はじめに〜AWS Jr.Championsとは?〜
アイレット株式会社の前野です。
この記事は、AWS Jr.Champions Adventcalendar 2024の1日目の記事です。
AWS Jr.Championsとは以下のようなプログラムです。
AWS Partner Network (APN) 参加企業に所属し、現在社会人歴 1~3 年目で突出した AWS 活動実績がある若手エンジニアを「Japan AWS Jr. Champions」として表彰します。これは、AWS を積極的に学び、自らアクションを起こし、周囲に影響を与えている APN 若手エンジニアを選出しコミュニティを形成する、日本独自の表彰プログラムです。
※2024 Japan AWS Jr. Champions クライテリアと申し込みサイトのお知らせより抜粋
上記説明に記載があるように、AWSに関して積極的に学び、アクションを起こしている若手を表彰する制度です。
Jr.Championsの執筆記事はこちらからチェックすることができます。Jr.Championsの皆さんのご活躍を是非ご覧下さい!
本記事でやったこと
今回の記事のテーマは、
「RAG/Kendra検索/マルチモーダル問い合わせ」を1画面で試せるチャットボットをStreamlitで作ろう!」 です。
Streamlitは、一言で説明するならば、「Pythonコードだけでフロントエンドをつくることができるツール」です。
(フロントエンドの実装の知見に乏しい私は重宝させていただいているツールです...)
今回はこれを使い、RAG、Kendra検索、マルチモーダル問い合わせの複数を1画面で試すことができる他機能チャットボットを作ってみました。
本記事ではKendraのindex作成方法や、RAGの仕組みなどの解説については割愛させていただきます。
今回のキーワード
今回のチャットボットを作るにあたって、重要な役割を担ってくれたのが、Amazon BedrockのConverse APIです。
Converse APIとは何か
公式の説明は以下です。
Amazon Bedrock Converse を使用してAPI、Amazon Bedrock モデルとの間でメッセージを送受信する会話アプリケーションを作成できます。例えば、多くのターンにわたって会話を維持し、役に立つテクニカルサポートアシスタントなど、ニーズに固有のペルソナまたはトーンのカスタマイズを使用するチャットボットを作成できます。
Converse APIオペレーションとの会話を実行するより引用
会話履歴を踏まえた回答などさせたい時に便利そうですね。
また、従来のAmazon Bedrockの、InvokeModel APIでは利用する基盤モデルごとで呼び出し方が異なる、という状況でしたが、このConverse APIでは、モデル全体で呼び出し方が共通化されているようです。
コード
早速にはなりますが、以下のような形でチャットボットを作成しました。
長いので、折りたたんで表示しています。
前提1
フォルダ構成は以下です。
amazon-bedrock-kendra-streamlit-app/
├── .env
├── app_config.py
├── app.py
├── kendra_bedrock_query.py
└── requirements.txt
前提2
動作確認環境は以下です。
- Windows 10(もちろん、Macでも動きます)
- Python 3.12
- Streamlit 1.30.0
- Amazon BedrockのモデルについてはClaude3 Haikuを利用(利用料を抑える観点で)
app.py
"""
Streamlitを使った画面の表示
"""
from kendra_bedrock_query_step2 import ragSearch, kendraSearch, invokeLLMWithFile
from app_config import AppConfig
from dotenv import load_dotenv
import streamlit as st
# 環境変数をロード
load_dotenv()
# メッセージリストの順序を保証する関数
def ensure_alternating_roles(messages):
"""
メッセージリストが `user` と `assistant` のロールが交互になるように調整する。
"""
# メッセージリストが空の場合、エラー回避のためユーザーメッセージが必須
if not messages:
raise ValueError("メッセージリストが空です。会話はユーザーメッセージから開始する必要があります。")
# 最後のメッセージが `assistant` でない場合に調整
if messages[-1]["role"] != "assistant":
messages.append({
"role": "assistant",
"content": [{"text": "準備中..."}]
})
return messages
# session_stateののメッセージを初期化
def initialize_session():
if "tab_messages" not in st.session_state:
st.session_state.tab_messages = {
"rag_search": [],
"kendra_search": [],
"multi_modal": []
}
# チャットメッセージを表示
def display_tab_messages(tab_key):
for message in st.session_state.tab_messages[tab_key]:
with st.chat_message(message["role"]):
st.markdown(message["content"][0]["text"])
# アプリの初期表示
st.title("Kendra-Bedrock-RAG検証")
initialize_session()
# 表示内容切り替えのためのプルダウン設定
tab_titles = AppConfig.WORDS_USED_IN_EACH_TAB_DICT
selected_tab = st.selectbox("プルダウンで機能を選択", options=list(
tab_titles.keys()), format_func=lambda x: tab_titles[x])
