ユースケース別 LLMベンチマーク読解ガイド — 何をやりたいかで見るべき数字が変わる
自分用メモとして書きました。海外LLMコミュニティの議論を調べて、「結局どのベンチマークを見ればいいの?」という疑問にユースケース別で答えをまとめたもの。
1. ベンチマークの大原則 — 数字の裏を読め
全てのベンチマークにはバイアスがある。信じすぎず、自分のタスクで検証すること。
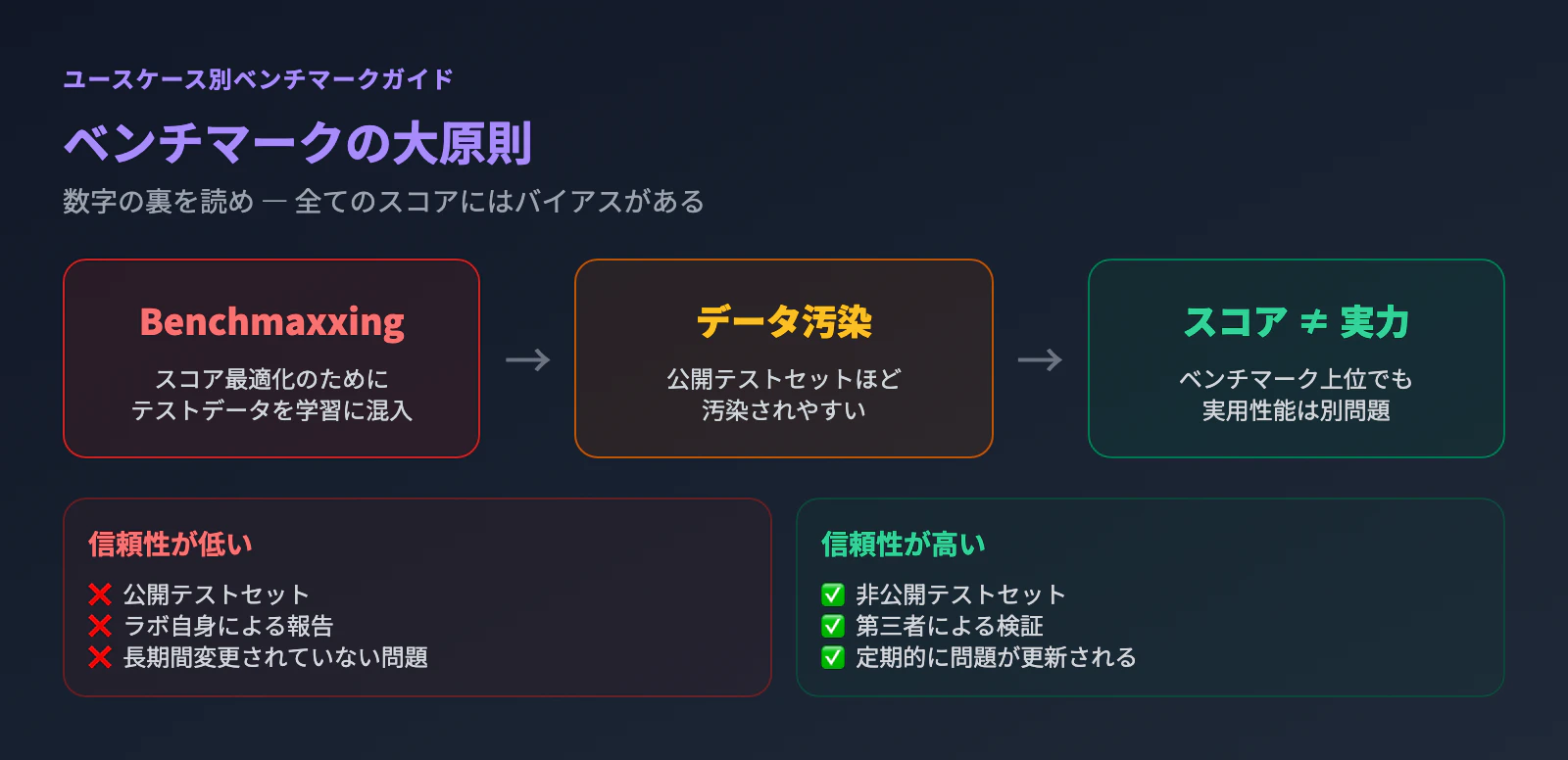
ベンチマークスコアは鵜呑みにできない。海外LLMコミュニティでは「bench score ≠ real world quality」がほぼ共通認識になっている。AIラボがスコア最適化のためにベンチマークデータを学習に組み込む「Benchmaxxing」は常態化しており、公開テストセットほど汚染されやすい。
非公開ベンチマーク(ARC-AGI、SimpleBenchなど)は、問題がリークしにくい分だけゲーミング耐性(攻略されづらさ)が高い。しかし、それでも完璧ではない。結局のところ、最も信頼できるベンチマークは「自分のユースケースで実際に試すこと」だ。本記事では、用途ごとに「何を見ればいいのか」を整理した。
2. コーディング — SWE-bench / LiveCodeBench / Aider Benchmark
コーディング用途ならSWE-rebenchとAider Benchmarkを見る。SWE-bench Verifiedはデータ漏洩で信頼低下。
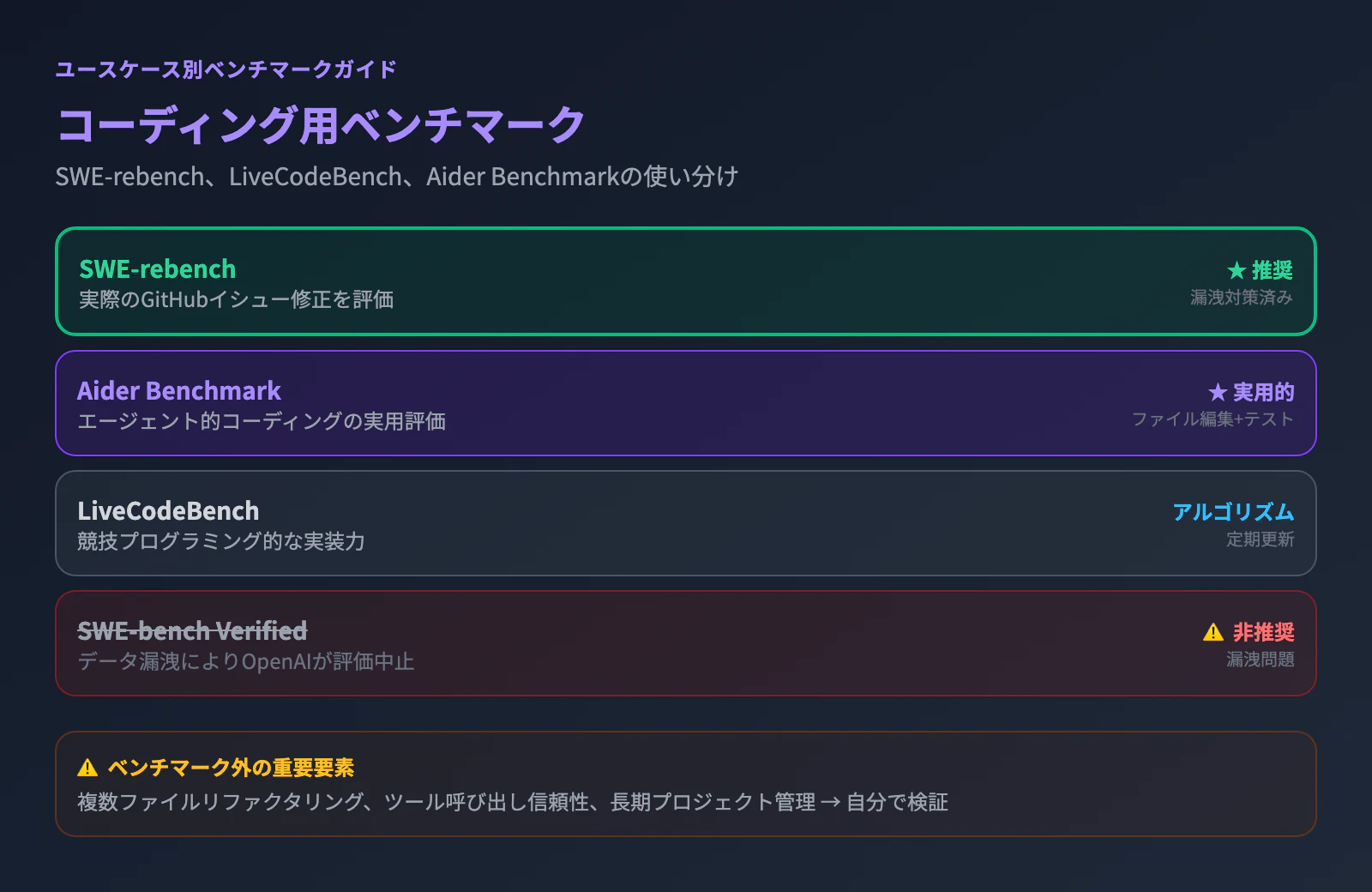
コーディング能力のベンチマークは最も充実している分野だが、それでも注意点は多い。SWE-bench VerifiedはGitHub上の実際のイシュー修正を評価する定番だったが、テストデータの漏洩問題が発覚し、OpenAIが評価を中止した経緯がある。後継のSWE-rebenchは漏洩対策を強化しており、現時点ではより信頼性が高い。
