目的
・機械学習を行うためのシンプルな流れを理解する
・不動産価格の需要予測するため、機械学習の方法を学ぶ。
・短時間で、機械学習の処理の流れを理解する。
・アウトプットの目的もあり、コードはほぼ書籍と一緒。
分析の流れ
「実務で役立つ実践Python機械学習入門」翔泳社によると
以下のフェーズの大まかな流れになっていると紹介されています。
ウォーターフォールのような流れではないこともあるようです。
1. データ収集と前処理
2. 探索的データ分析
3. 特徴量エンジニアリング
4. アルゴリズムと評価指標の選定
5. モデル学習・評価
5のモデル学習・評価が終わったらそこで終わりではなく、
1や3、4に戻って繰り返して精度を改善していくことが
繰り返されます。
プログラムの説明
今回紹介されたコードに説明と実行結果を加えて行きたいと思います。
利用した開発環境はGoogleColaboratory。
利用するCSVファイルはGoogleDrive内に保存している。
以下のコードを実行してGoogleDriveとの接続を行う。
# GoogleDriveと接続する
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
# 変更しやすいように、パス名とファイル名の変数を分ける
folder_path = '/content/drive/MyDrive/Colab Notebooks/Training/実務で役立つPython機械学習入門/2_2'
train_file_name = 'realestate_train.csv'
train_file_path = folder_path + '/'+ train_file_name
train_df = pd.read_csv(train_file_path)
# データの中身(上から5行分)確認する。
train_df.head()
■実行結果

このときにデータの特徴など理解するため、平均、データ数、欠損値など調べるが、今回大まかな流れを理解することが目的なので、省略します。
今回不動産価格の予測に、
rent_price:賃貸価格
house_area:部屋の広さ(m^2)
distance:駅からの距離(m)
を利用します。
機械学習モデルの学習
価格の予測なので、回帰アルゴリズムを利用します。
利用するアルゴリズムは
sklearnライブラリにある、Ridge Regressionを利用します。
モデルライブラリを読み込む
#Ridge Regression model
from sklearn.linear_model import Ridge
学習に使う、特徴量と正解データを分けて設定する
#特徴量と正解データのカラム名の設定
#正解データの特徴量
target_col = ['rent_price']
#学習に使う、特徴量
feature_cols =['house_area','distance']
# モデル学習用のデータの設定「X:学習データ」「y:正解データ」
X = df[feature_cols]
y = df[target_col]
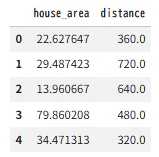
■X,yの中身を確認する。
X.head()
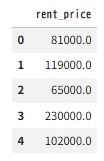
y.head()
モデルの学習
#モデルの初期化(インスタンス化)
model = Ridge()
#モデルの学習
model.fit(X,y)
モデルの学習前後
Google Colaboratoryの場合、
学習前後がわかるようになっているようです。
■学習前

■学習後

機械学習モデルの評価
#学習したモデルを用いて学習を行う。
train_df["pred_rent_price"] = model.predict(X)
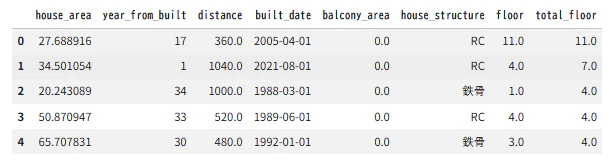
train_dfのデータを確認する。
train_df.head()
■実行結果

最後の列だった、total_flore列の右側に、pred_rent_priceが加わり、予測されたデータが加えられている。
正解データと予想データが遠いので、2つに絞って比較する。
train_df[['rent_price','pred_rent_price']].head()
■実行結果
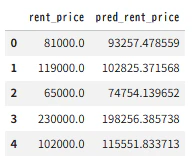
インデックス0の正解データは、
81000円、
予想データは、
93257円
と出ました。
評価指標を使って計算する
今回は評価指標として、MAE(Mean Absolute Error:平均絶対値誤差)します。
MAEはそれぞれの正解の値と、予測された値の差の絶対値の合計を平均した値です。
from sklearn.metrics import mean_absolute_error
# MAEを計算する
mae = mean_absolute_error(train_df['rent_price'],train_df['pred_rent_price'])
#小数点以下2位まで表示
print(f"{mae:.2f}")
機械学習モデルを使った予測
次は、家賃の入っていないデータに対して予測を行います。
pred_file_name = 'realestate_pred.csv'
pred_file_path = folder_path + '/'+ pred_file_name
df_pred = pd.read_csv(pred_file_path)
df_pred.head()
■実行結果
実行結果を見ると、rent_priceの列が入っていないことが確認できます。
df_predの変数の中から、予測に使うデータを選び、予測を行います。
#使う特徴量を指定する
pred_feature_cols =['house_area','distance']
X_pred = df_pred[pred_feature_cols]
#学習済みのmodelを使って、予測をしたいX_predのデータの予測をする
df_pred['pred_rent_price'] = model.predict(X_pred)
#実行結果を表示する
df_pred.head()
■実行結果
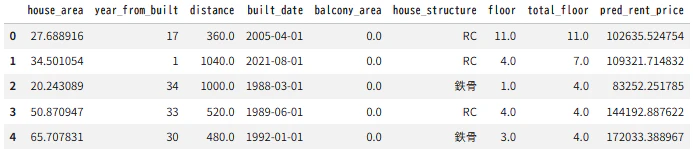
一番右の列にpred_rent_priceの列ができ、予測された数字が表示されました。
参考
■実務で役立つPython機械学習入門
https://amzn.to/4tHQ3J5
■「実務で役立つPython機械学習入門 課題解決のためのデータ分析の基礎」サンプルコード
https://github.com/ml-pg-book/python-business-ml-starter