この記事について
アイレット株式会社 Advent Calendar 2024 20日目の記事です。
今回はre:Invent2024で新たに発表されたAmazon Kendraの新機能「GenAI Index」を試してみて、その考察をまとめた記事となります。
GenAI Indexとは
AWS公式のブログ記事では、以下のように紹介されています。
簡潔にまとめるならば、RAGを組み込んだ生成AIアプリケーションをより簡単に構築できるようにするための、Amazon Kendraの新機能、といったところでしょうか。
Amazon Kendra GenAI Index は、企業がデジタルアシスタントとインテリジェント検索エクスペリエンスをより効率的かつ効果的に構築できるようにするために RAG とインテリジェント検索向けに設計された Amazon Kendra の新しいインデックスです。このインデックスは、高度なセマンティックモデルと最新の情報検索テクノロジーを使用して、高い検索精度を提供します。Amazon Bedrock ナレッジベースやその他の Amazon Bedrock ツールと統合して RAG を活用したデジタルアシスタントを作成したり、Amazon Q Business と組み合わせて完全に管理されたデジタルアシスタントソリューションとして使用したりできます。
実際に試してみる
Amazon Kendraのindexを消し忘れると、結構な額課金がかかってしまうため、検証終了後はindexの削除を忘れず行いましょう。
詳しくはAmazon Kendraの料金ページをご参照下さい。
