こんにちは!
株式会社ブレインパッド プロダクトユニット、新卒2年目の @y-tsukasa です!
業務では、主力プロダクトである「Rtoaster」の開発および運用・保守を担当しています。
また、データ活用におけるPoCやMVP開発など、新規価値創出のフェーズにも携わらせていただいてます!
はじめに
近年では、LLMをアプリケーションとして組み込むためのフレームワークが充実してきました。(e.g. LangChain, Genkit)
それにより、簡単に非構造化データを扱えるようになりました。
ですが、LLMを組み込む上では色々な心配事が付き纏います。
それは、例えば以下のような形で現れます。
- LLMが結果を生成中にインターネットへの接続が失われたら?
- レートリミットに引っ掛かったら?
- APIキーの期限が切れていたら?
- 望む形式で生成結果を得られなかったら?
- どうやってテストする?
- モデルを変えたくなったら?
こういった悩みは開発者への負担だけではなく、UXの悪化を招きサービスの品質にまで関わる問題へと直結します。
一見良さそうなコード
例として、以下のようなOpenAIにオヤジギャグを生成させるコードを考えましょう。
async function generateJoke() {
const res = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: { Authorization: `Bearer ${process.env.OPENAI_API_KEY}` },
body: JSON.stringify({
model: "gpt-4o",
messages: [{ role: "user", content: "オヤジギャグを教えて" }],
}),
});
return (await res.json()).choices[0].message.content;
}
console.log(await generateJoke());
一見、シンプルで読みやすく(≒読み慣れた)問題のないコードに見えるかもしれません。
ですが、次に示すような問題が隠れています。
async function generateDadJoke() {
// 404(Not Found)でも、429(Too Many Requests)でもそれを捕捉しない
const res = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: { Authorization: `Bearer ${process.env.OPENAI_API_KEY}` },
body: JSON.stringify({
model: "gpt-4o", // modelを変えたくなったら、エンドポイントも変えなければいけない
messages: [{ role: "user", content: "オヤジギャグを教えて" }],
}),
});
// モデルが返す形式が間違っていたり、変わると実行時エラー
return (await res.json()).choices[0].message.content;
}
なぜこうなるのか?
このような問題が起きてしまう理由は、LLM呼び出しという慎重に扱うべき操作を普通の関数のように扱ってしまっていることです。(同じ5行のコードが全く違って見える12の瞬間、なぜ私たちは学ぶのか?)
ネットワーク通信、環境変数、レートリミット、....
これらは全て 副作用 です。しかし上記コードはそれらを何も宣言していません。
熟練のエンジニアであれば、あらゆる例外へのフォールバック・対策を考えた最強のプログラムを書き上げることができるでしょう。
しかし、これはおかしな話だと思いませんか?
なぜ、プログラム(を解釈する系)はこれを問題として教えてくれないのでしょうか?
本来やりたいこと
今、やりたいことをそのまま書き下してみましょう。
それは、 「LLMにプロンプトを与えて、その結果を指定した形式で欲しい」 だけではないでしょうか?
その処理そのものに、HTTP通信の問題やモデルの選択などを考慮しなければいけないというのは、なんともナンセンスです。
詰まるところ、以下のようになって欲しいところです。
const generateDadJokeProgram = () => {
// fetcherは意識したくない
// モデルも考えていない
const response = LLM.generate({
prompt: "オヤジギャグを考えてください",
// 構造はこれで欲しい
schema: {
joke: string, // ジョーク本文
explanation: string, // ジョークの説明
},
});
return response; // { joke: "布団が吹っ飛んだ", explanation: "..."}
};
そして、この処理をする上で起きうる問題への対処は別の階層(Layer)に任せたいのです。
「Effect」
上記の問題を解決するのが Effect というエコシステムです。
今回はEffectとそのAI統合パッケージ Effect AI を実際に使ってみて、堅牢かつ型安全なLLM呼び出しをしてみました。
Effect AI (@effect/ai) は2025年12月12日時点ではα版なので仕様が変更されている可能性があります。
Effectとは?
