macOSアプリで、動画の音声を文字起こしして、その結果を翻訳する機能を実装しました。
この記事では、次の2点に絞って書きます。
-
SpeechAnalyzerでタイムスタンプ付きの文字起こしSegmentを作る -
Translation frameworkでSegment単位に翻訳し、元のタイムスタンプを維持する
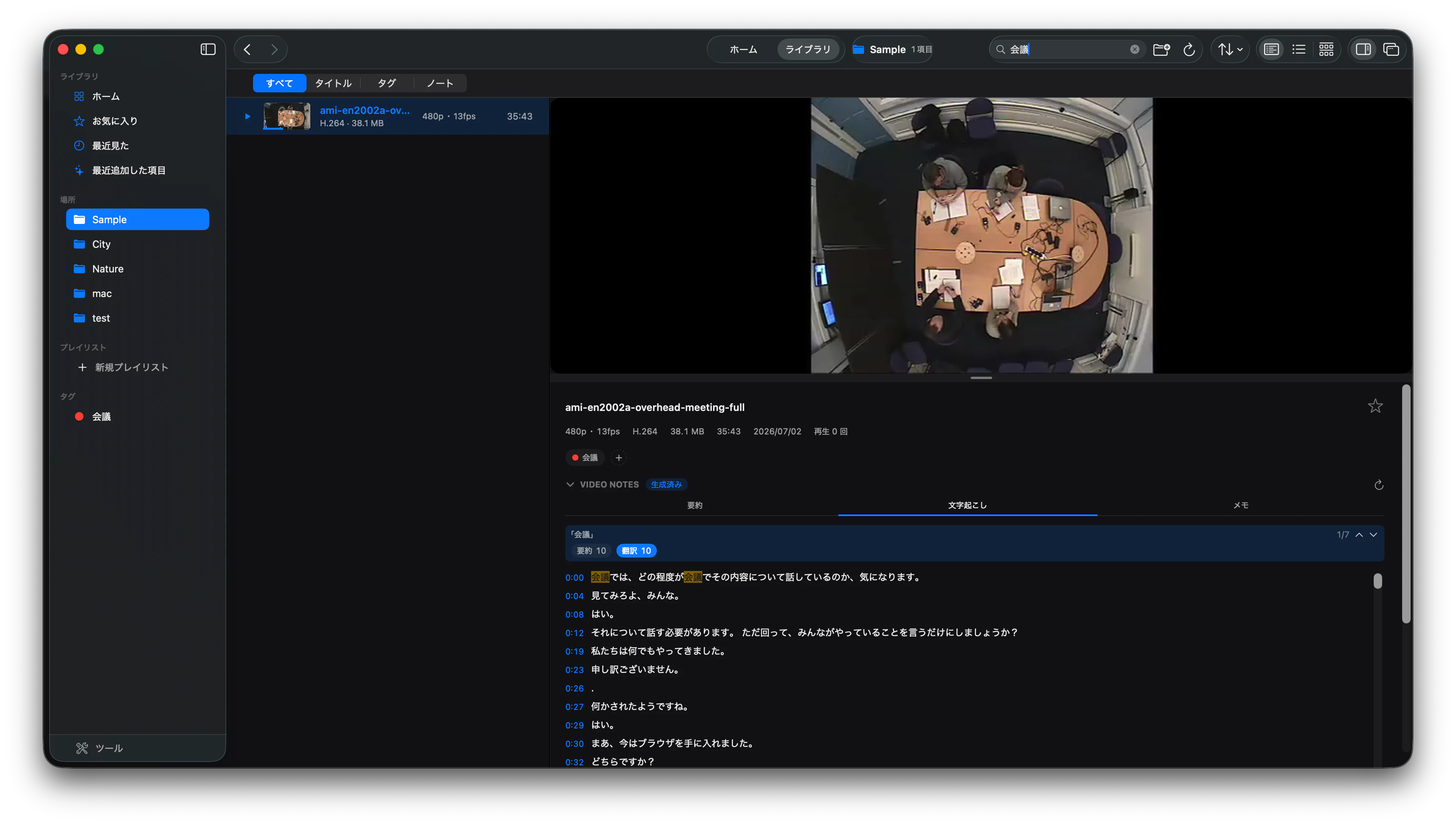
単に全文テキストを翻訳するのではなく、
struct Segment: Codable, Sendable, Equatable, Identifiable {
var id = UUID()
var time: TimeInterval
var text: String
}
のような形で、動画の位置へ戻れるデータとして扱うのが目的です。
前提
音声はあらかじめWAVにしてあります。
自分のアプリでは、動画を libmpv で開いて16kHz mono WAVを書き出し、そのWAVを SpeechAnalyzer に渡しています。
この記事ではWAVがある前提で、文字起こし以降だけを扱います。
let wav: URL = ...