※英語版のサービスページでは、今回追加されたGenAI Indexの料金が記載されていました。
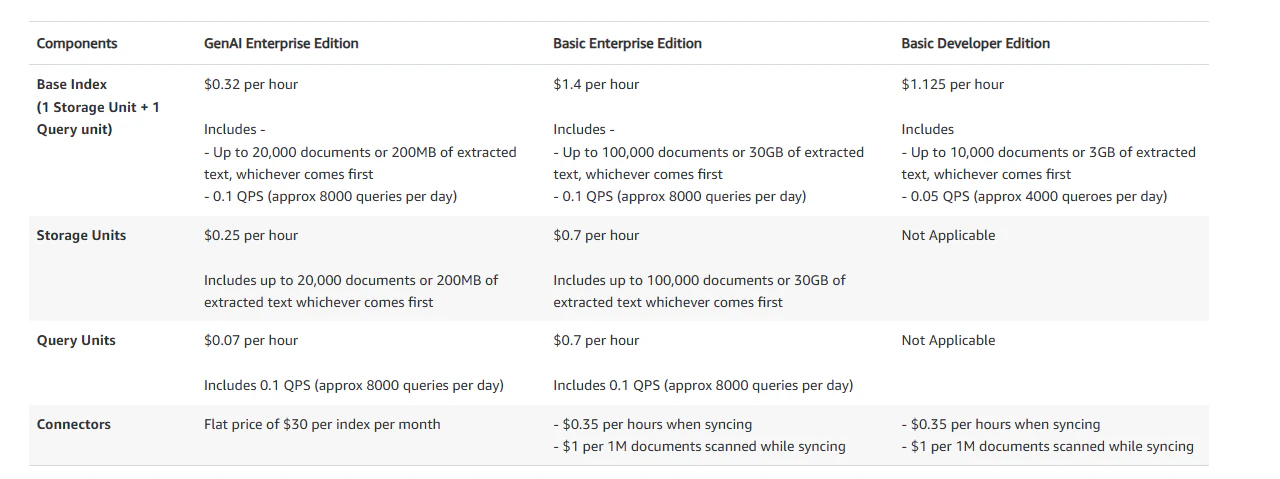
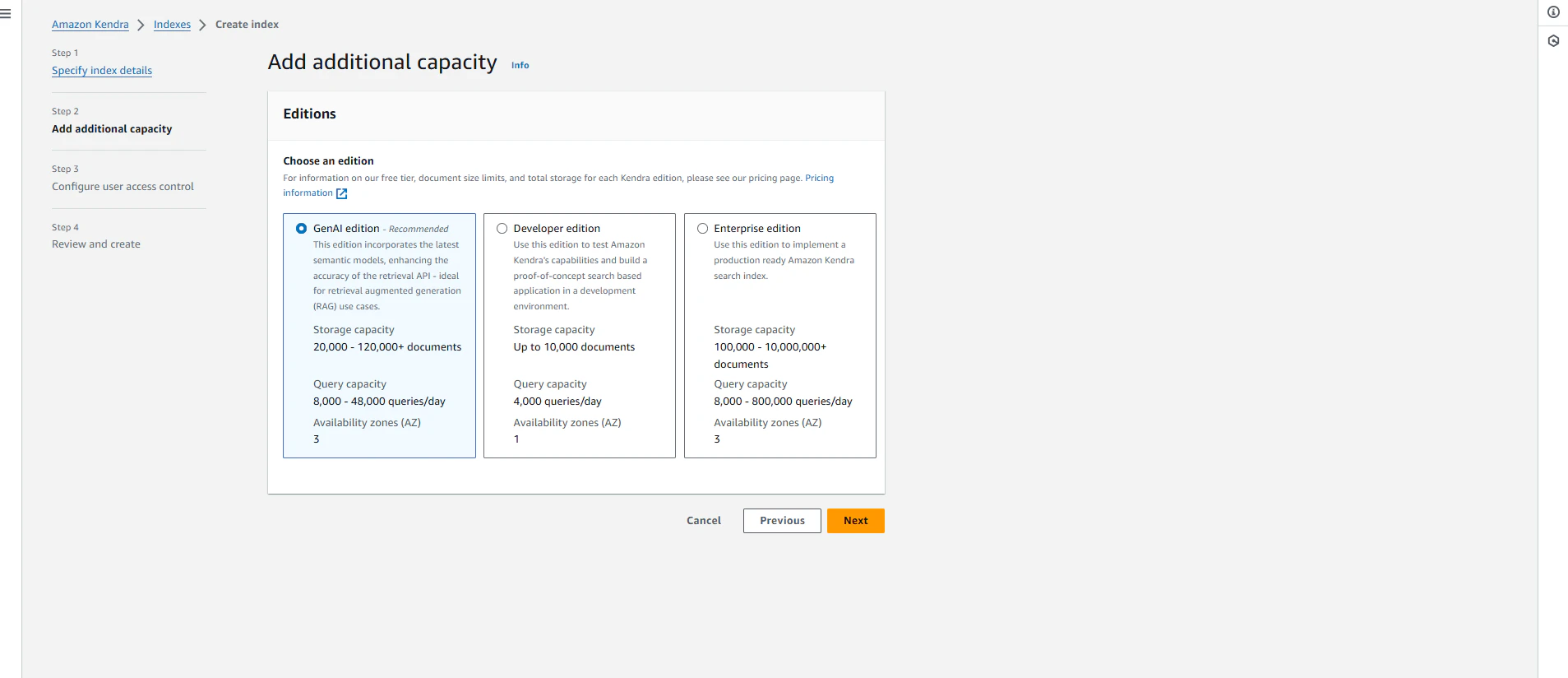
GenAI Indexの作成
ここについては、通常(Developer Editionや Enterprise Edition)のKendra index作成時とフローは変わりません。
通常時と違うのはEdition選択の部分くらいです。画面に沿って設定を進めていきます。
基本的にはデフォルトの設定で進めました。
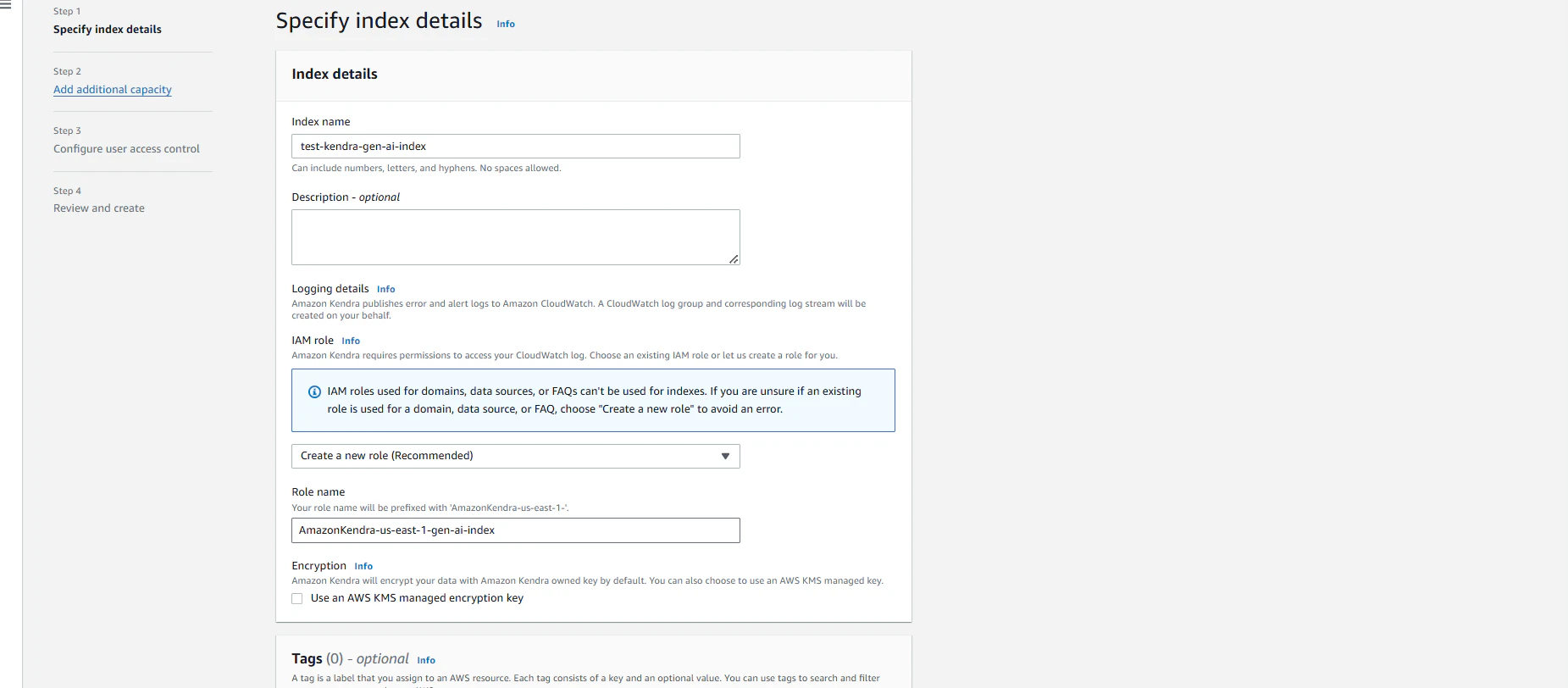
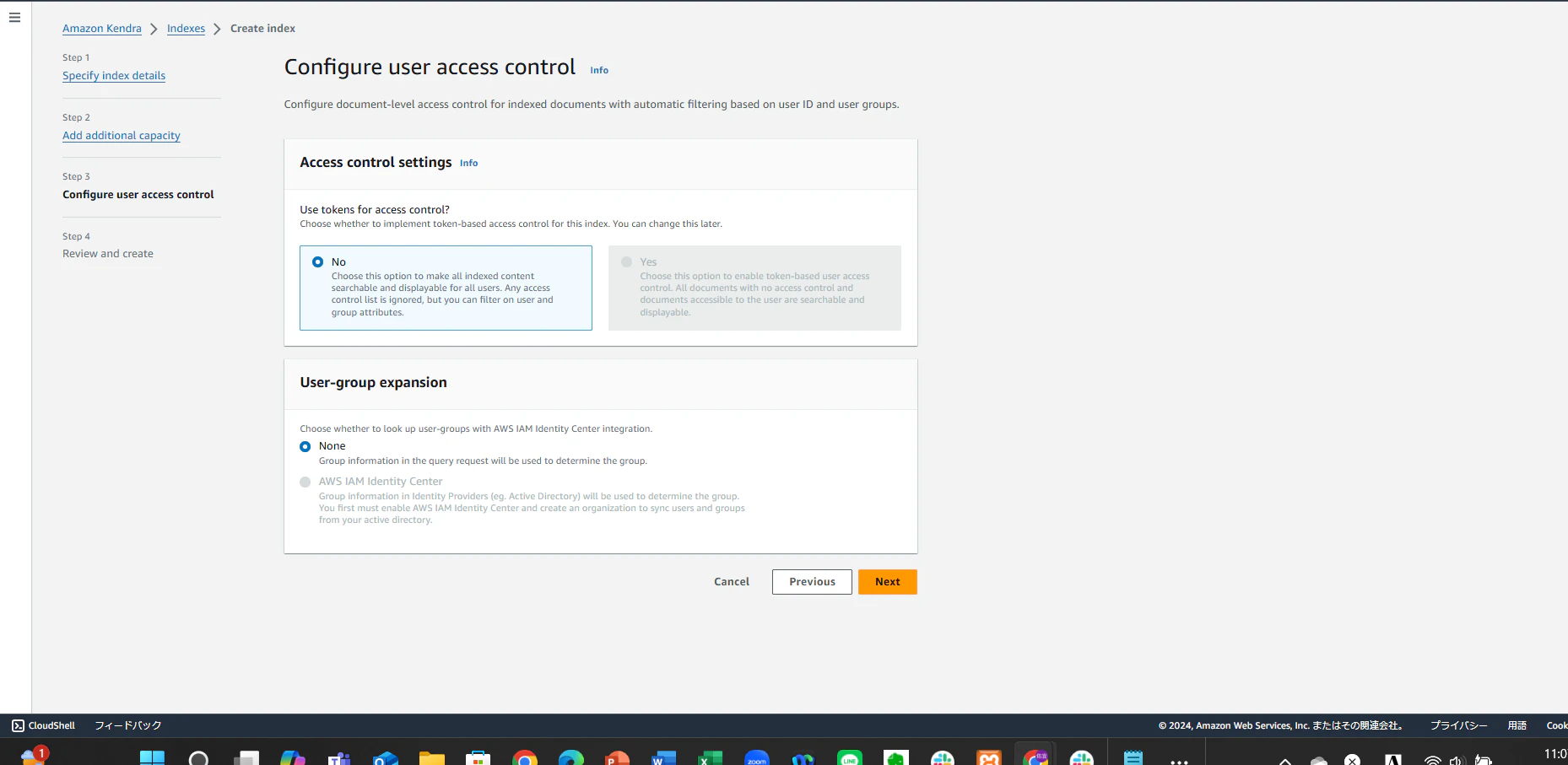
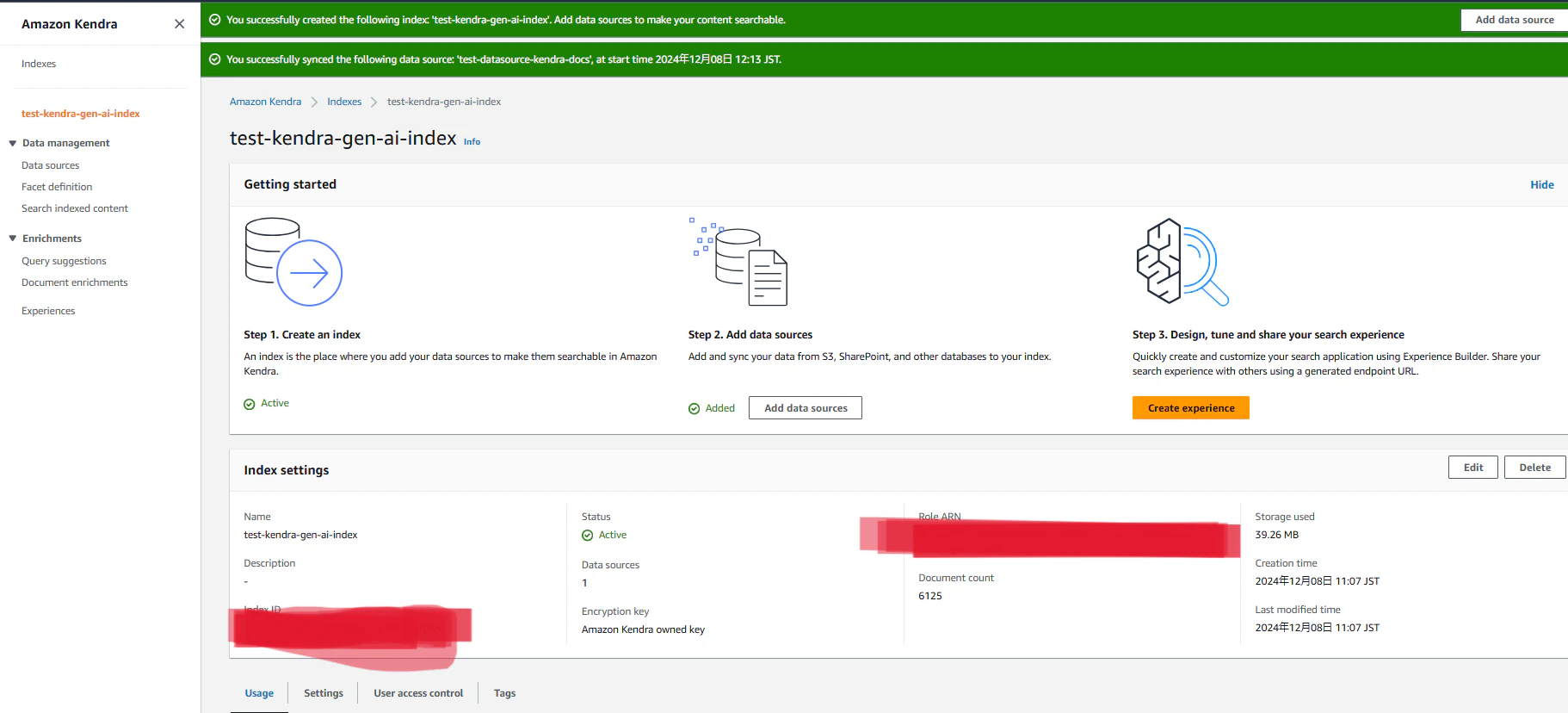
以下のような画面が表示されたらindexの作成は完了です。
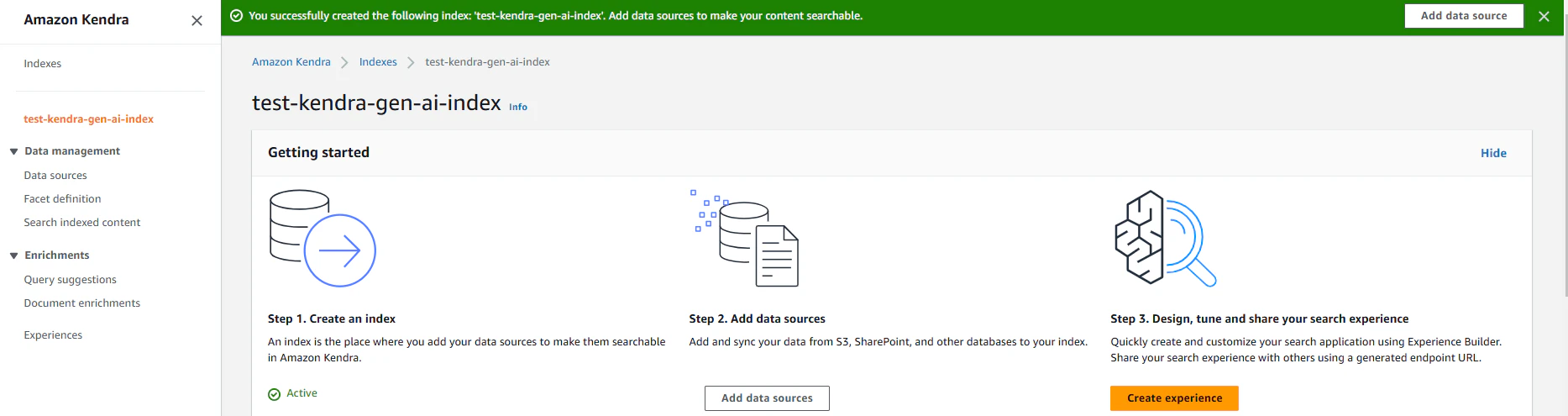
データソースの指定
データソースですが、Webクローラーを使い、マイナンバーに関するページWebページの内容を試そうとしました。画面に沿って設定を進めていきました。
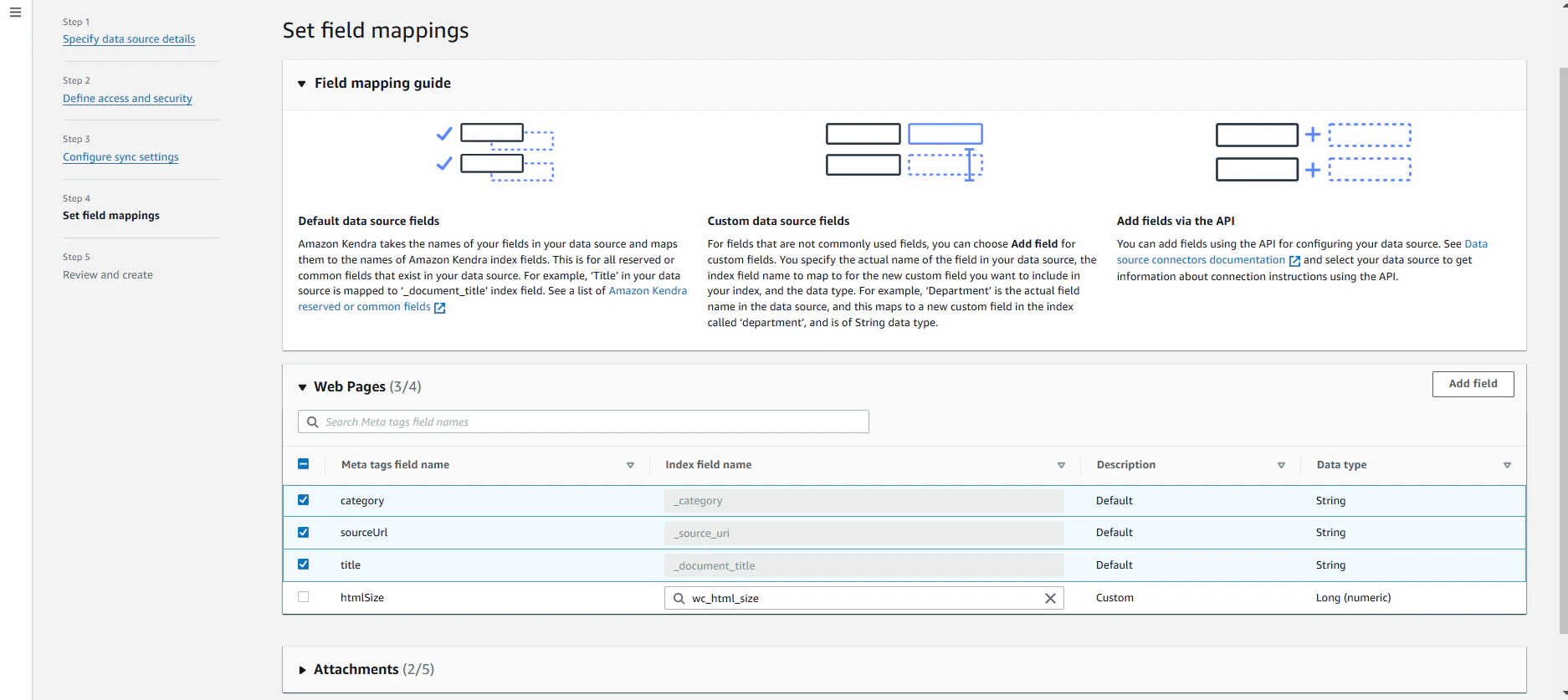
設定途中で、language code ja is not supported by Kendraという表示が出てしまったため、Kendra GenAI indexは、恐らくまだ日本語のページは対応していなさそうです。

