
![]() 当記事の初版は2017/9月に書いたものですが、Discoveryは日本語フル・サポート始めガンガン機能拡張が入っているので、2019/2月時点で内容を最新版にアップデート1しました。
当記事の初版は2017/9月に書いたものですが、Discoveryは日本語フル・サポート始めガンガン機能拡張が入っているので、2019/2月時点で内容を最新版にアップデート1しました。
当記事は2部構成とし、①「何、それ?」という方向けの「ご紹介編」と②実際の手順をご紹介する「やってみた編」に分けてます。大筋だけ知りたいけど手を動かすほどじゃない、って方は当記事だけお目をお通しくださいませ。
-
【やってみた】編はこちらです (
 2019/2月 SDUを使った最新版に更新済)
2019/2月 SDUを使った最新版に更新済)
Watson Discovery Serviceって何?
一言で言えば「コグニティブ・クエリー」でしょうか。ホームページでの謳い文句を翻訳すると「データから回答を見つけ出したり、トレンドやパターンをモニターすることでデータの隠れた価値を解明できる世界で最も先進的なクラウドネイティブの洞察エンジン」ということですが、要は「pdfやWordなどの文書群をとにかくぶち込めば、そこに書いてある文章を解釈して、あれこれ気の利いたデータを自動的に付加してくれて、それによって検索や回答の精度を上げてくれたり洞察を与えてくれる賢い照会・検索エンジン」だと思っていただけばよいかと思います。
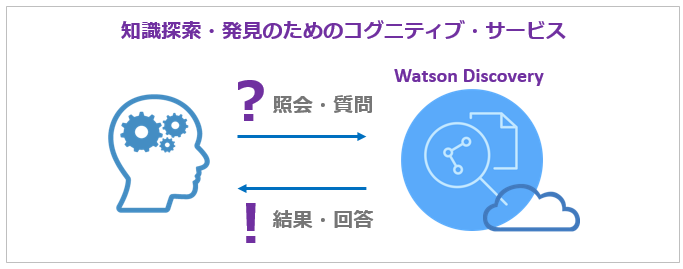
- オンプレのソフトウエアであるWatson Explorer(Advanced Conmponent)をご存知の方は、仕組みは違えどあれのクラウド版みたいなもの、と思っていただいて(大筋は) 結構です
- 従来別々に提供されてきた様々なWatson APIのサービスは以下のような感じでDiscoveryに統合され、より使いやすくなってます
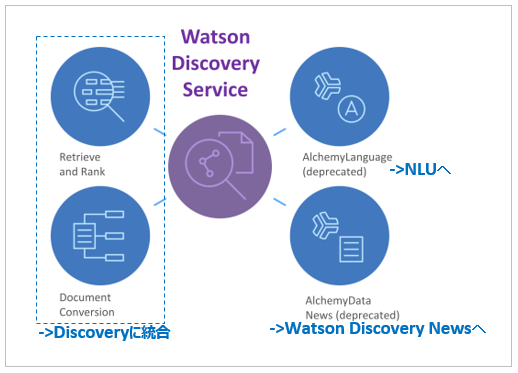
-
 ロングテールのQ&A用に、従来も Retrieve and RankとDocument Conversionというサービスがありましたが、既にサービスは停止されています。後継はWatson Discoveryの「Relevancy Training」機能になります。
ロングテールのQ&A用に、従来も Retrieve and RankとDocument Conversionというサービスがありましたが、既にサービスは停止されています。後継はWatson Discoveryの「Relevancy Training」機能になります。 - ずっと以前、似た名前で「Watson Discovery Advisor」というものがありました。課題感は似ていますが全くの別物です
- 2018/06/26より日本語がフルサポートになりました!フル対応とは、要は「日本語でも文書を勝手にエンリッチしてくれて、賢い文書の検索ができるようになった」2 、ってことです。
Watson Discovery Serviceって何がいいの?
以下がWDSサービスの特長です。
![]() 膨大な文献・文書データの準備が楽
膨大な文献・文書データの準備が楽
![]() 膨大な文献・文書の照会・検索が迅速に行える
膨大な文献・文書の照会・検索が迅速に行える
![]() 話し言葉でも検索できる(サーチと自然言語処理の融合)
話し言葉でも検索できる(サーチと自然言語処理の融合)
![]() 自然言語処理(NLP)をカスタマイズできる
自然言語処理(NLP)をカスタマイズできる
![]() 機械学習(NLU)による文書のエンリッチメント(英語のみ)
機械学習(NLU)による文書のエンリッチメント(英語のみ)
![]() 構造化データと非構造化データの両方を扱える
構造化データと非構造化データの両方を扱える
![]() クラウド上のサービスなので構築の手間が不要
クラウド上のサービスなので構築の手間が不要
![]() 日本語を始め9ケ国語を扱える
日本語を始め9ケ国語を扱える
![]() 様々なコグニティブ・サービスが1つに統合されており、使い勝手がシンプル
様々なコグニティブ・サービスが1つに統合されており、使い勝手がシンプル
![]() ずっと無料のLiteプランからお金持ち向けのPremiumプランまで、サービス・プランの選択肢が豊富
ずっと無料のLiteプランからお金持ち向けのPremiumプランまで、サービス・プランの選択肢が豊富
![]() 東京データセンターが選べる
東京データセンターが選べる
![]() AIアシスタントであるWatson Assistantとの容易な統合
AIアシスタントであるWatson Assistantとの容易な統合
まあ、ぶっちゃけ申しますと似たような「AIフレーバーの検索API/サービス」は他社様にもあるのですが、APIがバラバラで統合されていなかったり、まだベータ段階だったり、日本語未対応だったり、、、という「初期段階」「MVP」との印象です。すでに本番のサービスで東京で動いていて日本語も扱えるという意味で、Watson Discoveryは現時点でも最も進んでいるサービス、と言えるとおもいます。
IBM Cloudのカタログからインスタンスを簡単に作れます。

Watson Discoveryって何に使えるの?(ユースケース)
基本は「大量の文書(構造化・非構造化データ)」に対して照会をかけて洞察・知見を導く、ってことですが、大きくは下記3つの利用軸が考えられます。

具体的には以下のようなユースケースが考えられます。
| 業界・業種 | 文書例 | 利用場面 |
|---|---|---|
| 保険 | 業務規定集 | 査定で申請文書が規定のプロセスに沿っているか、チェックする(自動支払点検) |
| 製造 | 製品マニュアル | フィールドサポート担当者が故障事象から、原因や対策・必要部品を素早く特定する |
| 顧客サポート | 会話ログ | コールセンターにて「お客様の声(VoC)」や評判の傾向を分析する |
| 製造 | 苦情メール | クレームの傾向から製品不具合を早期に発見する |
| 研究機関 | 特許情報・論文等 | 膨大な専門分野の文献から、望む情報を素早く取り出す |
| リーガル | 判例 | 法律事務所で、膨大な判例や事案から類似したケースを素早く抜き出す |
| 共通 | 商品レビューやアンケート | マーケティング部門が自社およびブランドの評判の推移トレンドを分析する |
