概要
本記事は、アイレット株式会社 Advent Calendar 2024 24日目の記事です。
私自身、2024年はAWSの生成AIを使った、RAGの検証の案件に参画させていただき、さまざまな知見を得ることができた、と感じる一年でした。それを踏まえて、本記事では「AWSでRAGを実現する上で大事だと感じた考え方」について2024年の締めくくりとしてアウトプットしております。
AWSで、と記載はしましたが、
AWS以外のクラウドサービスにおいても当てはまる点もあるかも知れませんし、逆に他のクラウドサービスでは当てはまらない事項もあるかも知れません。自身の経験ベースでまとめておりますので、その点については予めご留意ください。
本記事では
Amazon Bedrock → Bedrock
Amazon Bedrock Knowledge Bases → Knowledge Bases
Amazon Kendra→ Kendra
Amazon S3→ S3
と表記しております。
AWSでRAGを実現する上で大事なこと
AWSの生成AIサービス(今回はBedrockとKendraを組み合わせたRAG)を実現する上で大事だと感じたことを3つに絞って整理します。
データソースとなるドキュメントの質を担保する重要性
※画像はGarbage in, garbage outより引用
「Garbage in, Garbage out」
データ分析や統計の世界ではよく言われる言葉ですが、「ゴミを入れればゴミが出てくる」という意味です。
RAGの世界でも、これが言えると強く実感しました。
例えば、Kendraを使って、RAGを実現するケース(データソースはS3)を考えてみましょう。当初、私はS3にデータを放り込んでおけば、いい感じに精度の出るRAGを実現できる、と考えていました。しかし、現実は違いました。実際には、以下のような部分でハマりました。
- そもそもKendraのデータソース↔︎indexとの同期の過程で読み込みに失敗するデータが一部混じっている
Kendraでは、データソースのドキュメントの同期に失敗するケースがあります。今回ハマったのは、テキストが画像として埋め込まれていたり、文書自体にそもそもテキストが含まれていないが故に失敗してしまった、という事例でした。
実際のエラー文は以下でした。
Document cannot be indexed since it contains no text to index and search on. Document must contain some text
これに対してはAdobe AcrobatのOCR機能、Amazon TextractなどのようなOCRサービス、tesseractや、PaddleOCRのようなライブラリを使用することが一つの選択肢として考えられました。
ただ、調査してみたところ以下のような結果でした。
- Adobe AcrobatでのOCR機能は、実装に組み込むのがやや煩雑そう
- Textractに関しては日本語のドキュメントには対応していない
- OCRのライブラリに関しては、キャッチアップの工数がかかりそう
これを踏まえ、以下のようなアプローチを行いました。
- 「Bedrock(Claude)で前段として書き起こしを行い、テキスト化→それを再度Kendraのデータソースに格納し、再度index化する」
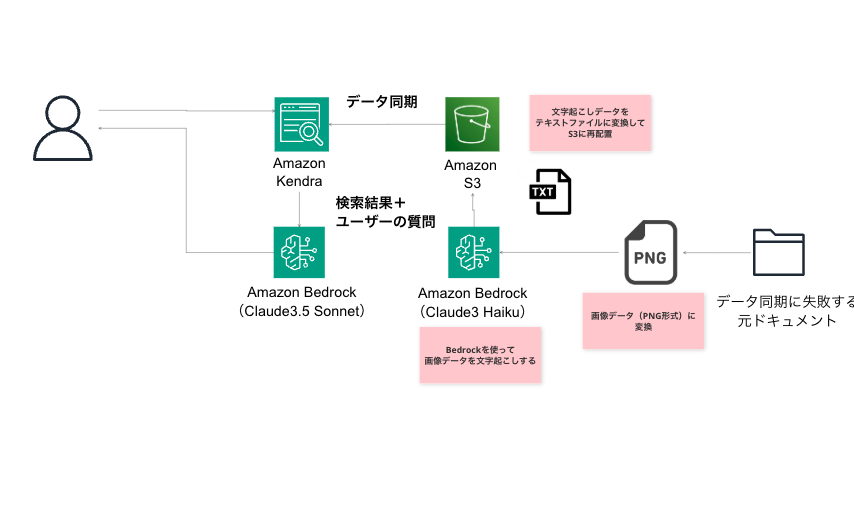
このアプローチでは、Bedrockの書き起こしの精度に回答精度は依存してしまいますが、体感としては比較的精度を高く書き起こしをしてくれている印象でした。
ちなみにですが、Bedrockの書き起こしについては、converseAPIを使用し、実装しました。