# プルダウンでで選択された値によって、動的に表示される内容を変更
# RAG検索タブ
if selected_tab == "rag_search":
st.header(tab_titles["rag_search"])
# 会話履歴の表示
display_tab_messages("rag_search")
# ユーザーの入力
user_input = st.chat_input("RAG検索クエリを入力してください")
if user_input:
# ユーザーの入力を session stateに格納
input_msg = {"role": "user", "content": [{"text": user_input}]}
st.session_state.tab_messages["rag_search"].append(input_msg)
history = st.session_state.tab_messages["rag_search"]
# ユーザーの入力を表示
with st.chat_message("user"):
st.markdown(user_input)
try:
# RAG検索を実行
with st.spinner("RAG検索実行中..."):
kendra_response, signed_urls = ragSearch(
user_input, history)
# LLMからのレスポンスをsession stateに格納
response_msg = {"role": "assistant",
"content": [{"text": kendra_response}]}
st.session_state.tab_messages["rag_search"].append(response_msg)
# LLM からのレスポンスを表示
with st.chat_message("assistant"):
st.markdown(kendra_response)
# 関連ドキュメントを表示
if signed_urls:
st.markdown("#### 関連するドキュメント")
for doc in signed_urls:
st.markdown(
f"- [{doc['document_name']}]({doc['signed_url']})")
except Exception as e:
st.error(f"エラーが発生しました: {e}")
# Kendra検索タブ
elif selected_tab == "kendra_search":
st.header(tab_titles["kendra_search"])
# 会話履歴を表示
display_tab_messages("kendra_search")
# ユーザーの入力
user_input = st.chat_input("質問を入力してください")
if user_input:
input_msg = {"role": "user", "content": [{"text": user_input}]}
st.session_state.tab_messages["kendra_search"].append(input_msg)
with st.chat_message("user"):
st.markdown(user_input)
try:
# Kendra検索実行
with st.spinner("検索中..."):
signed_urls = kendraSearch(user_input)
response_content = "以下の関連ドキュメントが見つかりました:\n\n" + "\n".join(
[f"- [{doc['document_name']}]({doc['signed_url']})" for doc in signed_urls])
response_msg = {"role": "assistant",
"content": [{"text": response_content}]}
# kendraの検索結果のレスポンスをsession_stateに格納
st.session_state.tab_messages["kendra_search"].append(response_msg)
with st.chat_message("assistant"):
st.markdown(response_content)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
# マルチモーダルタブ
elif selected_tab == "multi_modal":
st.header(tab_titles["multi_modal"])
# 会話履歴の表示
display_tab_messages("multi_modal")
# ファイルアップローダーの表示
uploaded_file = st.file_uploader("ファイルをアップロードしてください", type=[
"png", "jpg", "jpeg", "pdf"])
question = st.chat_input("ファイルに関する質問を入力してください")
# ファイルのアップロードの有無に応じて処理の分岐
if uploaded_file and question:
st.image(uploaded_file, caption="アップロードされたファイル", use_column_width=True)
input_msg = {"role": "user", "content": [{"text": question}]}
st.session_state.tab_messages["multi_modal"].append(input_msg)
with st.chat_message("user"):
st.markdown(question)
try:
# Bedrockモデルの呼び出し
with st.spinner("回答生成中..."):
response_content = invokeLLMWithFile(
question, uploaded_file, st.session_state.tab_messages["multi_modal"])
response_msg = {"role": "assistant",
"content": [{"text": response_content}]}
