グラレコ
はじめに 🎯
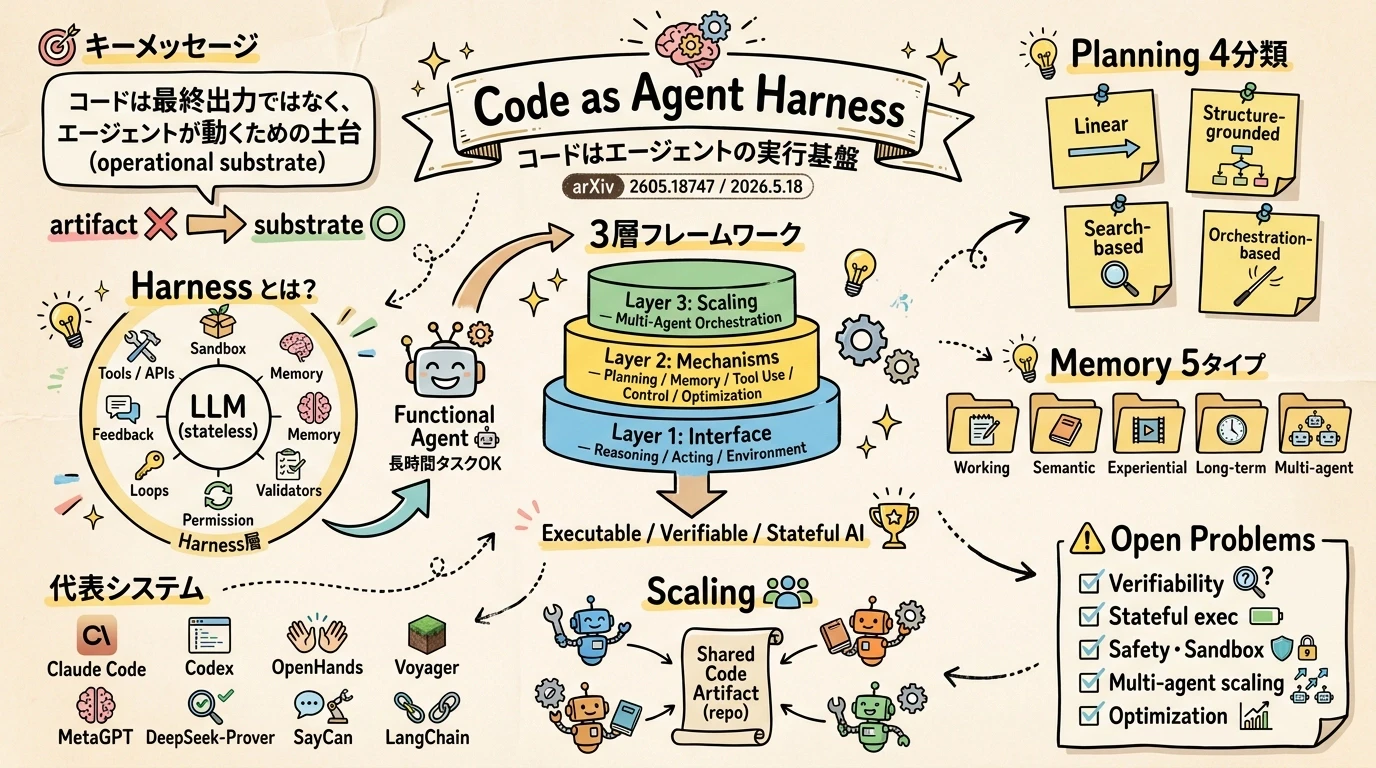
2026年5月18日、arXiv に「Code as Agent Harness」(arXiv:2605.18747)というサーベイ論文が公開されました。Xuying Ning らによる42名の共著で、カテゴリは cs.CL(Computation and Language)と cs.AI(Artificial Intelligence)です。
論文の主張をひとことに集約すると、こうなります。
Code as the executable and inspectable medium through which agents reason, act, and adapt.
「コードは、エージェントが推論し・行動し・適応するための 実行可能で観察可能な媒介(=動かして結果を確かめられる媒介)である」
――これが論文を通底するキーフレーズです。
コードを「LLM の最終出力」として捉える従来の視点から、コードを operational substrate(動作の土台) として捉える視点に切り替えると、エージェントの設計が一段整理しやすくなる、という主張です。
この記事では、論文が提示する3層フレームワーク(Harness Interface / Harness Mechanisms / Scaling the Harness)を中心に、Code as Agent Harness の輪郭と、関連する代表的なシステムまでを整理していきます。Claude Code や Codex のような既存のコーディング・エージェントを使ったことがあって、その内部設計の整理軸を欲しいエンジニア向けの内容です。
用語の整理: Harness と Code as Agent Harness 📖
論文を読み解く前に、ふたつの基本用語を押さえておきます。どちらも論文中で明確に定義されています。
Harness の定義
An agent harness refers to the software layer that surrounds an LLM with tools, APIs, sandboxes, memory, validators, permission boundaries, execution loops, and feedback channels, thereby turning a stateless model into a functional agent capable of long-running task execution.