Effectそのものについての詳細は公式ドキュメントを読んでいただくのが最も正確ですが、基本的な概念について簡単に説明してみようと思います。
Effect
EffectはEffectエコシステムの根幹を成すもので、端的には以下のように表されます。
// ┌─── Effectが"成功"した時にSuccess型の値を得る
// │ ┌─── Effectが"失敗"するとError型の値を得る
// │ │ ┌─── Effectの実行に必要な依存(Requirements)
// ▼ ▼ ▼
Effect<Success, Error, Requirements>
Success, Error, Requirementsにはそれぞれnever型を割り当てることができ、それぞれ以下のような意味を持ちます。
| パラメータ | 意味 |
|---|---|
| Success | このEffectが永久的に実行され続けることを意味します |
| Error | このEffectが失敗しないことを意味します |
| Requirements | このEffectにはいかなる必要な依存がないことを意味します |
例えば、数値の加算を行うプログラムのEffectは以下のようになります。※このような純粋な計算にEffectを使う理由はあまりないですが、説明用です
const addProgram: (a: number, b: number) => Effect<number, never, never> =>
Effect.succeed(a + b)
Effect.succeedは必ず成功するEffectを作れるヘルパーです。
必ず失敗させるEffect.failもあります。
重要なのは、このEffectそれ自体は何らかの処理を実行するものではない、というところです。
Effectは一連の処理フロー・相互作用を記述しただけのものです。
EffectランタイムにEffectを渡すことで初めて実行することができます。
// runSyncは同期処理用のEffectランタイム
Effect.runSync(Effect.succeed(console.log("Hello, World!")));
// runPromiseは非同期処理用のEffectランタイム (Promiseを返す)
Effect.runPromise(addProgram(1, 2)).then(console.log);
ServiceとLayer
ここまで読んだ方は「では、依存についてはどうするの?」という気持ちになっていることでしょう。
現代のアプリケーションでは、何らかの依存(Requirements)が必要になっているのが普通です。
例えば、
- HTTPクライアント
- DB接続
- ロガー
- 環境変数
などが相当しますね。
Service
Effectでは、これをServiceとLayerという仕組みで解決します。
例として、ロガーのServiceを作ってみましょう。
class Logger extends Context.Tag("Logger")<
Logger,
// Loggerでは "log" という能力を提供するだけ (実装は知らない)
{ log: (msg: string) => Effect.Effect<void, never, never> }
>() {}
(Context.TagはServiceに一意な識別子を付与するものです)
これだけでは、まだ実装は存在していません。
ここに具体的な実装を与えるのがLayerです。
Layer
先ほど作ったServiceに具体的な実装を与えてみましょう。
logの実装にはシンプルにconsole.logを使うことにしましょう。
const LiveLogger = Layer.succeed(Logger, {
log: (msg: string) => Effect.succeed(console.log(msg)),
});
LayerはServiceに実装を与えた部品のようなイメージです。
EffectでLoggerを使う
そして、Loggerを使ったEffectを書いてみましょう
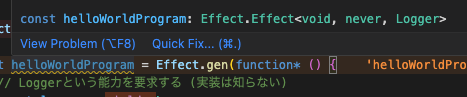
const helloWorldProgram = Effect.gen(function* () {
// Loggerという能力を要求する (実装は知らない)
const logger = yield* Logger;
yield* logger.log("Hello from Layer!");
});
Effect.gen() / yield* について
これらは複数のEffectを逐次処理的に書けるようにするためのヘルパーです。
Promiseにおけるasync/awaitのように処理を並べることができます。
このEffectの型が予想通り Effect<void, never, Logger>になっていますね。
実際にこのプログラムにLoggerの実装を流すにはEffect.provideを使って以下のようにするだけです。
Effect.provide(helloWorldProgram, LiveLogger)
// もしくはEffect.pipeを使って
helloWorldProgram.pipe(Effect.provide(LiveLogger))
ここまでのまとめ
EffectとService, Layerを使って、完璧にビジネスロジックと依存を切り離せていることにお気づきでしょうか?
helloWorldProgram 自体は「Logger という能力が欲しい」という宣言しかしていません。
つまり、ビジネスロジック側は 「Logger が存在すること」 さえ分かっていればよく、その実装がどうなっているかは一切知らなくて良いわけです。
一方で、LiveLogger は「Logger とはこのように動きます」という具体的な実装を提供しています。
しかし、この実装はプログラム本体とは完全に別の層に置かれています。
プログラムの中にconsole.logが登場することもなければ、標準出力の仕組みを意識する必要もありません。
Effect.provide がやっているのは、"Logger が必要です!"と宣言するプログラム と "Logger の実装はこれです!" と提供するLayerを実行時に合成する、ただそれだけです。
「安全な」オヤジギャグ生成プログラムを作る
ここからは、いよいよEffect AIを使って安全なLLM呼び出しを使った「オヤジギャグ生成プログラム」を実際に作っていきます。
やりたいことを書く
まず、今作りたいもののビジネスロジックをそのまま記述してみましょう。
Effect AIではLanguageModelというサービスが用意されています。
(正確には、モデル固有の設定・依存をまとめた「高レベルServiceコンポーネント」です)
import { LanguageModel } from "@effect/ai";
import dedent from "dedent";
import { Config, Context, Effect, Layer, Schema } from "effect";
// ジョークを生成するプログラムEffect (プログラムの設計書)
const generateDadJokeProgram = Effect.gen(function* () {
// どのモデルを使うかは知らなくて良い、APIキーの指定もしていない、fetcherが登場しない!