そのため、Amazon Kendraの英語のサービスページをデータソースとして指定しました。

Index作成後、Sync nowを押下して、データソースとのデータの同期が完了すれば、Amazon Kendra側の作業は完了です。
検索テスト
実際にテストをしてみます。
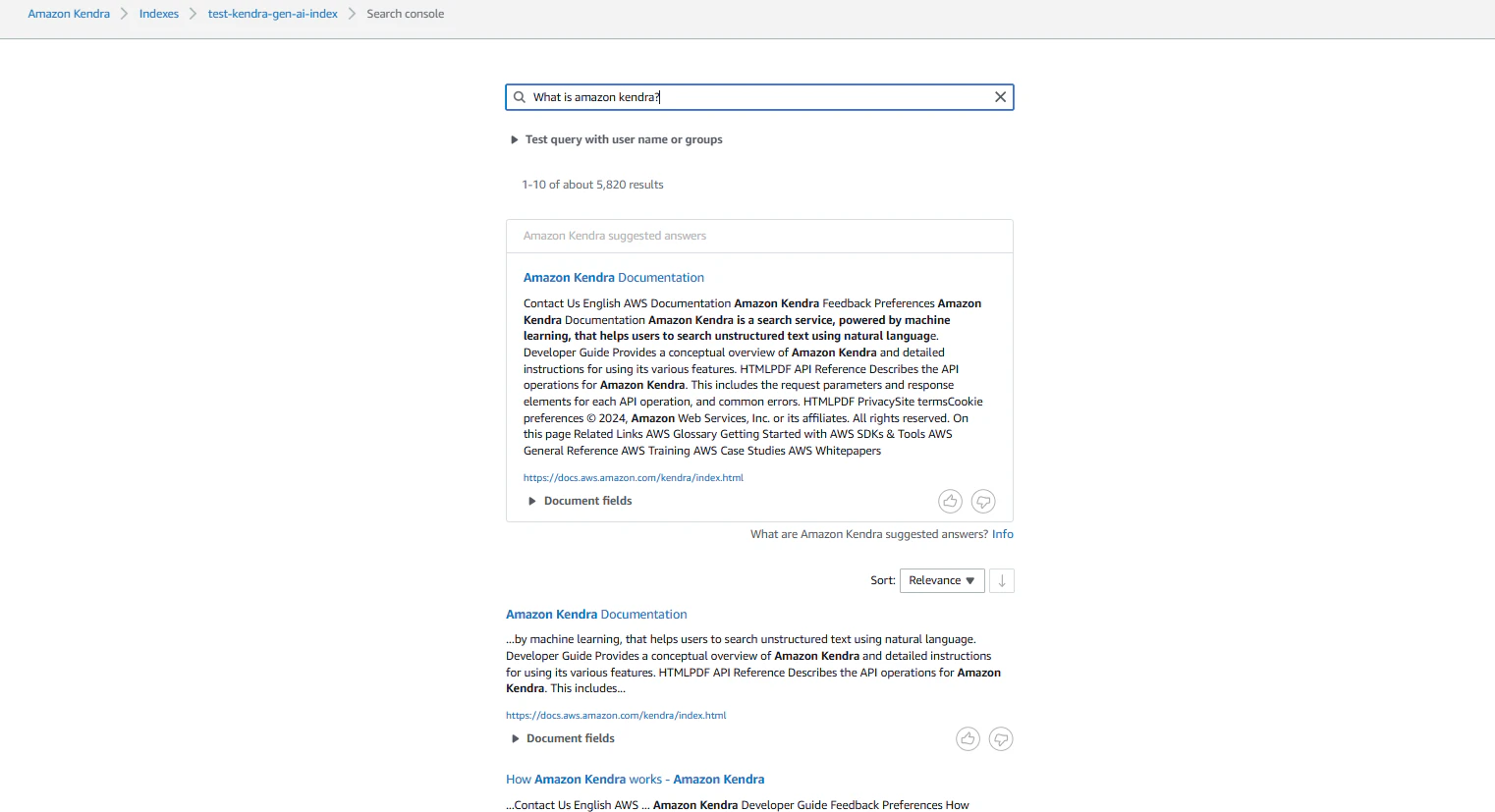
Step1 マネジメントコンソールからテスト
KendraのSearch indexed contentのメニューから、テストをしてみます。以下のように回答が帰ってくる事を確認できました。
Step2 Amazon Bedrock ナレッジベースと組み合わせてみる
Amazon Bedrockのナレッジベースと組み合わせてみます。
ナレッジベースを作成を押下すると、プルダウンでKnowledge Base with Kendra GenAI Indexが選択できるようになっているのが分かります。押下すると、ナレッジベースの詳細設定画面に遷移します。
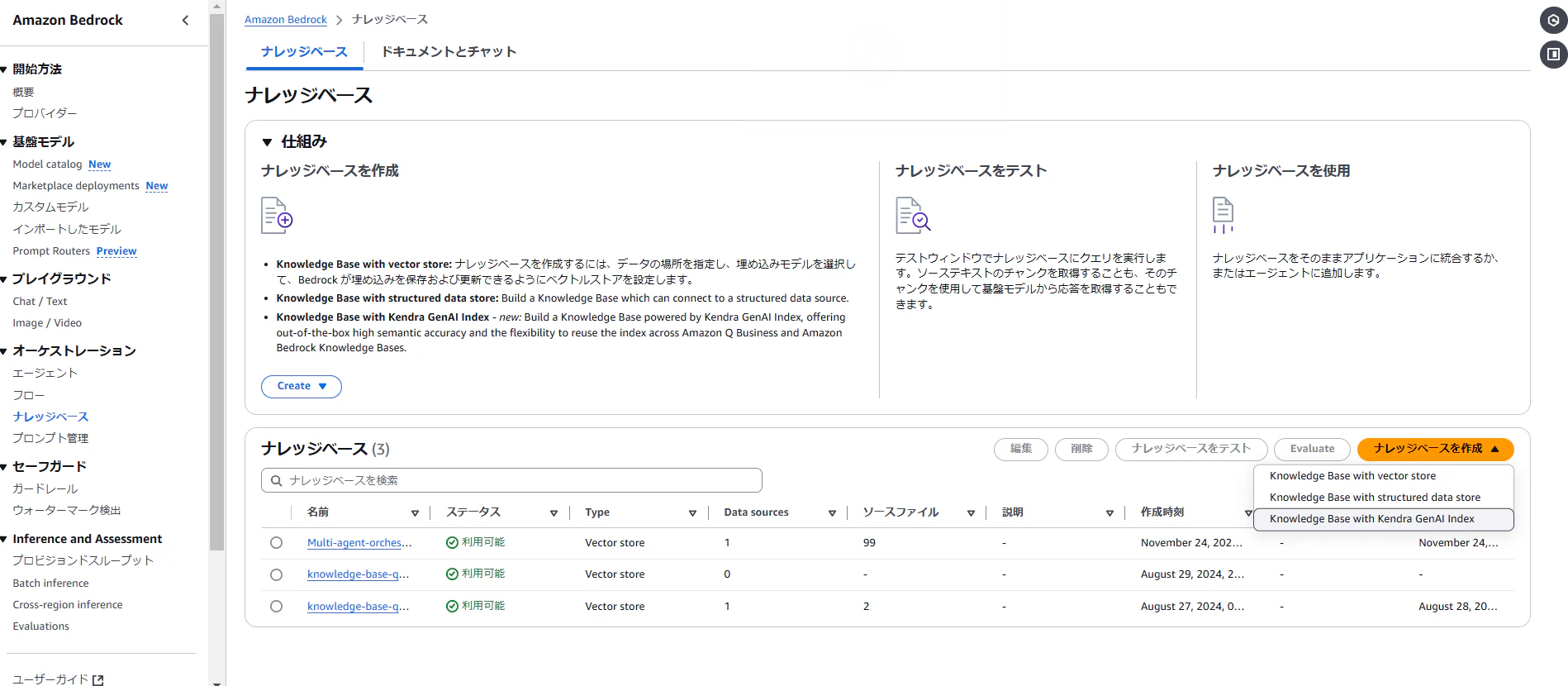
Kendra GenAI index という項目が表示されるようです。
Create a new Kendra GenAI Index(新しくGenAI Indexを作成)か、Use an existng Kendra GenAI Index(既存のものを選択する)かを選択するようですが、今回は前段で作成したGenAI Indexを使用することにします。
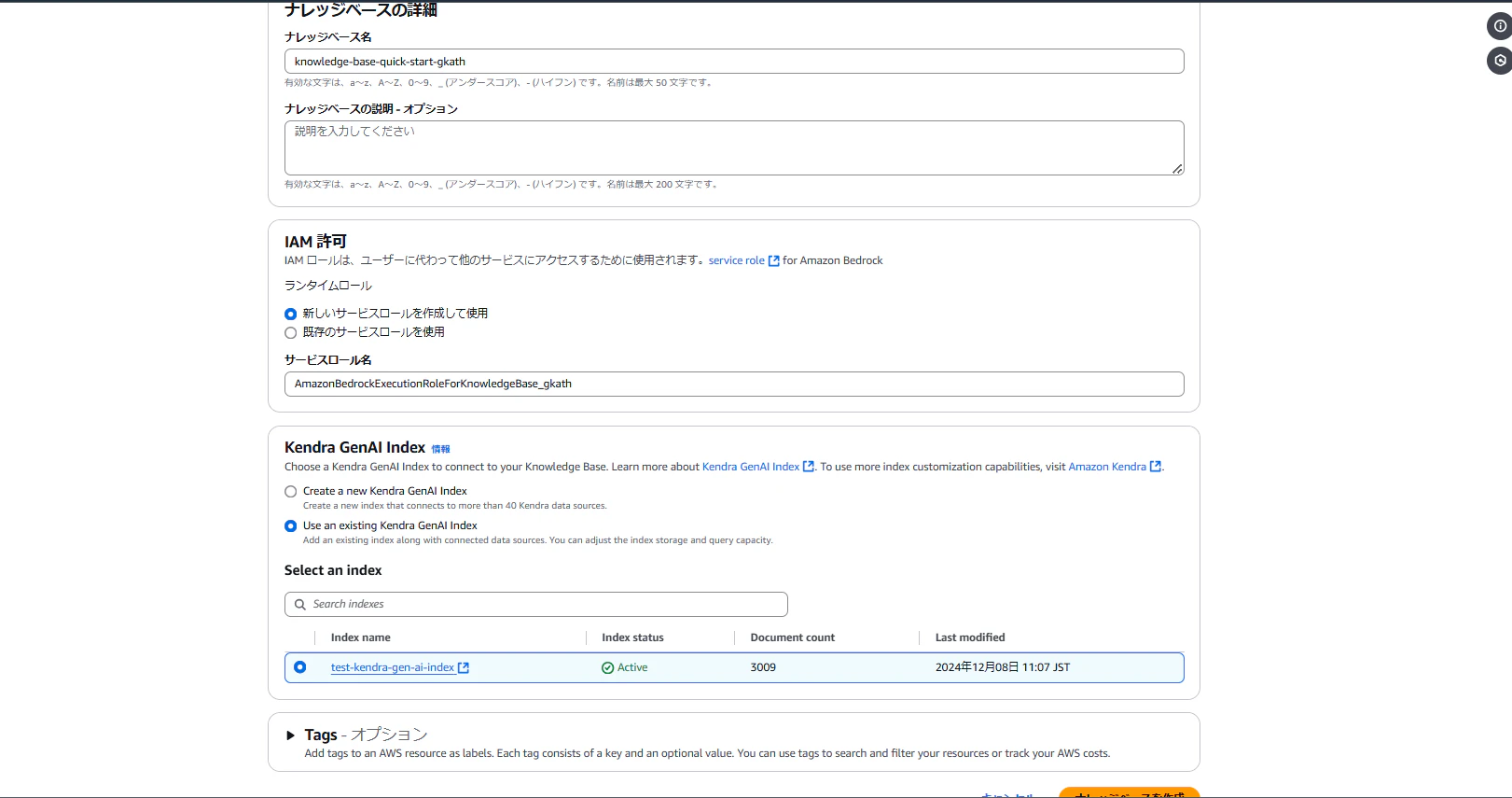