let locale = Locale(identifier: "ja-JP")
let transcript = await SpeechPipeline.transcribe(wav, locale: locale)
SpeechAnalyzerでタイムスタンプを取る
SpeechTranscriber を作るとき、attributeOptions に .audioTimeRange を指定します。
let transcriber = SpeechTranscriber(
locale: locale,
transcriptionOptions: [],
reportingOptions: [],
attributeOptions: [.audioTimeRange]
)
これを入れておくと、結果の AttributedString のrunから音声内の時間範囲を取り出せます。
初回は音声認識アセットを用意する
指定したlocaleの認識アセットが未インストールの場合があります。
if let request = try await AssetInventory
.assetInstallationRequest(supporting: [transcriber]) {
try await request.downloadAndInstall()
}
ここは時間がかかる可能性があるので、UIでは「準備中」や「文字起こし中」として扱える状態を持っておくとよいです。
WAVを解析する
実装は次のようにしました。
import AVFoundation
import Speech
enum SpeechPipeline {
static func transcribe(_ wav: URL, locale: Locale) async -> [Segment] {
do {
let transcriber = SpeechTranscriber(
locale: locale,
transcriptionOptions: [],
reportingOptions: [],
attributeOptions: [.audioTimeRange]
)
if let request = try await AssetInventory
.assetInstallationRequest(supporting: [transcriber]) {
try await request.downloadAndInstall()
}
let analyzer = SpeechAnalyzer(modules: [transcriber])
let audioFile = try AVAudioFile(forReading: wav)
let collector = Task { () -> [Segment] in
var segments: [Segment] = []
for try await result in transcriber.results {
let text = String(result.text.characters)
.trimmingCharacters(in: .whitespacesAndNewlines)
guard !text.isEmpty else { continue }
segments.append(.init(
time: startTime(of: result.text),
text: text
))
}
return segments
}
if let lastSample = try await analyzer.analyzeSequence(from: audioFile) {
try await analyzer.finalizeAndFinish(through: lastSample)
} else {
await analyzer.cancelAndFinishNow()
}
return try await collector.value
} catch {
return []
}
}
private static func startTime(of text: AttributedString) -> TimeInterval {
for run in text.runs {
if let range = run.audioTimeRange {
return range.start.seconds
}
}
return 0
}
}
transcriber.results は非同期に流れてくるので、analyzeSequence を走らせながら別Taskで結果を集めています。
この結果、次のような配列を作れます。
[
Segment(time: 4.2, text: "今日はこの実装について話します"),
Segment(time: 17.8, text: "次に翻訳処理を見ます")
]
UI側では、各行をクリックしたら time にシークできます。
翻訳はTranslationSessionを直接newしない
翻訳で少し設計が変わるのは、TranslationSession をサービスクラスで直接作るのではなく、SwiftUIの .translationTask から受け取る点です。
そのため、Modelは「翻訳したい」という設定を作り、Viewが実際のsessionを受け取ってModelに戻す形にしました。
import Translation
@MainActor
@Observable
final class NotesModel {
var translationConfig: TranslationSession.Configuration?