| 共通 | ニュース・決算情報 | 膨大な市場の情報から競合や買収対象の企業の情報を効率的に抜き出す |
| 共通 | マニュアル | Q&Aシステムで、通常のFAQに含みずらいロングテールな質問に対しても何らかの回答を提示する |
アーキテクチャー
以下がWDSの大きい処理の流れです。
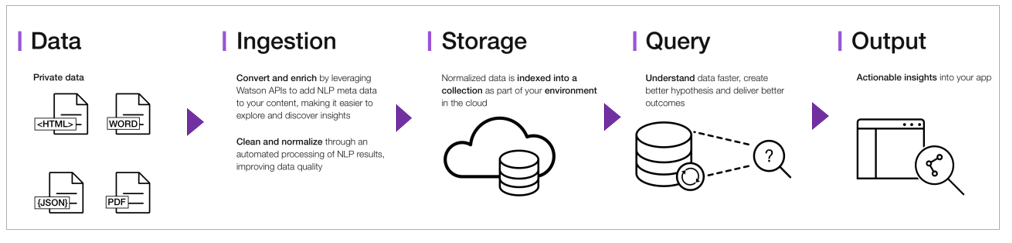
| フェーズ | 説明 |
|---|---|
| Data | 様々な形式の文書 |
| Ingestion3 | 文書の取り込みと前処理を実施 |
| Storage | 内部的に索引が作られ保管されます |
| Query | 照会または質問を投げます |
| Output | 照会結果、回答、パターン、傾向など |
「クエリ・検索」の仕組み面では、事前に文書を取り込んだりクロールして内部的に索引を作っておき、その索引を検索の対象にします。リアルタイムでデータソースに直接、検索をかけるわけではありません。
扱えるドキュメント形式(文書)
以前はHTML/PDF/Word/Jsonの4種でしたが、 ![]() 2019/2月からSDU(Smart Dosument Understanding)がサポートされ、Excel/PowerPoint/Imageが加わりました。
2019/2月からSDU(Smart Dosument Understanding)がサポートされ、Excel/PowerPoint/Imageが加わりました。
| 形式 | Query | SDU(Lite) | SDU(Advanced) |
|---|---|---|---|
| HTML | ○ | - | - |
| ○ | ○ | ○ | |
| Word | ○ | ○ | ○ |
| JSON | ○ | - | - |
| Excel | ○ | ○ | ○ |
| PowerPoint | ○ | ○ | ○ |
| Image(PNG,TIFF,JPG) | - | - | ○ |
- 素のtextはサポートしていません ( が、pdfやWordに変換すればいいでしょう)
- 一文書の最大サイズは50MB
- 文書内のイメージやJavaScript等は無視されます
- SDUは利用しているプランにより対象が異なります
- PDFやExcelでは表の中身も照会できるようになりました
- イメージはPNG/TIFF/JPG内のテキストを検出します
Connector
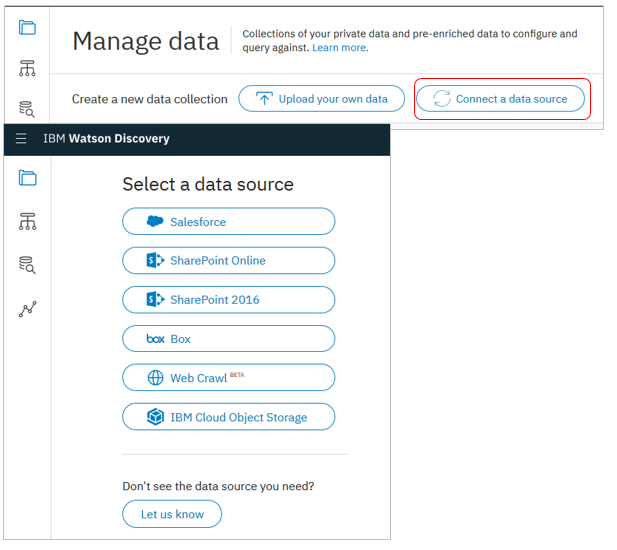
文書だけでなく、様々なデータストアとのコネクターをご用意しています。これらのデータストアとUI操作だけで簡単に連携してコンテンツを検索できます。
- 以前はクローラーがありましたが、2019/2月時点では非推奨です
- 今後の機能拡張はConnectorに対して行われますので、クローラーは使わないほうが良いでしょう
- Sharepoint、Boxなど既にConnectorが提供されているデータストアではクローラーはサポートされません
- まだDBなどがConnectorに入ってないので、そこはクローラー使えます
- ConnectorはAPIの形式でも使えます。APIのほうが細かいオプションをあれこれ指定できます。翻ってUI(Discovery Tooling)は「設定の簡単さ」重視です
- IBM Secure Gatewayと連携してオンプレミスのデータソースもクロールできます
ConnectorはUIで定義するだけですがクローラーはJavaベースで定義ファイルを用意したり面倒ですから、今後はConnectorをご利用ください。
以下は昔のクローラーの記述。ご参考として残しておきます
Javaベースのクローラーが提供されています。 (別途ダウンロードして導入要) クローラーでは以下のコネクターを利用できます
![]() ファイルシステム
ファイルシステム
![]() データベース(JDBC経由)
データベース(JDBC経由)
![]() CMIS(Content Management Interoperability Services)
CMIS(Content Management Interoperability Services)
![]() ファイル共有(SMB , CIFS, Samba)
ファイル共有(SMB , CIFS, Samba)
![]() SharePoint / SharePoint Online
SharePoint / SharePoint Online
![]() box
box
![]() 注意事項
注意事項
- クローラーはコマンド・ベースです。UIはありません
- Linuxのみ対応しています
- インターネット上のHTMLページをクロールする機能はありません(でもGitHub上にWatson Discovery Service indexing plugin for Apache Nutchというのがありました)
- クローラーはリモート・システムから大量の文書をアップロードするためのものです。ローカルファイルを利用する場合は通常のアップロードが推奨です
- Watson Discovery ServiceのData Crawlerでデータベース(MySQL)をクロールしてみたの記事を書きました
Watson Discovery News( 日本語ニュースも!)
日本語ニュースも!)
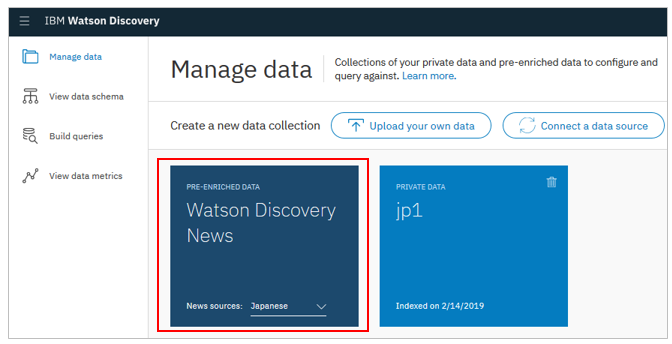
Watson Discovery Newsという巨大なニュースのデータセットが容易されており、簡単に利用できます。2018/7/29からは日本語のニュース提供も開始しています。
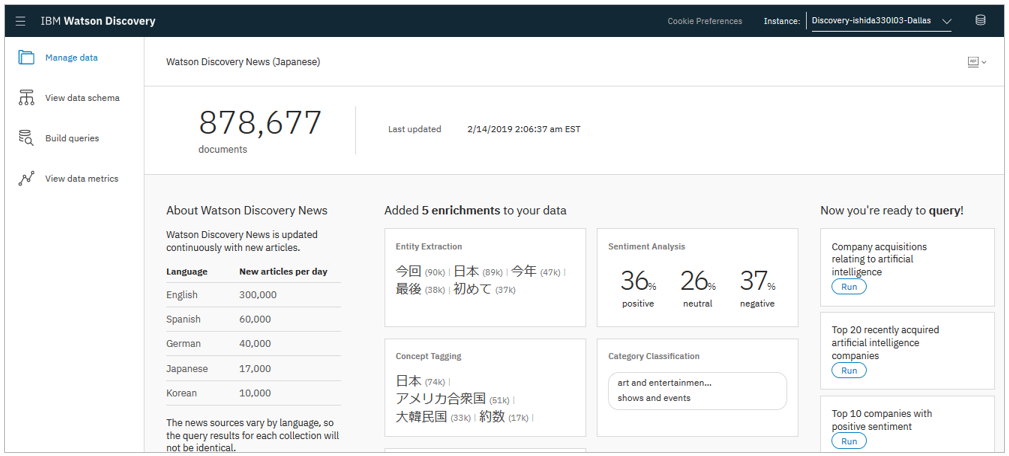
- Discoveryのインスタンスを作るとデフォルトで表示されます
- 過去60日間のニュースを保持(超えると消えていきます)
- エンティティやキーワードなどNLUによるエンリッチ済のデータセット
- ニュース・アラートやイベント検知、トピックのトレンド理解などに
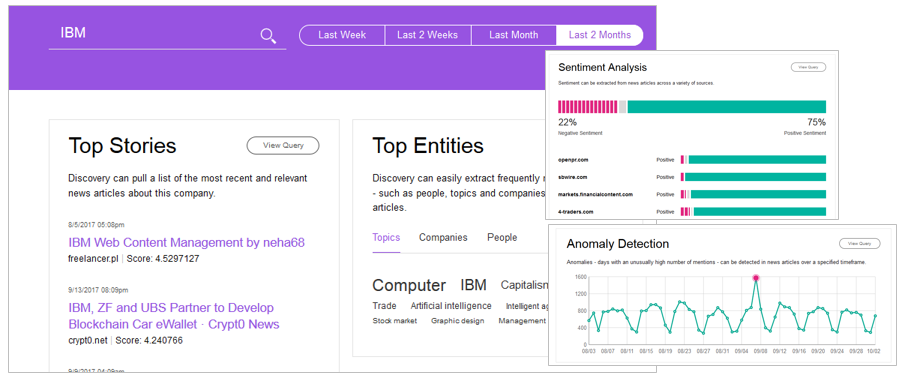
デモサイトではニュースをデータソースにした企業分析の例をご覧いただけます
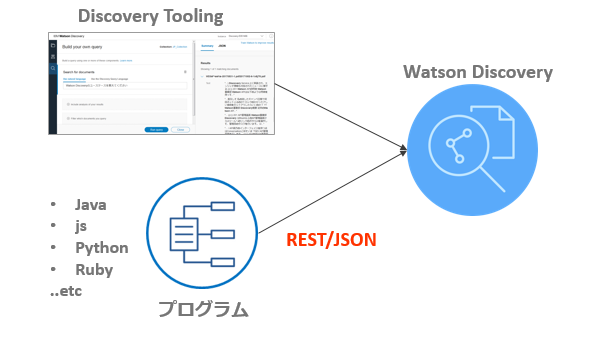
Discovery Tooling(UI)とAPI
Discoveryは①ブラウザー上のUIツール(Discovery Tooling)と②APIの両方でアクセスできます
日本語で何が出来て、何ができないの?