「可能な限り書き起こしして」というプロンプトを与えた上で、PDFファイルを一度画像に変換して、書き起こしをするような処理をしています。
4.5MB以上のファイルが一度にアップロードされると、API側でエラーとなってしまう(※)ので、
ページごとに分割して書き起こし→最後に結果を一つのファイルにまとめる、という方法を取りました。
※boto3のドキュメント(参照 Boto3 1.35.38 documentation)に記載があります。
処理は以下のコード(bedrock_extract_pdf.py)で行っています。
コード内でimportしているモジュールについては
「Streamlit×Bedrock×Kendraで作る! 多機能チャットボット」の、app_config.py/.envのファイルの記載をご覧ください。
- ざっくり要点
- 対象となるファイルは実施時点では、300ファイルとなかなか多く、将来増加することも考え、並列処理で効率的に処理を行うようにしています
- また、書き起こし結果は、ファイル名をそのままで、拡張子を.txtに変えたものをtranscription/フォルダに保存することで、フロント側で表示させる際に、「transcription/配下に、書き起こしデータがある場合は、書き起こしされる前のPDFドキュメントを回答の参照ドキュメントとしてユーザーに表示させる」といった制御を可能にしています
※ここではその部分の解説は省略
bedrock_extract_pdf.py
from app_config import AppConfig
import io
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
import fitz # NOTE pymupdfモジュールは"fitz"という名前でインポートする
from PIL import Image
import boto3
from botocore.client import Config
"""
Kendraのindex化に失敗しているPDFファイルを画像に変換し、Bedrockに書き起こし、その結果をテキストファイルとしてS3に再配置させる関数
"""
# .envに記載の環境情報読み込み
load_dotenv()
# AWSCLIに設定のprofileを元に、boto3のセッションを確立
boto3_session = boto3.Session(
region_name="ap-northeast-1", profile_name=os.getenv('profile_name'))
# Bedrock clientの初期化
bedrock = boto3_session.client('bedrock-runtime', 'ap-northeast-1',
endpoint_url='https://bedrock-runtime.ap-northeast-1.amazonaws.com', config=retries_config)
# S3クライアントの初期化
s3 = boto3_session.client('s3', region_name='ap-northeast-1')
# Kendraクライアントの初期化
kendra = boto3_session.client(
'kendra', region_name='ap-northeast-1')
# S3フォルダ内のPDFファイルを取得
def get_document_ids_from_s3(bucket_name, folder_name):
try:
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=folder_name)
