はじめに
Discoveryの概要については、@ishida330 さんの記事がとても詳しいので、どのようなサービスかご存知でない方はこちらをお読みください。
Watson Discovery Serviceが日本語対応したので、触ってみた【何、それ?】編
上の記事にあるとおり、Discoveryは多くのユースケースが考えられるサービスです。
本稿は、その一つである、質問応答システムとしてのユースケースを想定して触ってみた知見の共有です。
なお、質問応答システム用のサービスとしてはRetrieve and Rank (R&R)がありましたが、サービス終了となりました。
[[Watson] Retrieve and Rankのサービス終了について]
(https://qiita.com/y-some/items/fc0937e031a3ab52d459)
<ご注意>
本稿の内容は執筆時点の情報に基づいており、現在の情報と異なっている可能性があります。
本稿の内容は執筆者独自の見解であり、所属企業における立場、戦略、意見を代表するものではありません。
質問応答システムの動作イメージ
Node-REDでこんな感じのモノを作ってみました。

日本語のコレクション作成
作成手順は概ねこちらの記事通りです。
[Watson Discovery Serviceが日本語対応したので、触ってみた【やってみた】編]
(https://qiita.com/ishida330/items/bb1bd4cf61da9b9c6da2)
2017年11月現在、日本語のコレクションはAPIで作成しなければならず、Discovery toolでは作れません。
私が叩いたcurlコマンドを載せておきます。