# LLMからのレスポンスをsession_stateに保存
st.session_state.tab_messages["multi_modal"].append(response_msg)
# LLMからのレスポンスを表示
with st.chat_message("assistant"):
st.markdown(response_content)
except Exception as e:
st.error(f"ファイル処理中にエラーが発生しました: {e}")
kendra_bedrock_query.py
"""
RAG検索、Kendra単体での検索、マルチモーダル問い合わせの各処理を行う
"""
from app_config import AppConfig
import os
from dotenv import load_dotenv
import urllib
import boto3
from botocore.client import Config
# 環境変数の読み込み
load_dotenv()
# boto3セッションの定義
boto3_session = boto3.session.Session(profile_name=os.getenv('profile_name'))
# リトライ設定の作成(Amazon Bedrock ConverseAPI利用時のThrottlingエラー回避策)
retries_config = Config(AppConfig.RETRY_CONFIGS)
# Bedrock clientの初期化
bedrock = boto3_session.client("bedrock-runtime", region_name='ap-northeast-1', config=retries_config)
# デバッグ用
# print(bedrock)
# RAG検索を行う関数
def ragSearch(question, history):
"""
Kendraの query APIを使用して、その回答をLLMに渡す関数
:param question: ユーザーの質問
history: ユーザーの会話履歴
:return: 過去の会話履歴+ユーザーの質問を踏まえて、LLMによって生成された回答
"""
# kendra clientの初期化
kendra = boto3_session.client('kendra', region_name="ap-northeast-1")
# queryAPIを使ってKendraを呼び出す
kendra_response = kendra.query(
IndexId=os.getenv('kendra_index'), # Put INDEX in .env file
QueryText=question,
PageNumber=1,
PageSize=10,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {
"StringValue": "ja"
}
}
})
# デバッグ用:print(kendra_response)
# ドキュメントのメタデータを取得し、署名付きURLを生成
signed_urls = generateSignedUrls(kendra_response)
# デバッグ用
# print(signed_urls)
# 参照ドキュメントを生成 回答の参照ドキュメントが画面に出力されてしまうためマークダウンで表示できるよう整形
document_references = "\n".join(
[f"- [{doc['document_name']}]({doc['signed_url']})" for doc in signed_urls]
)
# Claudeモデルに渡すシステムプロンプトを定義
system_prompt = AppConfig.SYSTEM_PROMPT
# 会話の順番が`user`と`assistant`となるように制御
for i in range(len(history) - 1):
if history[i]["role"] == history[i + 1]["role"]:
raise ValueError("会話履歴のロールはuserとassistantで交互である必要があります。")
# デバッグ用
# print(f"messages:{messages}")
# 現在の質問と検索結果を会話履歴に追加
context_message = {
"role": "assistant",
"content": [{"text": f"Kendra検索結果:\n\n{document_references}"}]
}
history.append(context_message)
question_message = {
"role": "user",
"content": [{"text": question}]
}
history.append(question_message)
# デバッグ用(会話履歴の確認
print("-----------------------")
print(f"history:{history}")
print("-----------------------")
# # デバッグ用
# # print(bedrock)
# モデルIDと推論パラメータのセット
modelId = AppConfig.MODEL_ID_DICT["claude_3_haiku"]
inferenceConfig = AppConfig.INFERENCE_CONFIG_DICT
# ConverseAPIに会話履歴を渡した上で質問を行う
response = bedrock.converse(
modelId=modelId,
messages=history,
system=system_prompt,
inferenceConfig=inferenceConfig
)
# デバッグ用
# print(f"Converse API response: {response}")
# レスポンスの中身チェック
if "content" not in response["output"]["message"] or not response["output"]["message"]["content"]:
raise ValueError("Bedrock response content is empty.")