作成完了すると、以下のような画面になります。
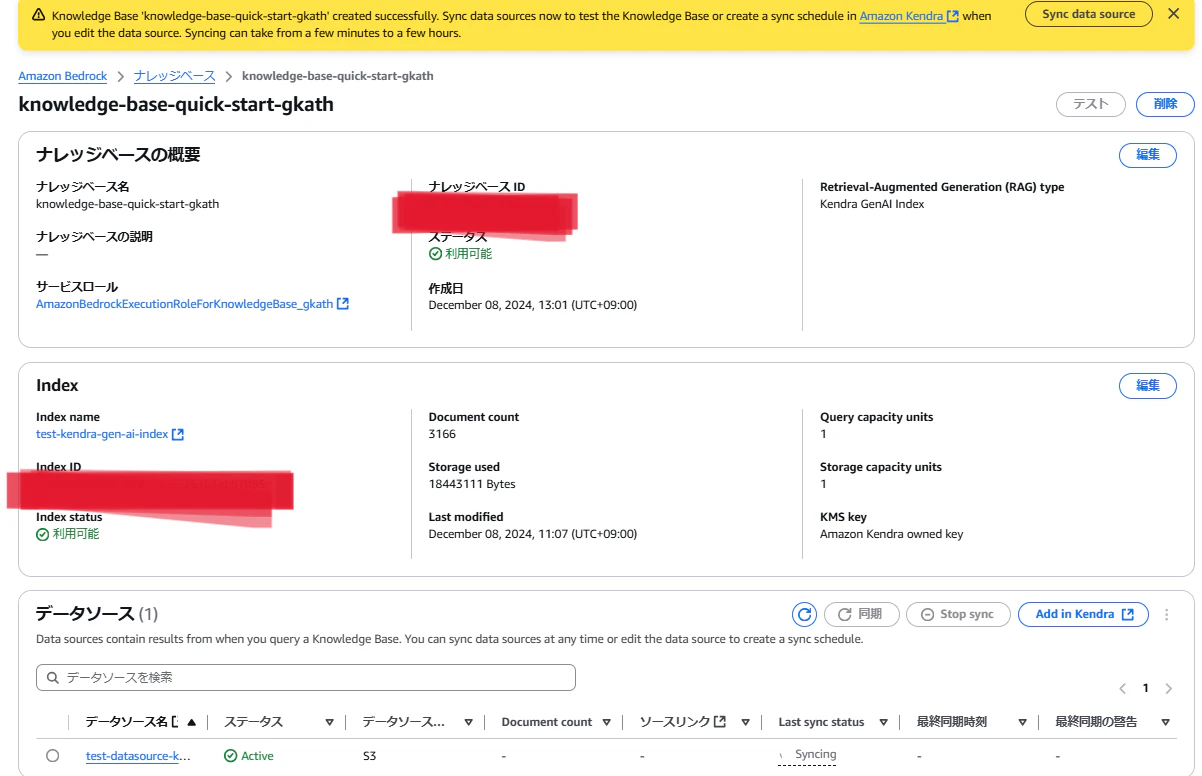
ナレッジベース内で検索のテストをしてみます。ModelはClaude3 Haikuを使用しました。
What is Amazon Kendra?と質問すると、KendraでIndex化されている、Kendraのサービスページに関する情報を元に回答がされていそうです。
注目すべきは、右側の「ソースチャンク」です。
質問内容と、参照されたKendra内のデータのメタデータ(ドキュメントや関連度など?)が確認できるようです。
Step2 Streamlitアプリに組み込む
Streamlit×Bedrock×Kendraで作る! 多機能チャットボットの記事で作成したStreamlitアプリに
このGenAI Indexを組み込んでみます。方針としては下記で考えます。
- ナレッジベースを元に回答するエージェントを作成、それを呼び出す
ナレッジベースを元に回答をするエージェントの作成
任意のエージェントを作成します。(エージェントの作成自体は2クリックでできます。)
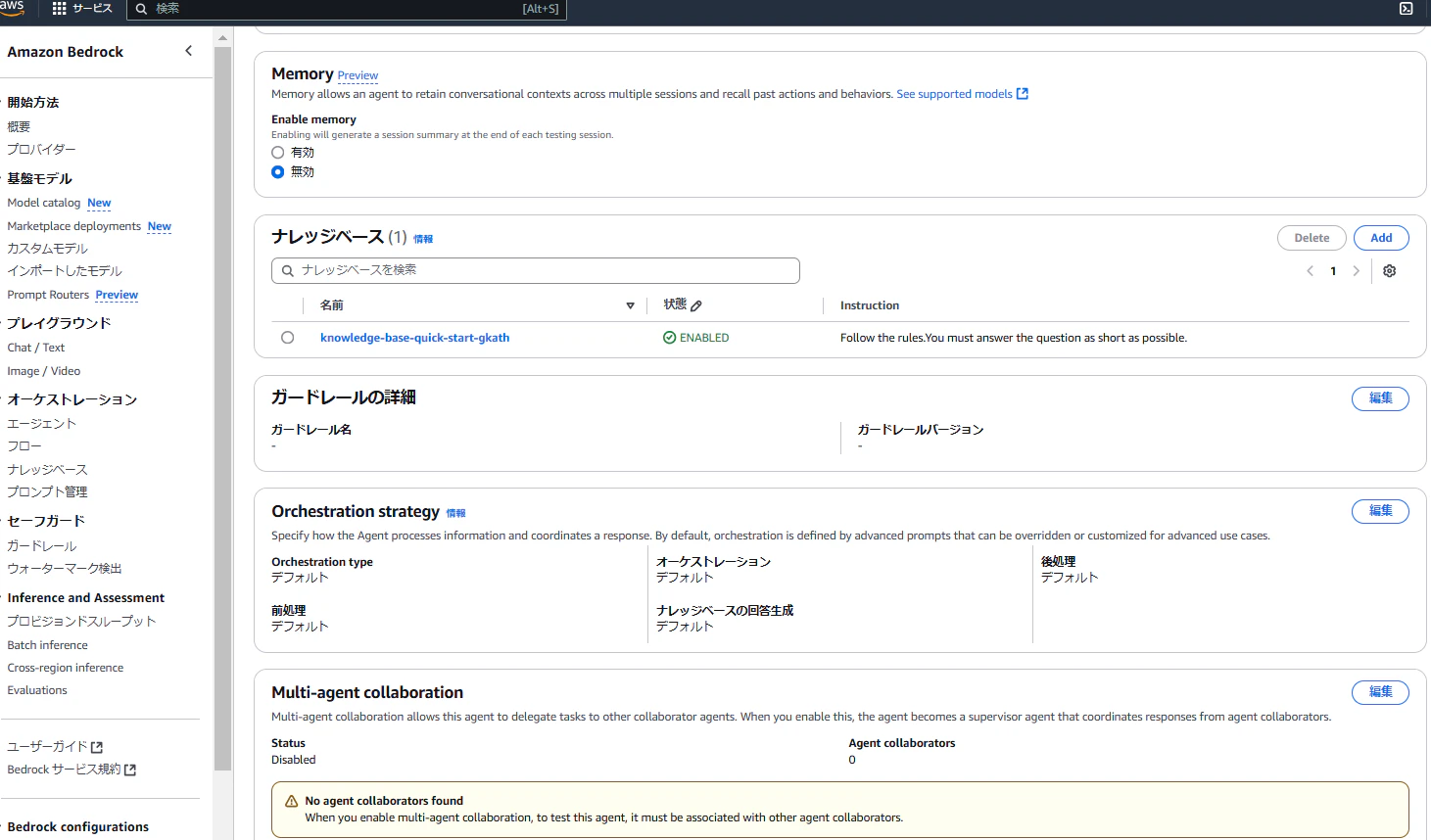
ナレッジベースのメニューで、Addを押下することで、ナレッジベースを追加できます。
コード修正
Streamlit×Bedrock×Kendraで作る! 多機能チャットボット内で記載されているapp.pyを修正します。
# session_stateののメッセージを初期化
def initialize_session():