以前は英語と日本語でサポートする機能に差があったのですが2018/6月にフルサポートしたことで(表向きには)機能差はほぼ無くなりました4。
言語毎の細かいサポート状況はSupported Languageのページに機能とサポート言語が書いてあります。2019/2月時点で簡単にまとめます。
| 種類 | サポート言語 |
|---|---|
| Basic | Arabic (ar) / Chinese, simplified (zh-CN) / Dutch (nl) |
| Full | English (en) / French (fr) / German (de) / Japanese (ja) / Korean (ko) / Spanish (es) / Italian (it) / Portuguese, Brazilian (pt-br) |
| # | 機能 | Basic | Full( |
|---|---|---|---|
| 1 | 文書の変換 | ||
| 2 | 他のWatson APIとの統合 | ||
| 3 | Discoveryツールの対応 | ||
| 4 | Front-end API (Front-end Query API除く) | ||
| 5 | 言語に最適化されたインデックス | ||
| 6 | 適切な回答のトレーニング(Relevancy training) | ||
| 7 | Watson Knowledge Studioカスタムモデルの利用 | ||
| 8 | 言語の検知(Language Detection) | ||
| 9 | 文書中の該当箇所の提示(Passage retrieval) | ||
| 10 | 翻訳されたWKSインターフェース | ||
| 11 | NLUによるエンリッチメント |
日本語はフル・サポートされている言語なので
-
 基本的な検索や質問は日本語の文書が扱える
基本的な検索や質問は日本語の文書が扱える -
「この質問にはこっちの回答のほうがいいよ!」と教えること(Relevancy Training)もできる
-
「あれこれ気の利いたデータを自動的に付加してくれる」(NLU Enrichment)機能も使える
-
「文書のここにヒットしてるよ!と教えてくれる」機能(Passage Retrieval)も使える
ってことですね。
Supported Languageのページによると2018/8時点で英語のみ![]() なのは以下の機能です
なのは以下の機能です
English-only support
The following features are currently supported in English only:
Element Classification enrichment
IBM Watson™ Discovery Knowledge Graph (beta)
Document deduplication (beta)
逆に日本語のみのサポートとして以下が書かれています。
Custom tokenization dictionaries
Discoveryの環境面の絵
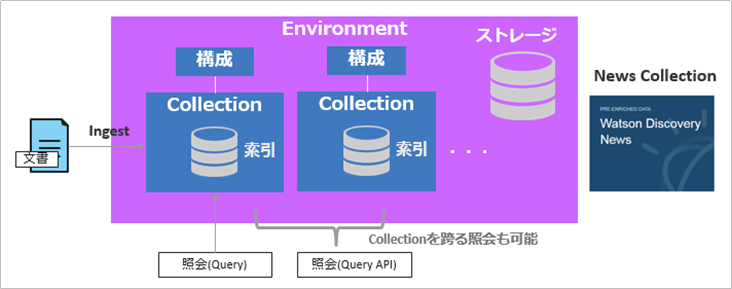
- Discoveyのインスタンスは複数定義できます
- インスタンス毎にEnvironmentが用意されます
- Environmentとは、要はストレージ領域でプラン毎に利用できるサイズは異なります
- 無料のLiteプランでは1000文書≒100MB程度が上限
- ストレージ・サイズの上限は1TB位が目安と聞いてます
- 標準で使えるNewsのCollectionは利用ストレージの勘定にいれません
- Environmentの中に実際の索引単位であるCollectionを作成できます
- 基本的に、文書のアップロードや照会は1つのCollectionに対して行います
- 複数のCollectionを作ることもできますが、Collectionの単位は業務やドメインの単位にまとめるのがよいでしょう。 関係のない文書が何でもかんでも入ってるゴミ箱のようなCollectionでは、照会結果にノイズが増えてしまいますから
日本語Collectionの作成
パネルのUIで「Japanese」を選べば作れます。

以前のCurl/APIを使う方法の記載も残しておきますが、もうこの手順で作る必要はありません
API Reference - Create a collection
>curl -X POST -u "dab333a2-0a6f-41a9-9e6b-xxxxxxxxxxxxxx":"xxxxxxxxxxxxxx" -H "Content-Type: application/json" -d '{ "name": "jp_collection", "description": "My test collection", "language": "ja" }' "https://gateway.watsonplatform.net/discovery/api/v1/environments/1b519542-9450-4316-ac21-xxxxxxxxxxxx/collections?version=2017-11-07"
----以下は戻り
{
"name" : "jp_collection",
"collection_id" : "05e96bca-cf07-4975-af5e-xxxxxxxxxxxx",
"description" : "My test collection",
"created" : "2017-11-16T04:27:25.065Z",
"updated" : "2017-11-16T04:27:25.065Z",
"configuration_id" : "0e99be1d-13cd-45de-xxxxxxxxxxxxxxxxx",
