- KWIC (keyword in context) は、あるキーワードが出てくる場所を取得するものですが、その前後の文脈を併せて取得してくれるという利点があります。
- つまり、そのキーワードがどのような文脈の中で使われているかを知ることで、定性的な解釈を深めるような用途に利用できます。
- KWIC は NLTK の
ConcordanceIndexクラスを利用して簡単に行えるもので、NLTK (Natural Language Toolkit) は、Pythonで自然言語処理を行うためのライブラリの一つです。
⑴ コーパスの取得
- ここでは 宮沢賢治の『銀河鉄道の夜』をコーパスとし、リソースとしてインターネットの電子図書館『青空文庫』を利用させていただきます。
❶ライブラリのインポート
import re # 正規表現の操作
import zipfile # zipファイルの操作
import urllib.request # Web上のデータを取得
import os.path # パス名の操作
import glob # ファイルパス名の取得
❷ファイルの取得、読み込み
- zipファイルを取得し、解凍して保存し、その保存したファイルのパスを取得するという一連のメソッドを定義します。
def download(URL):
# zipファイルのダウンロード
zip_file = re.split(r'/', URL)[-1]
urllib.request.urlretrieve(URL, zip_file)
dir = os.path.splitext(zip_file)[0]
# zipファイルの解凍と保存
with zipfile.ZipFile(zip_file) as zip_object:
zip_object.extractall(dir)
os.remove(zip_file)
# 保存したファイルのパスを取得
path = os.path.join(dir,'*.txt')
list = glob.glob(path)
return list[0]
- ファイルを読み込み、本文だけを抽出して、さらにノイズを除去するという一連のメソッドを定義します。
def convert(download_text):
# ファイル読み込み
data = open(download_text, 'rb').read()
text = data.decode('shift_jis')
# 本文の抽出
text = re.split(r'\-{5,}', text)[2]
text = re.split(r'底本:', text)[0]
text = re.split(r'[#改ページ]', text)[0]
# ノイズ削除
text = re.sub(r'《.+?》', '', text)
text = re.sub(r'[#.+?]', '', text)
text = re.sub(r'|', '', text)
text = re.sub(r'\r\n', '', text)
text = re.sub(r'\u3000', '', text)
text = re.sub(r'「', '', text)
text = re.sub(r'」', '', text)
text = re.sub(r'、', '', text)
text = re.sub(r'。', '', text)
return text
- 詳しくはこちら 3. Pythonによる自然言語処理 1-2. コーパスの作成方法 : 青空文庫にまとめてあります。
- URLを指定して、ファイルの取得から本文抽出までを実行します。当該作品の「図書カード:No.43737」中にある「ファイルのダウンロード」からリンクのアドレスをコピーします。
URL = 'https://www.aozora.gr.jp/cards/000081/files/43737_ruby_19028.zip'
download_file = download(URL)
text = convert(download_file)
print(text)
-
downloadメソッドに URL を指定してファイルを取り込み、それをconvertメソッドに渡して本文のみ抽出した結果は以下の通りです。

⑵ 形態素解析による分かち書き
- NLTK の
ConcordanceIndexクラスは英語の処理を前提としたものなので、日本語の文章を MeCab で分かち書きにして単語間が空白で区切られた形式に変換します。 - ちなみにconcordance は、主に「一致」という意味で用いられます。
❶MeCabのインストール
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
❷単語に分割
-
MeCab.Taggerクラスに分かち書き出力モード-Owakatiを指定してインスタンスを生成し、次いでparseメソッドにより単語で区切ります。
import MeCab
mecab = MeCab.Tagger("-Owakati")
words = mecab.parse(text).split()
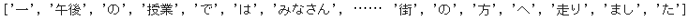
❸分かち書き
- さらに
joinを使って、半角スペースを区切り文字として単語を連結してやります。
doc = ' '.join(words)
print(doc)

⑶ KWICの実行
❶ nltk によるトークン化
- ここで
nltkをインポートしますが、併せてpunktというトークナイザをダウンロードしておかないと動作しません。 - 分かち書きされた
docを NLTK でトークン化して text フォーマットに変換します。
import nltk
nltk.download('punkt')
text_ = nltk.Text(nltk.word_tokenize(doc))
❷ KWIC 形式の出力
- 例として、キーワードを「ジョバンニ」と指定します。
-
ConcordanceIndexクラスに入力テキストをtext_と指定してインスタンスを生成し、キーワードにもとづいて KWIC 形式の出力を表示させます。
word = 'ジョバンニ'
# インスタンスを生成し、入力テキストを指定
c = nltk.text.ConcordanceIndex(text_)
# キーワードでKWIC形式を表示
c.print_concordance(word, width=40, lines=50)

- KWIC形式を表示させる
print_concordanceメソッドは、widthで表示の幅、linesで最大行数を指定できます。ここではマッチした 196 箇所をすべて表示させるようにしました。 - また次の
offsetsメソッドによって元のテキストにおけるキーワードの位置情報を取得できます。本来の用途である検索の結果がこちらになります。
print(c.offsets(word))
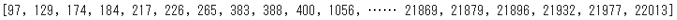
- 個人的には、コロケーションなどを行った後に、分析を深堀する目的で補完的に活用した経験があります。ただし、リサーチデータなどコーパスがあまり大きくなく、また重要な単語のいくつかがネガ・ポジの両側面をもっている場合でした。
- つまり簡易的に単語のネガポジ分析を行なったわけですが、次に、いわゆる感情分析(感情値の計算)の手法について見ていきたいと思います。