- 自然言語処理には2つの手法があります。
- 統計情報から単語を表現する手法を「カウントベース」といい、ニューラルネットワークによる手法を「推論ベース」といいます。
- カウントベースの手法として、文字や単語の「連なり」の頻度分布N-gramをもとに文を生成するプログラムを考えます。
⑴ テキストデータの読み込み
from google.colab import files
uploaded = files.upload()

- ローカルからテキストファイルを選択してColaboratory上にアップロードします。
- アップロードしたテキストファイルを開いて変数に格納します。
- 今回はコーパスとして夏目漱石の『吾輩は猫である』の全文をつかいます。
- https://github.com/yumi-ito/sample_data/blob/master/Neko.txt
with open('Neko.txt', mode='rt', encoding='utf-8') as f:
read_text = f.read()
nekotxt = read_text
print(nekotxt)
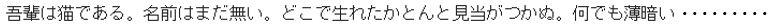
-
open()の引数は左から順にファイル名、mode='rt'はテキストモードの指定、encoding='utf-8'は文字コードです。左にwithをつけることで開いたファイルは、インデント内のコードが実行された後に自動的に閉じてくれます。
⑵ MeCabによる形態素解析
- MeCab(メカブ)はオープンソースの形態素解析エンジンで、2通りの使い方があります。
- 1つは、分かち書きを作る使い方で、英文と同じような処理にかけることができます。
- もう1つは、語ごとの読み・原形・品詞などの情報を取得するもので、たとえば名詞だけを取り出すといった使い方ができます。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
- 以上がMeCabのインストールになります。次いでインポートして全文を「分かち書き」に変換します。
-
MeCab.Tagger()というクラスに引数を-Owakatiとしてインスタンスを生成し、さらにparse()というメソッドを呼ぶことで結果が文字列として取得できます。
import MeCab
tagger = MeCab.Tagger("-Owakati")
nekotxt = tagger.parse(nekotxt)
print(nekotxt)
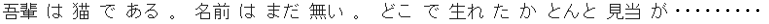
- さらに文字列を分割しますが、
split()で引数を省略すれば空白が区切り文字となります。
nekotxt = nekotxt.split()
print(nekotxt)

⑶ N-gram辞書の生成
from collections import Counter
import numpy as np
from numpy.random import *
- ここで、分割された単語の連なり
nekotxtを変数stringと置きます。 - 2単語すなわち2-gramの場合、
stringの先頭から終端の1つ前までのリストと、先頭の次の語から終端までのリストをzip()で1つにまとめてdoubleとします。 - 3-gramの場合は、
stringの先頭から終端の2つ前までのリストと、先頭の次の語から終端の1つ前までのリスト、先頭の次の次の語から終端までのリストを1つにまとめてtripleとします。 - その際、
filter()関数をつかって、変数delimiiterに定義された文字記号があれば除去します。
string = nekotxt
# 除外する文字記号
delimiter = ['「', '」', '…', ' ']
# 2語のリスト
double = list(zip(string[:-1], string[1:]))
double = filter((lambda x: not((x[0] in delimiter) or (x[1] in delimiter))), double)
# 3語のリスト
triple = list(zip(string[:-2], string[1:-1], string[2:]))
triple = filter((lambda x: not((x[0] in delimiter) or (x[1] in delimiter) or (x[2] in delimiter))), triple)
# 要素数をカウントして辞書を生成
dic2 = Counter(double)
dic3 = Counter(triple)
-
doubleは連続する2語を要素とし、またtripleは連続する3語を要素とするリストになっています。 -
Counter()で要素の出現頻度をカウントした結果が、2-gramはdic2、3-gramはdic3という頻度データすなわちN-gram辞書になります。 - N-gram辞書の中身を示します。
for u,v in dic2.items():
print(u, v)

for u,v in dic3.items():
print(u, v)