# 最終的に画面に表示する回答
answer = response["output"]["message"]["content"][0]["text"]
return answer, signed_urls
# Kendra検索時に使用する関数
def kendraSearch(kendra_query):
"""
Kendra検索用の関数
queryAPIを使った検索のみを行い、検索結果と、メタデータから署名付きURLを生成し、返却する
:param question: ユーザーの質問
:return: 署名つきURL
"""
# Kendra clientの初期化
kendra = boto3_session.client(
'kendra', region_name='ap-northeast-1')
# Kendraの queryAPIの呼び出し
kendra_response = kendra.query(
IndexId=os.getenv('kendra_index'), # Put INDEX in .env file
QueryText=kendra_query,
PageNumber=1,
PageSize=10,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {
"StringValue": "ja"
}
}
})
# デバッグ用
# print(kendra_response)
# 署名付きURLを取得
signed_urls = generateSignedUrls(kendra_response)
# デバッグ用
# print(f"署名つきURL:{signed_urls}")
return signed_urls
# 署名付きURLを返却する関数(Kendra検索, RAG検索共通
def generateSignedUrls(kendra_response):
"""
Kendraの検索結果から署名付きURLを生成する
:param kendra_response: Kendraの検索結果
:return: Kendra検索結果のドキュメントの署名付きURLのリスト
"""
s3_client = boto3_session.client(
's3', region_name='ap-northeast-1', config=Config(signature_version="s3v4"))
signed_urls = []
for result in kendra_response.get('ResultItems', []):
# ドキュメントのパスの存在確認
if 'DocumentURI' in result and "s3.ap-northeast-1.amazonaws.com" in result['DocumentURI']:
# 検索結果のS3ドキュメントのURIを取得
s3_url = result['DocumentURI']
try:
# Debug: print the DocumentURI to verify its structure
# print(f"DocumentURI: {s3_url}")
# Parse S3 bucket and key from the DocumentURI
# プロトコル部分を取り除く
s3_path = s3_url.replace("https://", "")
# パスをバケット名とオブジェクトキーに分割
parts = s3_path.split('/', 1)
if len(parts) == 2:
bucket_name = os.getenv('bucket_name')
# オブジェクトキーを取得(取得時はすでにエンコードされている)
object_key_encoded = parts[1]
# 取得したオブジェクトキーをデコード(オブジェクトキーが日本語だと二重でエンコードされてしまい、エラーとなってしまうため)
# 参照: https://github.com/aws-samples/generative-ai-use-cases-jp/issues/189
object_key = urllib.parse.unquote(object_key_encoded)
# Debug: print the decoded object key to verify its value
# print(f"Decoded Object Key: {object_key}")
# print(f"Bucket Name: {bucket_name}")
# print(f"Object Key: {object_key}")
# 署名付きURLの生成
signed_url = s3_client.generate_presigned_url(
'get_object',
Params={'Bucket': bucket_name, 'Key': object_key},
ExpiresIn=3600 # URL valid for 1 hour
)
signed_urls.append({
"document_name": result.get('DocumentTitle', 'Unknown Document').get('Text'),
"signed_url": signed_url
})
print(f"signed_urls: {signed_urls}")
else:
print(f"Unexpected S3 path format: {s3_url}")
except Exception as e:
print(f"Error generating signed URL: {e}")
return signed_urls
# マルチモーダル問い合わせを行う関数
def invokeLLMWithFile(question, uploaded_file, messages):
"""
マルチモーダルでのBedrock呼び出しを行う
:param: question ユーザーの質問
uploaded_file アップロードされたファイル
:return:messages LLMからの回答
"""
# モデルIDと推論パラメータのセット
model_id = AppConfig.MODEL_ID_DICT["claude_3_haiku"]
inference_config = AppConfig.INFERENCE_CONFIG_DICT
# ファイル形式を判別
if uploaded_file.type in ["application/pdf"]:
file_format = "pdf"
elif uploaded_file.type in ["image/png", "image/jpeg"]:
file_format = "png" if uploaded_file.type == "image/png" else "jpeg"
else:
raise ValueError("サポートされていないファイル形式です。PDF、PNG、JPEGのみ対応しています。")
# ファイルの内容を読み込む
file_content = uploaded_file.getvalue()
user_message = {
"role": "user",
"content": [
{"text": f"Uploaded {file_format} content:"},
{"document" if file_format == "pdf" else "image": {
"format": file_format,
"source": {"bytes": file_content}
}},
{"text": question if question else "画像の説明をお願いします。"}
]
}
# 会話のロールが交互になるように調整
if messages and messages[-1]["role"] != "assistant":
messages.append({"role": "assistant", "content": [{"text": "準備中..."}]})
messages.append(user_message)
# # デバッグ用
# print(f"messages:{messages}")
# Bedrock Converse APIを呼び出してファイルを処理しレスポンスを生成
response = bedrock.converse(
modelId=model_id,
messages=messages,
inferenceConfig=inference_config
)
return response["output"]["message"]["content"][0]["text"]
app_config.py
"""
各種設定値を定義する
"""
class AppConfig:
# Amazon BedrockのモデルID(Claude3.5 Sonnet, Claude3 Sonnet, Claude3 Haiku)
MODEL_ID_DICT = {
"claude_3_5_sonnet": "anthropic.claude-3-5-sonnet-20240620-v1:0",
"claude_3_sonnet": "anthropic.claude-3-sonnet-20240229-v1:0",
"claude_3_haiku": "anthropic.claude-3-haiku-20240307-v1:0",
}
# Claudeモデルの、推論時の各種パラメータ(追加したいパラメータを下記に追記していく)
INFERENCE_CONFIG_DICT = {
"maxTokens": 4096,
"temperature": 0.5,
# topP = 0.999(デフォルト),
# stopSequences = ['</output>']
}
# アプリ名称
APP_NAME = "Kendra-Bedrock-RAG検証"
# 各タブで利用される文言
WORDS_USED_IN_EACH_TAB_DICT = {
"rag_search": "RAG検索",
"kendra_search": "Kendra検索",
"multi_modal": "マルチモーダル"
}
# リトライ設定
# botocoreのリトライ設定の作成(Throttlingエラー回避策)
RETRY_CONFIGS = {
'max_attempts': 10, # 最大10回のリトライ
'mode': 'adaptive' # リトライモード
}
# システムプロンプト
SYSTEM_PROMPT = [{
"text": f"""
【指示】:
- 以下の「質問」と「検索結果」、過去の会話履歴に基づいて、ユーザーの質問に正確に、日本語で回答してください。
- 検索結果に回答が含まれていない場合は、「該当する情報は見つかりませんでした」と明示してください。
"""
}]
.env
# Kendra indexのID、プロファイル名、S3バケット名などの情報を格納
#検証で使用するS3バケット名(データソースとして使用するS3バケット)
bucket_name = "(S3バケット名)"
#IAMユーザープロファイル名(ローカル検証用)
profile_name = "(IAMプロファイル名)"
#KendraのIndexID
kendra_index = "(KendraのindexID)"
"""
以下工夫ポイントです。
コードの全てを解説すると長くなってしまうので、2点に絞ってお伝えします。
- 会話履歴の保持
- 2ターン目以降の質問で、過去のやり取りもconverseAPIに渡すことで文脈を理解した上での回答をさせるようにしています
具体的には、app.pyの
- 2ターン目以降の質問で、過去のやり取りもconverseAPIに渡すことで文脈を理解した上での回答をさせるようにしています
history = st.session_state.tab_messages["rag_search"]
で会話履歴を取得し、その上でkendra_bedrock_query.pyにおいて、Kendra検索結果とユーザーのした質問をhistoryに追加し、Bedrockのconverseメソッドのmessages引数に追加しています。
# 現在の質問と検索結果を会話履歴に追加
context_message = {
"role": "assistant",
"content": [{"text": f"Kendra検索結果:\n\n{document_references}"}]
}
history.append(context_message)
question_message = {
"role": "user",
"content": [{"text": question}]
}
history.append(question_message)
※converseAPIの仕様上、常に、messages配列におけるroleはuser→assistant→userというように交互に格納されないとエラーになってしまうため、若干無理やり感もあります。
[
{
"role": "user",
"content": [
{ "text": "question1" }
]
},
{
"role": "assistant",
"content": [
{
"text": "answer1"
}
]
},
{ "role": "user",
"content": [{ "text": "question2" }] },
{
"role": "assistant",
"content": [
{
"text": "answer2"
}
]
},
{
"role": "user",
"content": [{ "text": "question3" }]
},
{
"role": "assistant",
"content": [
{
"text": "answer3"
}
]
}
...
