概要
業務の中で、Streamlitで作成し、EC2にデプロイしたRAGアプリケーションを以下の要件で実装する必要があり、その際得た知見を整理してブログの形にまとめました。
- お名前.comで作成したドメインと紐付け、ネームサーバーの管理はAmazon Route 53 上でできるようにする
- HTTPS経由でセキュアにアクセスしたい
Streamlit Cloudでもデプロイできるのでは?という意見もあるかと思われますが、今回は「敢えて」EC2でデプロイする方法を実施しています。(詳細は後述)
前提) EC2上に構築したStreamlitアプリの特徴
- EC2上でStreamlitアプリを起動すると、デフォルトでは
http://で起動してしまうので、安全性の観点で少し不安が残る
→顧客要件で、http://でのアクセスは許可されておらず、https://でのアクセス設定が必要な場合も考えられる。
事前準備
お名前.comでドメインを払い出す、Route 53にドメイン管理を移管
今回は検証用に、お名前.comでmaeno-dev.comというドメインを取得しました。
ホストゾーンの作成
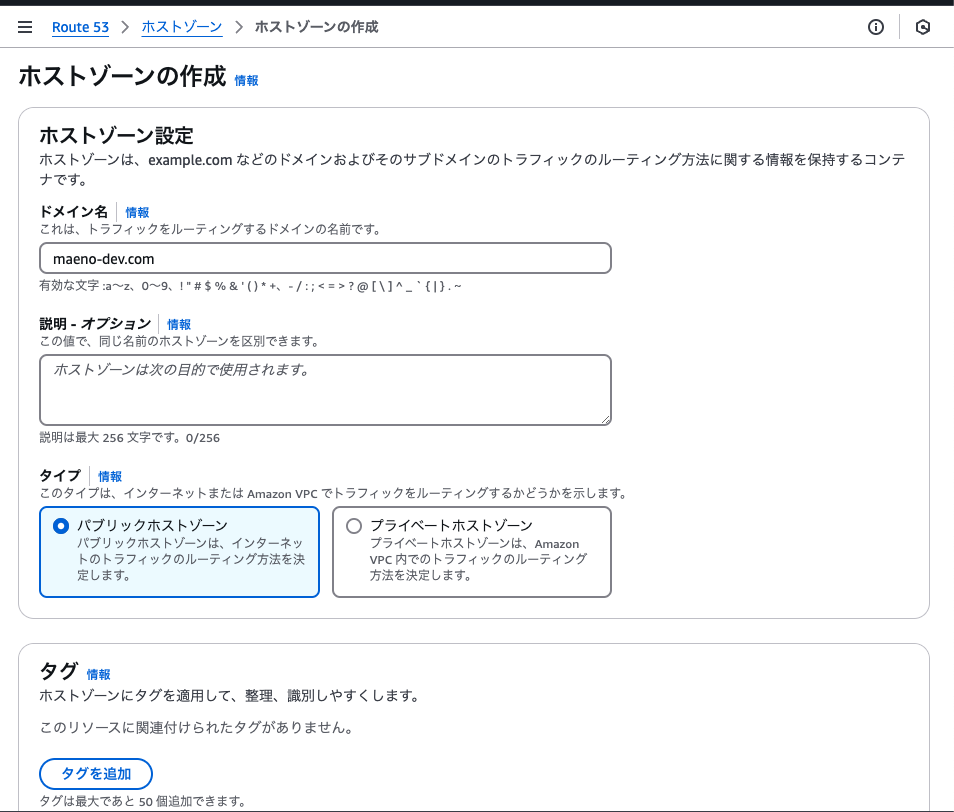
Aレコードの作成
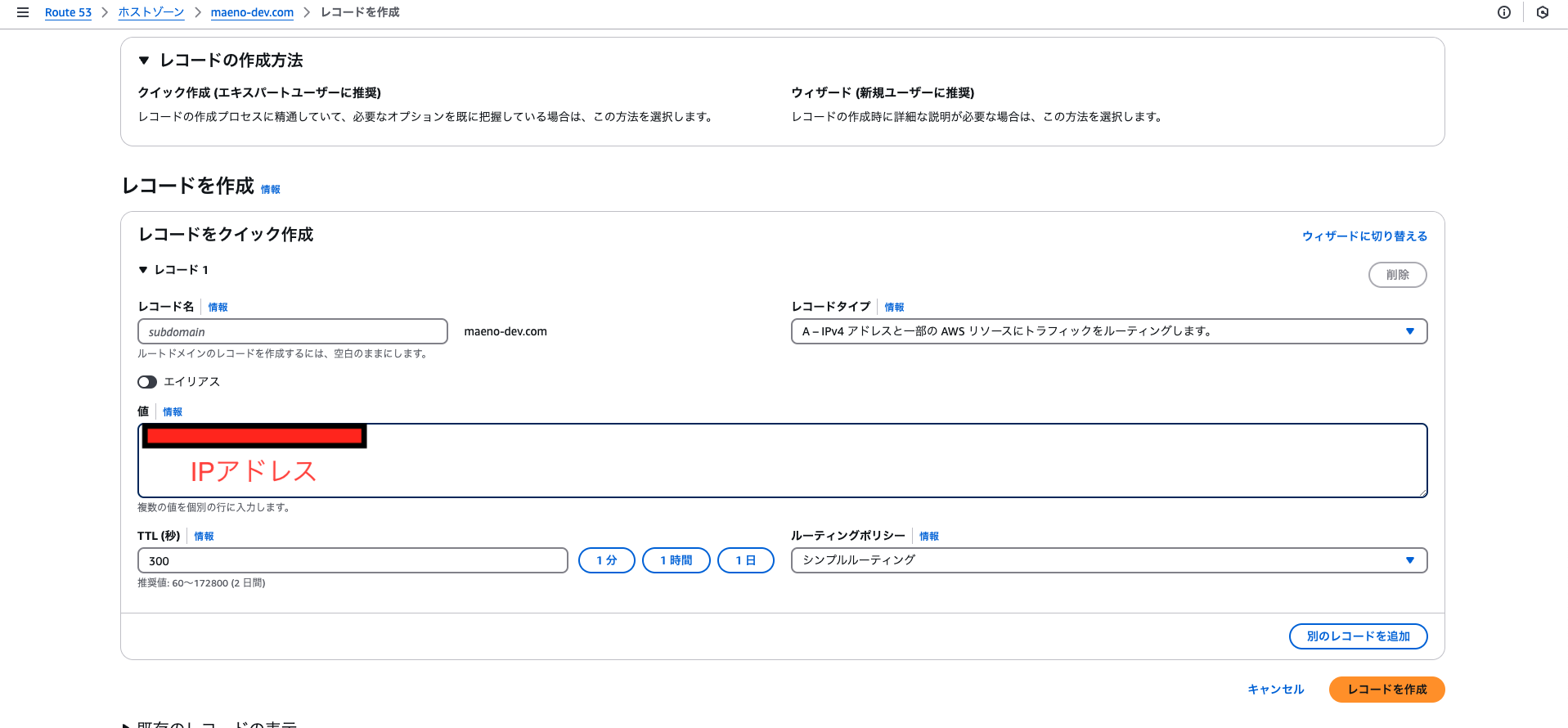
NSレコードの確認

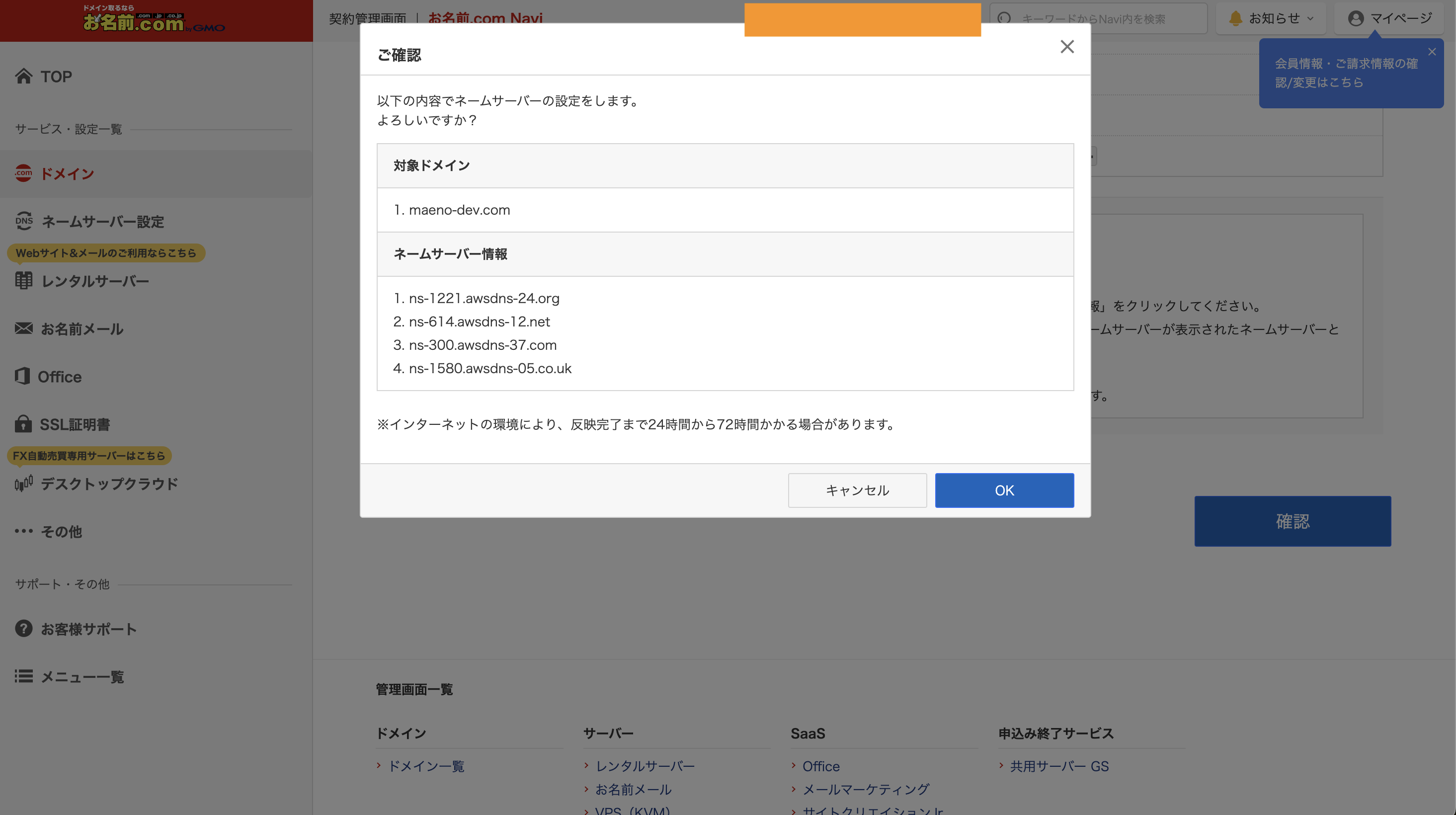
ネームサーバーの管理を、お名前.comからRoute 53に移管するために設定変更
お名前.comの、ドメインメニューから、ネームサーバー設定を選択し、ドメインを選択し、その他のネームサーバーを使うという部分で、先ほどの画面で表示されていた4つの名前を記載します。

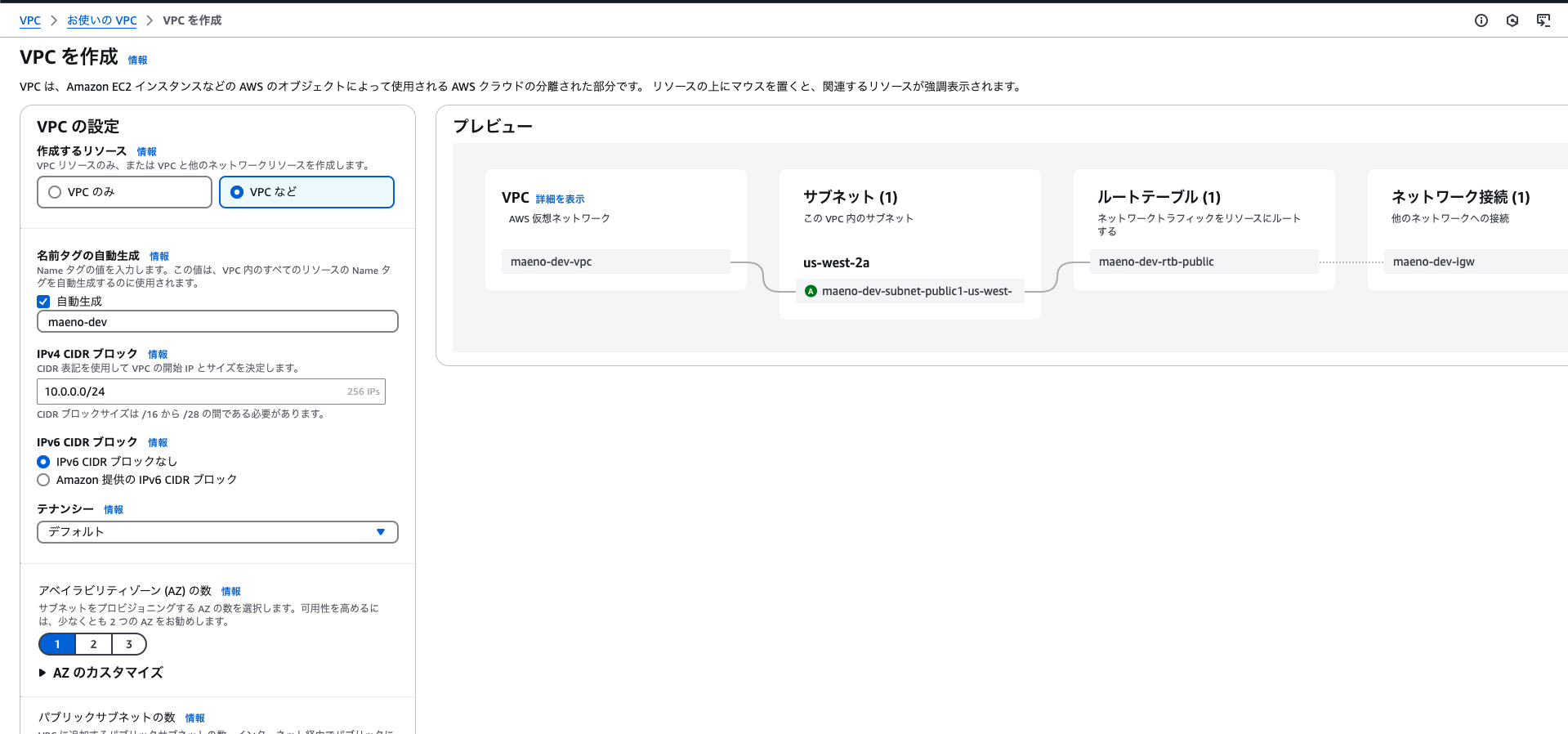
デプロイ用のEC2の作成、ローカルで作成したソースコードの移植
VPC作成
VPCなどを選択し、サブネットも同時に作成します。
EC2作成
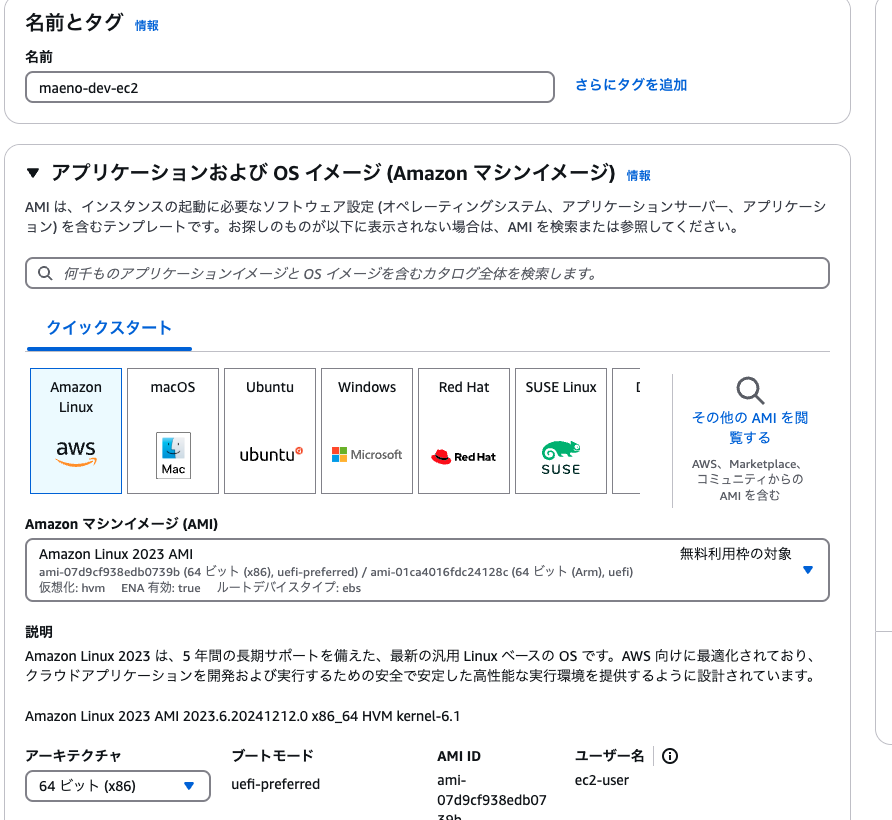

作成したVPC、サブネットを選択。
インスタンスタイプはデフォルトの選択のままで進めます。
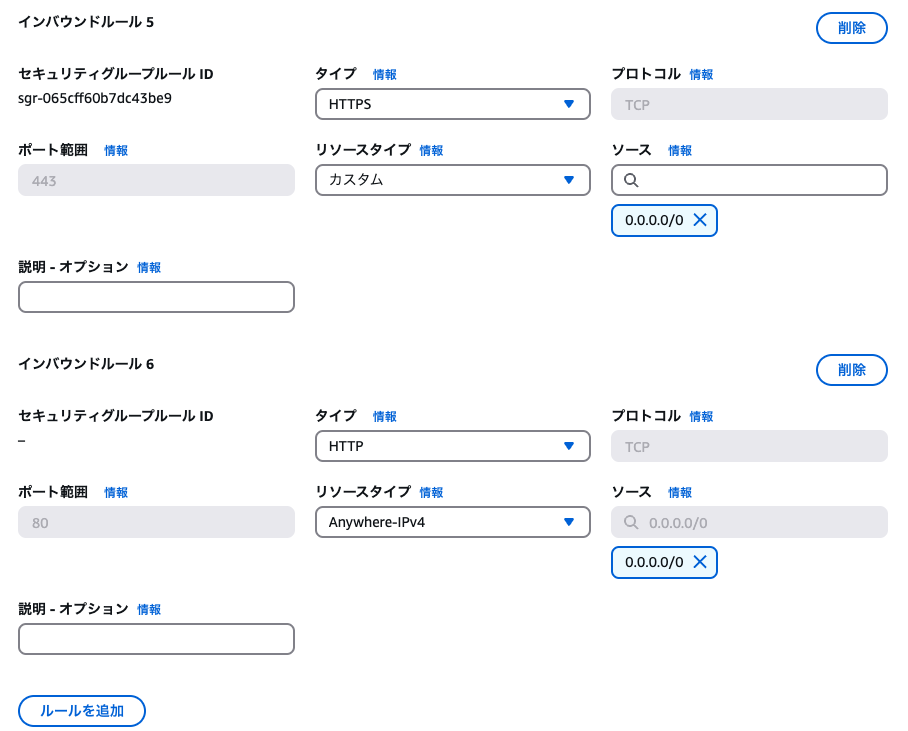
セキュリティグループは、HTTP化対応を行うまでは、自身のIPアドレスに加えて、HTTPS/HTTPで、全てのIPを許可しています。(おそらく、SSL証明書を発行する際、外部の認証機関からアクセスが入るため、自身のIPのみの許可では上手くいかなかった)証明書の設定が完了後、以下のルールを削除しました。
基本的には許可したいIPのみを指定し、安全にアクセスができるようにしましょう。
ローカルで作成したRAGアプリケーションをclone
ローカルで作成したソースコードをpullするために、gitをインストールします。
$ sudo yum install git-all
その後、
$ ssh-keygen -t rsa
で認証鍵を生成、公開鍵をGitHubに登録することで、EC2とリポジトリ間でSSHを可能にします。
その後以下コマンドでソースコードをcloneします。
$ git clone git@github.com:y-mae-dev/streamlit-rag-app.git
手順
0.RAGアプリケーションをローカルで準備
今回は Streamlit×Bedrock×Kendraで作る! 多機能チャットボットで紹介したアプリを使用します。(※一部アップデートを加えております。記事の本旨から逸れるためここでは解説しませんが、「参考)ソースコード」の項でソースコードは記載いたしますので参考にしていただければと思います。)
1.ローカル→作成したEC2インスタンスにSSH
