-
**単語N-gram**は、隣り合った単語の組をデータの単位とします。2-gram(2単語)であれば次のとおりです。

-
共起(co-location:コロケーション)は、対象とする単位(文)の中で単語が共に出現する回数をカウントします。

-
上記は名詞を対象に2単語とした例ですが、つまり相互の位置関係に関わらず、同一文中に出現する単語の組み合わせがデータの単位となります。
1. テキストデータの準備
⑴ 各種モジュールのインポート
import re
import zipfile
import urllib.request
import os.path
import glob
-
re:Regular Expressionの略で、正規表現の操作をするためのモジュール -
zipfile:zipファイルを操作するためのモジュール -
urllib.request:インターネット上のリソースを取得するためのモジュール -
os.path:パス名を操作するためのモジュール -
glob:ファイルパス名を取得するためのモジュール
⑵ ファイルパスの取得
- コーパスには、インターネット上の電子図書館「青空文庫」から、夏目漱石の『私の個人主義(新字新仮名、作品ID:772)』をお借りします。
- 青空文庫からテキストファイルを取得する方法
URL = 'https://www.aozora.gr.jp/cards/000148/files/772_ruby_33099.zip'
⑶ テキストファイルの取得と本文の抽出
- 以下にメソッドを2つ定義します。
- 1つ目は、zipファイルを取得し、解凍して、テキストファイルのパスを取得するメソッドです。
def download(URL):
# zipファイルのダウンロード
zip_file = re.split(r'/', URL)[-1]
urllib.request.urlretrieve(URL, zip_file)
dir = os.path.splitext(zip_file)[0]
# zipファイルの解凍と保存
with zipfile.ZipFile(zip_file) as zip_object:
zip_object.extractall(dir)
os.remove(zip_file)
# テキストファイルのパスを取得
path = os.path.join(dir,'*.txt')
list = glob.glob(path)
return list[0]
- 2つ目は、テキストファイルを読み込んで本文だけを抽出するメソッドになりますが、あわせて文中に含まれるルビや注記、改行コードや不要なスペースなども削除しておきます。
def convert(download_text):
# ファイルの読み込み
data = open(download_text, 'rb').read()
text = data.decode('shift_jis')
# 本文の抽出
text = re.split(r'\-{5,}', text)[2]
text = re.split(r'底本:', text)[0]
text = re.split(r'[#改ページ]', text)[0]
# 不要部分の削除
text = re.sub(r'《.+?》', '', text)
text = re.sub(r'[#.+?]', '', text)
text = re.sub(r'|', '', text)
text = re.sub(r'\r\n', '', text)
text = re.sub(r'\u3000', '', text)
text = re.sub(r'「', '', text)
text = re.sub(r'」', '', text)
return text
- さて、先に取得済みのファイルパスを引数として2つのメソッドを実行し、さらに句点「。」で文単位に分割します。
# ファイルパスの取得
download_file = download(URL)
# 本文のみ抽出
text = convert(download_file)
# 文単位のリストに分割
sentences = text.split("。")

- 本文が文単位で分割された、こちらをもとに**共起単語のペアと出現頻度からなる「共起データ」**を作成していきます。
2. 共起データの作成
⑷ MeCabのインストール
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
⑸ 文単位の名詞リストの生成
-
MeCab.Tagger()の引数は「出力モード」の指定ですが、-Ochasenは形態素解析の結果を出力してくれます。 - 形態素解析は文単位で行ない、名詞を対象に単語の基本形を取得して文単位の名詞リストを生成します。
import MeCab
mecab = MeCab.Tagger("-Ochasen")
# 文単位の名詞リストを生成
noun_list = [
[v.split()[2] for v in mecab.parse(sentence).splitlines()
if (len(v.split())>=3 and v.split()[3][:2]=='名詞')]
for sentence in sentences
]
-
for sentence in sentencesによって一文ずつ取り出す毎にmecab.parse(sentence)で形態素解析にかけています。 - その都度、
splitlines()で語単位に分割したリストをvとして、さらにvをsplit()で分割してリスト化した中から第3要素[2]を取得します。 - 以下に、形態素解析の出力フォーマットを例示します。 タブ区切りの
[2]は語の基本形(■部分)です。

- また、if文の
v.split()[3][:2]=='名詞'によって、vの第4要素[3]にあたる品詞が名詞(■部分)に一致するものだけが抽出されます。 - 出力結果は以下のとおり、名詞の基本形だけが抜き出されて文単位のリストを構成しています。

⑹ 共起データの生成
- 共起データとは、共起単語のペアと出現頻度からなる辞書型オブジェクトになります。
import itertools
from collections import Counter
-
itertools:効率的なループ処理のためのイテレータ関数を集めたモジュール -
Counter:各要素の出現個数をカウントするためのモジュール
# 文単位の名詞ペアリストを生成
pair_list = [
list(itertools.combinations(n, 2))
for n in noun_list if len(noun_list) >=2
]
# 名詞ペアリストの平坦化
all_pairs = []
for u in pair_list:
all_pairs.extend(u)
# 名詞ペアの頻度をカウント
cnt_pairs = Counter(all_pairs)
- 文単位の名詞リストから2語以上あるものを順次取り出して、
itertools.combinations()で2語の組み合わせを生成し、list()でリスト化してpair_listに格納します。 - ただし、
pair_listは文単位なのでそのままではカウントができません。 そこで新たに用意した変数all_pairsにextend()で順次追加するようにして平坦化します。 - これを
Counter()に渡して辞書型の共起データcnt_pairsを生成します。

