グラレコ
AI Engineering Summit Tokyo 2026(Summer)の 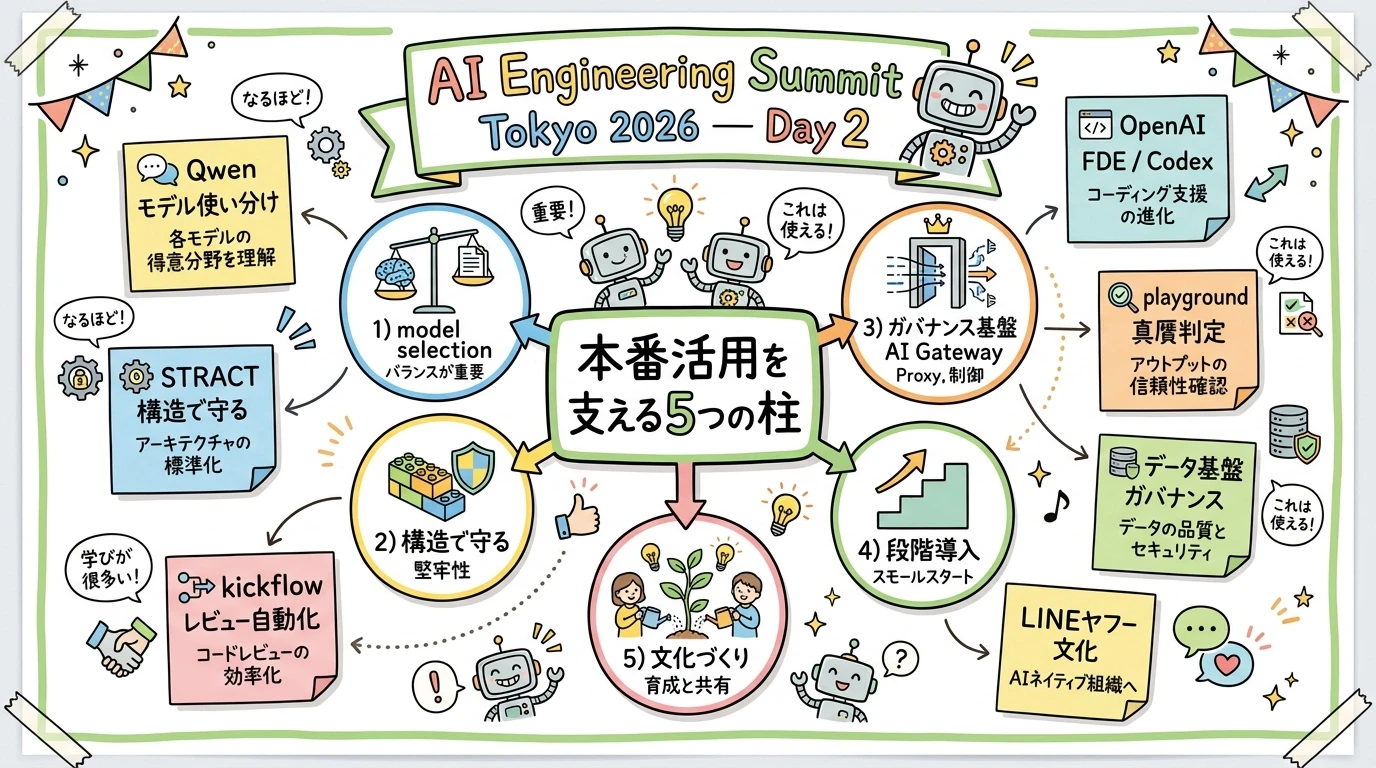
はじめに 🎯
2 日目(2026/06/09)に聴講した 7 セッションのレポートです。1 日目が「AI で作れることは前提になり、論点は運用・統制へ移っている」という大きな流れだったのに対し、2 日目はその「本番活用」を支える具体——モデルの使い分け、失敗を構造で潰す設計、ガバナンス基盤、そして AI 駆動開発を組織の「文化」にする取り組み——が、それぞれの現場から立体的に語られました。
業種は、クラウドベンダー、コマースアプリ、エンタメ DX、データ基盤、ワークフロー SaaS、大規模 Web サービス、そして OpenAI と幅広く、立場も CTO・テックリード・現場エンジニアとさまざまでした。それでも共通して聞こえてきたのは、「prompt(お願い)に頼らず、構造で守る」という設計思想と、「AI に任せる範囲を、実績データを見ながら段階的に広げる」という運用観でした。
この記事で分かること:
- 🧭 2 日目を貫く共通テーマ(本番活用を支える 5 つの柱)
- 🧩 モデルを「性能」ではなく「タスク特性」で選ぶ考え方(Qwen の使い分け)
- 🏗️ 「失敗を構造で消す」E2E AI-Native 開発基盤の実例(20 名で 100 億円規模)
- 🔐 AI ガバナンスと AI Gateway、ユーザー代理認証という統制の勘所
- ⚙️ コードレビュー自動化を「決定論的なガードレール」で安全に回す設計
- 🌱 AI 駆動開発を「文化」にする学習ループ(LINEヤフー ODW)
- 🔄 OpenAI が語った FDE と、Codex を中心とした outer loop
🧭 2日目を貫いたテーマ:「本番活用」を支える5つの柱
個別セッションに入る前に、全体像を先に置きます。2 日目の話を並べると、「本番で使えるエージェント」を支える要素が次の 5 つに整理できました。
この図のポイントは、どのセッションも「モデルが賢くなれば解決する」とは言っていないことです。賢さの外側にある設計——使い分け・構造・統制・段階・文化——をどう作るかに、各社の知見が集中していました。聴講した 7 セッションは次のとおりです。
| # | セッション | 登壇者(所属) | 主題 |
|---|---|---|---|
| 21 | Qwen×Happy Horse に学ぶ AI 選定戦略 | 藤川 裕一 氏(アリババクラウド) | タスク特性によるモデル使い分け |
| 22 | 20人で100億円規模コマースアプリの E2E AI-Native | 宇佐美 ゆう 氏(STRACT) | 失敗を構造で消す開発基盤 |
| 23 | 推しのライブを進化させる AI 駆動開発 | 伊藤 圭史 氏 / 舟口 翔梧 氏(playground) | AI ネイティブな組織と真贋判定 |
| 24 | "作る"から"本番活用"へ — データ基盤 | 真嘉比 愛 氏(ちゅらデータ)/ 大内山 浩(Databricks)/ 開 功昂(Findy) | ガバナンスとデータ基盤 |
| 25 | 開発フローに AI エージェントを組み込む | 森本 勝哉 氏(kickflow) | コードレビュー自動化と決定論的土台 |
| 26 | AI 駆動開発を文化にする | 平野 敬祐 氏 / 井上 雄飛 氏(LINEヤフー) | ボトムアップの学習ループ ODW |
| 27 | Forward Deployed Engineering at OpenAI | Ryan Cain 氏 / Sean Saito 氏(OpenAI) | FDE と Codex の outer loop |
1️⃣ Qwen×Happy Horse に学ぶ、AI選定戦略(アリババクラウド)