ハーネスは、素の LLM(stateless model = 状態を持たないモデル)を囲むソフトウェア層 です。ツール・API・サンドボックス・メモリ・バリデータ・権限境界・実行ループ・フィードバックチャネルといった部品を周囲に配置することで、単発の応答機械にすぎなかった LLM を、長時間のタスクをこなせるエージェントに変える役割を担います。
この図のポイントは、「LLM 単体」と「LLM をエージェントに変えるソフトウェア層」を明確に分けて考える ことです。Claude Code や Codex の実体は、LLM そのものではなく、後者のハーネス側の総体です。LLM はその中心に乗っている脳に相当します。
Code as Agent Harness の定義
We term this view code as agent harness: code as the executable and inspectable medium through which agents reason, act, and adapt.
論文はここで、コードそのものをハーネスの中心に据える見方を提案します。プロンプトや会話履歴ではなく、コード(プログラム・スクリプト・実行トレース・リポジトリ)が agentic AI の中心的な媒介になりつつある、という主張です。その裏付けはアブストラクトに書かれています。
In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification.
要点は「コードはもはや単なる出力対象ではなく、推論・行動・環境モデル化・実行ベースの検証 のための operational substrate(動作の土台)として機能している」というものです。
3層フレームワークの全体像 🗺️
論文は Code as Agent Harness を、互いに関係する3つの層として整理します。これが Figure 1 の taxonomy です。
3層は 「インタフェース(使い方の入口)→ メカニズム(動かす仕組み)→ スケーリング(広げ方)」 の順に読むと、自然に頭に入ります。まずコードを何のための入口として使うか(Layer 1)、それを動かすためにどんな仕組みが要るか(Layer 2)、最後にそれを複数エージェントに広げるとどうなるか(Layer 3)、という流れです。
論文の結びは次の一文で締めくくられます。
By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
「コードを agentic AI のハーネスとして据えることで、実行可能(executable)・検証可能(verifiable)・状態を持つ(stateful) な AI エージェントシステムへの統一的なロードマップを提供する」、というのが論文のゴール宣言です。
レイヤー1: Harness Interface 🛠️
Layer 1 は、コードを「どんなインタフェースとして使うか」を3つの軸で整理します。論文の §2 に対応し、Figure 2 が概観図です。
この図のポイントは、ひとつのコード生成物が「推論」「行動」「環境モデル化」の3つの目的に振り分けられる ことです。同じプログラムでも、何のために実行するかで意味が変わる、という整理です。
§2.1 Code for Reasoning(推論の土台)
エージェントの推論を、自然言語ではなく コードによる検証可能な計算(verifiable computation) として外部化する使い方です。プログラム・symbolic solver(記号的に解を出すソルバー、例: Lean などの定理証明器)・execution traces を通じて、推論を実行で確かめられる形に置き換えます。
代表例は DeepSeek-Prover や Lean4Agent といった、数学定理を形式言語で証明させるシステム群です。Table 1 で「reasoning substrate として code が機能するシステム」がまとめられています。
§2.2 Code for Acting(行動の入口)
生成されたプログラムが、embodied(身体性のある)/ GUI / software 環境への 実行ポリシー(executable policy = 実行可能な行動指針) として直接動く使い方です。
Voyager(Minecraft 内でコードを書いて行動する)、SayCan、RoboCodeX、Code-BT、BOSS などが代表例として挙げられています。自然言語の指示をテキストとして留めるのではなく、実行可能なプログラムに変換して環境に投入する という共通点があります。Table 2 にこの「action interface としてコードが機能するシステム」が並びます。
§2.3 Code for Environment(環境モデル化)
プログラムの状態・リポジトリ・実行トレースなどが、環境の状態とダイナミクスを表現する媒体 として機能する使い方です。エージェントが操作する対象(コードベース・ファイルシステム・API 状態)そのものが、エージェントから見た「世界モデル」になる、という見方になります。
OpenHands や Claude Code や Codex のようなコーディング・エージェントは、リポジトリ自体を環境表現として扱う典型例です。
レイヤー2: Harness Mechanisms 🧠
Layer 2 は、エージェントの実行を 持続させる ための機構を整理します。論文の §3 に対応し、5つの要素から構成されます。
各サブセクションの原文題名は次のとおりです。
| § | 原文題名 |
|---|---|
| 3.1 | Planning for Agent Harness |
| 3.2 | Memory and Context Engineering for Agent Harness |
| 3.3 | Tool Use for Agent Harness |
| 3.4 | Harness Control through the Plan, Execute, and Verify Loop |