"language" : "ja",
"status" : "active"
}
構成(Configuration)
(2019/2) 以前はCollectionを作成したら、文書をアップロードする前に「構成」を定義していましたが、今は「構成」のパネルは無くなっています。( 今でも細かい変換の定義ファイルを書けば可能)
- 「構成」は「文書を変換して索引を作る際のルールの定義」です
- デフォルトの構成が用意されていますが、カスタマイズ可能です
- (一部は)UIツールまたは(全体は)APIで定義できます
右上のConfigure Dataをクリックすると、3つの設定タブがあります
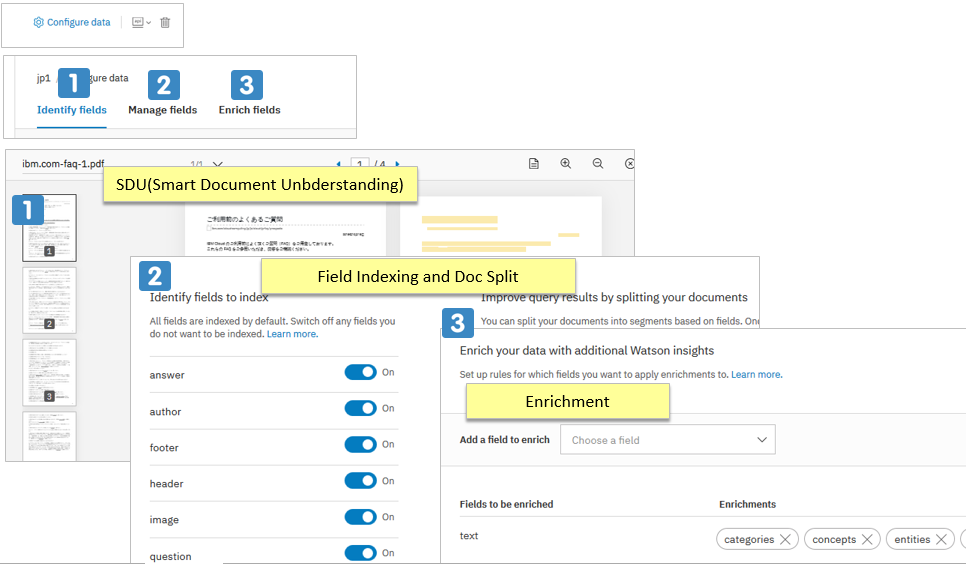
以前は以下のように「Convert/Enrich/Normalize」をパネルで定義出来ましたが、今はEnrichのみがパネルで定義可能です。Convert/Normalizeのカスタマイズは機能としては残っておりAPI経由でカスタム構成を組めば可能です。詳しくは ![]() Configuring Your Serviceをご参照ください。
Configuring Your Serviceをご参照ください。
![]() 注意点
注意点
-
デフォルトの構成(Default Configuration)では以下の4種類のエンリッチメントが有効になっています。それ以外のエンリッチメントを使いたければ明示的に追加登録する必要があります
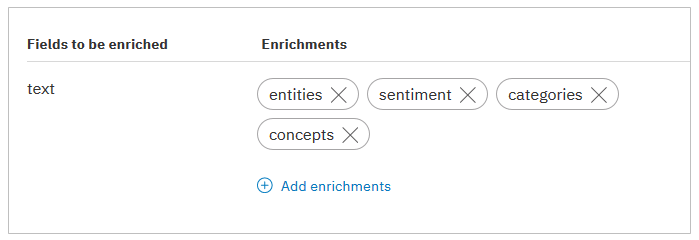
-
文書のアップロード後に構成情報を変更することはできますが、変更前にアップロードした文書は既に索引が作成済のため、変更内容は反映されません。定義を反映したければ文書を再度アップロードする必要があります。
文書の準備(Ingestion)
構成が固まったら、Discoveryで照会を行うため文書群をDiscoveryに格納します。このIngestionパイプラインは大きく3ステップから構成されます。
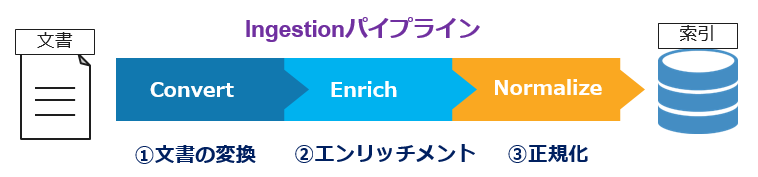
最新版では基本的に「デフォルト構成」が基本のようですので、文書をアップロードするだけであり、とても簡単です。(カスタマイズは可能です)
以下、上記パイプラインに沿ってご説明します。
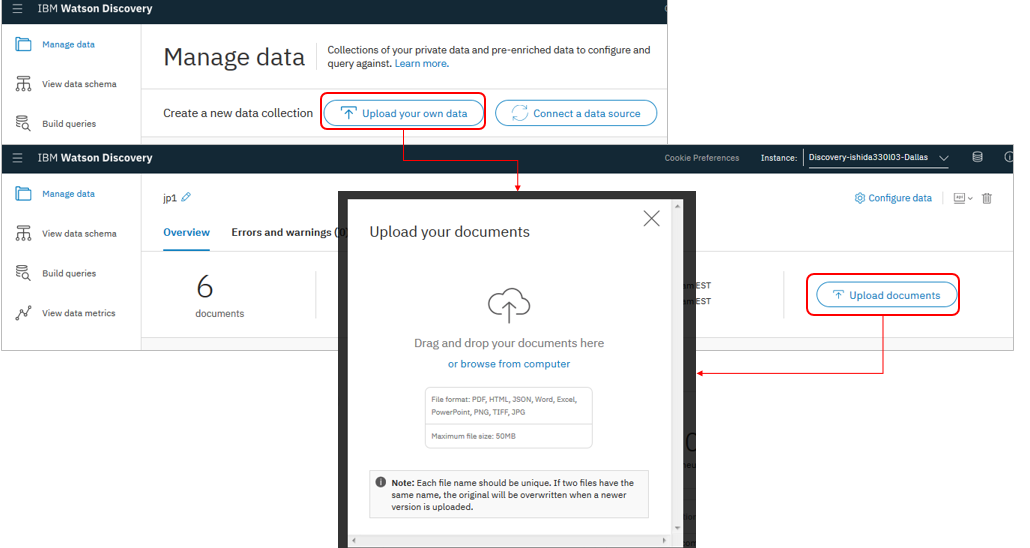
文書のアップロード
文書は以下の3通りの方法でDiscoveryにアップロードできます。
- UIツール経由でのファイルのアップロード
- API経由
- Connector経由
【UIでのアップロード画面】
1) 文書の形式変換(Convert)
文書がDiscoveryにアップロードされると、内部的には以下の流れで変換(Convert)され、最終的にはJSON形式になり内部インデックスに保管されます。(Discoveryのプランに記載のストレージのサイズはこの変換後のJSONの格納サイズです)
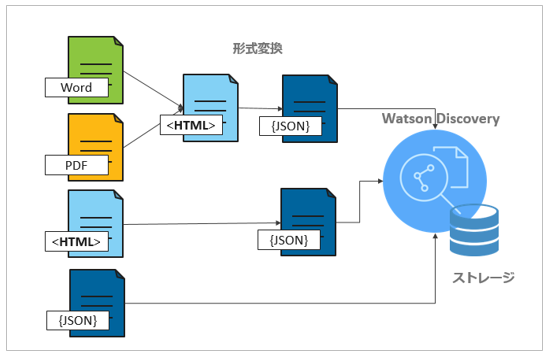
Discoveryは変換の過程で文書中の文節の区切りや文書のタイトルを識別しますが、WordやPDFではフォントのサイズ、HTMLの場合はh1などのタグで識別します。必要であれば、「構成」で文書種類毎にどうタイトルや文節に区切るかをルールとして指定可能です。(デフォルトあり)
更に「HTML中のJavaScriptを除去する」とか「文書中のイメージ部分を除去する」といった不要な部分をそぎ落とす処理も行います。
![]() Release Notesによると2017/10/3付でDocument segmentationという機能が搭載されました。大きなHTML/Word/PDF文書をHTMLのH1-H6タグのレベルで分割するものだそうです。詳細はSplitting documents with document segmentationをご参照ください。(ちら読みした限りでは、注意点もいくつかありそうです)
Release Notesによると2017/10/3付でDocument segmentationという機能が搭載されました。大きなHTML/Word/PDF文書をHTMLのH1-H6タグのレベルで分割するものだそうです。詳細はSplitting documents with document segmentationをご参照ください。(ちら読みした限りでは、注意点もいくつかありそうです)
2) エンリッチメント(Enrichment)
「エンリッチメント」という用語はあまり使われないので「??」と思われる方も多いかと思いますが、Discoveryにおいては一連の文章から「興味の対象」となるフィールドを抜き出して、元の文書に追加することです。(「元の文書をもっとリッチにする」って感じでしょうか。Information Extractionとも言います。)
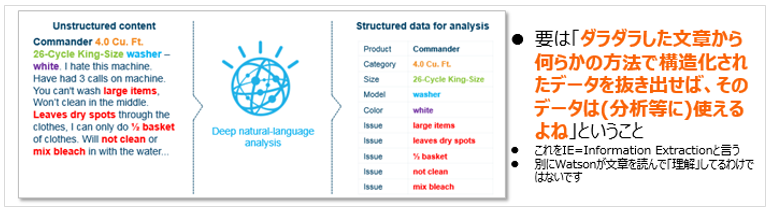
例えば上は洗濯機に関する消費者のレビューの文書ですが、「お客様の声」の分析において、ここから「製品名」「カテゴリー」「モデル」「色」「クレームの内容」などのフィールドを抽出して元の文書の横に添付しておけば、あとで照会する時に「クレーム内容別の件数集計」やトレンドの分析などに使えますよね。また単なる「文書に対する全文検索」だけでなく「エンリッチしたフィールドに対する検索」も可能になります。例えば「2017/10月の製品レビューで、ポジティブ/ネガティブな意見の件数はそれぞれ何件?」という調査が簡単にできます。「非構造化データから洞察・知見を導く」との謳い文句は例えばそういう意味です。
Discoveryではどんな「エンリッチメント」ができるの?