]
- 回答元のドキュメント表示は署名付きURLで表示をしている
- ユーザーがKendraの検索結果における、参照ドキュメントをすぐ閲覧できるようにしています
- 検索結果のドキュメントをを署名付きURLに変換→マークダウンで表示させている、といった具合です(
app.pyの以下の部分)
- 検索結果のドキュメントをを署名付きURLに変換→マークダウンで表示させている、といった具合です(
- ユーザーがKendraの検索結果における、参照ドキュメントをすぐ閲覧できるようにしています
# 関連ドキュメントを表示
if signed_urls:
st.markdown("#### 関連するドキュメント")
for doc in signed_urls:
st.markdown(
f"- [{doc['document_name']}]({doc['signed_url']})")
各種コードを記載したら、
$ streamlit run app.py
を実行すればlocalhost:8501でブラウザが立ち上がります。
試してみる
実際に試してみました。知識の整理という意味でも、各機能について図に整理してみたものも記載してます。
なお、今回Kendraでindex化するドキュメントは
マイナ保険証の利用促進等について(厚生労働省)を使用しました。
RAG検索
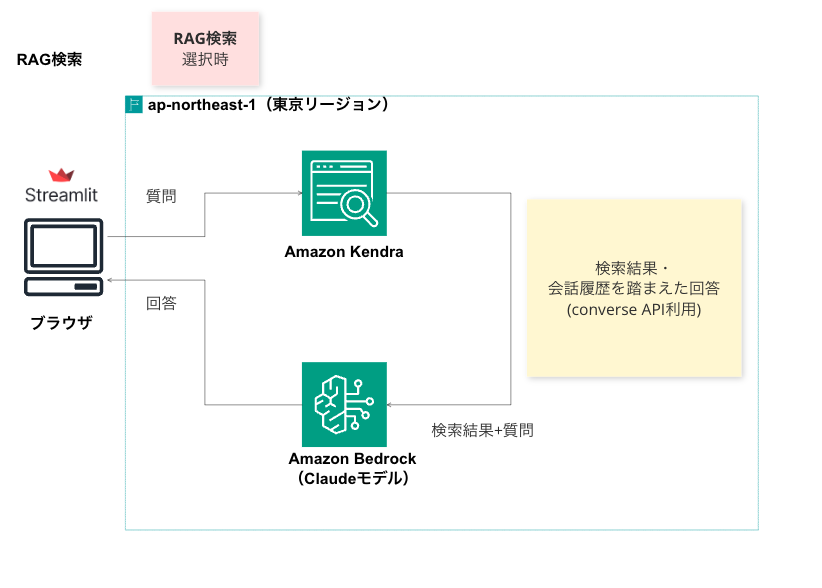
結果

さっき私はなんと質問した?という問に対して回答できていることから、会話履歴を踏まえた回答もできているようです。
Kendra検索
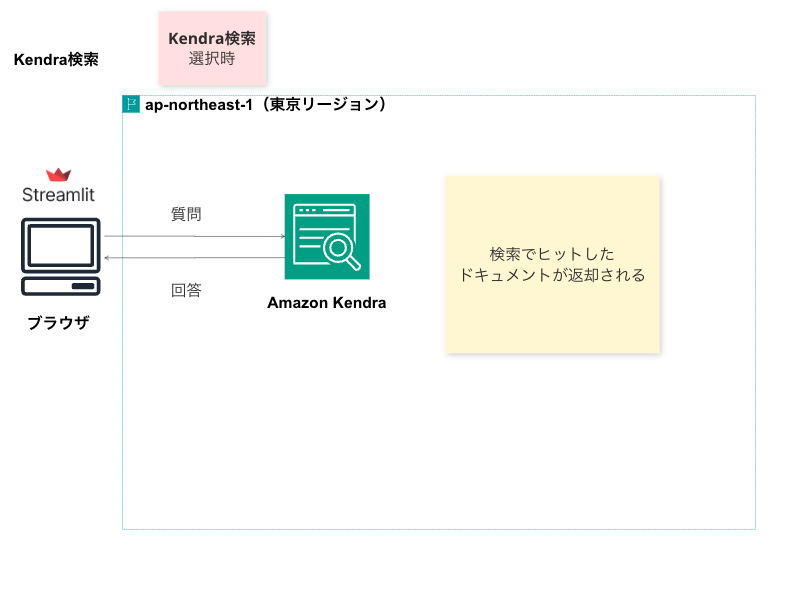
結果
こちらも、いい感じに検索結果のドキュメントが返却されていそうです。(1件のみしか登録していないため結果がさみしいですが・・・)

マルチモーダル問い合わせ
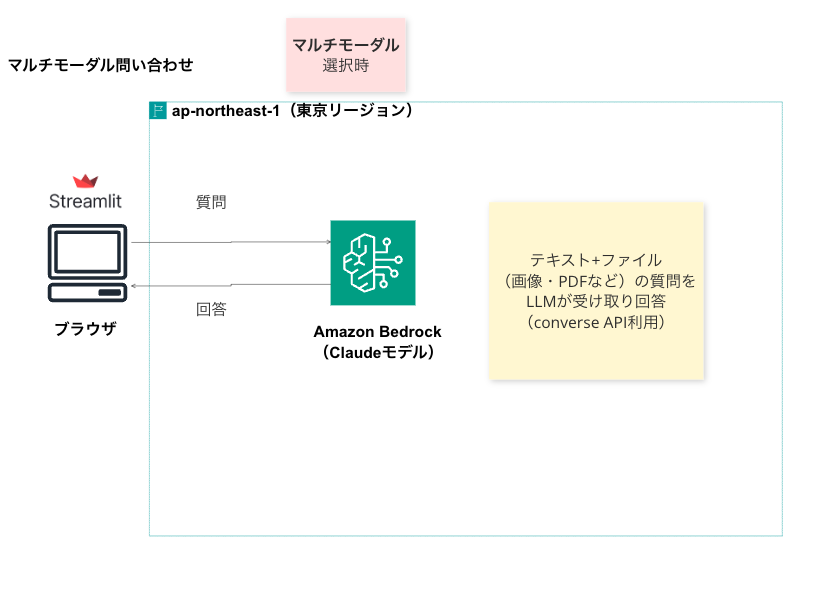
結果
試しに、画像(レシートメーカーで作ったレシート)から読み取れる内容を書き出させましたが、うまくいっているようです。

以上のように、Streamlitで複数機能を試すことができるチャットボットを作ることができました。
最後に
今回の記事では、こちらの記事に続き、Streamlitを活用してチャットボットを構築する方法をご紹介しました。生成AIの精度を効率的に検証しながら、ユースケースに応じて簡単にカスタマイズできるStreamlitは、AWSの生成AIサービスとの相性が抜群で、プロトタイプ開発に最適なツールであると改めて実感しています。