3. 作図用データの作成
import pandas as pd
import numpy as np
⑺ 共起データの絞り込み
- 作図にあたって見た目を簡潔にするために要素を絞り込みます。 ここでは出現頻度で上位50組のリストを生成します。
tops = sorted(
cnt_pairs.items(),
key=lambda x: x[1], reverse=True
)[:50]
-
sorted()とlambda式を組み合わせた構文になっていて、辞書型オブジェクトをkey=lambda以下で指定した要素を基準としてソートします。 - 基準となる
x[1]は第2要素、すなわち頻度で逆順ソートreverse=Trueしたものから上位50組を取り出しています。
⑻ 重み付きデータの生成
noun_1 = []
noun_2 = []
frequency = []
# データフレームの作成
for n,f in tops:
noun_1.append(n[0])
noun_2.append(n[1])
frequency.append(f)
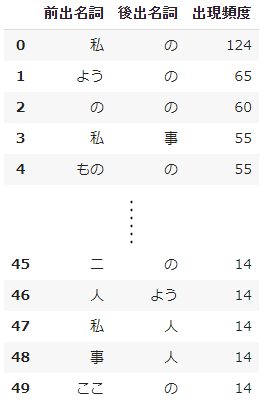
df = pd.DataFrame({'前出名詞': noun_1, '後出名詞': noun_2, '出現頻度': frequency})
# 重み付きデータの設定
weighted_edges = np.array(df)
- 上位50組分の共起データをarrayに変換して
weighted_edges(重み付きデータ)としました。 - 以下に、arrayに変換する前のデータフレームを示します。
4. ネットワーク図の描画
⑼ 可視化ライブラリのインポート
import matplotlib.pyplot as plt
import networkx as nx
%matplotlib inline
- networkXは、Pythonで複雑なネットワークやグラフ構造を作成・操作するためのパッケージです。
- ネットワーク図において、頂点のことを**ノード(node)といい、頂点同士を連結する辺をエッジ(edge)**といいます。
- ノードラベルを日本語で表示するためには、次の
japanize_matplotlibをインポートした上で、さらに日本語フォントを指定する必要があります。
# matplotlibを日本語表示に対応させるモジュール
!pip install japanize-matplotlib
import japanize_matplotlib
⑽ NetworkXによる可視化
- networkXでネットワーク図を描画する手順は、➀グラフ構造のオブジェクトを生成し、➁それにデータを読み込ませて、➂matplotlib上でノードやエッジ等の仕様を指定して描画、という3ステップです。
- くどいようですが
font_family = "IPAexGothic"が肝心で、font_familyに日本語フォントを指定することでノードラベルを日本語表示に対応させます。
# グラフオブジェクトの生成
G = nx.Graph()
# 重み付きデータの読み込み
G.add_weighted_edges_from(weighted_edges)
# ネットワーク図の描画
plt.figure(figsize=(10,10))
nx.draw_networkx(G,
node_shape = "s",
node_color = "c",
node_size = 500,
edge_color = "gray",
font_family = "IPAexGothic") # フォント指定
plt.show()
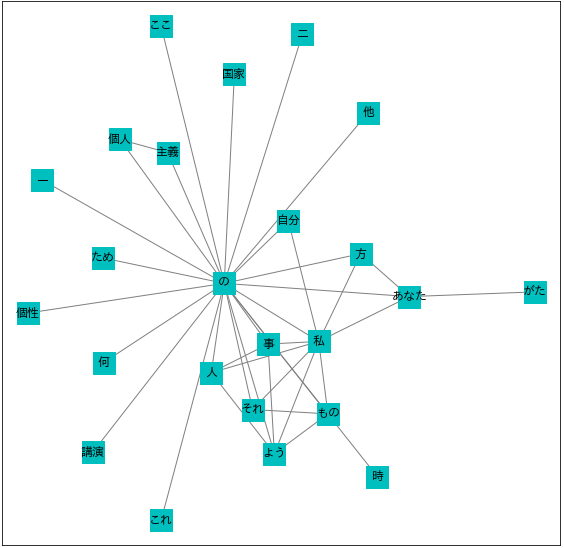
- 共起ネットワーク分析の仕組みを一つの大きな流れとして捉えるために、例えばストップワード(除外する語)の設定や熟語の処理(例えば「個人」と「主義」ではなく「個人主義」)等々、細部には目をつむりました。
- また、便宜上、次の4つの作業段階に分けて考えました。
➀テキストデータの準備、➁共起データの作成、➂作図用データの作成、➃ネットワーク図の描画、という4段階です。
けれど一般的には、➊前処理、➋解析、➌可視化という3段階で捉えるものと思います。 - 特に➊前処理は、自然言語処理の肝だと私は思っています。 実際スクリプト上では➋の一部に組み込まれたりもしますが、要するに「生のデータから必要な単語をどのように抽出するか」という問題です。 どういう分析視点を以て、どのような基準で単語を取り出すか。 それは直接的に解析結果に現れますし、 それにより解釈も左右されることになります。最も検討が必要で時間もエネルギーもかかる作業単位です。