pdf_files = [obj['Key'] for obj in response.get(
'Contents', []) if obj['Key'].endswith('.pdf')]
document_ids = [
f"s3://{bucket_name}/{pdf_key}" for pdf_key in pdf_files]
return document_ids
except Exception as e:
print(f"S3フォルダ内のファイル取得中にエラー: {e}")
return []
# Kendraからインデックス化状況を取得
def get_document_status(index_id, document_ids):
try:
status_list = []
batch_size = 10 # Kendra APIの制限
for i in range(0, len(document_ids), batch_size):
batch = document_ids[i:i + batch_size]
response = kendra.batch_get_document_status(
IndexId=index_id,
DocumentInfoList=[{"DocumentId": doc_id} for doc_id in batch]
)
status_list.extend(response.get('DocumentStatusList', []))
return status_list
except Exception as e:
print(f"Error fetching document status: {e}")
return []
# インデックス失敗ドキュメントをフィルタリング
def filter_failed_documents(status_list):
failed_docs = [status['DocumentId']
for status in status_list if status['DocumentStatus'] == 'FAILED']
return failed_docs
# PDFを画像に変換
def pdf_to_images(pdf_content):
images = []
pdf_document = fitz.open(stream=pdf_content, filetype="pdf")
for page_number in range(len(pdf_document)):
page = pdf_document[page_number]
pix = page.get_pixmap(dpi=100) # Claudeに読ませるのにdpiは100がちょうど良さそう
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
img_bytes = io.BytesIO()
image.save(img_bytes, format="PNG")
img_bytes.seek(0)
images.append(img_bytes.getvalue())
print(f"ページ {page_number + 1} を画像に変換しました。")
pdf_document.close()
return images
# Claudeで画像を処理
def process_document(bucket_name, doc_id):
try:
pdf_key = doc_id.replace("s3://", "").split("/", 1)[1]
response = s3.get_object(Bucket=bucket_name, Key=pdf_key)