const response = yield* LanguageModel.generateObject({
prompt: dedent`
すごく面白いオヤジギャグを考えてください
回答は以下のJSON形式で返してください。
{
"joke": "ジョークの内容",
"explanation": "ジョークの説明"
"score": 自己採点した時のジョークの面白さ (0~100)
}
`,
schema: Schema.Struct({
joke: Schema.String,
explanation: Schema.String,
score: Schema.Number.pipe(Schema.between(0, 100)),
}),
});
yield* Console.log(`オヤジギャグ: ${response.value.joke}`);
yield* Console.log(`説明: ${response.value.explanation}`);
yield* Console.log(`自己採点した時の面白さ: ${response.value.score}`);
});
いい感じです、記法に慣れは必要ですがビジネスロジックだけを書けています。(fetchもAPIキーも登場しません!)
使うモデルを定義する
では、実際に使うLLMを決めましょう。
今回はGeminiの2.0 flashを使うこととします。
@effect/ai-googleモジュールから利用できます。
import { GoogleLanguageModel } from "@effect/ai-google";
const Gemini2Flash = GoogleLanguageModel.model("gemini-2.0-flash");
重要なのは、この時点ではまだなにもHTTPリクエストは飛んでいないということです。
あくまで「このモデルを使うよ」という設定情報・依存関係の束を作っているだけで、実際の呼び出しは後でEffectランタイムが行います。
GeminiとHTTPクライアントのLayerを定義する
次に、「実際にGeminiを叩くための実装」をLayerとして用意します。
ここで初めて、APIキーやHTTPクライアントといった、現実世界の事情(副作用)が登場します。
const GoogleAI = GoogleClient.layerConfig({
apiKey: Config.redacted("GEMINI_API_KEY"), // redactedで環境変数を保護 (logに出ない)
});
一見すると、これでGoogleAIのクライアントLayerができたという印象を受けるかもしれません。
実際に型を確認すると、このGoogleAIのLayerの型は
GoogleAI: Layer<GoogleClient.GoogleClient, ConfigError, HttpClient>
となっています。
EffectがEffect<Success, Error, Requirements>という形で「成功値・失敗値・必要な依存」を持つように、Layerも実はLayer<RequirementsOut, Error, RequirementsIn>という形で 「作成されるサービス・サービスの構築中に発生するエラー・サービスの構築に必要な依存関係」 を持ちます。
つまり、この時点のLayerはまだ完全ではなく、HTTPクライアントを誰かから提供してもらわないと動けないという状態です。
この依存を解決するためにNode.jsのHTTPクライアント実装をLayer.provideでGoogleAIに注入しましょう!
import { NodeHttpClient } from "@effect/platform-node";
const GoogleAIHttpClient = GoogleAI.pipe(Layer.provide(NodeHttpClient.layerUndici))
最終的には全ての依存を解決した完全なLayerを定義することができます。
// ↓依存はもう不要!