.ssh/config 配下に 以下を記載しておきます。
Host streamlit-rag-app
HostName (EC2のパブリックIPアドレス)
User ec2-user
Port 22
IdentityFile ~/.ssh/(秘密鍵の名前)
$ ssh streamlit-rag-app
そうすることで上記コマンドを使用してEC2へアクセスできるようになります。
2. サーバー側でのリバースプロキシの設定
EC2でStreamlitを起動し、独自ドメインでHTTPS接続するまで(備忘録)
を参考にさせていただきました。
ここが今回の肝になります。
2.1 nginxのインストール
sudu yum install nginx 実行結果
[ec2-user@ip-10-0-0-10 ~]$ sudo yum install nginx
Last metadata expiration check: 7:51:01 ago on Mon Dec 30 22:17:27 2024.
Dependencies resolved.
================================================================================================================================================================================================================
Package Architecture Version Repository Size
================================================================================================================================================================================================================
Installing:
nginx x86_64 1:1.26.2-1.amzn2023.0.1 amazonlinux 33 k
Installing dependencies:
gperftools-libs x86_64 2.9.1-1.amzn2023.0.3 amazonlinux 308 k
libunwind x86_64 1.4.0-5.amzn2023.0.2 amazonlinux 66 k
nginx-core x86_64 1:1.26.2-1.amzn2023.0.1 amazonlinux 670 k
nginx-filesystem noarch 1:1.26.2-1.amzn2023.0.1 amazonlinux 9.9 k
nginx-mimetypes noarch 2.1.49-3.amzn2023.0.3 amazonlinux 21 k
Transaction Summary
================================================================================================================================================================================================================
Install 6 Packages
Total download size: 1.1 M
Installed size: 3.6 M
Is this ok [y/N]: y
Downloading Packages:
(1/6): libunwind-1.4.0-5.amzn2023.0.2.x86_64.rpm 1.3 MB/s | 66 kB 00:00
(2/6): nginx-1.26.2-1.amzn2023.0.1.x86_64.rpm 604 kB/s | 33 kB 00:00
(3/6): gperftools-libs-2.9.1-1.amzn2023.0.3.x86_64.rpm 4.6 MB/s | 308 kB 00:00
(4/6): nginx-filesystem-1.26.2-1.amzn2023.0.1.noarch.rpm 605 kB/s | 9.9 kB 00:00
(5/6): nginx-mimetypes-2.1.49-3.amzn2023.0.3.noarch.rpm 700 kB/s | 21 kB 00:00
(6/6): nginx-core-1.26.2-1.amzn2023.0.1.x86_64.rpm 12 MB/s | 670 kB 00:00
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Total 6.8 MB/s | 1.1 MB 00:00
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Running scriptlet: nginx-filesystem-1:1.26.2-1.amzn2023.0.1.noarch 1/6
Installing : nginx-filesystem-1:1.26.2-1.amzn2023.0.1.noarch 1/6
Installing : nginx-mimetypes-2.1.49-3.amzn2023.0.3.noarch 2/6
Installing : libunwind-1.4.0-5.amzn2023.0.2.x86_64 3/6
Installing : gperftools-libs-2.9.1-1.amzn2023.0.3.x86_64 4/6
Installing : nginx-core-1:1.26.2-1.amzn2023.0.1.x86_64 5/6
Installing : nginx-1:1.26.2-1.amzn2023.0.1.x86_64 6/6
Running scriptlet: nginx-1:1.26.2-1.amzn2023.0.1.x86_64 6/6
Verifying : gperftools-libs-2.9.1-1.amzn2023.0.3.x86_64 1/6
Verifying : libunwind-1.4.0-5.amzn2023.0.2.x86_64 2/6
Verifying : nginx-1:1.26.2-1.amzn2023.0.1.x86_64 3/6
Verifying : nginx-core-1:1.26.2-1.amzn2023.0.1.x86_64 4/6
Verifying : nginx-filesystem-1:1.26.2-1.amzn2023.0.1.noarch 5/6
Verifying : nginx-mimetypes-2.1.49-3.amzn2023.0.3.noarch 6/6
Installed:
gperftools-libs-2.9.1-1.amzn2023.0.3.x86_64 libunwind-1.4.0-5.amzn2023.0.2.x86_64 nginx-1:1.26.2-1.amzn2023.0.1.x86_64 nginx-core-1:1.26.2-1.amzn2023.0.1.x86_64
nginx-filesystem-1:1.26.2-1.amzn2023.0.1.noarch nginx-mimetypes-2.1.49-3.amzn2023.0.3.noarch
Complete!