pdf_content = response['Body'].read()
# PDFを画像に変換
images = pdf_to_images(pdf_content)
transcription_parts = []
# 各画像をClaudeで処理
for idx, image_bytes in enumerate(images):
bedrock_response = bedrock.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=[
{
"role": "user",
"content": [
{"image": {"format": "png",
"source": {"bytes": image_bytes}}},
{"text": "この画像の内容を可能な限り詳細にテキスト化してください。"}
]
}
],
inferenceConfig={"maxTokens": 4096, "temperature": 0}
)
transcription = bedrock_response["output"]["message"]["content"][0]["text"]
transcription_parts.append(transcription)
# 結果を統合してS3に保存
final_transcription = "\n\n".join(transcription_parts)
transcription_key = pdf_key.replace(
"XXXXXX", "transcription/").replace(".pdf", ".txt")
s3.put_object(Bucket=bucket_name, Key=transcription_key,
Body=final_transcription.encode('utf-8'), ContentType='text/plain')
return doc_id, "Success"
except Exception as e:
print(f"Error processing {doc_id}: {e}")
return doc_id, f"Error: {e}"
# 並列処理で失敗ドキュメントを処理
def process_failed_documents_in_parallel(bucket_name, failed_doc_ids, max_workers=10):
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_doc = {executor.submit(
process_document, bucket_name, doc_id): doc_id for doc_id in failed_doc_ids}
for future in as_completed(future_to_doc):
doc_id = future_to_doc[future]
try:
result = future.result()
results.append(result)
except Exception as e:
print(f"Error processing document {doc_id}: {e}")
return results
# メインフロー
def main(bucket_name, index_id, folder_name):
document_ids = get_document_ids_from_s3(bucket_name, folder_name)
if not document_ids:
print("対象フォルダ内にPDFがありません。")
return
# Kendraインデックス状況を確認
status_list = get_document_status(index_id, document_ids)
failed_docs = filter_failed_documents(status_list)
if not failed_docs:
print("インデックス化に失敗しているドキュメントはありません。")
return
print(f"インデックス化に失敗しているドキュメント: {len(failed_docs)} 件")
# 失敗したドキュメントを並列処理で処理
results = process_failed_documents_in_parallel(bucket_name, failed_docs)
for doc_id, status in results:
print(f"{doc_id}: {status}")
# スクリプト実行
if __name__ == "__main__":
bucket_name = os.getenv('bucket_name')
index_id = os.getenv('kendra_index')
folder_name = "XXXXX(index化失敗ドキュメントが存在するフォルダ)/"
main(bucket_name, index_id, folder_name)
検索の仕組みにも目を向けることの重要性
私自身、検証を進めている中で、以下の課題に直面しました。
- データソースに大量のドキュメントがあるため、狙った情報が検索結果として出てこない。結果として生成AIによる回答が期待外れなものになってしまう
これに対しては、Kendraの「ファセット検索」を使って解決しました。(参照 Amazon Kendraによる検索結果のチューニング- AWS Blog)
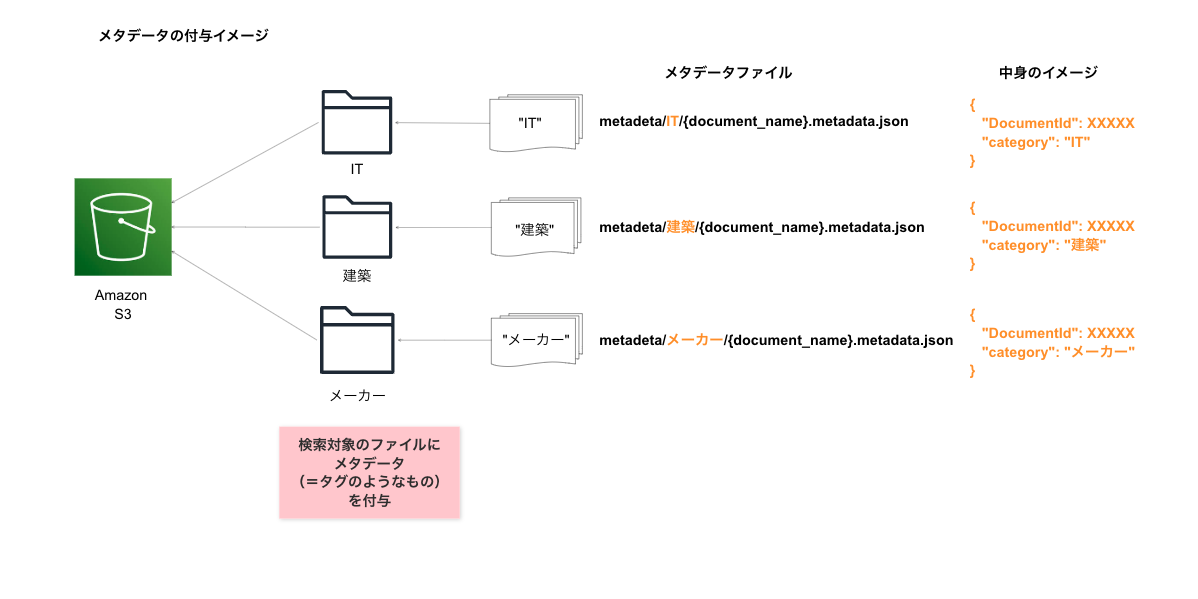
仕組みとしては、データソースにメタデータを付与して、ドキュメントに"タグ"をつけ、検索結果をフィルタリングする、という方法です。以下の図のように、データソースに指定しているS3バケットの中にmetadata.jsonという拡張子がついたメタデータファイルを作成し、S3のDocumentIdと、付与したいカテゴリの名前をつけたものを記載し、元ドキュメントとの紐付けを行うことができます。
カテゴリでのフィルタリングだけでなく、日付や著者、カスタムの属性フィルタリングなど、他にも様々な工夫ができます。
詳細はAmazon S3 document metadataをご覧ください。
KendraのqueryAPIを使う場合だと、以下のような実装(sample.py)で簡単に実装できることがわかりました。
boto3だと、以下の部分がポイントとなる箇所です。(参照 Boto3 1.35.39 documentation)
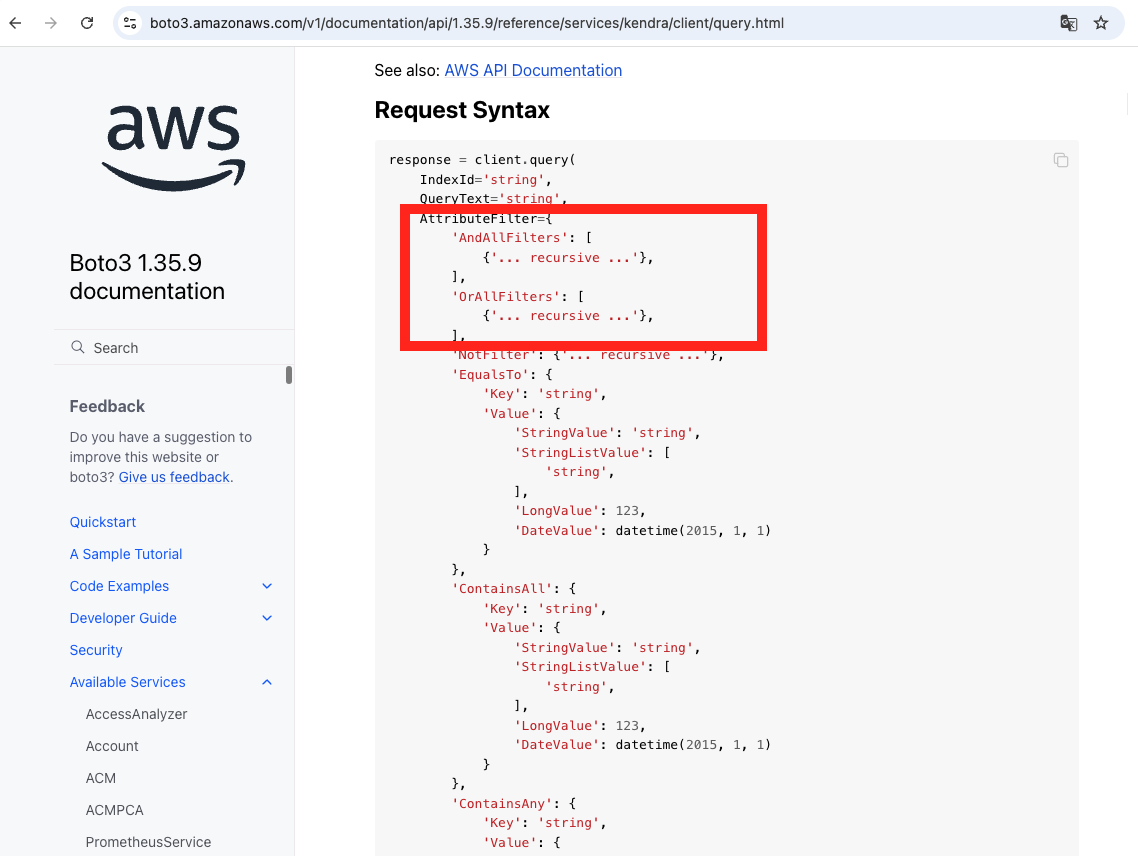


フロント側の実装の解説は省略しますが、画像のように、ボタンで検索対象を絞り込んで、生成AIに渡る回答を絞り込んだ上で回答を生成させる制御も可能です。(Streamlitで実装しています)
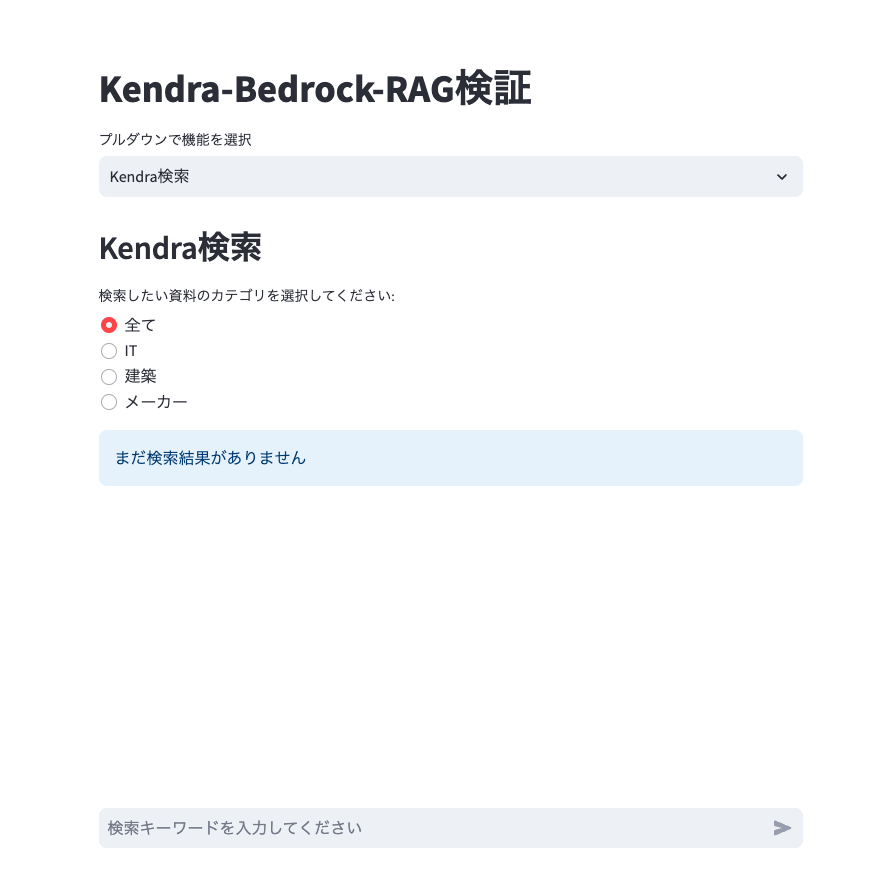
import boto3
# kendra clientの初期化
# boto3セッションの定義
boto3_session =boto3.session.Session(profile_name=os.getenv('profile_name'))
kendra = boto3_session.client('kendra', region_name="ap-northeast-1")