LiveCodeBenchは競技プログラミング的な問題を出題するベンチマークで、アルゴリズム的な実装力を測る。一方、Aider Benchmarkはエージェント的なコーディング(ファイル編集、テスト実行、エラー修正のループ)を評価するため、実用性に近い。
ただし、これらのベンチマークにも共通する限界がある。複数ファイルにまたがるリファクタリング、長期的なプロジェクト管理、そしてツール呼び出しの信頼性はどれも測定対象に含まれていない。特にツール呼び出し(function calling)の安定性は、エージェント的なコーディングで最も重要な要素の一つだが、標準ベンチマークではテストされない。これは自分で検証するしかない。
3. 日本語タスク — 日本語を使うなら最も重要、かつ最も不足
日本語性能の信頼できるベンチマークはほとんど存在しない。自分で試すしかない現実。

大半のベンチマークは英語のみで構成されており、日本語性能を正確に測れるものは極めて少ない。JGLUE(日本語版GLUE)やJMMLE(日本語版MMLU)は存在するが、モデルリリース時にスコアが報告されることは稀だ。多言語ベンチマークのMGSM-jaもあるものの、カバー範囲は薄い。
海外LLMコミュニティのコンセンサスとして、英語ベンチマークのスコアと日本語性能は相関しないことが多い。英語のMMLUで高スコアを叩き出しているモデルが、日本語では壊滅的な品質になるケースは珍しくない。モデル系統別に見ると、QwenとGemmaは日本語でも比較的良好な性能を示す傾向がある一方、Llamaは英語と日本語の性能差が大きい。
最も確実なアプローチは、自分が実際に使う日本語プロンプトでテストすることだ。5~10個の定型プロンプトを用意して候補モデルを横並びで比較するのが現実的だ。
4. ロールプレイ・クリエイティブライティング — 数字では測れない世界