DiscoveryではIngestionパイプラインの処理過程で自動的にエンリッチメントが行われます。「どんなエンリッチメントをしたいか」は事前に構成で指定しておきます。実装イメージでは元の文書にエンリッチされたフィールドが追加されたJSONの形式になります。以下は元の文書に「センチメント分析」の結果(positive/netative/neutral)を追加した場合の例です。

Discoveryでのエンリッチメントは大きく2種類に分類できます。
- **NLU(Natural Language Understanding)**による(標準の)エンリッチメント - 日本語も扱えます
-
Watson Knowledge Studioによるカスタム・エンリッチメント - 日本語も扱えます
なお、なおデフォルトモデル(NLU)とカスタムモデル(WKS)を併用したばあい、デフォルトモデル(NLU)は上書き(無視)されます。
NLUエンリッチメント
NLUはDiscoveryとは別の独立したAPIサービスであり、単独で使うこともできますが、DiscoveryはNLUと統合されており、Discoveryで「こういうエンリッチメントがしたい」と指定しておけば自動的に実行してくれます。(NLUの分の課金も不要です)
| # | 種類 | デフォ | 意味 | 例 |
|---|---|---|---|---|
| 1 | Entity Extraction | 人名/場所/会社名など | IBM / Watson | |
| 2 | Sentiment Analysis | センチメント | positive/negative/neutralの3つ | |
| 3 | Category Classification | 所定の5階層のタクソノミー | art and entertainment->radio->podcast | |
| 4 | Concept Tagging | 隠れたコンセプト | 「CERN」と「ヒッグス粒子」の文章から「大型ハドロン衝突型加速器」を導く | |
| 5 | Keyword Extraction | 文書にとって重要なキーワード | エンティティと被ることもある | |
| 6 | Emotion Analysis - |
感情 | anger/disgust/fear/joy/sadnessの5つ | |
| 7 | Semantic Role Extraction | 主語・述語・目的語の関係を抽出 | 説明が難しいのでこちらを参照 |
- Discoveryは内部的にNLUサービスを呼び出すので、使う側ではNLUは意識不要です
- 1文書の先頭の50000文字がエンリッチの対象です
- エンリッチの対象はこんな感じで事前に構成にて指定します。複数のエンリッチを同時に指定することもできます。
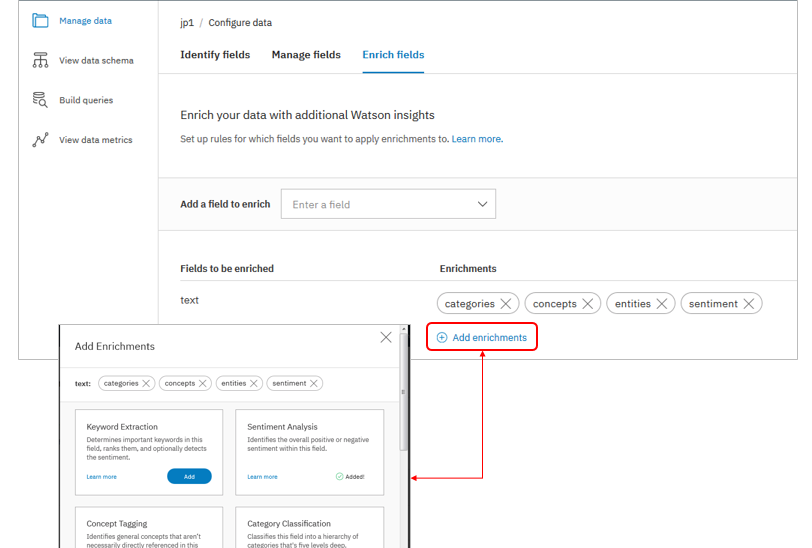
- NLUで認識できるエンティティとカテゴリーは「一般的な項目=事前にIBM側で定義された項目」だけです。(ここにNLUでどんな項目を認識するかのリストがあります)
- エンリッチと同時に0-1.0の適切さ/確信度のスコア(Relevarance)も返します
- NLUのConcept Taggingではdbpediaの知識を活用しています
WKSを用いたカスタム・エンリッチメント
Discoveryは前述のNLUエンリッチメントを内蔵していますが、残念ながらNLUでは「興味の対象=エンリッチしたいフィールド」を自由にカスタマイズすることはできません。たとえば文章中に「A123」という自社製品のパーツ名(固有名詞)があるとして、IBM側でトレーニングしたNLUは「A123」という単語に出くわしても「あ、これはお客様製品の固有のパーツ名だな!」と知る由もありません。結果、「文書からウチの製品の名称とモデル名称、パーツ名、パーツ番号を抜きたい」てなことは通常のNLUではできません。
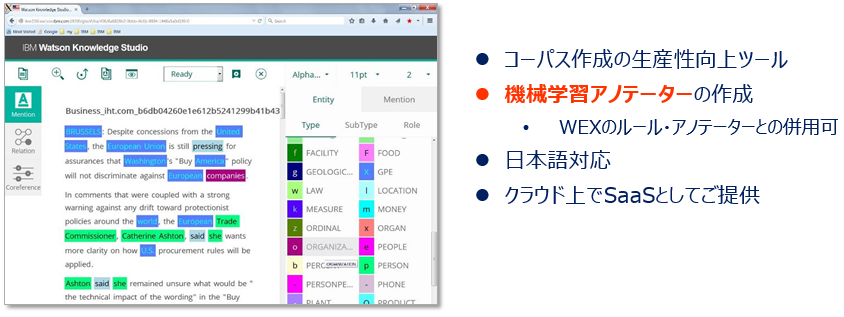
しかしWatson Knowledge Studioを使うと、これができるようになります。WKSは情報抽出(Information Extraction)のための機械学習モデル(カスタム・アノテーター)を作成できますが、このモデル(アノテーター)をWatson Discoveryに取り込んで利用することができます。(日本語もOK) これによりNLUの提供する一般的な概念モデルだけではカバーできないお客様固有の文脈に合わせた情報抽出が可能になります。「お客様固有の文脈に合わせた情報」とは、たとえば「自社の製品名・型番・パーツ#」や「部門名」「社内用語」「業界特有の言い回し」など、一般的な知識だけでは「これはXXだな」と解釈できないようなフィールドのことです。具体的には、WKSのUIツール上で「ここはウチの製品のパーツの名前だよ!」とラインマーカーで線を引くように印をつけ「PARTS」というタイプに割り当てる、といった作業(アノテーション)を行っていくと、そこから機械学習して「製品のパーツ名を抽出する」カスタム・アノテーターが作られます。
- 前述の通りエンリッチメントには様々な種類がありますが、WKS&日本語で利用できるのはEntityとRelationに関するエンリッチメントになります。詳しくはこちら
【WKSで作ったモデルをDiscoveryで利用するイメージ】
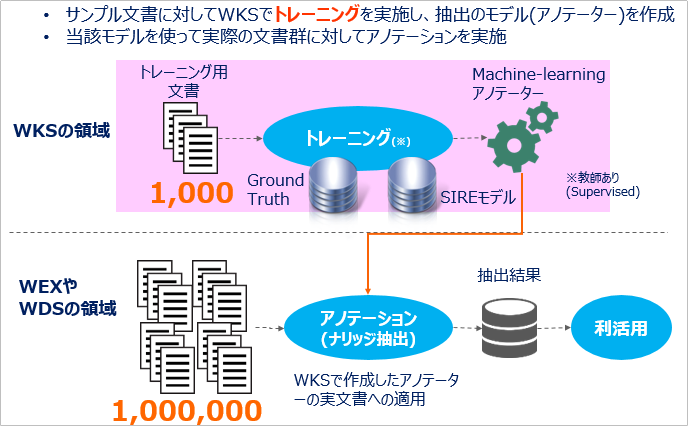
要は、業務での要件に合わせてWKSで(例えば)サンプルの1000文書をトレーニング(アノテート)して一旦独自の機械学習アノテーター(カスタム・モデル)を作ってしまえば、Discoveryではそのアノテーター(モデル)を使って100万文書からの抽出を自動的に/楽に行える、ってことです。
![]() WKSのモデルの取り込みはDiscovery Toolingからは行えません。APIを使う必要があります。(cURLで代用できます)
WKSのモデルの取り込みはDiscovery Toolingからは行えません。APIを使う必要があります。(cURLで代用できます)
Smart Document Understanding(SDU)
SDUは2019/2月にGAになった新しい機能です。「エンリッチ」とはちょっと違うのですが、毛色が似ているのでここでご紹介します。

要は構造の決まっていない文書に対して、上記のように文書を表示しながら「ここ、タイトルだよ~」とか対話式に教えてあげると、それを学んでよしなにメタデータを抜いてくれる、って話で、前掲の「Watson Knowlegde Studio」の簡易版のようなもの?と思ってます。
![]() 「Watson Discovery の新機能のベータ公開に伴い、一部UIパネルの操作が変わりました(+ちょっとだけSDUのご紹介)」で、もう少しだけ詳しくご紹介しています。
「Watson Discovery の新機能のベータ公開に伴い、一部UIパネルの操作が変わりました(+ちょっとだけSDUのご紹介)」で、もう少しだけ詳しくご紹介しています。
3) 正規化(Normalize)
インデックスを作る前の最後の調整やお掃除を行いますが、殆どの場合デフォルトでよろしいかと。