2 日目の最初は、アリババクラウドの藤川さんによるモデル選定のセッションでした。出発点は明快で、「性能だけで選ばない」。単一のクローズド大規模モデルだけに頼ると、非効率・API 利用料の高騰・個別要件へのファインチューニング不可、という問題が出ます。代わりに、次の 4 軸でモデルクラスを決めるべきだと示されました。
この図のポイントは、「すべてに高性能モデルは不要」という割り切りです。適材適所の配置こそが、コスト効率と ROI を最大化する鍵だと語られました。
その文脈で紹介されたのが Qwen です。Qwen はオープンウェイトモデルの普及による「AI のコモディティ化」を象徴するモデルファミリーで、300 以上のオープンウェイトモデル、10 億ダウンロード、20 万以上の派生モデルがあるとされました。最新モデルの使い分けは次のとおりです。
| モデル | 立ち位置 | 特徴(登壇時点) |
|---|---|---|
| Qwen3.7-Max | 性能最優先 | 最先端コーディングエージェント、長時間の自律実行、複雑な推論 |
| Qwen3.7-Plus | バランス重視 | 1M コンテキスト、画像・動画マルチモーダル、201 言語対応 |
| Qwen3.6-Flash | コスト最優先 | 1M コンテキスト、コンテキストキャッシュ、大量バッチ処理 |
価格例として、2026 年 5 月時点の International リージョンで Max が入力 $2.5 / 出力 $7.5(per 1M)、Plus が入力 $0.4 / 出力 $1.6、Flash が入力 $0.25 / 出力 $1.5 と紹介されていました。バイブコーディングのコスト最適化では、通常タスクを Qwen で低コスト化し、複雑な推論だけ他社モデル、長文脈は Qwen の 100 万トークンで対応、とタスク難易度別に複数 LLM へ振り分ける例が示されました。
アリババクラウドは、テキストの Qwen に加え、動画・画像生成の Wan、音声系の Fun、AI エージェント搭載 IDE の Qoder まで全方位で展開しています。
| 系統 | 内容 |
|---|---|
| Qwen | LLM・マルチモーダル・専門モデル(VL / Omni / Image / Audio / Coder / Embedding 等) |
| Wan | 動画・画像生成(Text-to-Video、Image-to-Video、inpainting、sketch-to-image 等) |
| Fun | 音声系(CosyVoice = TTS、Fun-ASR = ASR) |
| Qoder | AI エージェント搭載のスマート IDE / PC 上で動く QoderWork |
動画生成の HappyHorse 1.0 は「世界 No.1 AI ビデオ生成モデル」として、1080p HD・最大 15 秒生成が紹介されました。運用面では、基盤モデル API プラットフォーム Model Studio(メータリング・課金、権限管理、レート制限など)や、GPU を 82% 節約・処理遅延を 97% 削減できるとする GPU 最適化技術 Aegaeon も語られました。データは国内 Alibaba Cloud データセンター内で完結し、日本法・コンプライアンスに準拠する、という国内要件への配慮も強調されました。
💡 締めの「勘所」は 3 つでした。性能でなくタスク特性で選ぶ/1 モデルに頼らず役割で組み合わせる/API 層で疎結合にして差し替え可能にし、既存システムへ段階的に統合する。1 日目から続く「使い分け」の話が、具体的なモデル名で裏づけられたセッションでした。
2️⃣ 20人で100億円規模コマースアプリ事業を作る E2E AI-Native のリアル(STRACT)
AI ショッピングアプリ『PLUG』が 20 名で年間流通額 100 億円規模に達した——その裏側を、宇佐美さんが「E2E AI-Native」という設計思想で語りました。中心にあるのは、強烈な一言です。「“気をつけろ”を prompt に書くな、構造で消せ」。