RP/創作の品質はベンチマークで測れない。コミュニティの「体感」と検閲の有無が全て。

ロールプレイや創作ライティングの品質を客観的に測定できるベンチマークは、実質的に存在しない。ライティング系ベンチマークは「90% personal taste」(90%は個人の好み)であり、数値化が本質的に困難な領域だ。
この用途で最も重要なのは、検閲(セーフティフィルタ)の有無だ。どれだけベンチマークスコアが高くても、強力なフィルタリングが掛かっているモデルではロールプレイはまともに機能しない。コミュニティでは、体感レポート、SillyTavernコミュニティでのテスト結果、口コミが最も信頼される情報源になっている。
評価のポイントとして挙がるのは、キャラクターの一貫性、設定への忠実さ、文章の品質(語彙の豊かさ、描写の細かさ)、そしてダークな・成熟したテーマに対する追従性だ。結果として、ローカルで動かすアンセンサードモデルやファインチューンモデルがこの用途では支配的になっている。
5. 推論・数学 — AIME / GPQA / FrontierMath
推論力を見るならAIME(数学)とGPQA(科学)。Thinkingモデルで大きく差が出る領域。

推論能力の評価は、ベンチマークが最も有効に機能する分野の一つだ。AIME(アメリカ数学招待試験)は数学的推論力を測る定番で、GPQA(大学院レベルの科学問題)は科学的推論力を評価する。FrontierMathは最先端の数学問題で構成されており、現在のモデルにとっても困難な課題が多い。
Thinkingモデル(o3、Claudeのextended thinking、Qwenのthinkingモード)は、この領域で劇的な改善を示す。非Thinkingモデルとの差が最も顕著に出るカテゴリだ。
注意点として、推論ベンチマークにも誤差がある。FrontierMathについてはEpochの推定で約7%のエラー率が報告されている。一方で、IMOなどの数学オリンピックは数千人の参加者によって検証されるため、最も信頼性の高いベンチマークの一つとされている。