- フィールドを移動、マージ、コピー、削除
- データが無い空白のフィールドを削除するかどうか
APIを使えばCSS Selectorを書いて独自の複雑な変換を行うこともできます。
照会(Query)
(冒頭の絵を再掲しますが)照会はUIツールとAPIのどちらでも行えます
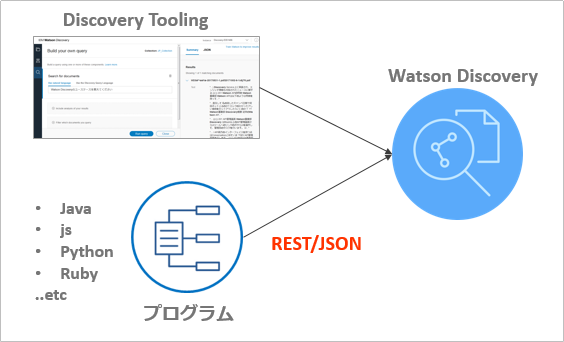
Discoveryでの照会の種類
大きくDQL(Discovery Query Language)を用いたQueryと自然言語による照会が可能です。
| 種類 | 用語 | 方法 | UIツール | API |
|---|---|---|---|---|
| 照会 | Query | DQL | ||
| 絞り込み | Filter | DQL | ||
| 集約 | Aggregation | DQL | ||
| 自然言語照会 | Natural Language Query(NLQ) | 自然言語 |
Discovery Query Language(DQL)
Collectionを照会する際にはDiscovery独自の照会言語であるDQLを利用できます。どんなものかの感覚を掴んでいただくためにいくつか例をお示しします。
| DQL | 意味 | 注 |
|---|---|---|
| text:Watson,text:Macy's | Watson 及び(and) Macy'sという単語を含む文書 | シンプルな全文検索 |
| enriched_text.entities.text:IBM | EntityのtextにIBMを含む文書 | |
| enriched_text.entities.sentiment.label::positive | センチメントがpositiveの文書 | |
| term(enriched_text.concepts.text).top_hits(10) | コンセプトのTop10 | |
| max(product.price) | 商品価格の最大値 | DBなどの構造化データ利用時 |
- 上記で
 のマークがついているものでは「エンリッチ」で追加されたフィールドに対する照会のため、日本語環境では現時点は利用できません
のマークがついているものでは「エンリッチ」で追加されたフィールドに対する照会のため、日本語環境では現時点は利用できません - 集約で面白い機能として(APIのみですが)①histogram(数値を使ってヒストグラムを作れる) ②timeslice(時系列に並べる)などもあります。なお、timesliceでは時間経過に伴う外れ値の検知(Anomary Detection)もできます
Query buildingのドキュメントにDQLの構文が掲載されています。
Visual Query Builder(VQB)
Visual Query BuilderというUIツールでDQLを組み立てられますので、慣れるまではUIツールで実行するのがよいでしょう。
Visual Query Builderでの照会はこんな感じです
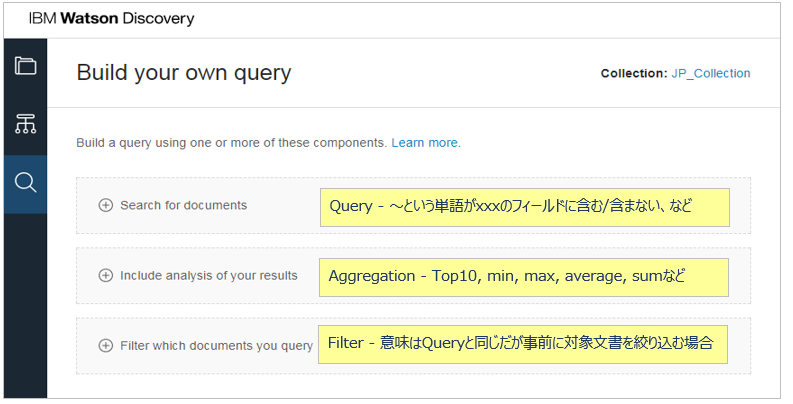
Queryの条件を指定すると下の方にDQLが表示されます
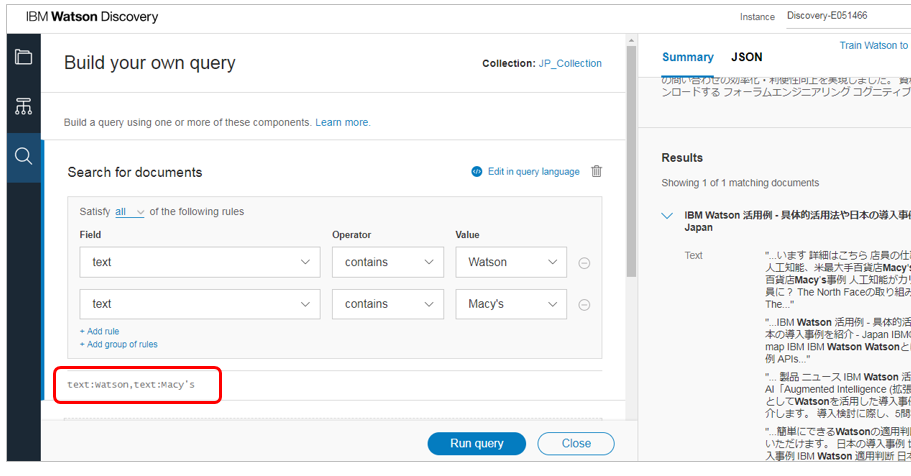
他にもオプションを指定できます
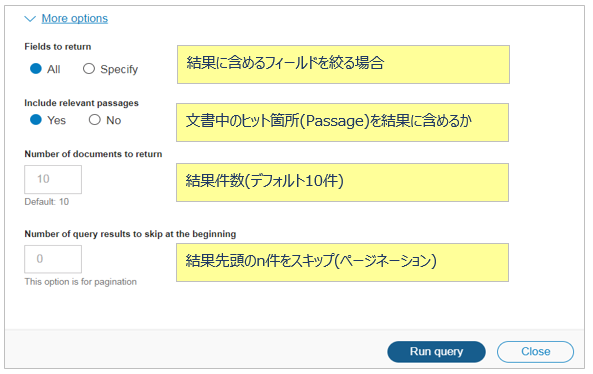
- 複数のCollectionを跨る照会はVQBでは未サポート。APIで実行する必要があります
QueryとFilterはどう違う?
Difference between the filter and query parameters
QueryとFilterは、どちらも「条件に合う文書に絞り込む」という意味で非常に似ていますが、Discoveryの仕組み上は下記の違いがあります。
| 種類 | 用語 | 結果の並べ替え | 結果のキャッシュ |
|---|---|---|---|
| 1 | Filter | 行わない(順番は保証されない) | する |
| 2 | Query | 適切(Relevancy)の高い順に並べ替える | しない |
- FilterとQueryはDQLで同時に指定できます
- 同時に指定した場合は①まずFilterが適用され②次にQueryで結果を並べ替えます
- 非常に小規模なデータセットではどちらも似たようなもの
- 大規模なデータセットではまずFilterを先に実行すべき(キャッシュで高速化が期待できる)
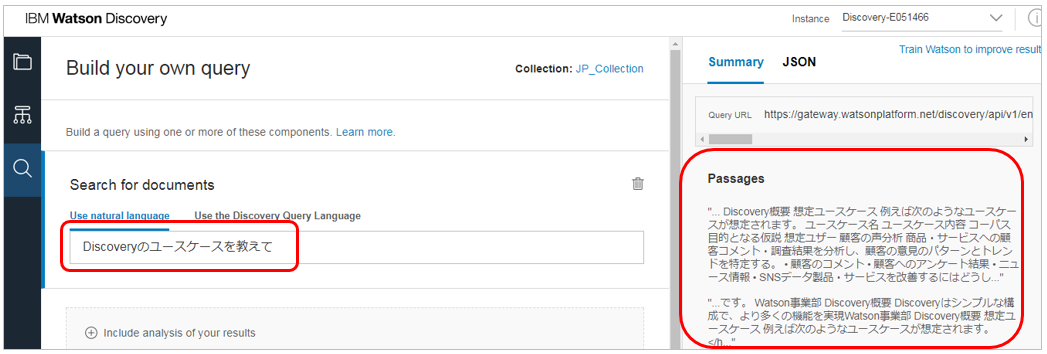
自然言語による照会( Natural Language Query)
DQLを使わず、普通の話し言葉で質問することもできます。(日本語も使えます)
以下のようにツールから入力することもできます
「この質問への回答はこっちの方が適切だよ!」( Relevancy Training )
「質問に対する回答の適切さ・優先順位のトレーニング」は従来Document ConverstionとR&Rで行っていましたが、Discoveryではより簡単になりました。今までは①DCで文書を変換 ②Apache Solrの構成 ③R&Rへの文書の登録(GT作成) ④優先度のトレーニングと様々な手順を踏む必要がありまして、正直「面倒くさい!」感じでしたが、Discoveryでは①~③は一気通貫で自動的に行われますので、文書をIngestしたら④のトレーニングをするだけで済みます。なお、Relevancy Trainingは自然言語照会に対して行うモノです。前述のDQLに対しては適用できません。
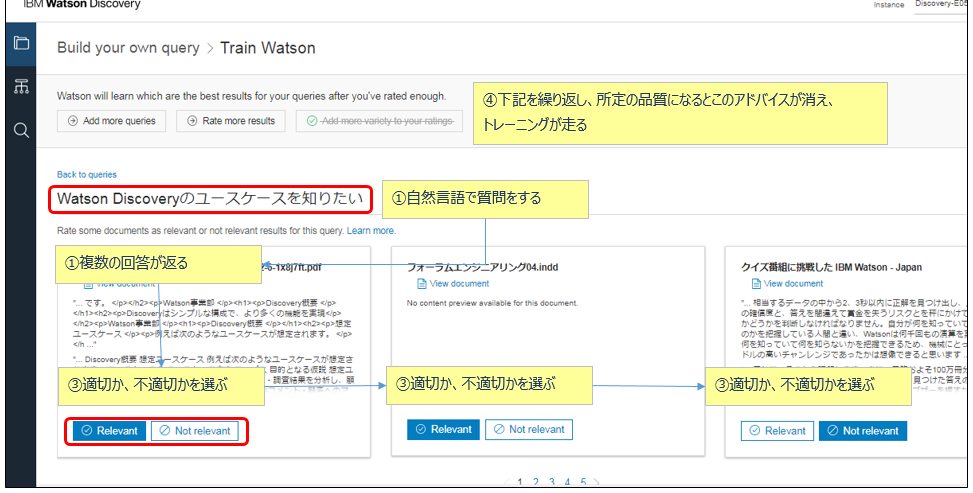
以下はトレーニングの画面例です(APIでも行えます)
- R&Rで以前提供されていたUIのトレーニングツールと同じようなもの
- 1 Environmentあたり最大4Collectionまで適用可能
- 最低でも49個の質問について適・不適を回答する必要がある
- 質問-回答作業を継続し、所定の品質に達するとパネル上部の表示が消えてトレーニングが自動的に実行される
- 質問はユーザーが実際に使った、または使うであろうものが望ましい
- 質問と回答には同じ用語が含まれるようにすると精度が上がる
- 回答の際の適切さのスコアはAPIでは0-100まで設定可能
- ただし普通は3-4段階程度であり、そこまで幅広く構えない
- UIツールではスコアは適=10 不適=0で計算する
- (無いと思いますが)もし仮にUIツールとAPIの両方でトレーニングする場合は、上記スコアのスケールを合わせておかないと、精度が引っ張られるので注意(APIで0/10/50/100のスケールを使ってしまったら、UIの0-10のスケールの影響は非常に小さいものになる)
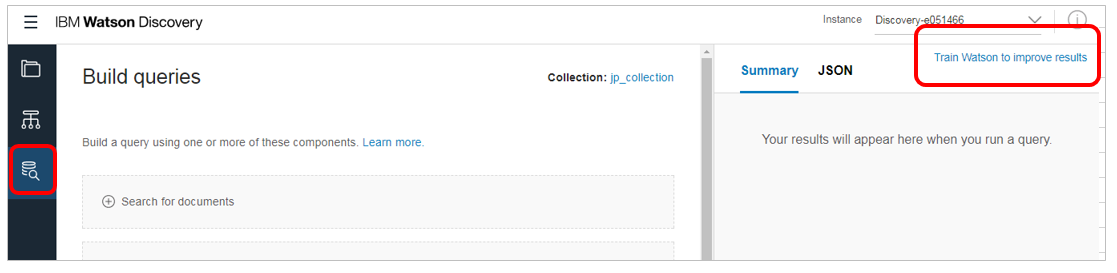
![]() (2017/12/27) ある方から「上のトレーニングの画面って、どうやって入るの?」と聞かれたので追記します。左側の「Build Query」ボタンを押して表示されるパネルの右上「Train Watson to improve results」のリンクをクリックします。(ちょっとわかりずらいですね)