特に、生成AIを使った文書検索の精度を検証するようなケースでは、 シンプルな画面で素早くプロトタイプを作成し、検証そのものに集中したいニーズ が高いのではないでしょうか。こうした場面では、StreamlitとAWSの生成AIサービス(特に最近アップデートが頻繁に発表されている Amazon Bedrockなど)を組み合わせることで、手間を最小限に抑えながら実験や検証を進めることが可能だと思います。
また、今回の検証を通じて、Streamlitを活用した検証テンプレートをあらかじめ作成しておき、プロジェクトに応じて中身を調整していくという活用法も有効だと感じました。このアプローチを取ることで、様々なプロジェクトに簡単に流用できるほか、「あれを試したい」というアイデアが浮かんだ際にも、素早く検証を開始できるのではないかと思います。
生成AIの進化が加速する中、 「ビジネスアイデアをすぐ形にする」 ニーズは今後さらに高まっていくと感じています。AWSから日々発表される生成AI関連のアップデートをうまく活用しながら、便利で実用的な生成AIアプリケーションの開発をしていきたいな、と思います!
参考にさせていただいたもの
以下、本チャットボットを構築するにあたり、参考にさせていただいたものです。
-
aws-samples/genai-quickstart-pocs
- 今回のチャットボット作成においてもそうですが、生成AIを使ったアプリケーション開発に関してかなり知見が得られると感じたリポジトリでした
- 今回の検証で使用したコードも、一部こちらのサンプル実装を参考にさせていただいております
- ちなみにこのOSSでは、Streamlitを使った37種類のPoCのサンプルコードを試すことができます!
- こちらのブログで解説記事は書いているので、よければご覧ください
- 今回のチャットボット作成においてもそうですが、生成AIを使ったアプリケーション開発に関してかなり知見が得られると感じたリポジトリでした
-
Amazon Bedrock Converse API AWS 公式ドキュメント・boto3ドキュメント
- (当たり前ではありますが)Converse APIの仕組み、boto3での使い方などはここをしっかり確認することで理解が深まりました
最後まで読んでいただき、ありがとうございます!
Advent Calendar 2日目は@prinprinprrrさんの記事です!
25日間、2024 Jr.Championsの皆さんの熱い記事を是非ともご覧下さい!