解答に明確な正誤があり、ゲーミングが困難で、大規模な検証を経るという条件が揃っているためだ。
6. 知識・事実性 — MMLU / SimpleQA / Omniscience Index
知識量ならMMLU、事実への忠実さならSimpleQA。「知ってるけど嘘をつく」問題に注意。

MMLUは知識の幅広さを測る最も有名なベンチマークだが、ゲーミングが進んでいるため信頼性は低下している。SimpleQA(OpenAI開発)は事実の正確さ、特に「知らないときに知らないと認める能力」を測定する。Omniscience Indexは知識量と誠実さの両方を評価する。
ここで重要なのは、知識量と事実性は別物だということだ。大量の知識を持つモデルが、確信のない領域でもっともらしい嘘をつくパターンは実際に観測されている。「知識は豊富だが、知らないことを知らないと言えない」というのは、実用上の大きなリスクだ。
モデル選びの観点では、SimpleQAの精度(正答率だけでなく「分からない」と回答する率も含む)が実用的な指標になる。知識量だけを見てMMLUの高スコアモデルを選ぶと、ハルシネーションの多さに悩まされる可能性がある。
7. 長文コンテキスト — RULER / Needle-in-Haystack / 実用テスト
公称コンテキスト長と実効コンテキスト長は別物。RULER系テストで実力がわかる。

モデルが128Kや1Mのコンテキスト長を宣伝していても、実際にその全範囲で高い精度を維持できるとは限らない。公称値と実効値のギャップは、この分野の最大の罠だ。
Needle-in-a-Haystack(干し草の中の針)テストは、長いテキストの中に埋め込まれた特定の情報を検索できるかを測る基本的なテストだ。RULERはより複雑で、長文コンテキストにまたがる推論能力を評価する。