if "tab_messages" not in st.session_state:
st.session_state.tab_messages = {
"rag_search": [],
"kendra_search": [],
"multi_modal": [],
"kendra_genai_index": [], #追加
}
# kendra_genai_indexタブ 追加
elif selected_tab == "kendra_genai_index":
st.header("kendra_genai_index")
display_tab_messages("kendra_genai_index")
user_input = st.chat_input("エージェントへの質問を入力してください")
if user_input:
input_msg = {"role": "user", "content": [{"text": user_input}]}
st.session_state.tab_messages["kendra_genai_index"].append(input_msg)
with st.chat_message("user"):
st.markdown(user_input)
try:
# Bedrockモデルの呼び出し
with st.spinner("回答生成中..."):
# Invoke Bedrock agent for the response
response = bedrock_agent_runtime.invoke_agent(
agent_id, agent_alias_id, "kendra_genai_index", user_input
)
output_text = response["output_text"]
# Handle citations and trace
if response["citations"]:
output_text += "\n" + "\n".join([f"[{i+1}] {cit['retrievedReferences'][0]['location']['s3Location']['uri']}" for i, cit in enumerate(response["citations"])])
st.session_state.tab_messages["kendra_genai_index"].append({"role": "assistant", "content": [{"text": output_text}]})
with st.chat_message("assistant"):
st.markdown(output_text)
except Exception as e:
st.error(f"エージェント処理中にエラーが発生しました: {e}")
"""
エージェントを呼び出す関数(新規追加)
"""
import boto3
from botocore.exceptions import ClientError
def invoke_agent(agent_id, agent_alias_id, session_id, prompt):
try:
client = boto3.session.Session().client(service_name="bedrock-agent-runtime")
