態素解析によって名詞を抽出
- 記事単位に分かれた1ヵ月分のデータ
docsから、記事ごとに処理して結果をnounに格納します。
noun = []
for d in docs_:
result = []
v1 = m_neo.parse(d) #形態素解析の結果
v2 = v1.splitlines() #語単位に分割したリスト
for v in v2:
v3 = v.split("\t") #1語分の解析結果を空白で「元の語」と「解析の内容部分」に2分割
if len(v3) == 2: #EOS"や" "を除く
v4 = v3[1].split(',') #解析の内容部分
if (v4[0] == "名詞") and (v4[6] not in stopwords):
#print(v4[6])
result.append(v4[6])
noun.append(result)
print(noun)
3. TF-IDF用にデータを整形
-
sumで二次元リストを一次元リストに変換し、joinでカンマ区切りから半角スペース区切りに変換します。
doc_06 = sum(noun, [])
text_06 = ' '.join(doc_06)
print(text_06)

- 以上で、記事単位の1ヵ月分の名詞データが、一つの月単位のドキュメントにまとまりました。
4. ローカルPCにダウンロード
- では
text_06を'nipponcom_covd19_2020-06.txt'というファイルに書き出します。引数の'w'は書き込みモードの指定です。
with open('nipponcom_covid19_2020-06.txt', 'w') as f:
f.write(text_06)
-
filesは、ColaboratoryとローカルPCとの間でファイルをアップロードないしダウンロードするためのモジュールです。
from google.colab import files
files.download('nipponcom_covid19_2020-06.txt')
- 以上の処理を12ヵ月分を行ない、ローカルPCに取り込んでいたものを当該記事のTF-IDF分析に用いました。