Geminiはこの領域で伝統的に強いとされるが、ベンチマークスコアと実際の使用感が乖離するケースも報告されている。長文コンテキストが最も重要になるユースケースはRAG、ドキュメント分析、エージェント的なコーディング(大量のファイルを参照しながら作業する場面)だ。
実用的には、自分が実際に処理したい長さのドキュメントで試すのが最も確実だ。特に、コンテキストの「中盤」に配置された情報を拾えるかどうかは、モデルによって大きく差が出る。
8. マルチモーダル(画像理解) — 見えるけど「わかる」とは限らない
画像認識ベンチマークは多いが、実用的な理解力とは乖離がある。
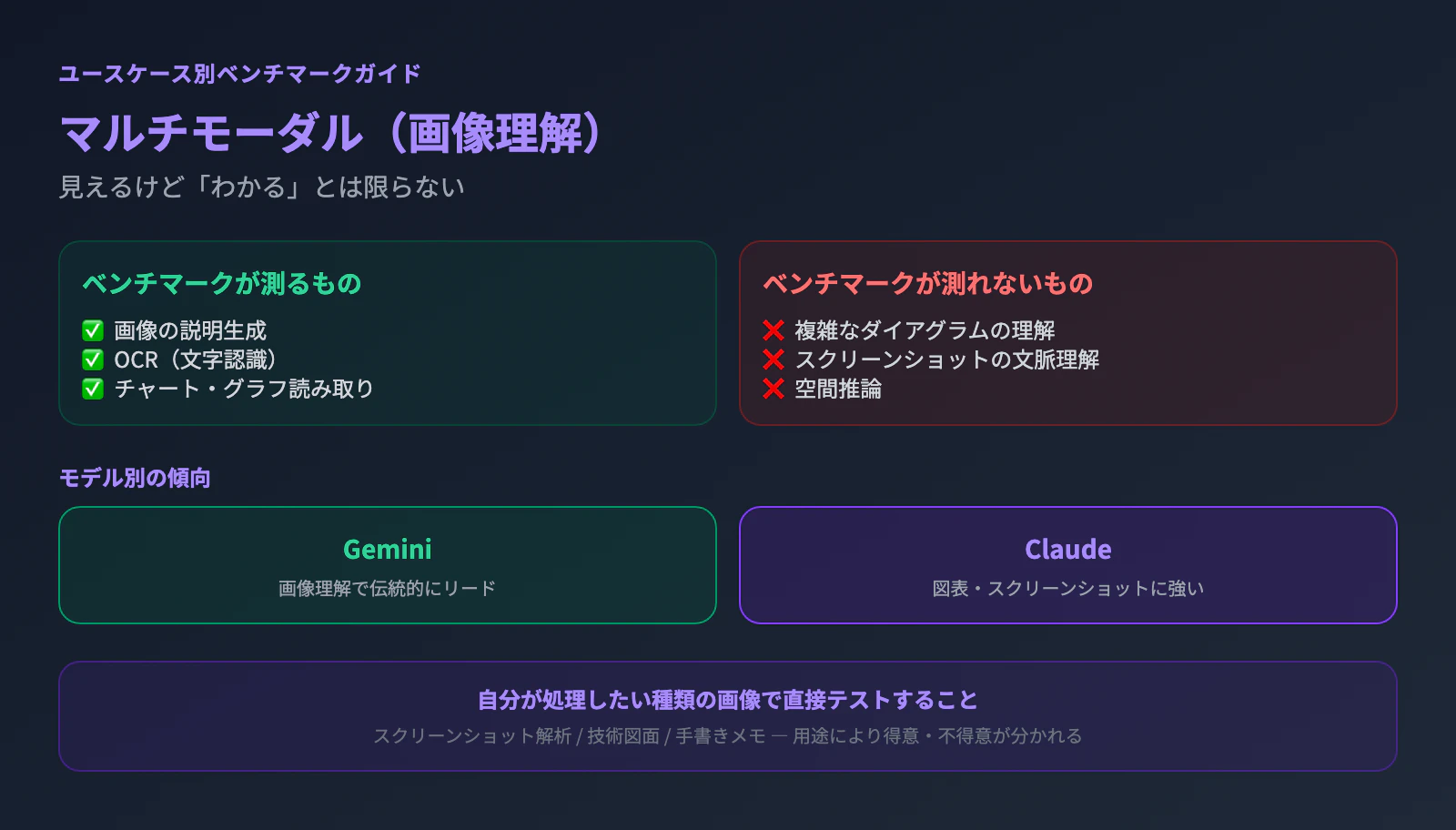
画像理解のベンチマークは、画像の説明生成、OCR、チャート読み取りなど多数存在する。しかし、実用的なマルチモーダル使用(複雑なダイアグラムの読み取り、スクリーンショットの理解、空間推論)は、ベンチマークでは十分に測定されていない。
GeminiとClaudeがこの領域ではリードしている傾向があるが、画像の種類によって得意・不得意が分かれる。たとえば、OCRは得意でも回路図の理解は苦手、というパターンがある。
実用的なアドバイスとしては、自分が処理したい種類の画像で直接テストすること。ベンチマークの「画像理解スコア」が高くても、自分のユースケースの画像タイプに対応しているとは限らない。スクリーンショット解析、技術図面の読み取り、手書きメモの解読など、用途に応じたテストが不可欠だ。
9. エージェント・ツール使用 — 最も測りにくい、最も重要
エージェント性能のベンチマークは未成熟。Tool callingの信頼性は自分で検証するしかない。
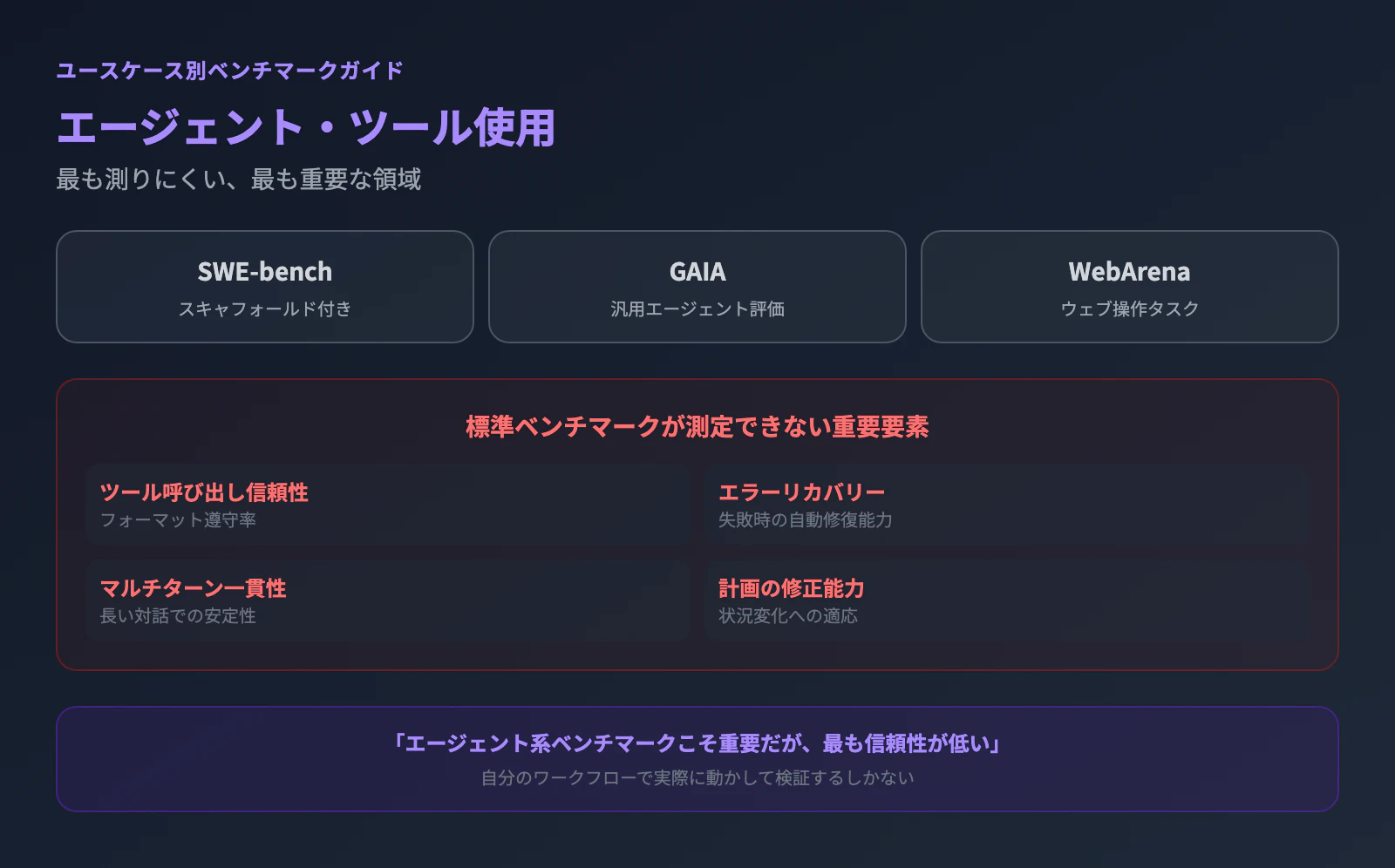