# ユーザーが選択したカテゴリの値に応じて、検索条件を動的に構築
# デフォルトは検索条件の絞り込みなし(_language_codeの絞り込みのみ)
attribute_filter = {
"AndAllFilters": [
{
"EqualsTo": {
"Key": "_language_code",
"Value": {
"StringValue": "ja"
}
}
}
]
}
# "choice_1", "choice_2", "choice_3"が送られてきた時の絞り込み条件(AndAllFiltersのリストの要素に追加する)
additional_attribute_filter = {
"OrAllFilters": [
{
"EqualsTo": {
"Key": "_category",
"Value": {
"StringValue": selected_category_key #フロント側で検索対象のドキュメントを選択させる
}
}
}
]
}
# 「全て」以外が選択された時は検索条件の絞り込みを行う
if selected_category_key != "all":
attribute_filter["AndAllFilters"].append(additional_attribute_filter)
# queryAPIを使ってKendraを呼び出す
kendra_response = kendra.query(
IndexId=os.getenv('kendra_index'), # Put INDEX in .env file
QueryText=question,
PageNumber=1,
PageSize=30,
AttributeFilter=attribute_filter
)
他にも、query APIとretrieve APIでは、検索の内部的な仕組みに違いがある(※)
など、生成AIによる回答の前段の部分一つとってもいろいろな改善のアプローチがあることが分かります。
query APIとretrieve APIの違い
retrieve APIのドキュメントには、以下のような記載がされています。
https://docs.aws.amazon.com/cli/latest/reference/kendra/retrieve.html
This API is similar to the Query API. However, by default, the Query API only returns excerpt passages of up to 100 token words. With the Retrieve API, you can retrieve longer passages of up to 200 token words and up to 100 semantically relevant passages. This doesn't include question-answer or FAQ type responses from your index. The passages are text excerpts that can be semantically extracted from multiple documents and multiple parts of the same document. If in extreme cases your documents produce zero passages using the Retrieve API, you can alternatively use the Query API and its types of responses.