(2017/12/27) ある方から「上のトレーニングの画面って、どうやって入るの?」と聞かれたので追記します。左側の「Build Query」ボタンを押して表示されるパネルの右上「Train Watson to improve results」のリンクをクリックします。(ちょっとわかりずらいですね)
トレーニングが面倒なら「Continuous Relevancy Training」
前項のRelevancy Trainingは質問/適切な回答のペアをひたすら一定量、地道にトレーニングする必要があり面倒だ、との声を反映し「勝手に勉強してくれる」モード=Continuous Relevancy Trainingができました。
-
ディスカバリーが時間の経過とともに最も関連性の高い回答を自動的に学習します
-
ユーザーとの対話から自動的に学習してディスカバリーの関連性を手動トレーニングの時間と労力を削減します
-
モデル性能を改善するために、人工的に作られたトレーニングセットではなく、実際に使われたデータを使ってトレーニングします
-
データの使われ方に沿って自動的にトレーニングを実施してモデルを更新するので、新しいトレーニングデータを手動で作成する手間を削減できます
-
有償のAdvanced plan のSmall以上またはプレミアムのご契約が必要です。残念ながら無償のLiteプランではお試しいただけません。
-
CRTはEnvironmentのレベルで有効化します。より細かいCollectionのレベルで使う・使わないの制御はできません。
-
最大でコレクション5つまでCRTを有効にできます
-
学習データは実際のユーザーのクリック・イベントです。よって事前にアプリケーションでイベントAPIを使ってイベントを記録しておく必要があります。
-
CLSの学習を起動するには最低1000個の(イベントに紐ついた)自然言語照会が必要です。イベントやログの保存期間は30日なので、30日間の間に最低1000個の(イベントに紐ついた)自然言語照会が必要です。(あまりヒマなシステムでは学習が起動しません)
「マッチするのは文書のココ!」( Passage Rertieval )
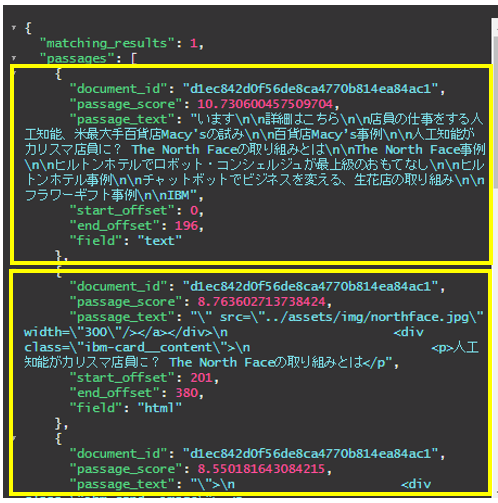
単純な「全文検索」では「キーワードを含む文書はこれ!」と文書名までは教えてくれても、次に文書内の該当箇所にたどり着くのが面倒です。Discoveryでは文書を断片(Snippet)に分解し、「該当箇所はここ!」と教えてくれます。
下記は「North Faceを含む文書」を照会した結果ですが、該当する箇所のスニペットと共に文書のid、Passageスコア、文書内でのスニペットの開始・終了位置などのメタデータも返っています。
ドキュメントの一部が古いようですが下記が新しいパラメーターです
- 1つのパッセージの長さは2000文字以内 (passages.characters)
- パッセージの対象フィールドを指定できる(passages.fields)
- 1つのQueryで返すパッセージの数を指定できる(passages.count)
![]() (2017/12/27) 以下3点は2017/11~12月の追加です。今はまだ日本語では使えませんが、今後の機能強化の方向性をお示しする意味でご参考までに。
(2017/12/27) 以下3点は2017/11~12月の追加です。今はまだ日本語では使えませんが、今後の機能強化の方向性をお示しする意味でご参考までに。
(英語のみ) Element Classification
英語のみ、かつExperimentalという位置づけですが、2017/12/15にElement Classificationが公開されました。少し前まで「Compare & Comply」と呼ばれていたユースケースを実現するもので、「準拠すべき文書と検査対象の文書の類似度合を比較(Compare)して、ちゃんと基準を満たしているか(Comply)をチェックする」ことを目指しています。例えば「この文書は必須の事項が書いてないよ!」とか、「この部分はルールに違反しているよ!」と指摘してくれたり、長~い契約書の中から「この購買契約の提供者の責務はなんだっけ?」と簡単に検索できたりするものです。「準拠すべき文書」とは契約書や法律・法令・規制であり、適用例としては法律事務所での契約書のチェック、損害保険での事故査定時の申請文書のチェック、企業の購買契約のチェックなど色々考えられます。
- Element Classificationは上記を実現するための第一段階で、「今まで単語レベルで行っていたメタデータのエンリッチメントを文章や文節レベルに拡張する」ものです。要は基盤固め、でありElement Classificationだけで最終目標である「準拠しているかどうか」までは判断できません。 当機能は2018年も段階的に強化されていくようです
- ここにデモがあります
(英語のみ) Visual Insights
こちらも英語のみ、かつExperimentalという位置づけですが、Visual Insightsというコンテンツの可視化ツールが公開されています。コンテンツにエンリッチメントで追加されたエンティティやリレーションやコンセプトなどのメタデータを基に、それらの関連を見せてくれるものです。
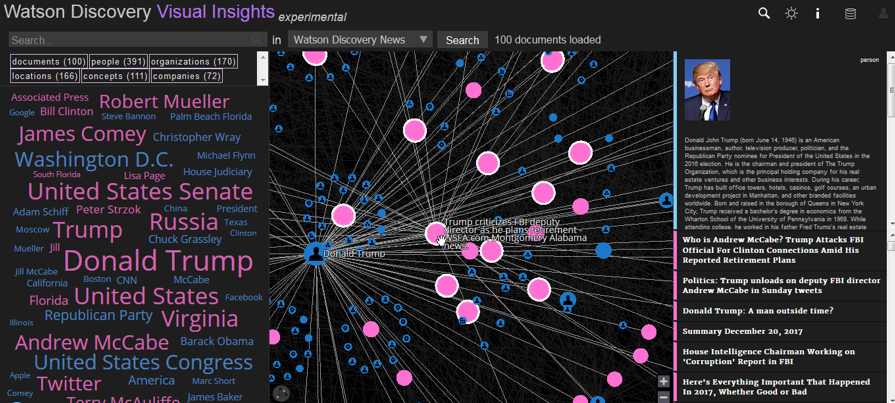
- ここから試せます
- デフォルトではDiscovery Newsのコンテンツが使えるようになっています
- ログインすればご自身のCollectionも対象にできます。ただし日本語Collectionは現在NLUエンリッチメントが未サポートのため、意味のある結果が表示されません。(WKSでエンリッチすれば使えるような気もしますが、試していません)

(英語かつAdvancedプラン限定) Knowledge Graph
英語のみのベータ、かつAdvanced(拡張)プランのお客様限定なので私も実際に触ってないのですが、Knowledge Graphという機能が出ました。
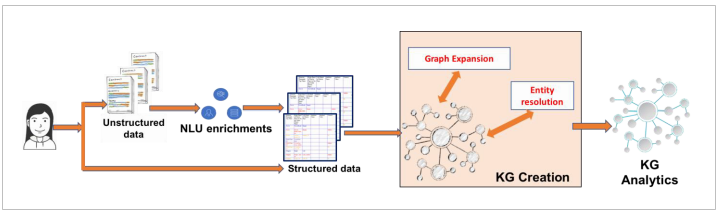
-
NLUエンリッチメントの結果を使ってエンティティ間の関連を機械学習で整理・拡張してカスタム知識グラフを構築します
-
利用者から見ると、従来の「ドキュメントに対する単語・キーワードや自然言語によるサーチ」だけではなく「関係・関連に基づくサーチ」が出来るようになります。以下はドキュメントからの例です。
- 曖昧さの回避。「Steve」のサーチで、「Apple」の文脈(context)なら「Steve Jobs」。「Microsoft」の文脈なら「Steve Ballmer」
- 回答のランク付け。「Obama」を「Health」の文脈で検索するなら「Affordable Care Act」(オバマケア)が最適、と判定
- 文書間の推論および集約からの洞察・知見。XさんとYさんはどう繋がっているか?Aさんのデータアクセスパターンは普通の人とどう異なっているか? Bさんの周囲への影響力はどのくらい?