| 3.5 | Agentic Harness Engineering for Adaptive Harness Optimization |
論文が特に紙幅を割いているのが Planning と Memory なので、その2つを掘り下げます。
§3.1 Planning ― 4つの分類
エージェントのタスク分解(planning)の手法を、論文は4つに分類しています。
| 分類 | 中身 |
|---|---|
| Linear Decomposition | 順序的な単一系列の分解 |
| Structure-grounded | 階層やグラフ構造を持つ分解 |
| Search-based | 探索による解候補の生成・選別 |
| Orchestration-based | 複数エージェント・コンポーネント間の協調による分解 |
この図のポイントは、Planning が単一のテクニックではなく、4つの異なる戦略の集合体 だということです。タスクの形状に応じて、線形分解で済むのか、構造的に分解する必要があるのか、探索が必要なのか、複数の協調が必要なのか、を使い分けることになります。
§3.2 Memory and Context Engineering ― 5つのタイプ
§3.2 の正式題名は「Memory and Context Engineering for Agent Harness」で、メモリ管理だけでなくコンテキスト設計までを射程に入れています。Memory 側は次の5タイプに整理されます。
| タイプ | 中身 |
|---|---|
| Working memory | タスク実行中の一時的な状態 |
| Semantic memory | 概念・事実・知識ベース |
| Experiential memory | 過去の試行の経験 |
| Long-term memory | 永続的に保持される情報 |
| Multi-agent memory | 複数エージェント間で共有される状態 |
「メモリ」と一口に言っても5層あり、Working と Long-term だけでなく、Semantic(知識)・Experiential(経験)・Multi-agent(共有)を独立軸として設計する余地がある、というのが論文の整理になります。
💡 自分が運用しているハーネスを、この5タイプに当てはめて棚卸ししてみると、「Experiential が抜けている」「Multi-agent 用のチャネルが無い」のような抜けが見える、という使い方ができる整理です。
§3.3 Tool Use / §3.4 Plan-Execute-Verify Loop / §3.5 Adaptive Harness Optimization
残る3要素は次のような役割を担います。
- §3.3 Tool Use for Agent Harness: ツール呼び出しの設計(どのツールをいつ呼ぶか)
- §3.4 Harness Control through the Plan, Execute, and Verify Loop: 計画→実行→検証ループによる実行フロー制御
- §3.5 Agentic Harness Engineering for Adaptive Harness Optimization: ハーネス自体を運用しながら最適化していくエンジニアリング
これらは Memory と並んで、コードハーネスを「動かし続け、改善し続けるための仕組み」として位置づけられます。
レイヤー3: Scaling the Harness 👥
Layer 3 は、ハーネスを 単一エージェント から 複数エージェント に広げる scaling の整理です。
論文 §4 の正式題名は「Scaling the Harness: Multi-Agent Orchestration over Code」で、末尾の「over Code」が、コードを共有媒体としたマルチエージェント協調にフォーカスする論文の論点を象徴しています。
この図のポイントは、scaling の中心が 「共有コードアーティファクトを介した協調」 にある、という整理です。複数エージェントが対話的にやり取りするだけでなく、書き換え可能なコード資産(リポジトリ・共有ファイル・状態)を介して間接的に協調する という側面が強調されます。
代表例として、論文では MetaGPT のようなマルチエージェント・システムが挙げられます。エージェントごとに役割(Engineer / Architect / PM 等)を持たせ、共通のドキュメント・コードを介して協調するパターンが、コードハーネスの観点で整理し直されています。
代表的なシステム例 📦
論文で言及される、Code as Agent Harness の各レイヤーを体現するシステムを、用途別に並べておきます。
| カテゴリ | 代表的なシステム |
|---|---|
| 推論ハーネス(reasoning substrate) | DeepSeek-Prover, Lean4Agent |
| エージェント実行枠組み(execution shell) | AutoHarness, OpenHands, Claude Code, Codex |
| 探索学習・行動ポリシー(embodied) | Voyager, SayCan, RoboCodeX, Code-BT, BOSS |
| マルチエージェント・オーケストレーション | MetaGPT |
| スキル獲得(skill acquisition) | LRLL, ViReSkill |
| 一般的なフレームワーク | LangChain |
これらは互いに排他的なグループではなく、たとえば Claude Code は「execution shell」かつ「リポジトリを環境表現として扱う」、Voyager は「reasoning substrate」かつ「action interface」、というように 複数の役割を兼ねる システムが多くあります。