⑷ 文章生成メソッドの定義
- N-gram辞書にもとづいて**単語を次々に発生させて文章生成するメソッド
nextword**を定義します。 - つまり、連続する語の組ごとの出現頻度を「次に来る語」の確率と読み替えるわけです。
- 先頭の単語を与えて、次の語、その次の語と、頻度が高い単語を選ぶことをくり返して「。」などの終止符に行き着いたら生成をやめます。
def nextword(words, dic):
## ➀先頭の単語wordsの要素数gramsを取得
grams = len(words)
## ➁N-gram辞書dicから一致する要素を抽出
# 2語の場合
if grams == 2:
matcheditems = np.array(list(filter(
(lambda x: x[0][0] == words[1]), #1番目が合致
dic.items())))
# 3語の場合
else:
matcheditems = np.array(list(filter(
(lambda x: x[0][0] == words[1]) and (lambda x: x[0][1] == words[2]), #1番目と2番目が合致
dic.items())))
## ➂一致する語がない場合のエラーメッセージ
if(len(matcheditems) == 0):
print("No matched generator for", words[1])
return ''
## ➃重み付き出現頻度リスト
# matcheditemsから出現頻度を取得
probs = [row[1] for row in matcheditems]
# 0~1の疑似乱数を生成して出現頻度にかける
weightlist = rand(len(matcheditems)) * probs
## ➄matcheditemsから重み付き出現頻度が最大の要素を取得
if grams == 2:
u = matcheditems[np.argmax(weightlist)][0][1]
else:
u = matcheditems[np.argmax(weightlist)][0][2]
return u
-
➀第一引数の
wordsは先頭として任意に入力する単語です。その要素数が、2語か3語かによって第二引数のdic(dic2かdic3)が選ばれます。 -
➁2語の場合は先頭の語が一致するもの、3語の場合は先頭とその次の語が一致するものをそれぞれN-gram辞書から抽出し、変数
matcheditemsに格納します。 - ➂エラーメッセージで、一致する語がない場合に返します。
- **➃出現頻度に疑似乱数をかけた「重み付き出現頻度」**のリストを生成します。かりに、単に出現頻度が最大の要素をとると結果が固定して面白くないので、ノイズを与えることで変化をつけます。
-
➄一致した要素のリスト
matcheditemsから**「重み付き出現頻度」が最大の要素**を取得して返します。
⑸ 文章生成プログラムの実行
- ここでは、2単語(2-gram)を採用し、先頭の語を「吾輩」と入力します。
- なお、最終的に文章化された出力で
print()にオプション引数end=”を使うと、文字列を連結する際にできる空白(半角スペース)をなくしてくれます。
# 先頭の単語wordsを入力
words = ['', '吾輩'] # 2-gram
# words = ['', '我輩', 'は'] # 3-gram
# 出力outputの先頭にwordsを埋め込む
output = words[1:]
# 「次の語」を取得
for i in range(100):
# 2語の場合
if len(words) == 2:
newword = nextword(words, dic2)
# 3語の場合
else:
newword = nextword(words, dic3)
# 出力outputに次の語を追加
output.append(newword)
# 次の文字が終止符なら終了
if newword in ['', '。', '?', '!']:
break
# 次のnextwordの準備
words = output[-len(words):]
print(words)
# 出力outputを表示
for u in output:
print(u, end='')

- 2-gram辞書から次々に要素が抽出された過程を示します。

- このように、推論ベースの手法とは違って、N-gramはとても単純なものですが・・・
- 個人的な経験として、2008年(平成20年)のこと、 N-gramを用いた非常に興味深い研究報告に出会いました。
- 平安時代前期の勅撰和歌集『古今和歌集』をコーパスとして、N-gramによって男女それぞれの特有表現を抽出し、これをもとに『源氏物語』の中で登場人物たちが詠んだ和歌を検証するという取り組みです。
- 現代においても女性が男言葉を使うというのは珍しくありませんが、実は男言葉・女言葉の使いようで巧妙に人物造形がなされていたということが判明しました。例えば、男性特有の表現に乏しく男らしくない男性とか、 男性中心の社会規範を超えていく女性とか、およそ当時の読者にしか分からない面白みといえましょう。
- 要するに、コーパスに何を用いるのか、それで何を分析するのかというアイデア次第では、N-gramにもまだ大いにポテンシャルがあるのではないかと思っています。