const GoogleAiHttpClient: Layer.Layer<GoogleClient.GoogleClient, ConfigError, never>
また、設定に不備がある場合(APIキーが間違っているなど)にConfigErrorを起こすことが型レベルで確認できます。(そして、その責任がLayerにあります)
EffectにLayerを注入し、実行する
ここまでで、
- やりたいことだけを書いたプログラム:generateDadJokeProgram
- どのLLMモデルを使うか:Gemini2Flash
- そのモデルをどうやって叩くか(Google API + HTTPクライアント):GoogleAIHttpClient
という3つが揃いました。
あとは、これらをEffectに「注入」して実行するだけです。
generateDadJokeProgram
.pipe(Effect.provide(Gemini2Flash)) // LLMモデル(gemini-2.0-flash)を注入
.pipe(Effect.provide(GoogleAIHttpClient)) // GoogleAIHTTPClientの実装を注入
.pipe(Effect.runPromise);
最後の.pipe(Effect.runPromise)によって、HTTPリクエストが飛び、LLMが動き、JSONが返ってきて、Schemaでバリデーションされ、Console.logが呼ばれます。
プログラム全文
import { LanguageModel } from "@effect/ai";
import { GoogleClient, GoogleLanguageModel } from "@effect/ai-google";
import { NodeHttpClient } from "@effect/platform-node";
import dedent from "dedent";
import { Config, Effect, Layer, Schema, Console } from "effect";
// 使うLLMモデルの定義
const Gemini2Flash = GoogleLanguageModel.model("gemini-2.0-flash");
// Google APIを使うためのHttpClientの定義
const GoogleAiHttpClient = GoogleClient.layerConfig({
apiKey: Config.redacted("GEMINI_API_KEY"), // redactedで環境変数を保護 (logに出ない)
}).pipe(Layer.provide(NodeHttpClient.layerUndici));
// ジョークを生成するEffect
const generateDadJokeProgram = Effect.gen(function* () {
const response = yield* LanguageModel.generateObject({
prompt: dedent`
すごく面白いオヤジギャグを考えてください
回答は以下のJSON形式で返してください。
{
"joke": "ジョークの内容",
"explanation": "ジョークの説明"
"score": 自己採点した時のジョークの面白さ (0~100)
}
`,
schema: Schema.Struct({
joke: Schema.String,
explanation: Schema.String,
score: Schema.Number.pipe(Schema.between(0, 100)),
}),
});
yield* Console.log(`オヤジギャグ: ${response.value.joke}`);
yield* Console.log(`説明: ${response.value.explanation}`);
yield* Console.log(`自己採点した時の面白さ: ${response.value.score}`);
});
generateDadJokeProgram
.pipe(Effect.provide(Gemini2Flash))
.pipe(Effect.provide(GoogleAiHttpClient))
.pipe(Effect.runPromise);
実行してみる
$ GEMINI_API_KEY=xxxxxxxx pnpm run dev
> tsx src/Program.ts
オヤジギャグ: 「そろそろトイレに行っといれ!」
説明: 「トイレに行く」という行動を促す言葉と、語尾の「いっといれ(行ってらっしゃい)」という響きをかけたダジャレです。親しい間柄で使うとよりユーモラスに聞こえます。
自己採点した時の面白さ: 85
かなり強気ですね
嬉しさ
ここまでを踏まえて、改めてこのEffectによる嬉しさを整理してみます。
ビジネスロジックに集中できる
「レートリミットに引っかかっていたら?」「環境変数を間違えていたら?」と言った雑念に惑わされずに、ロジックに集中してコーディングすることができます。
依存の不足に気付ける
もし、Layerの一部をprovideし忘れてしまっても大丈夫です。
型レベルでLayerが必要なことは静的に検出されます。

これは従来のDIとは決定的に異なります。
「テストを実行して落ちるのを確認する」のではなく、「エディタ上で赤い波線が出る」 のです。
Effectを見るだけで依存が明確になる
次のようなEffectを見るだけで、もうそのプログラムにはどのような依存が必要かわかるでしょう。
const ToDoApp: Effect<void, ToDoError, Database | Logger>
テスタビリティ
依存(さらには依存そのものの依存関係)が明確に構造化・分離されているため、テストがとても簡単です。
モデルを入れ替えるなら、新しくモデルを定義して入れ替えるだけです。
import { AnthropicLanguageModel } from "@effect/ai-anthropic"
import { OpenAiLanguageModel } from "@effect/ai-openai"
const Gpt4o = OpenAiLanguageModel.model("gpt-4o")
const Claude37 = AnthropicLanguageModel.model("claude-3-7-sonnet-latest")
generateDadJokeProgram
.pipe(Effect.provide(Gpt4o)) // Gpt4o, Claude37, Gemini2.0Flash
.pipe(Effect.provide(GoogleAiHttpClient))
.pipe(Effect.runPromise);
generateDadJokeProgramは一切触らなくて良いです。
副作用の責任範囲が明確になる
「外部世界と話すのはLayerの責任」
「やりたいことを組み立てるのはEffectの責任」
という役割分担が非常にクリアになるので、コードリーディングとリファクタリングがしやすくなります。
型安全な構造化出力
これは特に説明していませんでしたが、score: Schema.Number.pipe(Schema.between(0, 100))によって、score は必ず数値であることかつ 0〜100 であることが型レベルで保証されます。
参考: Introduction to Effect Schema
悲しさ
Effectを使ったコードが世にまだ少ないのか、コード補完やLLMにaskした時の精度が(体感)かなり悪いことは悲しいです。
さいごに
実はEffect AIでは他にもExecution Planningによるリトライ戦略(exponential backoff)やフォールバックモデルの管理(ex. OpenAI呼び出しが失敗したら、Geminiを使う)、Tool Useによる型安全なLLMの関数呼び出しなどもサポートされています。
これらはまた別の記事で紹介できればと思います。
ここまで読んでいただきありがとうございます!