💡 自分が触っているエージェントを、この表のどのカテゴリに当てはまるかで見てみると、その harness 設計の「どこに重心が置かれているか」が掴みやすくなります。
既存サーベイとの差別化 🔀
論文が既存のサーベイ群と異なる打ち出し方をしている点を、3つ整理します。
Contribution 1: Novel framing
コードを「LLM の最終生成物(artifact)」として扱う見方から、エージェントの動作基盤(operational substrate)として扱う見方への転換が、本論文のフレーミングの核です。
Contribution 2: Explicit taxonomy
Interface / Mechanisms / Scaling の3層を明示的な taxonomy として提示しているのが特徴です。既存のサーベイは「LLM の能力」や「エージェントの応用領域」を軸に整理することが多く、コードハーネスの内部構造に焦点を当てた整理は新規性があります。
Contribution 3: Agent-initiated focus
論文は、事前にプロンプトに対して生成された code だけでなく、実行中にエージェント自身が動的に生成・改変する code に強く焦点を当てています。Voyager のようなシステムが時間とともにスキルライブラリを蓄積していくプロセスや、Claude Code が作業中に補助スクリプトを書き起こす挙動を、ハーネス設計の中心問題として位置づけ直す視点です。
論文は3つの要素を区別することも強調しています(原文表記に近い形で示します)。
- Model-internal capabilities(モデル自体の能力)
- System-provided harness infrastructure(システム基盤)
- Agent-initiated code artifacts(エージェントが実行中に作る コード 成果物)
3つを混同せずに、それぞれを独立した研究軸として扱おう、というのが論文の姿勢です。特に3つ目の "agent-initiated code artifacts" は、論文全体のキーフレーズ "code as ..." と直結する用語なので、"code" を落とさずに把握することが大事になります。
Open Problems と今後の方向 ⚠️
論文の §5「Emerging Fields and Open Problems」では、Code as Agent Harness の今後の課題が論じられています。アブストラクトおよびイントロから読み取れる主要な論点を整理しておきます。
| 課題 | 中身 |
|---|---|
| Verifiability | 生成・実行されるコードの検証可能性をどう担保するか |
| Stateful execution | 長期にわたる状態保持と更新の設計 |
| Safety / Sandboxing | 実行ベースのエージェントが副作用を持つ環境での安全性 |
| Multi-agent scaling | 共有コードアーティファクトを介した協調の規律 |
| Optimization | ハーネス自体の自動最適化 |
実務的な視点で言えば、ここで挙げられている課題はそれぞれ既存のシステムが部分的に取り組んでいる領域でもあります。sandboxing は Docker や Firecracker による隔離、stateful execution はベクトルストアやセッション DB の活用、multi-agent scaling は MetaGPT のようなパターンで、部分的に解決されてきました。
論文の貢献は、これらを 「コードを中心に据えたハーネス」 という共通の枠で議論できるようにする整理を与えた点にあります。
⚠️ 論文はサーベイなので、個別の手法の新規性ではなく「分野全体の整理軸」を提供することが目的です。新しい技術を直接持ち込むものではなく、既存技術の見取り図として読むのが正しい使い方になります。
まとめ 🏁
「Code as Agent Harness」というキーフレーズで、論文が伝えたいことはひとつに集約できます。
コードはエージェントの最終生成物ではなく、エージェントが動くための実行基盤である という見方です。
この視点が定まると、Claude Code や Voyager のような一見すると別物に見えるシステムが、同じ taxonomy の上で比較できるようになります。
本記事の範囲で覚えておくと役立つ点は3つです。
| # | キーメッセージ |
|---|---|
| ① | Harness の定義 は「LLM を tools / sandbox / memory / validator / loops で取り囲むソフトウェア層」。LLM 単体とハーネスを分けて考える |
| ② | Code as Agent Harness は3層 で整理される: Interface(推論 / 行動 / 環境モデル化)→ Mechanisms(Planning / Memory / Tool Use / Control / Optimization)→ Scaling(Multi-agent) |
| ③ | 本論文の貢献は、code を「artifact」から「operational substrate」に再定義 したフレーミングと、interface / mechanisms / scaling の明示的 taxonomy にある |
論文には GitHub の Awesome リスト(YennNing/Awesome-Code-as-Agent-Harness-Papers)も併設されているので、関連論文を追いかけたい場合はここを起点にすると効率的です。
参考
- arXiv:2605.18747 / Code as Agent Harness ― 本記事のベースとした arXiv preprint(2026-05-18 公開、CC BY 4.0)
- arXiv HTML 版 ― 構造化されたブラウザ閲覧用
- Awesome-Code-as-Agent-Harness-Papers (GitHub) ― 論文の併設リポジトリ