-- environmentの一覧を取得
curl -u "{ユーザーID}":"{パスワード}" "https://gateway.watsonplatform.net/discovery/api/v1/environments?version=2017-11-07"
-- environment_idを指定して日本語にカスタムしたconfiguration_idを取得
curl -u "{ユーザーID}":"{パスワード}" "https://gateway.watsonplatform.net/discovery/api/v1/environments/{上で取得したenvironment_id}/configurations?version=2017-11-07"
-- 日本語にカスタムしconfiguration_idを指定して日本語のcollectionを作成
curl -X POST -u "{ユーザーID}":"{パスワード}" -H "Content-Type: application/json" -d '{ "name": "{作成するコレクション名}", "description": "{作成するコレクションの説明}", "configuration_id": "{上で取得したconfiguration_id}", "language": "ja"}' "https://gateway.watsonplatform.net/discovery/api/v1/environments/{上で取得したenvironment_id}/collections?version=2017-11-07"
ユーザーIDとパスワードは「サービス資格情報」で確認できます。

ドキュメントのアップロード
厚生労働省の労働基準法に関するQ&Aから、適当に見繕って使いました。
(ご参考)厚生労働省のコンテンツは、規約に従えば『複製、公衆送信、翻訳・変形等の翻案等、自由に利用できます』とのことです。
厚生労働省 > ホーム > 利用規約
上のサイトの質問文のリンクをクリックすると、こんな感じのページが表示されるので、
ソースを取得して、余計なタグを全部取っ払って、こんな感じのシンプルなHTMLにしてUTF-8で保存します。
(ここまでタグを省略しても大丈夫でした)
2017年11月現在、ファイル名に全角文字は使えません。
<!DOCTYPE html>
<head>
<title>勤務時間の上限は法律で決まっていますか。|厚生労働省</title>
</head>
<body>
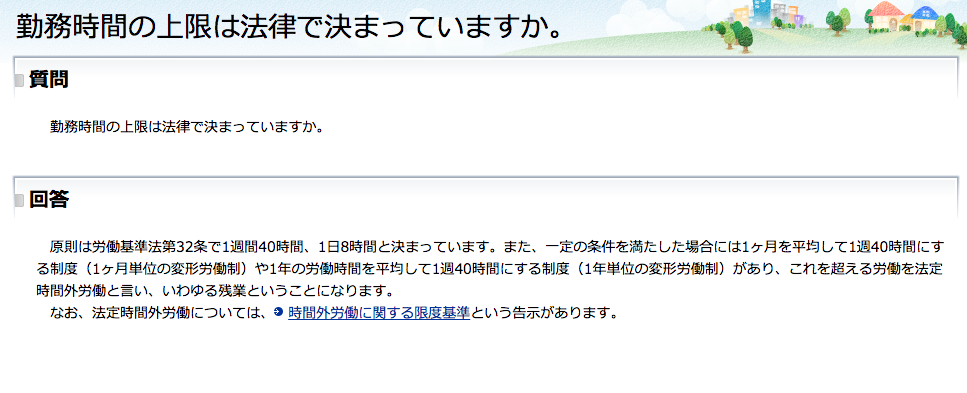
原則は労働基準法第32条で1週間40時間、1日8時間と決まっています。また、一定の条件を満たした場合には1ヶ月を平均して1週40時間にする制度(1ヶ月単位の変形労働制)や1年の労働時間を平均して1週40時間にする制度(1年単位の変形労働制)があり、これを超える労働を法定時間外労働と言い、いわゆる残業ということになります。<br />
なお、法定時間外労働については、<a href="/new-info/kobetu/roudou/gyousei/kantoku/040324-4.html" class="ico-link">時間外労働に関する限度基準</a>という告示があります。
</body>
そして、HTMLファイルをDiscovery tool上でアップロードし、成功すると以下のようなビューで見ることができます。


tool上で自然言語検索を試してみる
こんな感じで、tool上で自然言語検索を試すことができます。

トレーニング(機械学習)
この状態でも質問応答システムのバックエンドとして使うことはできますが、「この質問にはこの回答が適切だよ!」という教師データを作成して、トレーニングすることもできます。
上図右上「Train Watson to improve results」のリンクから、トレーニング画面に遷移したら、自然言語の質問を追加して…
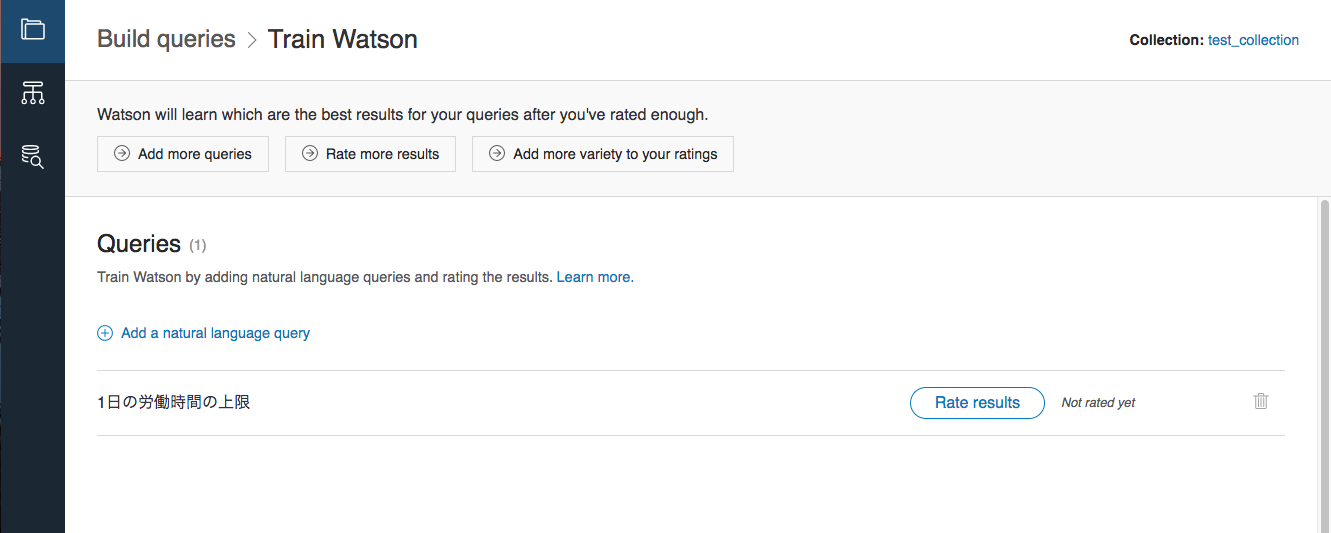
表示された結果に対して、適切かどうかを評価していきます。
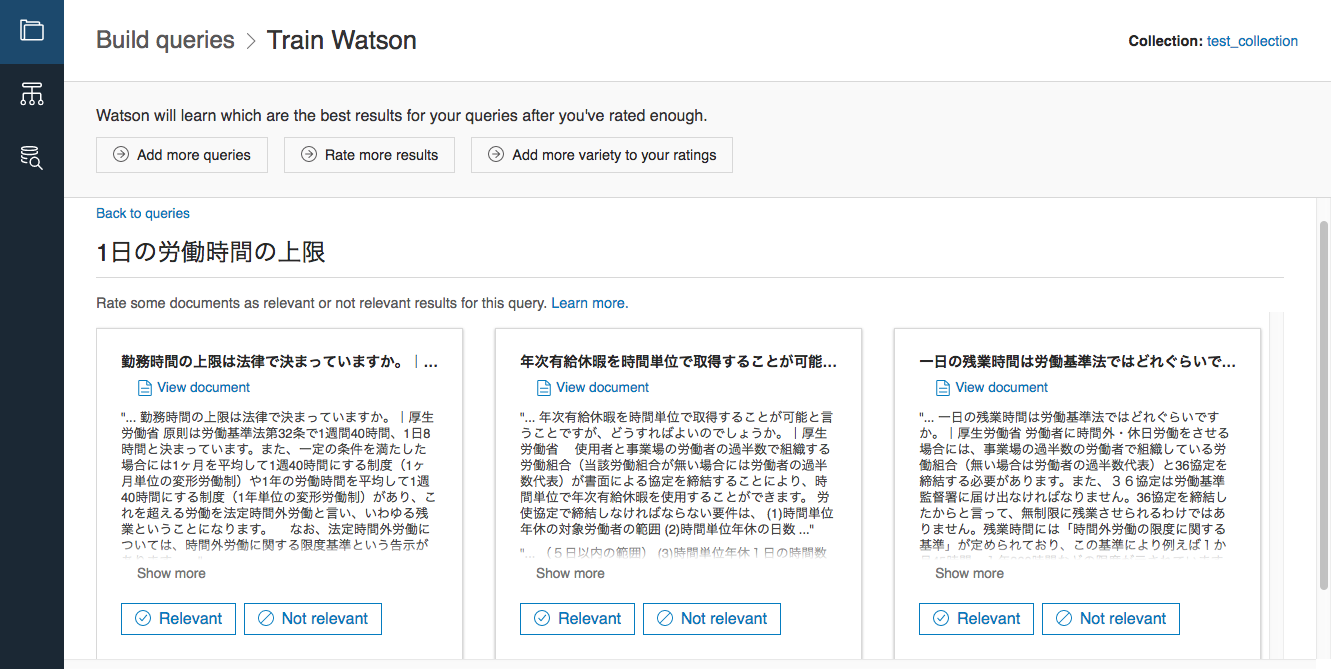
49以上の質問に対して上を繰り返すとトレーニングが始まります。
今回はこちらの作業は省略しました。
それにしても、R&Rと比べると遥かに簡単になっています。![]()
Node-REDの定義

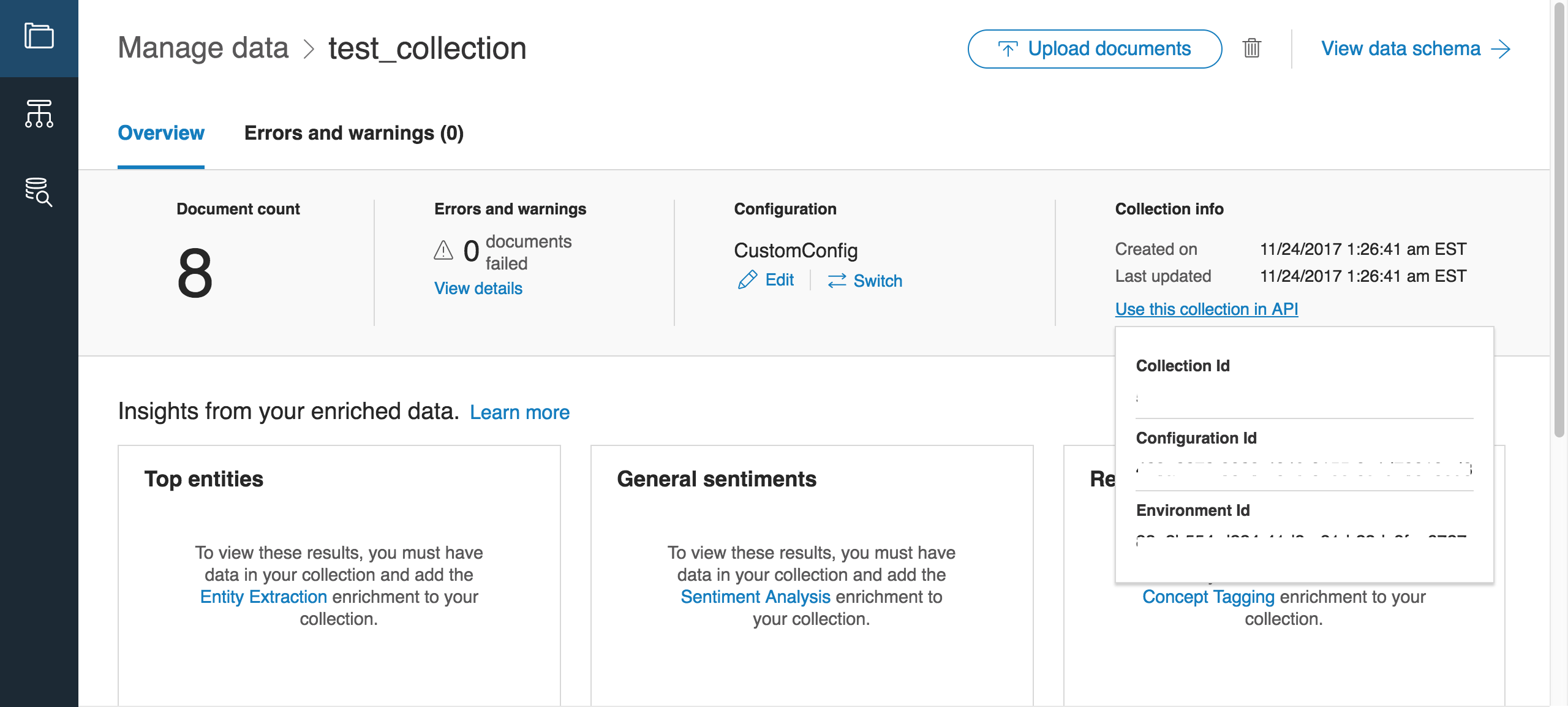
Discoveryノードには以下のような項目があります。
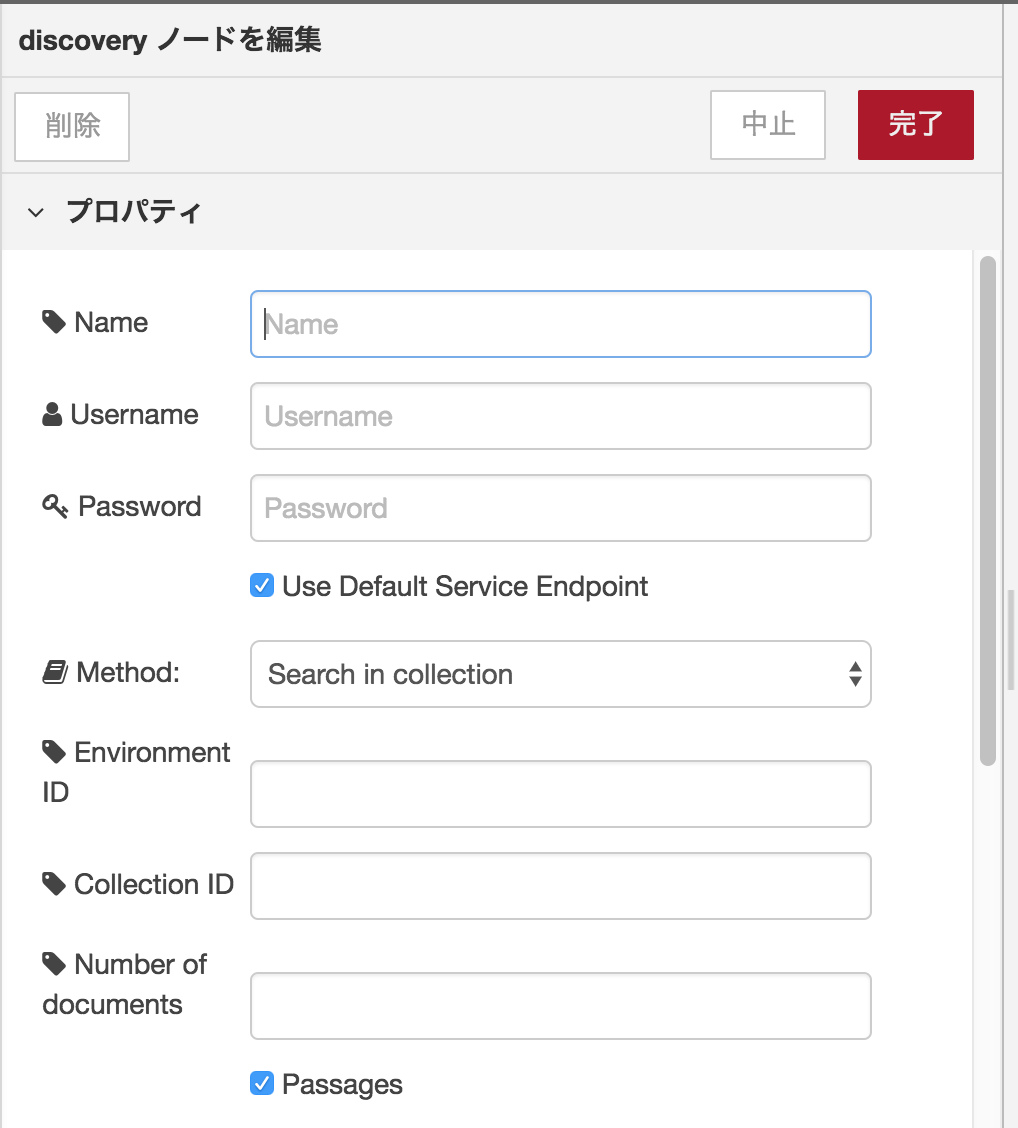
Environment ID、Collection IDは、以下の画面で確認できます。
Discovery以外のノード定義は、私が以前書いたこちらの記事とほぼ同じですので、参考にしてください。
Watson Retrieve and Rankの公式ツールを利用して質問応答システムを作る (3)
Node-REDにインポートするためのJSONも公開しておきます。
GithubGist
レスポンス
レスポンスの取得方法
Discoveryノードのレスポンスは、msg.search_resultsに格納されています。
レスポンス項目
今回の手順でアップロードした文書では、
・文書ID
・スコア(確信度)
・タイトル
・html
・text
を取得することができました。
結果配列は確信度が高い順に並んでいるようです。
(資料上それが明記されている部分は探せませんでしたが)
応答文書数
リクエストパラメータで、応答で返す文書数を指定できます。
Discoveryノードでは「Number of documents」という項目で指定します。
Passages
Discoveryノードで「Passages」というチェックボックスをチェックすると、文書中の関連性の高い箇所が配列で返ってきます。
ただし、Node-REDのバージョンが古いと、Passagesチェックボックスが表示されず、取得できません。(falseで照会されるようです)
(2017/12/14 追記)
まだ日本語環境ではPassagesの内容が正しくないようで、実質使えません。
エンリッチメント
本来は、エンリッチメントの情報も返ってきます。
しかし今回は(日本語未対応のため)カスタム構成でエンリッチメントを削除していますので、その情報は返ってきません。
レスポンスのサンプル
API Referenceにて、レスポンスのサンプルJSONファイルをダウンロードできます。
Discovery - API Reference - Query your collection
おわりに
Discoveryの日本語対応は現在進行形で、まだ全機能は対応していません。
その真価は質問応答だけではありませんので、また後日触ってみたいと思います。