その他
node-redのノードもありますよ!
日本語のEnvironmentやCollectionを管理するところまでは未対応ですが、Discovery-Toolingで作った日本語環境のCollectionは普通に照会できました。
Performance
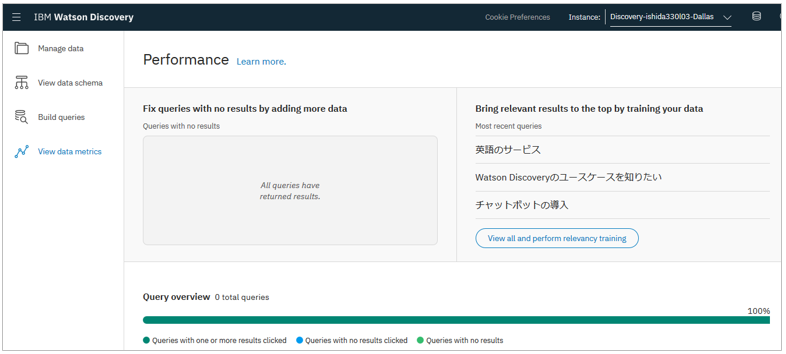
(データが少なくて恐縮ですが ) Performanceパネルでは照会の状況を見たり
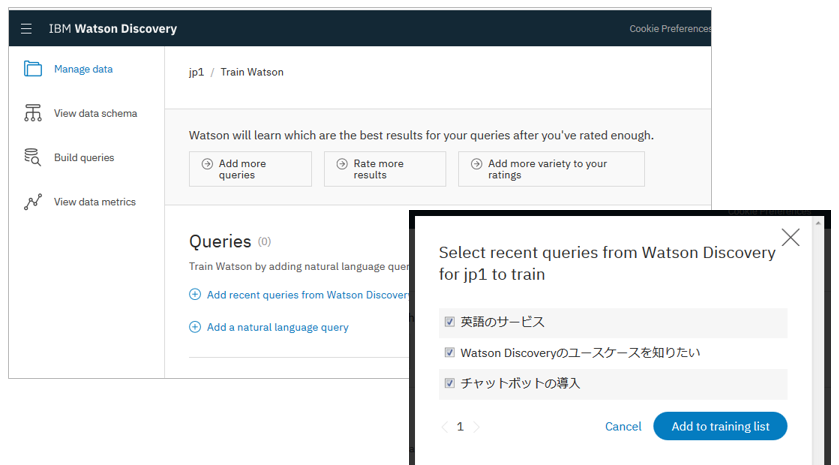
実行された照会を取り込んでRelevancy Trainingに使ったりして、検索の精度を上げることができます。
サービスのプラン
![]() 2018/07/02にブログでWatson Discovery 利用料金変更のお知らせが出ました。2018/8/1からは以下のようになります。
2018/07/02にブログでWatson Discovery 利用料金変更のお知らせが出ました。2018/8/1からは以下のようになります。
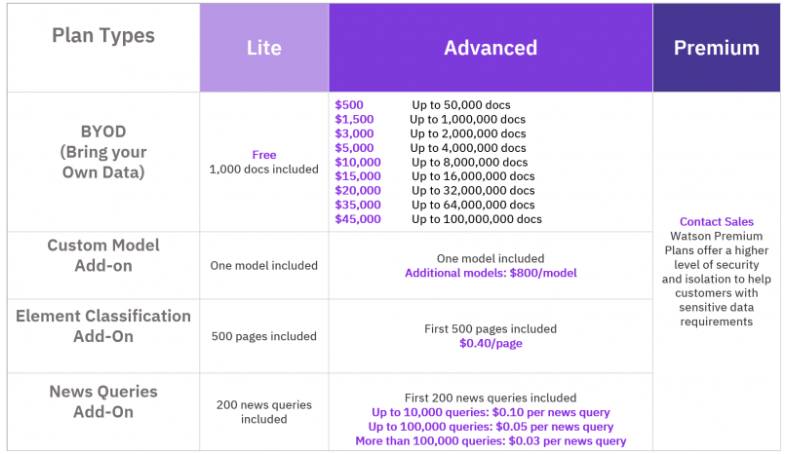
以前はプラン毎に課金の考え方や計算方法が違ってたりして計算が複雑だったので、「簡単にした」んだろうと思います。
- ライトプランの文書数上限を2000→1000に変更
- Standardプランを廃止してLite/Advanced/Premiumの3つに減らした
- 課金モデルを「文書の数」のラダーに統一(「 ~文書までなら一律xx円」という形)
IBM CloudのカタログにDiscoveryのプランや料金が掲載されていますのでご参照ください。(無償のLiteプランでは1ケ月間使わないと削除されますのでご注意ください)
参考文献
Discovery - Document
Discovery - API Reference
Discovery - API Explorer
Viewデモ
改訂履歴
Release notesみると、最近機能強化が続いているので、記事に改訂履歴をつけることにしました。本文の更新した箇所は ![]() をつけておきますね。
をつけておきますね。
| Release Notes日付 | 記事更新日 | 内容 |
|---|---|---|
| 2017/10/03 | 2017/10/06 | Document Segmentationが利用可能に |
| 2017/10/09 | インスタンス再作成要 Visual Query BuilderでHistogram と Timeslice が利用可能に | |
| インスタンス再作成要 Data schema explorer でのRun Queryメニューの追加 | ||
| 2017/10/16 | 2017/10/18 | Discovery Toolingが機能強化され画面が変更になったので記事を更新 |
| 2017/11/15 | 2017/11/17 | Discovery Toolingで日本語Collectionの定義方法が変更になったので記事を更新 |
| - | 2017/12/14 | snbsntrさんのコメント=Passage Retrievalは実際はまだ使えない点を記載 |
| - | 2017/12/27 | Element Classification他最近の機能追加を簡単に記載 |
| 2018/06/28 | 2018/06/26 | Discovery 日本語フルサポートしたことを追記(記事本体は未修正) |
| 2018/07/30 | 2018/07/31 | Discovery 日本語フルサポート&日本語ニュース&価格改定で記述更新 |
| 2018/08/02 | 2018/08/06 | Box, Salesforce, and SharePoint Online接続で日本語サポートを追加 |
| 2018/09/25 | 2018/10/11 | Continuous Relevancy Trainingとlonger query |
| - | 2019/02/14 | 全体的な見直しとアップデート |