以下の記述から、いくつか比較項目を抽出してみました。
※「パッセージ」=ユーザーのクエリに関連すると判定され、抽出された文章
| 比較項目 | Query API | Retrieve API |
|---|---|---|
| 返されるパッセージの長さ | 最大 100 トークン(約100単語) | 最大 200 トークン(約200単語) |
| 返されるパッセージの数 | 最大 10 パッセージ | 最大 100 パッセージ |
| 返される内容 | 検索クエリに関連する抜粋 | 検索クエリに関連する長めの抜粋(複数のドキュメントから) |
| パッセージの関連性 | クエリに対して関連するテキストの抜粋を返す | セマンティックに(意味的に)関連するテキストの抜粋を返す |
RAG検証の結果の定量化/評価基準の事前定義
PoC(概念実証)を行う場合は、ある検証の目的があり、それを踏まえて検証の方針を考え、実施していく流れが基本的かと思います。
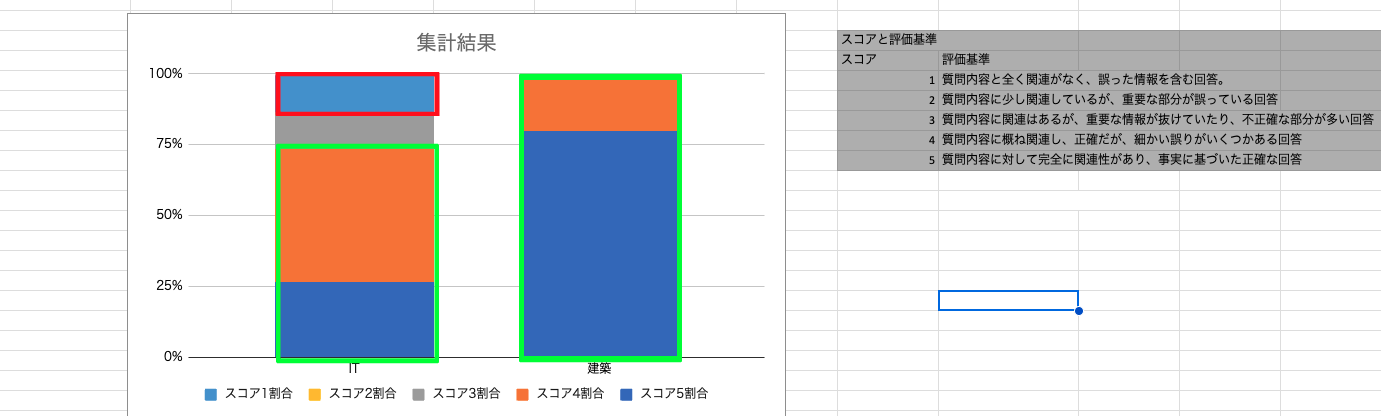
その際、(RAGに限らずですが)「いい回答が返ってきた」という定性的な結果だけでは、評価者(=お客様)はどう判断していいか分かりません。不確実な回答の可能性を孕む生成AIに関する検証だからこそ、結果を定量的に評価できるようにしておくことが大事なのでは、と感じました。
実際、以下のように検証結果(画像は実際のものではなくサンプル)をスプレッドシートにまとめ、可視化するようにしていました。
なお、私が検証を行った際は実施しませんでしたが、期待値や、実施規模、期間などを鑑みて、必要に応じて、RagasのようなRAG評価ツールを導入してみるのもいいな、と感じました。(導入してみたい気持ちもありましたが、検証の実施期間と自身の知識レベルを鑑み断念しました。)
また、定量的に結果を整理するためには、「どんな質問をして」「どんな回答が返ってきたら期待通りなのか」という、質問のユースケースと回答の期待値を事前に丁寧にヒアリングしておくことが重要だと感じました。だからこそ、顧客の業務理解、という観点も大事な気がしています。
また、AWS re:Invent 2024 で新たにプレビュー版として発表されたKnowledge Basesの RAG Evaluation機能(参照)も今後の活用の検討材料として期待できそうです。
まとめ
今回は、「AWSで、RAGを実現する上で大事だと感じたこと」を、経験ベースでまとめさせていただきました。
RAGシステムを運用するにあたっては、検索の前段の仕組みの改善、検索の仕組みの改善、ほかにもたくさん考慮すべきことがあるかな、と経験を通して実感しました。
だからこそ、奥の深さがありますし、工夫次第で結果を改善できる面白さがある、と感じています。
ここまで読んでいただき、ありがとうございました。
拙い記事ではありますが、この記事が皆さんの少しでもお役に立てれば幸いです。