2.2 nginxの起動
[ec2-user@ip-10-0-0-10 ~]$ sudo service nginx start
Redirecting to /bin/systemctl start nginx.service
2.3 設定ファイルの修正
2つのディレクトリを作成し、設定ファイル(nginx.conf)を一部変更します。
$ sudo mkdir /etc/nginx/sites-available
$ sudo mkdir /etc/nginx/sites-enabled
$ sudo vi /etc/nginx/nginx.conf
include /etc/nginx/conf.d/*.conf;
の下に、
include /etc/nginx/sites-enabled/*;
を追加
$ sudo chmod 777 /etc/nginx/sites-available
$ sudo chmod 777 /etc/nginx/sites-enabled
を実行し、フォルダ内の権限を変更
[ec2-user@ip-10-0-0-10 ~]$ echo '''server {
listen 80;
server_name maeno-dev.com;
location / {
proxy_pass http://0.0.0.0:8501/;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}''' > /etc/nginx/sites-available/maeno-dev.com
を実行し、nginxのルーティング設定を追加します。
これによって、httpのアクセスが8501にルーティングされます。
(streamlit-rag-app) [ec2-user@ip-10-0-0-10 streamlit-rag-app]$ streamlit hello
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
Welcome to Streamlit. Check out our demo in your browser.
URL: http://maeno-dev.com:8501
Ready to create your own Python apps super quickly?
Head over to https://docs.streamlit.io
May you create awesome apps!
表示されているURLにアクセスしてみると、以下のような画面になり、通信が転送できていることがわかります。
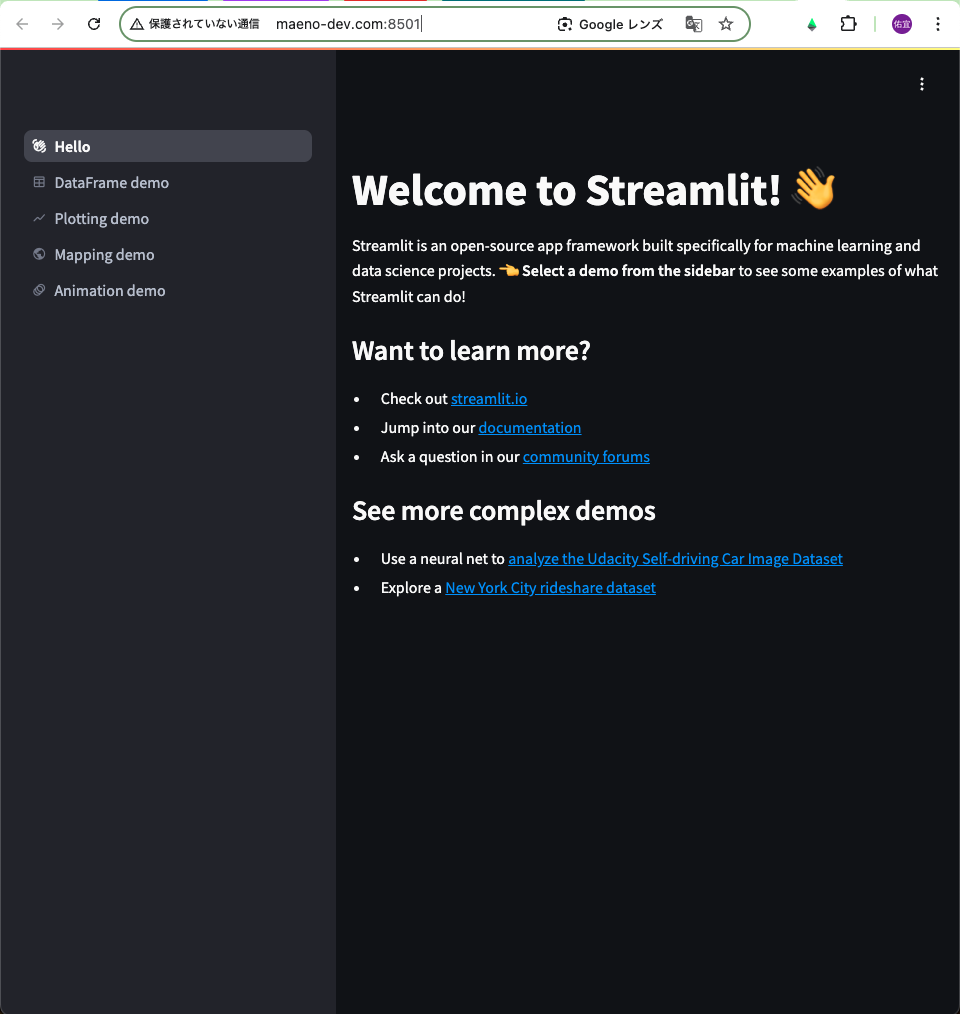
streamlit hello
を実行すると、streamlitが提供するWelcomeページに遷移します。
ここまではhttp接続を行い、アプリを起動できる状態にしました。
ただ、本記事の目的はhttps接続できるようにすることでした。続いてのステップとして、無料かつ自動でSSL証明書を発行できるツールであるcertbotを使って、SSL証明書を発行し登録します。
まずは、certbotをインストールします。(実行結果は以下)
sudo yum install certbot-nginx実行結果
[ec2-user@ip-10-0-0-10 ~]$ sudo yum install certbot-nginx
Last metadata expiration check: 10:25:55 ago on Mon Dec 30 22:17:27 2024.
Dependencies resolved.
=======================================================================
Package Arch Version Repository Size
=======================================================================
Installing:
python3-certbot-nginx noarch 2.6.0-4.amzn2023.0.1 amazonlinux 158 k
Installing dependencies:
fontawesome-fonts noarch 1:4.7.0-11.amzn2023.0.2
amazonlinux 205 k
python3-acme noarch 2.6.0-4.amzn2023.0.1 amazonlinux 161 k
python3-certbot noarch 2.6.0-4.amzn2023.0.1 amazonlinux 677 k
python3-configargparse noarch 1.7-1.amzn2023 amazonlinux 45 k
python3-josepy noarch 1.13.0-6.amzn2023 amazonlinux 61 k
python3-parsedatetime noarch 2.6-10.amzn2023 amazonlinux 80 k
python3-pyOpenSSL noarch 21.0.0-1.amzn2023.0.2 amazonlinux 92 k
python3-pyparsing noarch 2.4.7-6.amzn2023.0.2 amazonlinux 152 k
python3-pyrfc3339 noarch 1.1-16.amzn2023 amazonlinux 19 k
Installing weak dependencies:
certbot noarch 2.6.0-4.amzn2023.0.1 amazonlinux 49 k
python-josepy-doc noarch 1.13.0-6.amzn2023 amazonlinux 20 k
Transaction Summary
=======================================================================
Install 12 Packages
Total download size: 1.7 M
Installed size: 7.8 M
Is this ok [y/N]: y
Downloading Packages:
(1/12): python-josepy-doc-1.13.0-6.amz 303 kB/s | 20 kB 00:00
(2/12): certbot-2.6.0-4.amzn2023.0.1.n 607 kB/s | 49 kB 00:00
(3/12): fontawesome-fonts-4.7.0-11.amz 1.7 MB/s | 205 kB 00:00
(4/12): python3-acme-2.6.0-4.amzn2023. 2.3 MB/s | 161 kB 00:00
(5/12): python3-configargparse-1.7-1.a 1.1 MB/s | 45 kB 00:00
(6/12): python3-certbot-nginx-2.6.0-4. 2.4 MB/s | 158 kB 00:00
(7/12): python3-certbot-2.6.0-4.amzn20 6.0 MB/s | 677 kB 00:00
(8/12): python3-josepy-1.13.0-6.amzn20 1.5 MB/s | 61 kB 00:00
(9/12): python3-pyOpenSSL-21.0.0-1.amz 1.9 MB/s | 92 kB 00:00
(10/12): python3-pyparsing-2.4.7-6.amz 4.3 MB/s | 152 kB 00:00
(11/12): python3-parsedatetime-2.6-10. 1.1 MB/s | 80 kB 00:00
(12/12): python3-pyrfc3339-1.1-16.amzn 815 kB/s | 19 kB 00:00
-----------------------------------------------------------------------
Total 5.2 MB/s | 1.7 MB 00:00
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Installing : python3-pyOpenSSL-21.0.0-1.amzn2023.0.2.n 1/12
Installing : python3-pyrfc3339-1.1-16.amzn2023.noarch 2/12
Installing : python3-pyparsing-2.4.7-6.amzn2023.0.2.no 3/12
Installing : python3-parsedatetime-2.6-10.amzn2023.noa 4/12
Installing : python3-configargparse-1.7-1.amzn2023.noa 5/12
Installing : python-josepy-doc-1.13.0-6.amzn2023.noarc 6/12
Installing : python3-josepy-1.13.0-6.amzn2023.noarch 7/12
Installing : python3-acme-2.6.0-4.amzn2023.0.1.noarch 8/12
Installing : python3-certbot-2.6.0-4.amzn2023.0.1.noar 9/12
Installing : fontawesome-fonts-1:4.7.0-11.amzn2023.0.2 10/12
Installing : certbot-2.6.0-4.amzn2023.0.1.noarch 11/12
Running scriptlet: certbot-2.6.0-4.amzn2023.0.1.noarch 11/12
Certbot auto renewal timer is not started by default.
