今後、分散処理にSpark導入を検討されている方、または、少し興味がある方を対象に、
実験的に取組んだ知識を提供できればと思います。
 Apache Sparkって
Apache Sparkって
「ポストHadoopとして期待される分散処理フレームワーク」
巨大なデータに対して高速に分散処理を行うオープンソースのフレームワークです。
ポイントは、SparkとHadoopは共存できる。Sparkは一見Hadoopのように見えるが、
Hadoopを置き換えるものではなく、MapReduceを置き換えるものという理解が今のところしっくりきています。
補足)Hadoopの苦手な部分を補なえるので注目された!?
Hadoop MapReduce の弱点
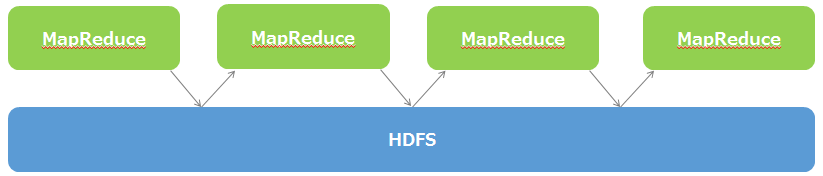
そもそも ディスクIOの並列化(分散)をベース としていることに起因。
そのため、いくら並列化をしたとしても、ディスクIOが都度都度発生するような
繰り返し処理 や リアルタイム処理 には、動作コストがかかってしまう。。。
これをインメモリで処理できるので早いのがApacheSparkの特徴!

本家サイトで謳われている通り、Sparkの特徴を挙げるとしたら。
![]() HadoopのMapReduce処理と比べた場合100倍速くなる。
HadoopのMapReduce処理と比べた場合100倍速くなる。
![]() JavaやScala、Pythonなどいろいろなプログラミング言語のAPIが用意されている。
JavaやScala、Pythonなどいろいろなプログラミング言語のAPIが用意されている。
![]() SparkSQLを使用して、SQLやHiveQLを使用した低レイテンシーのインタラクティブクエリを実行できる。(今回の注目点!)
SparkSQLを使用して、SQLやHiveQLを使用した低レイテンシーのインタラクティブクエリを実行できる。(今回の注目点!)
![]() SparkとHadoopの関係は競合関係ではない。
SparkとHadoopの関係は競合関係ではない。
![]() Sparkはデータの入出力場所としてHDFSにも対応している。
Sparkはデータの入出力場所としてHDFSにも対応している。
逆に、メモリに乗り切らない事をやる場合は導入に向かないため、
HDFSなどで一時処理させて、メモリ内で処理する部分はSparkでというのがセオリーのようです。
**(今回の注目点!)**JDBCアクセス可能なデータベースに対しデータ操作してみたい!
![]() 通常のJDBCアクセス可能なデータベースに対しても操作ができそうですね。
通常のJDBCアクセス可能なデータベースに対しても操作ができそうですね。
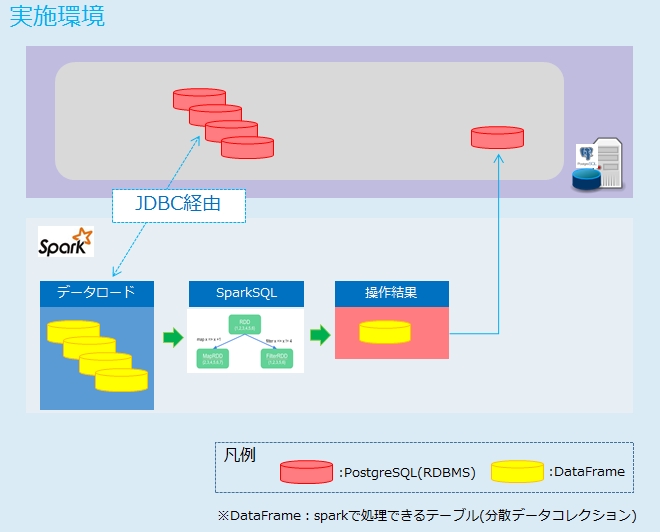
利用イメージ
- PostgreSQLのデータを用いる
- JDBC経由でデータをロードする
- 取得したデータを操作
- 操作した結果をデータロードした元に戻す
実行環境
-
Apache Spark:2.2.0
- 公式サイトよりダウンロード
- 開発当時の最新バージョンを利用しています。
-
JDBCドライバ:postgresql-42.1.1.jar
-
使用言語:Scala2.11.8
- 公式サイトよりダウンロード(画面最下部)
- 利用するバージョンはSparkに依存します。2.2.0に対応するScalaのバージョンが2.11.8
-
実行方式:spark-submitコマンドによって、ScalaソースからビルドしたJarを実行。
※Scalaを選んだ理由
- 企業が出しているSpark関連の記事にはScalaを利用するものが多かった。
- Java VM上で動作するため、既存の(膨大な)Javaライブラリを使用できる。
- コンパイルを通すことにより多人数開発でも品質が保ちやすい。
- 補足)ビルドにはSBT:0.13.15(当時の最新)を利用しましたが、コンパイルが出来れば任意のもので良いと思います。
サンプルコード
Sparkをインストールしたサーバーでspark-shellというコマンドを実行することで、対話形式でSparkの処理を実行していく事ができます。
特に触りはじめの時期に感覚をつかんでいくのに有用だったので、spark-shellを使ったサンプルコードを紹介しておきます。
サンプル処理概要:会員のみの応募履歴を取得する
前提とするRDMS
| 利用テーブル | データの用途 | サンプルコード内でのテーブル名 |
|---|---|---|
| ユーザ情報テーブル | 会員、非会員を含めたユーザ情報が保存されている | user_info_table |
| 応募情報テーブル | ユーザが応募した情報が履歴情報として管理されている | entry_history_table |
処理の流れ
- ①Sparkシェルの起動
- ②DBから『ユーザ情報テーブル』(user_info_table)のデータを読み込む > Select条件を3つ付与する > 結果を確認し、一時保存する
- ③DBから『応募履歴テーブル』(entry_history_table)のデータを読み込む > 一時保存したデータとJoinする > 結果を確認する
※{}で括った箇所については環境に応じて変更してください。
①Sparkシェルの起動
spark-shell --jars={JDBCドライバの格納場所}/postgresql-42.1.1.jar
②DBから『ユーザ情報テーブル』(user_info_table)のデータを読み込む > 絞り込み条件を3つ付与する > 結果を確認し、一時保存する。
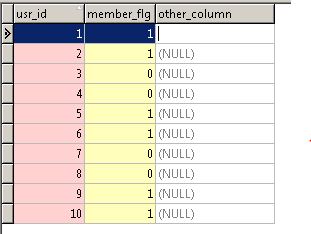
『ユーザ情報テーブル』(user_info_table)のレコード
//DB接続用のクラスをインポート
import java.sql.Connection
import java.sql.DriverManager
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
//DB接続情報セット
val ipPort = "{接続文字列(ex:192.168.1.123:5432)}"
val dbName = "{DB名}"
val dbUsrName = "{DB接続ユーザ名}"
val dbPassword = "{DB接続パスワード}"
//ユーザ情報テーブル(user_info_table)の中身をDataFrameに取得
val dfUserInfo = sqlContext.read.format("jdbc").options(Map("url" -> ("jdbc:postgresql://" + ipPort + "/" + dbName + "?user=" + dbUsrName + "&password=" + dbPassword) ,"dbtable" -> "user_info_table")).load()
//dfUserInfoに絞り込み条件を追加する。⇒変数dfMemberUsrに格納。
val dfMemberUsr = dfUserInfo.select(
//select文によりカラムを絞り込み.
$"usrId" //ユーザID
,$"member_flg" //会員フラグ(1:会員、0:非会員)
).where( //このように.でチェインして複数の条件を同時に指定することが可能。
//行を絞り込むにはwhere、もしくはfilterを利用(等価)。
$"member_flg".equalTo("1") //会員のみ
).persist //計算が実行された際に、この中間結果を保持する。(デフォルトではメモリ上に保持)
//dfMemberUsrの内容を表示する
dfMemberUsr.show
dfMemberUsr.showの実行結果

③DBから『応募履歴テーブル』(entry_history_table)のデータを読み込む > 一時保存したデータとJoinする > 結果を確認する。
『応募履歴テーブル』(entry_history_table)のレコード
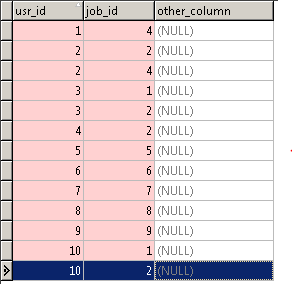
val dfEntryHistory = sqlContext.read.format("jdbc").options(Map("url" -> ("jdbc:postgresql://" + ipPort + "/" + dbName + "?user=" + dbUsrName + "&password=" + dbPassword) , "dbtable" -> "entry_history_table")).load()
//※応用:repartitionによりマッチングに利用するusr_idごとにパーティションを切りなおす
val dfRepEntryHistory = dfEntryHistory.repartition($"usr_id")
//usr_idをキーに会員ユーザ情報と応募履歴をJoinする
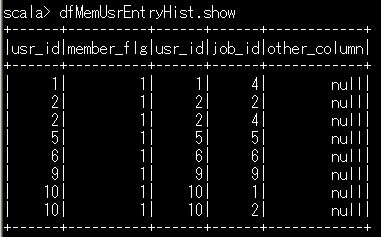
val dfMemUsrEntryHist = dfMemberUsr.join(dfEntryHistory,dfMemberUsr.col("usr_id") === dfEntryHistory.col("usr_id"))
//会員ユーザのみの応募履歴情報が確認できる。
dfMemUsrEntryHist.show
dfMemUsrEntryHist.showの実行結果
DataFrameの利点や操作の勘所など
- Dataframeの利点は、
SQL風の文法で、条件に該当する行を抽出したり、Dataframe同士のJoinができる。 - 更に、これらはSparkがクラスタ上の各ノード・各CPUで並列処理してくれる。(上記サンプルコードの各SQLも並列実行されています!)
- filter, selectというmethodで、条件に該当する行、列を抽出できる。
- persistの利用 ※DataFrameと言っても中身はRDD、プログラム途中でpersistはしておいて問題ない。
- repartitionによるマッチング高速化。
まとめ
DataFrameを使っての分散処理のサンプルのイメージが掴めたでしょうか。
DataFrame自体がテーブルのようなデータ構造をもった分散処理用データセットなため、SQLを使うように可読性の高いコードで記載していく事が可能です!
更に、ある程度勝手に分散処理をしてくれるというメリット付。
RDDベースで処理を最適化するためには、Sparkの処理に適したロジックを考えなければならないのに比べ、DataFrameの場合は、Catalystオプティマイザの仕組みによって、効率の良い処理へ自動的に内部で組み替えてくれるのも導入の敷居が下げてくれているような気もします!
とりあえず分散処理やApacheSparkを試してみたいという方への助けになれば。