エージェント系ベンチマーク(SWE-bench with scaffolding、GAIA、WebArena)は存在するが、実際のエージェントワークフローを十分に捉えていない。海外LLMコミュニティでは「Agentic benchmarks are those that matter」(エージェント系ベンチマークこそが重要)という声がある一方で、「最も信頼性が低いベンチマークでもある」という矛盾した状況だ。
最大の問題は、ツール呼び出し(tool calling)の信頼性を測る標準ベンチマークが存在しないことだ。実際のエージェント運用では、関数呼び出しのフォーマット遵守率、エラー時のリカバリー能力、マルチターンでの一貫性、計画の修正能力が最も重要だが、これらはどのベンチマークでもテストされていない。
この領域は、完全に「自分で検証するしかない」フェーズにある。エージェントフレームワーク(LangChain、CrewAI、Claude Codeなど)で実際にタスクを実行させて、成功率とエラーパターンを確認するのが唯一の確実な方法だ。
10. 新モデル発表時のチェックリスト — これだけ見ればいい
新モデルが出たら、このチェックリストで自分の用途に合うか5分で判断できる。
新モデルが発表されたとき、全てのベンチマークを追いかける必要はない。自分の用途に応じて以下のポイントだけ確認すればいい。
- コーディング: SWE-rebenchスコア、Aiderリーダーボードの順位
- 日本語: 自分のプロンプトでテスト(信頼できるベンチマークなし)
- RP/創作: アンセンサードかどうか、コミュニティの初期レポート
- 推論: AIMEスコア、GPQAスコア
- 知識: SimpleQAの精度
- 長文コンテキスト: RULERスコア、公称値 vs 実効値
- マルチモーダル: 自分の画像で試す
- エージェント: ツール呼び出し信頼性テスト(手動)
- サイズ/速度: VRAM要件、自分のハードウェアでのtokens/sec
ベンチマークは「足切り」として使い、最終判断は自分のタスクでの体感で行う。