Run 'systemctl start certbot-renew.timer' to enable automatic renewals.
Installing : python3-certbot-nginx-2.6.0-4.amzn2023.0. 12/12
Running scriptlet: python3-certbot-nginx-2.6.0-4.amzn2023.0. 12/12
Verifying : certbot-2.6.0-4.amzn2023.0.1.noarch 1/12
Verifying : fontawesome-fonts-1:4.7.0-11.amzn2023.0.2 2/12
Verifying : python-josepy-doc-1.13.0-6.amzn2023.noarc 3/12
Verifying : python3-acme-2.6.0-4.amzn2023.0.1.noarch 4/12
Verifying : python3-certbot-2.6.0-4.amzn2023.0.1.noar 5/12
Verifying : python3-certbot-nginx-2.6.0-4.amzn2023.0. 6/12
Verifying : python3-configargparse-1.7-1.amzn2023.noa 7/12
Verifying : python3-josepy-1.13.0-6.amzn2023.noarch 8/12
Verifying : python3-parsedatetime-2.6-10.amzn2023.noa 9/12
Verifying : python3-pyOpenSSL-21.0.0-1.amzn2023.0.2.n 10/12
Verifying : python3-pyparsing-2.4.7-6.amzn2023.0.2.no 11/12
Verifying : python3-pyrfc3339-1.1-16.amzn2023.noarch 12/12
Installed:
certbot-2.6.0-4.amzn2023.0.1.noarch
fontawesome-fonts-1:4.7.0-11.amzn2023.0.2.noarch
python-josepy-doc-1.13.0-6.amzn2023.noarch
python3-acme-2.6.0-4.amzn2023.0.1.noarch
python3-certbot-2.6.0-4.amzn2023.0.1.noarch
python3-certbot-nginx-2.6.0-4.amzn2023.0.1.noarch
python3-configargparse-1.7-1.amzn2023.noarch
python3-josepy-1.13.0-6.amzn2023.noarch
python3-parsedatetime-2.6-10.amzn2023.noarch
python3-pyOpenSSL-21.0.0-1.amzn2023.0.2.noarch
python3-pyparsing-2.4.7-6.amzn2023.0.2.noarch
python3-pyrfc3339-1.1-16.amzn2023.noarch
Complete!
続いて、以下コマンドを実行します。
$ sudo certbot --nginx
このコマンドは、Let’s Encrypt を使って SSL/TLS 証明書を取得し、自動的に Nginx に設定を追加するものです。以下が実行結果(一部)です。
[ec2-user@ip-10-0-0-10 ~]$ sudo certbot --nginx
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Please enter the domain name(s) you would like on your certificate (comma and/or
space separated) (Enter 'c' to cancel): maeno-dev.com
Requesting a certificate for maeno-dev.com
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/maeno-dev.com/fullchain.pem
Key is saved at: /etc/letsencrypt/live/maeno-dev.com/privkey.pem
This certificate expires on 2025-03-31.
These files will be updated when the certificate renews.
Certbot has set up a scheduled task to automatically renew this certificate in the background.
Deploying certificate
Could not install certificate
NEXT STEPS:
- The certificate was saved, but could not be installed (installer: nginx). After fixing the error shown below, try installing it again by running:
certbot install --cert-name maeno-dev.com
Could not automatically find a matching server block for maeno-dev.com. Set the `server_name` directive to use the Nginx installer.
Ask for help or search for solutions at https://community.letsencrypt.org. See the logfile /var/log/letsencrypt/letsencrypt.log or re-run Certbot with -v for more details.
どうやらSSL証明書は登録できましたが、nginxにインストールできなかったようです。
もう一度手順を見直してみたところ、下記二つの対応が漏れていたようでした。
- 仮想ホスト
maeno-dev.comの設定を有効化 - nginxの再起動を行い、設定の反映
ln -s /etc/nginx/sites-available/maeno-dev.com /etc/nginx/sites-enabled/maeno-dev.com
[ec2-user@ip-10-0-0-10 ~]$ sudo service nginx restart
Redirecting to /bin/systemctl restart nginx.service
Successfully deployed certificate for maeno-dev.com to /etc/nginx/sites-enabled/maeno-dev.com
Congratulations! You have successfully enabled HTTPS on https://maeno-dev.com
上記のように、最終的に You have successfully enabled HTTPS on https://(ドメイン名)というような表示が出ればHTTPS化の作業は完了です。
4.Streamlitアプリを起動、https://ドメイン名でアクセスできるか確認

画面のように、ドメイン名を当てた状態で、サンプルアプリケーションを起動できたことが確認できました。
ここでTips
nohup streamlit run app.py &
とすれば、アプリをバックグラウンドで常時起動することができます。
バックグラウンドで起動しない場合、以下のような問題が発生します。
- ローカル→EC2との接続が切れてしまった際にアプリとの接続も切れてしまう
- ターミナルが操作できない(アプリ起動時に、別ターミナルを開かないと、他のコマンドが打てない)
そのためアプリケーションを実際に誰かに公開する場合は、バックグラウンドで常時起動させておくのが運用上よいと思います。
EC2 vs Streamlit Community Cloud
EC2にStreamlitアプリをデプロイする場合と、Streamlit Community Cloudを比較するべく、セキュリティ、労力、コストの観点から比較してみました。
安全性を重視したいならEC2へのデプロイ、お手軽さを重視したいならStreamlit Community Cloudへのデプロイが良さそうですね。
| 比較項目 | EC2へのデプロイ | Streamlit Community Cloudへのデプロイ |
|---|---|---|
| セキュリティ | ・SGにおいて、特定IPによるアクセス許可を実施することでアクセス 制限が可能 ・HTTPS対応や証明書の管理が 手動 |
- 基本的なセキュリティはStreamlit側で管理なので、サーバーや証明書の更新作業は不要。 ・アプリはインターネット上に公開されるためアクセス制限は基本的に難しい |
| 労力 | ・サーバーのセットアップや環境構築が必要。 |
非常に簡単にデプロイ可能 |
| コスト | ・EC2の利用料が発生 | ・無料。(無料プランであれば)ただし、サービスの制限(リソースの利用量制限など)がある |
参考)ソースコード
完全版はGithubに公開しています。
app.py
import re
import streamlit as st
from app_config import AppConfig
from dotenv import load_dotenv
from kendra_bedrock_query import (
invokeLLMWithFile,
invokeLLMWithoutFile,
kendraSearch,
ragSearch,
)
# 環境変数をロード
load_dotenv()
# メッセージリストの順序を保証する関数
def ensure_alternating_roles(messages):
"""
メッセージリストが `user` と `assistant` のロールが交互になるように調整する。
"""
# メッセージリストが空の場合、エラー回避のためユーザーメッセージが必須
if not messages:
raise ValueError(
"メッセージリストが空です。会話はユーザーメッセージから開始する必要があります。"
)
# 最後のメッセージが `assistant` でない場合に調整
if messages[-1]["role"] != "assistant":
messages.append({"role": "assistant", "content": [{"text": "準備中..."}]})
return messages
# session_stateののメッセージを初期化
def initialize_session():
if "tab_messages" not in st.session_state:
st.session_state.tab_messages = {
"rag_search": [],
"kendra_search": [],
"multi_modal": [],
}
# チャットメッセージを表示
def display_tab_messages(
tab_key, label="過去のやり取り", empty_message="履歴がありません"
):
"""
過去のメッセージや履歴を折りたたみで表示する汎用関数。
:param tab_key: session_stateのキー
:param label: 折りたたみタイトル
:param empty_message: メッセージが空の場合の表示内容
"""
# チャット履歴が存在するか確認し、なければ履歴がない旨のメッセージを表示
if not st.session_state.tab_messages[tab_key]:
st.info(empty_message)
return
# 過去の会話/検索履歴を expander 内にまとめて表示
with st.expander(label):
for message in st.session_state.tab_messages[tab_key]:
with st.chat_message(message["role"]):
st.markdown(message["content"][0]["text"])
# モデル名の表示を整形
def format_model_key_for_display(key):
formatted_model_name = key.replace("_", " ").title().replace("3 5 ", " 3.5 ")