private(set) var translatingID: UUID?
private(set) var translationFailedID: UUID?
private var translationSource: [Segment] = []
private var translationInFlight = false
private var translationPair: String?
func translate(id: UUID, notes: Notes) {
guard !notes.transcript.isEmpty,
notes.translation.isEmpty else {
return
}
translatingID = id
translationFailedID = nil
translationSource = notes.transcript
let src = notes.transcribeLanguage == "ja" ? "ja" : "en"
let dst = src == "ja" ? "en" : "ja"
let pair = "\(src)>\(dst)"
if translationConfig != nil && pair == translationPair {
translationConfig?.invalidate()
} else {
translationConfig = TranslationSession.Configuration(
source: Locale.Language(identifier: src),
target: Locale.Language(identifier: dst)
)
}
translationPair = pair
}
}
同じ言語ペアでも再翻訳したいことがあるので、既存の translationConfig が同じpairなら invalidate() しています。
逆に、言語ペアが変わった場合は新しい TranslationSession.Configuration を作ります。ここを使い回すと、別の動画で翻訳方向が古いままになることがあります。
View側でtranslationTaskを持つ
View側は次のようにします。
struct NotesPanel: View {
let model: NotesModel
var body: some View {
content
.translationTask(model.translationConfig) { session in
await model.performTranslation(using: session)
}
}
}
Model側では、渡された TranslationSession で翻訳を実行します。
@MainActor
extension NotesModel {
func performTranslation(using session: TranslationSession) async {
guard let id = translatingID,
!translationInFlight else {
return
}
translationInFlight = true
defer {
translationInFlight = false
translatingID = nil
}
let segments = translationSource
do {
try await session.prepareTranslation()
let requests = segments.enumerated().map {
TranslationSession.Request(
sourceText: $0.element.text,
clientIdentifier: String($0.offset)
)
}
let responses = try await session.translations(from: requests)
let translated = zip(segments, responses).map {
Segment(time: $0.time, text: $1.targetText)
}
guard !translated.isEmpty else {
translationFailedID = id
return
}
// cache[id]?.translation = translated
translationFailedID = nil
} catch {
translationFailedID = id
}
}
}
ここで重要なのは、翻訳後も元の time を残すことです。
Segment(time: original.time, text: translatedText)
としておけば、翻訳表示に切り替えても、クリックした行から同じ動画位置へ戻れます。
複数のtranslationTaskが走るケース
同じModelを複数のViewから見せる構成では、.translationTask が複数箇所で発火することがあります。
自分の実装では、インスペクタ内のパネルと別ウィンドウのパネルが同じModelを見る可能性があったため、translationInFlight を持たせて二重実行を止めています。
guard let id = translatingID,
!translationInFlight else {
return
}
translationInFlight = true
このフラグは最初の await より前に立てています。そうしないと、2つの .translationTask がほぼ同時に入ったときに両方が通る可能性があります。
翻訳アセットの準備
session.prepareTranslation() を明示的に呼んでいます。
try await session.prepareTranslation()
これを入れずに翻訳を始めると、必要な言語アセットがない環境で失敗し、UI上は単に翻訳が空のままに見えます。
失敗時は translationFailedID のような状態を持って、ユーザーに「翻訳できなかった」ことを出せるようにしています。
まとめ
動画や音声の文字起こし結果をアプリ内で使うなら、全文文字列ではなくSegment配列にしておくと扱いやすいです。
struct Segment {
var time: TimeInterval
var text: String
}
実装上のポイントは次の通りです。
-
SpeechTranscriberに.audioTimeRangeを指定する -
AttributedStringのrunから開始時刻を取り出す - 翻訳は
.translationTaskからTranslationSessionを受け取る - 翻訳後も元のSegmentの
timeを維持する - 同じModelを複数Viewで使うなら二重実行を防ぐ
この形にすると、文字起こし表示と翻訳表示のどちらでも、行クリックで動画へシークできるUIを作れます。
関連記事: