皆様が「あれ?」と迷われるといけないので記事にしました。
TL;DR(要は)
Watson DiscoveryのRelease Noteによると、2019/1/22付けでSDU(Smart Document Understanding)という新機能のベータがリリースされました
- それに伴い、UIパネルの操作が一部変わります!
- 具体的には、コレクションの構成に関し「機能」は同じですが「定義の方法」が変わりました
- 新規にコレクションを作るときのお話です。既存のコレクションは影響ありません。
操作上で変わったところ
今まで
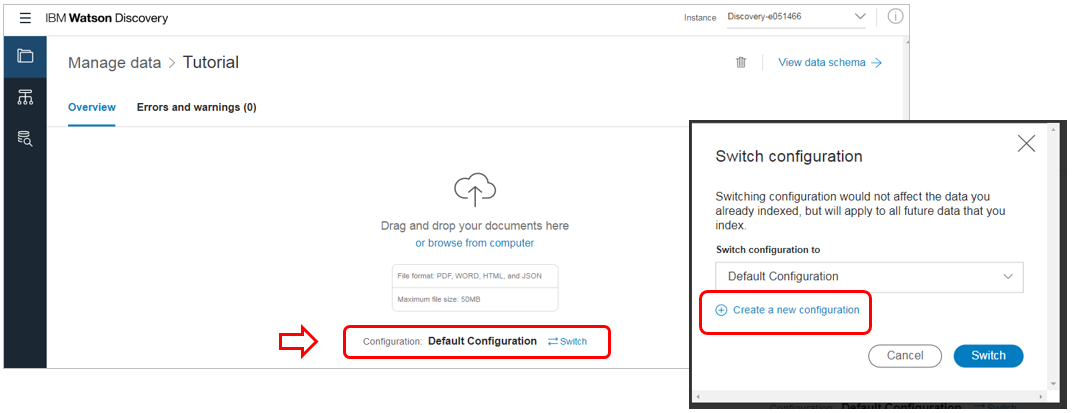
Watson Discoveryでの「構成」とは、文書の集まりである「コレクション」に対する文書変換と索引付けのルール定義です。具体的にはエンリッチメントの種類などを定義します。今まではコレクション作成時にデフォルトまたは独自の構成を定義し、名前を付けて保存できました。
今後は、「構成」の定義箇所が変わります
既存のコレクションには影響ありませんが新規にコレクションを作成する場合、構成の指定方法が変更に1なっています。
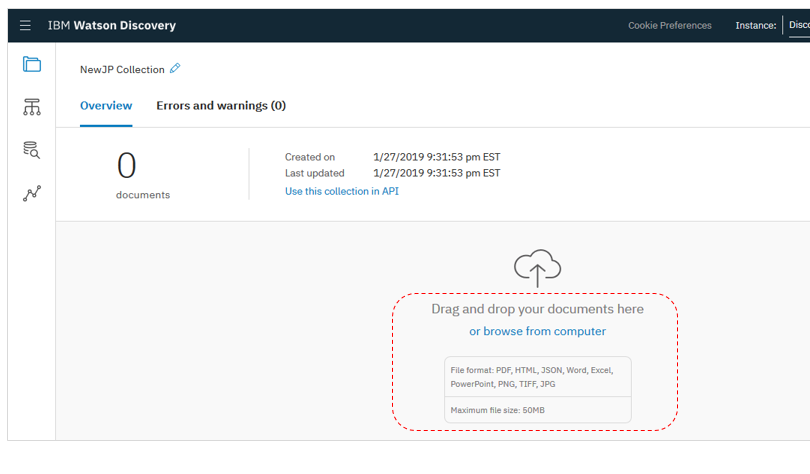
具体的には上記のパネルから「構成」を切り替えたり、定義することはできなくなっています。
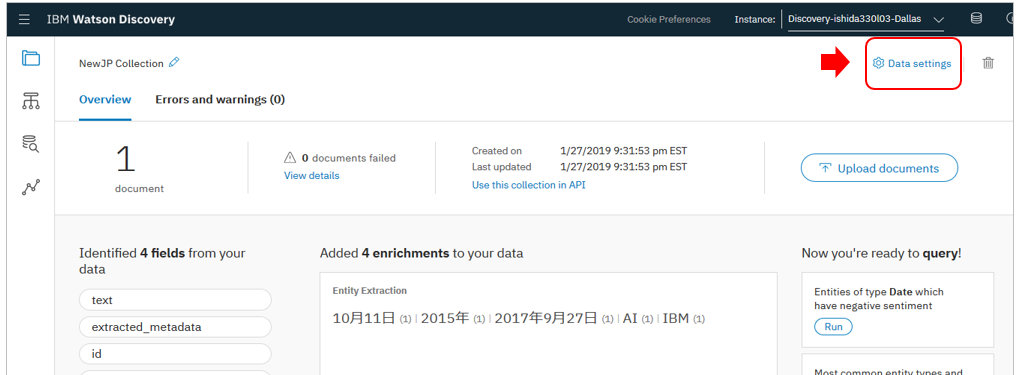
かわりに、今後は「コレクションに最低一件、データを投入すれば2」(←これ、重要!)右上に「Data Settings」のアイコンが表示されますので、ここから構成の設定を行うようになりました。
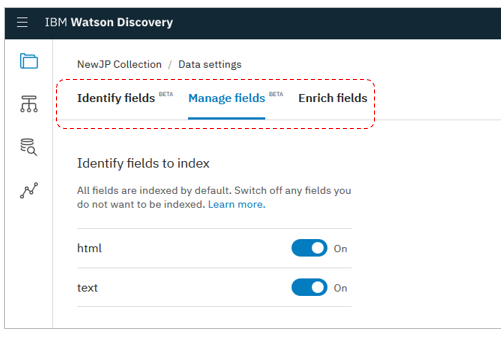
上記のようにベータ機能であるSDU機能の設定があります。
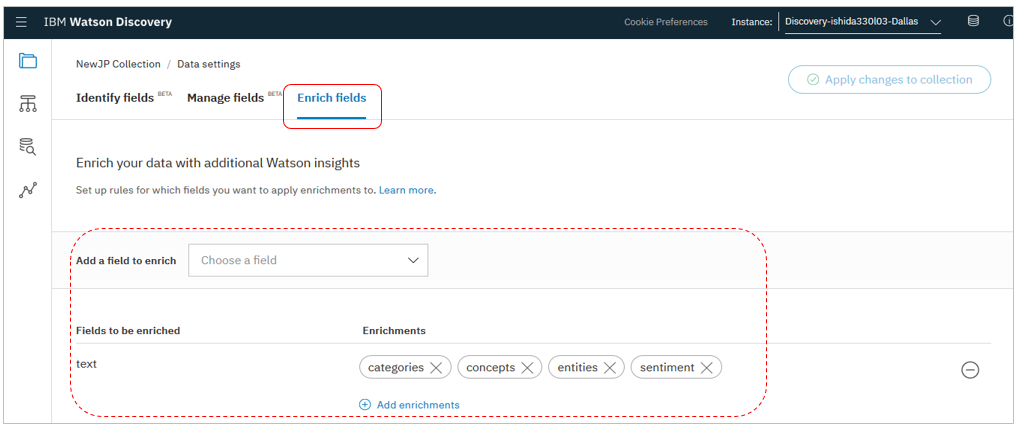
エンリッチメントのタブもあり、ここから従来同様にエンリッチメントを追加・削除できます。
- 従来のように**「名前を付けて保存する」ことはできなく**なりました。(まあ、あまり影響ないかと3思いますが)
新機能(ベータ)のSDU(Smart Document Understanding)って何?
![]() Smart Document Understandingに解説がありますが、要は
Smart Document Understandingに解説がありますが、要は
非構造化データ(文書)照会の課題
- 非構造化データの文書にはノイズ4が多い
- 照会の対象としたい範囲が限定的
- 情報がPDFやExcelの表(テーブル)の形に埋め込まれている場合がある
ために照会結果にゴミが混じったり、表の中身が検索できない、などで照会結果の精度に問題あり、というケースがままあります
SDUとは
- ドキュメントからカスタム・フィールドを抽出するための新しい方法
- 文書の構造を手軽にアノテーションしていくことで、抽出の精度を向上させる
- 新しい文書のタイプとしてパワポ(ppt)、Excel、イメージ(PNG, TIFF, JPG)5をサポート
- 表の中身やイメージ内の文字も検出
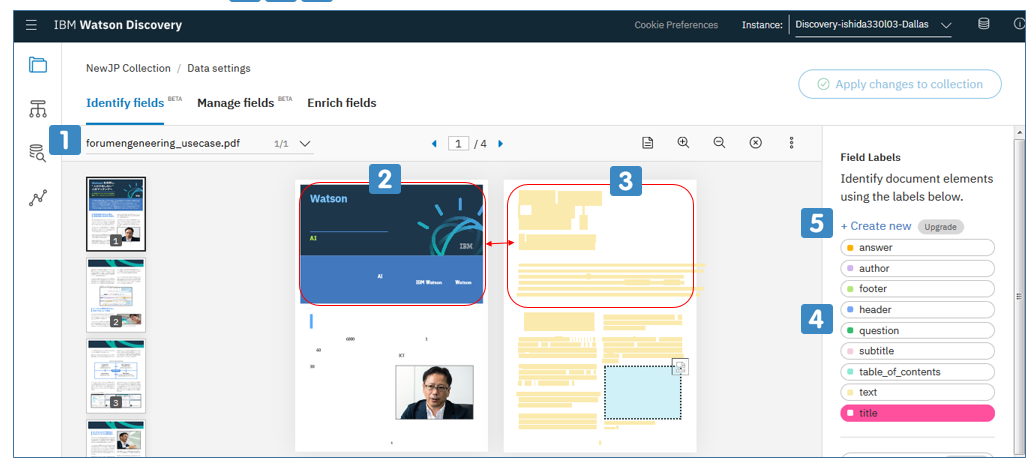
上記のように文書を表示しながら「ここ、タイトルだよ~」や「ここは質問だよ~」と対話式に教えてあげると、それを動的に学んで、よしなにメタデータを抜いてくれたり、(文書中の索引など)照会で重要でないところは無視してくれたり、章別に文書を区切ってくれたりする、、って話で、「Watson Knowlegde Studio」の簡易版のようなもの?と思ってます。下のアニメーションを見ていただけばおわかりのように、一番の利点は「ITに詳しくない普通のユーザーさんでも文書構造のトレーニングができ、結果として照会精度を改善できる」ところかと思います。
![]() アノテートする文書を選びます
アノテートする文書を選びます
![]() 文書のイメージ
文書のイメージ
![]() 左の文書イメージに対応するセクション
左の文書イメージに対応するセクション
![]() ラベル。デフォルト提供はタイトル、サブタイトル、ヘダー、などの文書構造
ラベル。デフォルト提供はタイトル、サブタイトル、ヘダー、などの文書構造
![]() カスタム・ラベル。「PartsNo」など、好きなラベルを5付けられる
カスタム・ラベル。「PartsNo」など、好きなラベルを5付けられる

上のような感じで一連のセクションにラベルを割り当てることでアノテーションを行います。まさにWatson Knowledge Studioの機能を落として簡単にしたもの、って感じですね。
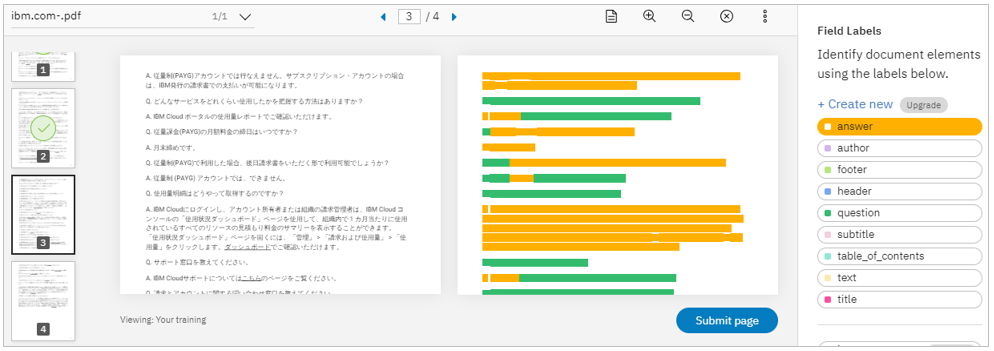
上記は4ページの日本語FAQの文書の例ですが、2ページ分をQuestion/Answerでアノテーションして「Submit Pages」ボタンを押したら、3ページ目からは不完全で間違いもあるものの、何もしていないのにQuestion/Answerのフィールドを認識し始めました。フィードバックを動的に学んでいるようです。
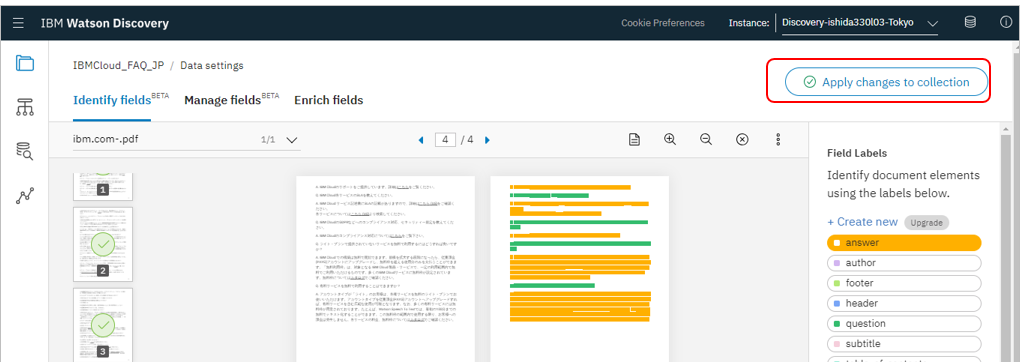
認識の間違いを直して4ページ分を完成させ、「Apply changes to collection」ボタンを押すと改めてドキュメントのアップロードを指示されます。
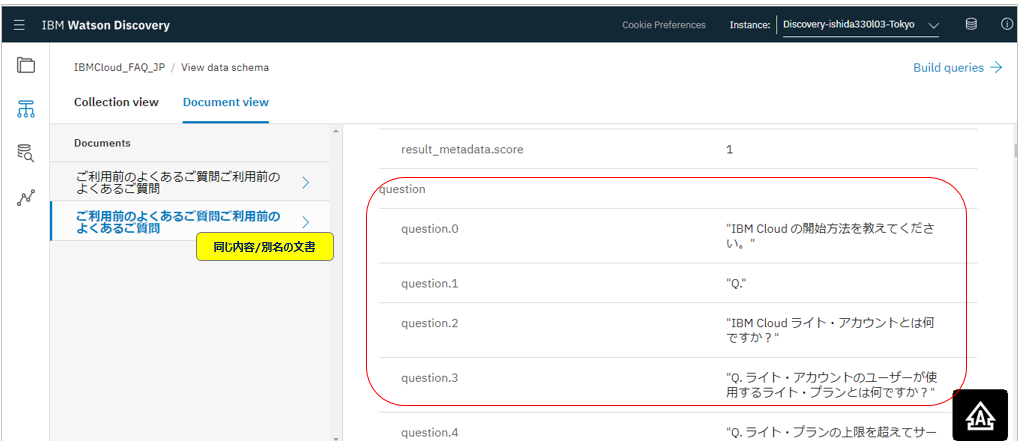
ここで便宜的に同じ内容で別ファイル名の文書をアップしてみたら、今度はQuestionやAnswerのメタデータが識別されていました。ということは、文書中の検索範囲をQuestionやAnswerに限定した条件検索ができることになります。(目次やヘダー・フッター部分のキーワードはヒットしないので、検索の精度が上がるはず。アドバンス・プランでカスタム・フィールドを使えば、検索対象をそのフィールドだけに限定できるようになる、ってことですね)
以上です。