# See https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/bedrock-agent-runtime/client/invoke_agent.html
response = client.invoke_agent(
agentId=agent_id,
agentAliasId=agent_alias_id,
enableTrace=True,
sessionId=session_id,
inputText=prompt,
)
output_text = ""
citations = []
for event in response.get("completion"):
# Combine the chunks to get the output text
if "chunk" in event:
chunk = event["chunk"]
output_text += chunk["bytes"].decode()
if "attribution" in chunk:
citations = citations + chunk["attribution"]["citations"]
except ClientError as e:
raise
return {
"output_text": output_text,
"citations": citations,
}
また、環境変数でBedrockのエージェントID,エイリアスIDを指定しておいてください。
agent_id = os.getenv("BEDROCK_AGENT_ID")
agent_alias_id = os.getenv("BEDROCK_AGENT_ALIAS_ID")
結果確認
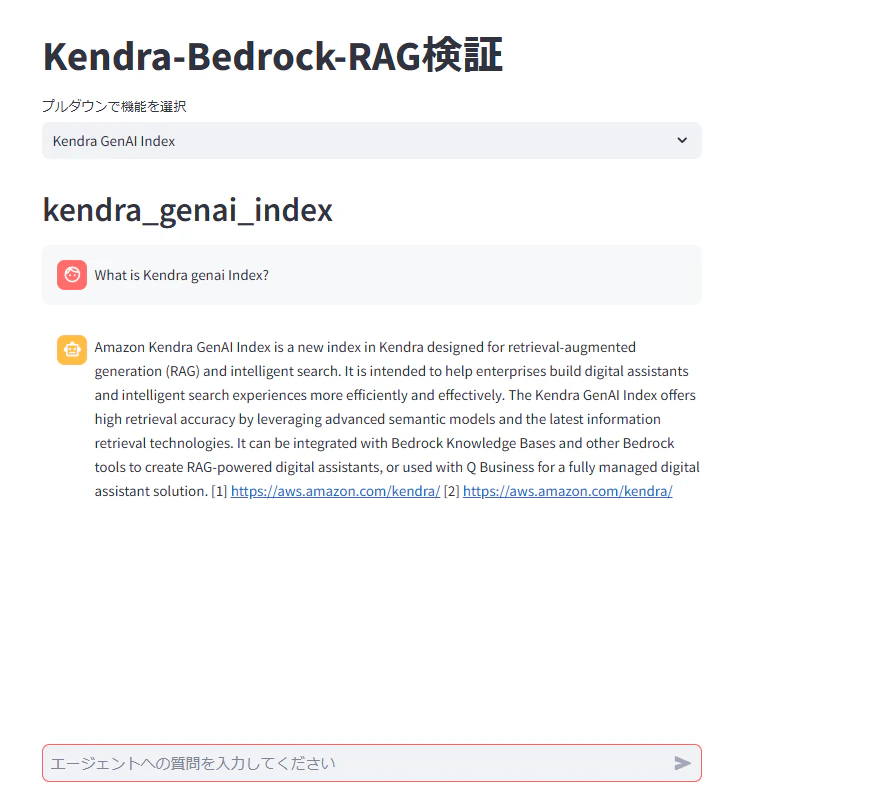
streamlitアプリを起動すると、
Kendra GenAI Indexのプルダウンが出現し、質問を行うとナレッジベース内のドキュメントを元に回答を得ることができました。
もう少しエージェントの設定を細かく制御してみたりしたかったですが、一旦検証はここまでとします。
まとめ
今回は、Amazon Kendra の新機能「GenAI Index」を試してみました。
Amazon Bedrock との統合もスムーズにできたため、全体として詰まることなく、比較的容易にRAGを実現出来たな、という印象でした。
既存のEditionと比べた精度の比較や、料金の比較など、まだまだ未知数の部分はありますが、ひとまずRAGシステムを作る上での選択肢が増えそうです。
今回のre:Invent2024では様々な生成AIサービスのアップデートが発表されました。引き続きAWSの生成AIサービスに関して、動向を注視してキャッチアップしていきたいと思います。
参照記事
Amazon Kendra GenAI Index のご紹介 – 強化されたセマンティック検索および取得機能
Amazon Kendra GenAI インデックスを使用して Amazon Bedrock ナレッジベースを作成する
Agents for Amazon Bedrock Test UI