prompt は「お願い」でしかなく、LLM の解釈に依存すると非決定的に破られます。だから force push、direct merge、費用超過、危険コマンド、範囲外変更などは、prompt ではなく、型・スキーマ・コード・権限・ブランチ保護・ハーネスで「できない状態」にする、という考え方でした。
開発基盤の作りも具体的でした。GitHub/Linear の webhook を Orchestrator が受け、Claude Agent SDK の Worker を git worktree ごとに起動します。「1 Issue = 1 worktree」なので、並列実行・失敗時の再開・干渉防止がしやすい設計です。
HITL(Human-in-the-loop)の捉え方も学びでした。HITL は「人に聞く」だけでなく「勝手に進ませない」ための構造です。エージェントが AskUserQuestion を発行すると、PreToolUse hook が質問を Linear へ転送してセッションを停止。最大 7 日待ち、返答が来たら resume するため、待機中の費用は発生しません。承認が取れないのに自律モードを理由に実装へ進んだ事故があり、承認ゲートは prompt ではなく file write・commit・run tests などの決定的なハーネス層に寄せるべきだ、と語られました。
実際の失敗事例も率直でした。
- Approval: plan 後に承認が取れないのに実装へ進んだ。強い prompt を足しても再発 → 承認なしでは次 phase に進めない構造が必要。
- State: agent が「commit を作成しました」と言っても marker がなく止まった → 言葉でなく git state を見て、正常終了・commit あり・未保存変更なしを確認して push する。
- Evidence: tests green や「確認しました」は UI が動く証拠ではない → build 後に Simulator/Chrome で実行し、録画 clip を Linear に残してレビュー可能にする。
失敗管理はログ化して潰し込み、失敗ログ 86 件のうち 69 件は構造で eliminate(承認ゲート、git 事実判定、範囲外チェックなど)、残りの曖昧な判断は HITL や prompt 改善で mitigate したそうです。SDK/API はドキュメントを信じ切らず、総検証スクリプト 36 本で docs unclear/drift を先に潰す、という徹底ぶりでした。
💡 Takeaway は明快でした。「prompt を厚くするより、失敗できない構造・決定的な状態確認・証拠の記録を先に作る」。そして最終的には開発だけでなく、Ops(scoped token で下書き作成までに制限し人間承認後に反映)やスライド作成まで、全業務を AI-Native にしていく方向だと語られました。
3️⃣ 推しのライブを進化させる! AI駆動開発(playground)
電子チケット発券サービス MOALA を提供する playground は、エンタメ人脈ゼロから技術力だけで国内 No.1 シェアに到達した会社です。伊藤さん・舟口さんのセッションは、「AI ネイティブな会社にゼロベースで作り直す」という組織改革と、その余白で挑むクリエイティブエンジニアリングの話でした。
象徴的なのは、「AI フル活用」ではなく「AI が主役の会社」へ、という言い回しです。人同士の情報共有ではなく AI 経由でファイル共有し、人間が説明して終わりではなく AI が参照・再利用できる形で残す。専門別の分業ではなく一人で成果を出す体制へ移し、入力もキーボードから音声へ移行したそうです。開発プロセスの変化は数字で示されました。
| 指標 | 状況(登壇時点) |
|---|---|
| Figma → フロントエンドコード化率 | 90% |
| テスト自動化カバレッジ | 95% |
| 障害調査時間 | 自動検知でほぼゼロ |
| Web フロントのフルリファクタ | 従来比 5 倍速で完了 |
| 開発チームの Condition Survey | 「満足」→「大満足」へ改善 |
このカルチャーを象徴するのが、顔認証の自社開発でした。顧客ヒアリングでは「ニーズはない」「絶対提案しない」「来場者が嫌がる」と酷評されたそうですが、それでも未来を信じてイベント業界特化の顔認証技術 BioQR を自社開発。いまでは超大型フェスやドームクラスの興行で年間数百万枚規模で使われ、来場者が導入興行を称賛するサービスに育ち、米国・欧州を含む世界各国で特許も成立済みとのことでした。「目の前の顧客を喜ばせる」ではなく「5 年後の市場を驚かせる」価値に傾倒する文化が、土台にあります。
後半は「AI がなければ挑戦しなかった技術」の話でした。スマホ画面の「見た目」だけでは真贋判定できず、スクリーンショットでの QR 転売や AI による画面偽造が課題になっています。従来見積もりでは 72 人月(3 人 × 3 年)で、成功も不確かなため先送りされていた領域です。現場ではスタッフが 1 秒以内に判定する必要があり、通信もさせられません。
そこで、特許出願済みの仕様として「時間経過で完全ランダムに変化する記号 & 色」を表示し、通信不要なのにすべての正しい端末で表示が同期される仕組みを作ったそうです。偽造防止として、表示内容を非保持化して「盗むものがない」状態にし、Web アプリ側でも WebAssembly で専用 VM を作って復元しにくくする、という徹底ぶりでした。
💡 印象的だったのは、AI 活用の論点の整理です。「いまの AI 活用は工数削減目的が大半だが、本質的には“AI がなければ作れなかった技術”を作れるようになることだ」。効率化の先にある創造性に踏み込んだセッションでした。
4️⃣ AIエージェントは"作る"から"本番活用"へ ── データ基盤が支える次のステージ(ちゅらデータ/Databricks/Findy)
ちゅらデータ・Databricks・Findy の 3 社による、データ基盤とガバナンスのセッションです。出発点は「PoC は急速に広がったが、“本番で使える”エージェントに到達できている企業はまだ多くない」という現実でした。紹介された数字が、それを裏づけます。
| 指標(登壇で紹介) | 数値 |
|---|---|
| パイロットの 40% 以上を本番移行できた企業 | 25% |
| エージェントのガバナンス体制が「成熟」と答えた企業 | 21% |
| 2027 年末までに中止見込みのエージェント型 AI プロジェクト | 40% 超 |
本番品質へは段階的に上げる必要があり、業務適合性・出力品質・ガバナンス&安全性・運用性&スケーラビリティ・コスト効率の 5 観点が示されました。そして「賢くなったエージェントが現場で使えない理由は、知能ではなくコンテキスト不足」という指摘が核心でした。社内データに「先月の売上は?」と聞いても、自社にとっての売上の定義・指標・ルールを知らないと、それっぽいが間違った数字を返します。ここで効くのがセマンティックレイヤー(テーブル・カラム・生の値に意味・指標・関係性を定義し、エージェントに文脈を供給する層)でした。
ガバナンスの話も具体的でした。AI エージェントのデータアクセスは急速に広がる一方で制御が追いついておらず、紹介された数字は次のとおりです。
- AI エージェントは 82% が導入済みという前提で、80% の企業が意図しないアクションを経験
- 内訳: 未認証システムへのアクセス 39% / 機密データへの不適切アクセス 33% / 機密データのダウンロード 32% / 機密情報の不適切共有 31%
- ガバナンスを導入している企業は 44% に留まる
推奨された設計が「エージェント + ユーザー代理認証」です。エージェントにスーパー権限を持たせるとユーザー権限外のデータにもアクセスできてしまうため、エージェントがユーザー権限を引き継ぐ形にして、意図どおりのアクセスを担保します。さらに、乱立する「Agent Sprawl」に対しては AI Gateway / Agent Gateway(例: Unity AI Gateway)のような Proxy 層が必要だと語られました。
この図のポイントは、エージェントを個別に放流するのではなく、Proxy 層で集約してガバナンスを効かせることです。締めでは、AI ガバナンスは「あった方がいい」から「必須」へ移り、AI Gateway が標準装備の時代になる、という業界観が共有されました。
5️⃣ 開発フローにAIエージェントを組み込む設計と運用の実際(kickflow)
ワークフロー SaaS の kickflow から、森本さんが「コードレビューに AI エージェントを本番投入した」実践を共有しました。方針は「人間の判断が不要な開発業務は AI に任せる」。前提は GitHub、GitHub Actions、Claude Code、CodeRabbit、Renovate で、当時 1 チーム 6 名・モノレポ・ほぼ毎営業日リリースという環境でした。
課題は、AI コーディングで PR 数が増え、人間が全 PR をレビューする運用が限界になったことです。そこで、AI が PR ごとに影響度を自動判定し、CI 内で XS/S/M/L/XL のラベルを付与。ラベルごとにレビュー担当を分けました。
| ラベル | 内容の例 | レビュー方針 |
|---|---|---|
| XS | typo、コメント、設定値変更 | オートマージ |
| S | i18n、テスト追加、小規模バグ修正 | CodeRabbit レビューで OK(人間は補助的) |
| M | 単一機能の追加・改修 | CodeRabbit + 人間レビュー |
| L | 複数機能、DB、API 仕様変更 | CodeRabbit + 人間レビュー |
| XL | 認証、不可逆な設計 | CodeRabbit + 人間レビュー |
過去 PR を判定ロジックで評価したところ XS+S が 65% で、人間レビューは最大 35% に抑えられる見込みだったそうです。重要なのは、非決定的な AI 判定を、決定論的な土台で受け止める設計でした。
この図のポイントは、非決定的な A/B(AI 判定・AI レビュー)を、決定論的な C/D/E(CODEOWNERS・Branch Protection・オートマージ)で受け止めることです。AI が影響度判定を間違えても、全 PR で必ず走る CodeRabbit が最終防波堤になり、高リスク領域は CODEOWNERS で必ず人間に回ります。
実装では想定外もありました。GitHub 標準オートマージ + Required status checks では静的に指定した CI しか見られず、早すぎるマージや pending 固定が起きたため、別ワークフローの完了を検知して実際に実行された全ジョブを取得し、全部成功ならマージする自前のワークフローを作ったそうです。導入も段階的で、まずラベル判定だけ運用 → XS のみオートマージ → S を人間レビュー必須から外す → XS も CodeRabbit を通す、という順に任せる範囲を広げました。
💡 効果は数字に出ました。同じ小さな PR(impact/XS・S、QA フェーズなし)がマージされるまでの中央値は、約 5 時間から 26 分へ短縮。学びは「AI に任せる範囲は推測でなく実績データで線引きする」「暴走は決定論的ガードレールで止める」「いきなり広げず目検で確かめながら段階的に」でした。
6️⃣ AI駆動開発を文化にする:ボトムアップの熱量とワークショップ(LINEヤフー)
LINEヤフーの平野さん・井上さんは、「AI 駆動開発を文化にする」取り組みを現場視点で語りました。難しいのはツール導入ではなく行動変容です。トップダウンで方針があっても、現場では「何が正しい使い方かわからない」「このツールを使ってよいのか迷う」「個別に解決しても知見が共有されない」が起きます。必要だったのは、方針を「試せる学習ループ」に変換することでした。
その中核が ODW(Orchestration Development Workshop)です。講義ではなく、登壇者の手元と開発プロセスを追体験する Workshop 形式で、定例開催・全社横断 Guild でテーマ選定・JP/KR/EN で全社展開する設計になっています。
この図のポイントは、「見る → 試す → 振り返る → 再利用」のループに加えて、アーカイブと再利用の導線まで含めて設計していることです。成果は数字で示されました。
| 指標(LINEヤフー ODW、登壇で紹介) | 数値 |
|---|---|
| PAT 未利用率(4 か月で改善・2026/1 時点) | 53% → 33%(約 20pt 改善) |
| PAT 未利用率(非参加者 vs 参加者・2025/12 時点) | 54.6% vs 20.9% |
| 実質総リーチ / Git アクティブ層への到達 | 4,712 / 92.8% |
| 満足度 / NPS / Hands-on 参加者数 | 4.04/5.0 / +25.2 / 4,123 |
文化づくりの設計原則は 3 つ——Learning loop(方針を試せる体験に変える)、Spread, not only usage(導入率だけでなくロングテール到達を見る)、Local autonomy(正解を固定せず各自の引き出しを増やす)でした。「AI 駆動開発を広げるとは、全員を同じやり方に揃えることではなく、試行錯誤が続く仕組みを作ること」という言葉が、このセッションの芯でした。
個人からチームへ広げるときのギャップも率直でした。個人では「AI に相談する」までできていても、チームでは「1 つの作業を任せきる」「PR として完結させる」が浸透していなかった。ハードル(自信がない・時間が取れない・情報を追うのが大変・社内ルール)は「見せる」という 1 つの手段で同時に下げられる、として、画面ごと共有しチャット履歴も渡す取り組みが紹介されました。
💡 利用普及の先の数字も強烈でした。「AI だけで作成した PR」(手でコードを書かず Agent への指示の繰り返しだけで作る PR)の割合は、2025 年 10 月の 1.7% から 2026 年 5 月には 79.5% まで伸びたそうです。一方で利用量には上位・下位で数倍の差があり、「タスクのゴールを遠くに置く」「任せきる」がまだ十分でない、という課題も共有されました。引き上げ方は、目標共有・試行錯誤・引き出しを増やすの 3 本柱で設計しているとのことでした。
7️⃣ Forward Deployed Engineering at OpenAI(OpenAI)
2 日目の最後は、OpenAI の Ryan Cain さん・Sean Saito さんによる FDE のセッションでした。LLM の性能は短期間で飛躍的に伸びている一方、モデル性能と企業で実際に創出される価値の間にはギャップがあります。OpenAI の FDE(Forward Deployed Engineer)は、顧客とプロダクト・リサーチの間に入り、このギャップを埋める役割です。企業への導入・実装と、現場で得た学びを研究へ戻すフィードバック——この好循環を作ります。
刺さったのは、「AI 開発ツールは“実装支援”に留まりがち」という指摘でした。ほとんどのツールは Build(コード実装)の支援に集中していますが、開発者が実際にコードを書いている時間は約 16% に過ぎません。Plan・Design・Test・Review・Document・Deploy まで含めた開発プロセス全体を AI で扱わないと、企業価値にはつながりにくいのです。
そこで示されたのが、inner loop から outer loop への移行でした。以前は開発チームがワークフローを設計し、個別に専門エージェントを組み込む必要がありました(inner loop)。現在は、Codex を中心としたループを定義し、多くのタスクを任せる outer loop の形に移っています。Codex を中心とした構成は、次の 4 要素で整理されました。
この図のポイントは、「AI に実装させる」だけでなく、グラウンディング・スキル・ツール・フィードバックループをセットで設計することです。紹介された 3 つのユースケースも、すべてこの 4 要素で整理されていました。
| ユースケース | グラウンディング | スキル | ツール | フィードバックループ |
|---|---|---|---|---|
| 半導体エージェント | リポジトリ / ワークフロー | 組込み開発 / 評価 | デザインツール / ドキュメント | 圧縮テスト / 最適化ループ |
| 営業エージェント | 顧客概要 / 営業フロー | 資料作成 / 議事録作成 | CRM / 資料リポジトリ | ユーザー評価 / インサイト抽出 |
| カスタマーサポート | SOP / 規約 | SOP 作成 / サポート | サポートシステム / SOP 参照 | エラー検知 / SOP 改善 |
営業エージェントのデモでは、商談相手の情報から内部向けブリーフィング PDF を生成する Account Brief Studio が示されました。「“AI で何ができます”よりも、拠点横断で手順を見える化・標準化し、現場責任者が意思決定できる状態を作るほうに寄せるのが良い」という示唆が、地に足のついた指摘でした。
💡 自社エージェント開発への示唆は明快でした。エージェントは単体機能でなく、グラウンディング・スキル・ツール・フィードバックループをセットで設計する。MCP や社内ツール接続は重要だが、それだけでは足りず、成果物を評価し、ユーザー評価やエラー検知を次の改善に戻す仕組みが要る。そして FDE 的に、現場に入り込んで解くべき課題を選び、実装したものをプロダクトや標準機能へ戻していく——この流れが大事だ、と締められました。
🏁 2日間を通しての考察
1 日目・2 日目を並べると、業種や立場を超えていくつかの共通項が、より太く浮かび上がりました。
- 🔁 エージェントは“拡張前提”で設計する。フローを柔軟に差し替えたり停止させたりできることが重要で、機能はエージェントの「ツール」として実装する。
- 🧩 最適解は時代によって変わる。だから入れ替えやすくしておく。ルールベースと LLM ベースの使い分けが現実的でした(2 日目の Qwen 使い分け・kickflow の判定がまさにこれ)。
- ❓ AI に“質問”して汎用知識を引き出す。指示するだけでなく、Foundation Model から引き出す姿勢が共通していました。
- 🔍 品質担保は複数モデルの相互チェック。Claude や Codex など複数の AI に相互レビューさせる運用が繰り返し出てきました。
- 🛡️ 重心は「生成」から「権限・監査」へ。エージェントがプロダクトを生成するのは当たり前になり、時代はエージェントの権限設計や監査方法に注力している。
- 🧱 そして 2 日目の通奏低音は「構造で守る」。STRACT の「prompt に書くな、構造で消せ」、kickflow の「決定論的な土台で受け止める」、Databricks 系の「AI Gateway・ユーザー代理認証」——いずれも、お願いではなく仕組みでガードする思想で一致していました。
- 🌱 最後は“文化”。LINEヤフー の ODW が示したとおり、本番活用の鍵は最終的に「組織が試行錯誤し続ける仕組み」をどう作るかに行き着きます。OpenAI が「OpenAI は FDE に注力している」と語ったことも、技術を価値に変える“人と仕組み”への投資という点で同じ方向でした。
参考 📚
- AI Engineering Summit Tokyo 2026 Summer(公式サイト) — カンファレンス概要・タイムテーブル。
- 本レポートは 2026/06/09(2 日目)に聴講した 7 セッションの個人メモに基づきます。各セッションで紹介された数値・価格・事例は、登壇内容として記録したものです(時点・条件は登壇時のもの)。