return formatted_model_name
def display_search_results(signed_urls):
"""
検索結果を上位10件はそのまま表示し、残りは折りたたみで表示する。
:param signed_urls: 検索結果(辞書のリスト形式)
"""
if not signed_urls:
st.info("関連ドキュメントが見つかりませんでした。")
return
# 検索結果が10件以下の場合
if len(signed_urls) <= 10:
st.write("#### 関連するドキュメント")
for i, result in enumerate(signed_urls, 1):
st.markdown(f"{i}. [{result['document_name']}]({result['signed_url']})")
else:
# 上位10件を表示
st.write("#### 関連するドキュメント(上位10件)")
for i, result in enumerate(signed_urls[:10], 1):
st.markdown(f"{i}. [{result['document_name']}]({result['signed_url']})")
# 残りの結果を折りたたみ表示
if len(signed_urls) > 10:
with st.expander(
f"残りの関連ドキュメントを表示(※最大20件)({len(signed_urls) - 10}件)"
):
for i, result in enumerate(signed_urls[10:], 11):
st.markdown(f"{i}. [{result['document_name']}]({result['signed_url']})")
# ファイル名のバリデーション
def is_valid_filename(filename):
# アルファベット、数字、空白(1文字のみ)、ハイフン、括弧が含まれることを確認
return bool(re.match(r"^[a-zA-Z0-9\s\-\.\(\)\[\]]+$", filename))
# ファイルのサイズチェック(Claudeが受け付ける4.5MBを超えているかどうか)
def is_file_size_valid(uploaded_file):
return uploaded_file.size <= 4.5 * 1024 * 1024 # 4.5MB
# アプリの初期表示
st.title("Kendra-Bedrock-RAG検証")
initialize_session()
# 表示内容切り替えのためのプルダウン設定
tab_titles = AppConfig.WORDS_USED_IN_EACH_TAB_DICT
selected_tab = st.selectbox(
"プルダウンで機能を選択",
options=list(tab_titles.keys()),
format_func=lambda x: tab_titles[x],
)
# プルダウンで選択された値によって、動的に表示される内容を変更
# RAG検索タブ
if selected_tab == "rag_search":
st.header(tab_titles["rag_search"])
# 使用するClaudeのモデルを選択できるようにする
display_model_options = {
format_model_key_for_display(k): k for k in AppConfig.MODEL_ID_DICT.keys()
}
selected_model_name = st.selectbox(
"使用する生成AIモデルを選択してください",
options=display_model_options.keys(),
index=0, # デフォルトは"Claude3.5 Sonnet"を選択
)
# 選択されたmodelIdを抽出
selected_model_key = display_model_options[selected_model_name]
selected_model_id = AppConfig.MODEL_ID_DICT[selected_model_key]
# Select Temperature
selected_temperature_key = st.radio(
"生成AIの回答スタイルを選択してください",
options=AppConfig.TEMPERATURE_OPTIONS.keys(),
index=0, # デフォルトは"厳密に"
)
selected_temperature = AppConfig.TEMPERATURE_OPTIONS[selected_temperature_key]
# 検索対象のドキュメントを選択させる
category_dict = AppConfig.CATEGORY_LABELS
# ラジオボタンでカテゴリを選択
category_labels_to_display = AppConfig.CATEGORY_LABELS.values()
selected_category_value = st.radio(
"検索したい資料のカテゴリを選択してください:", category_labels_to_display
)
# 選択された日本語ラベルから英語のキーを取得(バックエンドで、categoryをAttributeFilterで絞り込む際に使用。)
selected_category_key = [
category_key
for category_key, category_value in category_dict.items()
if category_value == selected_category_value
][0]
# サイドバーにKendra検索タブの使い方を追加
st.sidebar.markdown("### RAG検索の使い方")
st.sidebar.markdown(AppConfig.HOW_TO_USE_RAG_SEARCH)
# 会話履歴の表示
display_tab_messages(
tab_key="rag_search",
label="過去の会話履歴",
empty_message="まだ会話履歴がありません",
)
# ユーザーの入力
user_input = st.chat_input("RAG検索クエリを入力してください")
if user_input:
# ユーザーの入力を session stateに格納
input_msg = {"role": "user", "content": [{"text": user_input}]}
st.session_state.tab_messages["rag_search"].append(input_msg)
history = st.session_state.tab_messages["rag_search"]
# ユーザーの入力を表示
with st.chat_message("user"):
st.markdown(user_input)
try:
# RAG検索を実行
with st.spinner("RAG検索実行中..."):
kendra_response, signed_urls = ragSearch(
user_input,
history,
selected_model_id,
selected_temperature,
selected_category_key,
)
# LLMからのレスポンスをsession stateに格納
response_msg = {"role": "assistant", "content": [{"text": kendra_response}]}
st.session_state.tab_messages["rag_search"].append(response_msg)
# LLM からのレスポンスを表示
with st.chat_message("assistant"):
st.markdown(kendra_response)
# 関連ドキュメントを表示
display_search_results(signed_urls)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
# Kendra検索タブ
elif selected_tab == "kendra_search":
st.header(tab_titles["kendra_search"])
# 検索対象のドキュメントを選択させる
category_dict = AppConfig.CATEGORY_LABELS
# ラジオボタンでカテゴリを選択
category_labels_to_display = AppConfig.CATEGORY_LABELS.values()
selected_category_value = st.radio(
"検索したい資料のカテゴリを選択してください:", category_labels_to_display
)
# 選択された日本語ラベルから英語のキーを取得(バックエンドで、categoryをAttributeFilterで絞り込む際に使用。)
selected_category_key = [
category_key
for category_key, category_value in category_dict.items()
if category_value == selected_category_value
][0]
# 会話履歴を表示
display_tab_messages(
tab_key="kendra_search",
label="過去の検索結果",
empty_message="まだ検索結果がありません",
)
# サイドバーにKendra検索タブの使い方を追加
st.sidebar.markdown("### Kendra検索の使い方")
st.sidebar.markdown(AppConfig.HOW_TO_USE_KENDRA_SEARCH)
# ユーザーの入力
user_input = st.chat_input("質問を入力してください")
if user_input:
input_msg = {"role": "user", "content": [{"text": user_input}]}
st.session_state.tab_messages["kendra_search"].append(input_msg)
with st.chat_message("user"):
st.markdown(user_input)
try:
# Kendra検索実行
with st.spinner("検索中..."):
signed_urls = kendraSearch(user_input, selected_category_key)
# 検索結果を表示
display_search_results(signed_urls)
# 検索結果をsession stateに格納
response_content = "以下の関連ドキュメントが見つかりました"
response_msg = {
"role": "assistant",
"content": [{"text": response_content}],
}
st.session_state.tab_messages["kendra_search"].append(response_msg)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
# マルチモーダルタブ
elif selected_tab == "multi_modal":
st.header(tab_titles["multi_modal"])
# 会話履歴の表示
display_tab_messages(
tab_key="multi_modal",
label="過去の会話履歴",
empty_message="まだ会話履歴がありません",
)
# サイドバーにガイドを表示
st.sidebar.markdown("### マルチモーダルの使い方")
st.sidebar.markdown(AppConfig.HOW_TO_USE_MULTI_MODAL)
# マルチモーダルでサポートされるファイル形式
supported_formats_dict = AppConfig.SUPPORTED_FORMATS
# ファイルアップローダーの表示
uploaded_file = st.file_uploader(
"ファイルをアップロードしてください", type=supported_formats_dict.values()
)
# ユーザーの質問の入力
question = st.chat_input("質問を入力してください")
# ファイルアップロードの有無をチェック
if uploaded_file:
st.markdown(f"アップロードされたファイル名: `{uploaded_file.name}`")
# 処理条件: ファイルと質問が揃った場合のみ実行
if uploaded_file and question:
# ファイルが有効かチェック(名前、サイズなど)
if not is_valid_filename(uploaded_file.name):
st.error(
"ファイル名にはアルファベット、数字、空白(1文字のみ)、ハイフン、括弧のみを使用してください。"
)
elif not is_file_size_valid(uploaded_file):
st.error("アップロードできるファイルサイズは最大4.5MBまでです。")
else:
file_type = uploaded_file.type
file_format = supported_formats_dict.get(file_type)
if not file_format:
st.error(
f"サポートされていないファイル形式です。以下の形式に対応しています: {', '.join(supported_formats_dict.values())}"
)
else:
# ファイル形式に応じた表示
if file_format in ["png", "jpeg"]:
st.image(
uploaded_file,
caption="アップロードされた画像",
use_column_width=True,
)
# 入力メッセージをセッションに追加
input_msg = {"role": "user", "content": [{"text": question}]}
st.session_state.tab_messages["multi_modal"].append(input_msg)
with st.chat_message("user"):
st.markdown(question)
try:
# Bedrockモデルの呼び出し
with st.spinner("回答生成中..."):
response_content = invokeLLMWithFile(
question,
uploaded_file,
st.session_state.tab_messages["multi_modal"],
)
response_msg = {
"role": "assistant",
"content": [{"text": response_content}],
}
# LLMからのレスポンスをセッションに保存
st.session_state.tab_messages["multi_modal"].append(response_msg)
# LLMからのレスポンスを表示
with st.chat_message("assistant"):
st.markdown(response_content)
except Exception as e:
st.error(f"ファイル処理中にエラーが発生しました: {e}")
elif uploaded_file and not question:
# ファイルがアップロードされているが質問が入力されていない場合
# 質問が入力されているがファイルがアップロードされていない場合
# 入力メッセージをセッションに追加
input_msg = {"role": "user", "content": [{"text": question}]}
st.session_state.tab_messages["multi_modal"].append(input_msg)
with st.chat_message("user"):
st.markdown(question)
try:
# Bedrockモデルの呼び出し
with st.spinner("回答生成中..."):
response_content = invokeLLMWithoutFile(
st.session_state.tab_messages["multi_modal"]
)
response_msg = {
"role": "assistant",
"content": [{"text": response_content}],
}
# LLMからのレスポンスをセッションに保存
st.session_state.tab_messages["multi_modal"].append(response_msg)
# LLMからのレスポンスを表示
with st.chat_message("assistant"):
st.markdown(response_content)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
elif question and not uploaded_file:
# 質問が入力されているがファイルがアップロードされていない場合
st.info("ファイルをアップロードしてください。")
else:
# 両方が未入力の場合
st.info("ファイルをアップロードし、質問を入力してください。")
kendra_bedrock_query.py
import os
import urllib
import boto3
from app_config import AppConfig
from botocore.client import Config
from dotenv import load_dotenv
"""
Kendra RAG検索/マルチモーダル
参照ソ-ス:https://github.com/ryanadoty/Amazon-Bedrock-RAG-Kendra-POC/blob/main/kendra_bedrock_query.py
https://github.com/aws-samples/genai-quickstart-pocs/tree/main/genai-quickstart-pocs-python/amazon-bedrock-claude3-multi-modal-poc
"""
# 環境変数の読み込み
load_dotenv()
# boto3セッションの定義
boto3_session = boto3.session.Session(profile_name=os.getenv("profile_name"))
# リトライ設定の作成(Amazon Bedrock ConverseAPI利用時のThrottlingエラー回避策)
retries_config = Config(AppConfig.RETRY_CONFIGS)
# Bedrock clientの初期化
bedrock = boto3_session.client(
"bedrock-runtime",
region_name=AppConfig.REGION_NAME_DICT["oregon"],
config=retries_config,
)
# デバッグ用
# print(bedrock)
# RAG検索を行う関数
def ragSearch(
question, history, selected_model_id, selected_temperature, selected_category_key
):
"""
Kendraの query APIを使用して、その回答をLLMに渡す関数
:param question: ユーザーの質問
:param history: ユーザーの会話履歴
:param selected_model_id ユーザーが画面で選択したClaudeのモデル
:param selected_temperature ユーザーが画面で選択した「振る舞い」(temperature)の値
:param selected_category_key 画面上で選択された検索対象のドキュメントのkey(KendraのAttributeFilterで絞り込みに使用される値)
:return: 過去の会話履歴+ユーザーの質問を踏まえて、LLMによって生成された回答
"""
# kendra clientの初期化
kendra = boto3_session.client(
"kendra", region_name=AppConfig.REGION_NAME_DICT["oregon"]
)
# ユーザーが選択したカテゴリの値に応じて、検索条件を動的に構築
# デフォルトは検索条件の絞り込みなし(_language_codeの絞り込みのみ)
attribute_filter = {
"AndAllFilters": [
{"EqualsTo": {"Key": "_language_code", "Value": {"StringValue": "ja"}}}
]
}
# 絞込み条件の追加
additional_attribute_filter = {
"OrAllFilters": [
{
"EqualsTo": {
"Key": "_category",
"Value": {"StringValue": selected_category_key},
}
}
]
}
# 「全て」以外が選択された時は検索条件の絞り込みを行う
if selected_category_key != "all":
attribute_filter["AndAllFilters"].append(additional_attribute_filter)
# queryAPIを使ってKendraを呼び出す
kendra_response = kendra.query(
IndexId=os.getenv("kendra_index"), # Put INDEX in .env file
QueryText=question,
PageNumber=1,
PageSize=30,
AttributeFilter=attribute_filter,
)
# デバッグ用:print(kendra_response)
# ドキュメントのメタデータを取得し、署名付きURLを生成
signed_urls = generateSignedUrls(kendra_response)
# デバッグ用
# print(signed_urls)
# 参照ドキュメントを生成 回答の参照ドキュメントが画面に出力されてしまうためマークダウンで表示できるよう整形
document_references = "\n".join(
[f"- [{doc['document_name']}]({doc['signed_url']})" for doc in signed_urls]
)
# Claudeモデルに渡すシステムプロンプトを定義
system_prompt = AppConfig.SYSTEM_PROMPT
# 会話の順番が`user`と`assistant`となるように制御
for i in range(len(history) - 1):
if history[i]["role"] == history[i + 1]["role"]:
raise ValueError(
"会話履歴のロールはuserとassistantで交互である必要があります。"
)
# デバッグ用
# print(f"messages:{messages}")
# 現在の質問と検索結果を会話履歴に追加
context_message = {
"role": "assistant",
"content": [{"text": f"Kendra検索結果:\n\n{document_references}"}],
}
history.append(context_message)
question_message = {"role": "user", "content": [{"text": question}]}
history.append(question_message)
# デバッグ用(会話履歴の確認
print("-----------------------")
print(f"history:{history}")
print("-----------------------")
# # デバッグ用
# # print(bedrock)
# ConverseAPIに会話履歴を渡した上で質問を行う
response = bedrock.converse(
modelId=selected_model_id,
messages=history,
system=system_prompt,
inferenceConfig={"temperature": selected_temperature},
)
# デバッグ用
# print(f"Converse API response: {response}")
# レスポンスの中身チェック
if (
"content" not in response["output"]["message"]
or not response["output"]["message"]["content"]
):
raise ValueError("Bedrock response content is empty.")
# 最終的に画面に表示する回答
answer = response["output"]["message"]["content"][0]["text"]
return answer, signed_urls
# Kendra検索時に使用する関数
def kendraSearch(kendra_query, selected_category_key):
"""
Kendra検索用の関数
queryAPIを使った検索のみを行い、検索結果と、メタデータから署名付きURLを生成し、返却する
:param question: ユーザーが画面で入力した質問
:param selected_category_key 画面上で選択された検索対象のドキュメントのkey(KendraのAttributeFilterで絞り込みに使用される値)
:return: 署名つきURL
"""
# Kendra clientの初期化
kendra = boto3_session.client(
"kendra", region_name=AppConfig.REGION_NAME_DICT["oregon"]
)
# ユーザーが選択したカテゴリの値に応じて、検索条件を動的に構築
# デフォルトは検索条件の絞り込みなし(_language_codeの絞り込みのみ)
attribute_filter = {
"AndAllFilters": [
{"EqualsTo": {"Key": "_language_code", "Value": {"StringValue": "ja"}}}
]
}
# 絞込み条件の追加
additional_attribute_filter = {
"OrAllFilters": [
{
"EqualsTo": {
"Key": "_category",
"Value": {"StringValue": selected_category_key},
}
}
]
}
# 「全て」以外が選択された時は検索条件の絞り込みを行う
if selected_category_key != "all":
attribute_filter["AndAllFilters"].append(additional_attribute_filter)
# Kendraの queryAPIの呼び出し
kendra_response = kendra.query(
IndexId=os.getenv("kendra_index"), # Put INDEX in .env file
QueryText=kendra_query,
PageNumber=1,
PageSize=30,
AttributeFilter=attribute_filter,
)
# デバッグ用
# print(kendra_response)
# 署名付きURLを取得
signed_urls = generateSignedUrls(kendra_response)
# デバッグ用
# print(f"署名つきURL:{signed_urls}")
return signed_urls
# 署名付きURLを返却する関数(Kendra検索, RAG検索共通
def generateSignedUrls(kendra_response):
"""
Kendraの検索結果から署名付きURLを生成する
:param kendra_response: Kendraの検索結果
:return: Kendra検索結果のドキュメントの署名付きURLのリスト
"""
# プロファイルを元にセッションを確立
boto3_session = boto3.session.Session(profile_name=os.getenv("profile_name"))
s3_client = boto3_session.client(
"s3",
region_name=AppConfig.REGION_NAME_DICT["oregon"],
config=Config(signature_version="s3v4"),
verify=False,
)
signed_urls = []
for result in kendra_response.get("ResultItems", []):
# ドキュメントのパスの存在確認
if (
"DocumentURI" in result
and "s3.us-west-2.amazonaws.com" in result["DocumentURI"]
):
# 検索結果のS3ドキュメントのURIを取得
s3_url = result["DocumentURI"]
try:
# Debug: print the DocumentURI to verify its structure
# print(f"DocumentURI: {s3_url}")
# Parse S3 bucket and key from the DocumentURI
# プロトコル部分を取り除く
s3_path = s3_url.replace("https://", "")
# パスをバケット名とオブジェクトキーに分割
parts = s3_path.split("/", 1)
if len(parts) == 2:
bucket_name = os.getenv("bucket_name")
# オブジェクトキーを取得(取得時はすでにエンコードされている)
object_key_encoded = parts[1]
# 取得したオブジェクトキーをデコード(オブジェクトキーが日本語だと二重でエンコードされてしまい、エラーとなってしまうため)
# 参照: https://github.com/aws-samples/generative-ai-use-cases-jp/issues/189
object_key = urllib.parse.unquote(object_key_encoded)
# print(f"Decoded Object Key: {object_key}")
if object_key.startswith("transcription/") and object_key.endswith(
".txt"
):
txt_file_name = object_key.split("/")[-1] # XXXX.txt
pdf_object_key = f"hogehoge/{
txt_file_name.replace('.txt', '.pdf')}"
# .txtファイルの名前と同名の.pdfファイルが存在するかを確認し、存在する場合はそちらを署名付きURLに変換して返却
try:
s3_client.head_object(
Bucket=bucket_name, Key=pdf_object_key
)
print(f"PDF file exists: {pdf_object_key}")
# 署名付きURLを生成
signed_url = s3_client.generate_presigned_url(
"get_object",
Params={"Bucket": bucket_name, "Key": pdf_object_key},
ExpiresIn=3600,
)
signed_urls.append(
{
"document_name": txt_file_name.replace(
".txt", ".pdf"
),
"signed_url": signed_url,
}
)
except s3_client.exceptions.ClientError as e:
if e.response["Error"]["Code"] == "404":
print(f"PDF file not found: {pdf_object_key}")
else:
raise
else:
# 同名のファイルが存在しない場合は検索結果のファイルをそのまま署名付きURLに変換
signed_url = s3_client.generate_presigned_url(
"get_object",
Params={"Bucket": bucket_name, "Key": object_key},
ExpiresIn=3600, # URL valid for 1 hour
)
signed_urls.append(
{
"document_name": result.get(
"DocumentTitle", "Unknown Document"
).get("Text"),
"signed_url": signed_url,
}
)
print(f"signed_urls: {signed_urls}")
else:
print(f"Unexpected S3 path format: {s3_url}")
except Exception as e:
print(f"Error generating signed URL: {e}")
return signed_urls
def invokeLLMWithFile(question, uploaded_file, messages):
"""
マルチモーダルでのBedrock呼び出しを行う
ファイルがアップロードされなかった場合、通常のチャットとして動作する
:param question: ユーザーの質問
:param uploaded_file: アップロードされたファイル
:param messages: 過去の会話履歴
:return answer: LLMからの回答
"""
# モデルIDと推論パラメータのセット
model_id = AppConfig.MODEL_ID_DICT["claude_3_haiku"]
inference_config = AppConfig.INFERENCE_CONFIG_DICT
# マルチモーダルでサポートされるファイル形式
supported_formats_dict = AppConfig.SUPPORTED_FORMATS
if uploaded_file:
# ファイル形式を判別
file_format = supported_formats_dict.get(uploaded_file.type)
if not file_format:
raise ValueError(
f"サポートされていないファイル形式です。以下の形式に対応しています: {
', '.join(supported_formats_dict.values())}"
)
# ファイルの内容を読み込む
file_content = uploaded_file.getvalue()
# 画像のバリデーションと処理
if file_format in ["png", "jpeg"]:
file_message = {
"image": {"format": file_format, "source": {"bytes": file_content}}
}
default_question = (
f"アップロードされた画像({file_format})の内容を要約してください。"
)
elif file_format == "pdf":
# PDFの処理
# TODO nameの部分に関して、ファイル名の名前を使用するとなぜかconverseAPIのエラーになってしまうため決めうちで指定
file_message = {
"document": {
"format": "pdf",
"name": "pdf",
"source": {"bytes": file_content},
}
}
default_question = f"アップロードされたPDF({uploaded_file.name})の内容を要約してください。"
else:
raise ValueError("サポートされていないファイル形式です。")
# `question` が空の場合、デフォルトの質問を使用
question = question if question.strip() else default_question
# メッセージの構築
user_message = {
"role": "user",
"content": [
{"text": f"Uploaded {file_format} content:"},
file_message,
{"text": question},
],
}
else:
# ファイルがない場合の処理
user_message = {
"role": "user",
"content": [
{"text": question if question.strip() else "質問が入力されていません。"}
],
}
# メッセージを追加
if messages and messages[-1]["role"] != "assistant":
messages.append({"role": "assistant", "content": [{"text": "準備中..."}]})
messages.append(user_message)
# Bedrock API呼び出し
try:
response = bedrock.converse(
modelId=model_id, messages=messages, inferenceConfig=inference_config
)
answer = response["output"]["message"]["content"][0]["text"]
except Exception as e:
answer = f"エラーが発生しました: {e}"
return answer
def invokeLLMWithoutFile(history):
"""
通常のLLMとのチャットを行う関数(会話履歴を考慮した回答をさせる)
:param history: ユーザーの会話履歴
:return answer: 過去の会話履歴を踏まえて、LLMによって生成された回答
"""
# モデルIDと推論パラメータのセット
model_id = AppConfig.MODEL_ID_DICT["claude_3_5_sonnet"]
inference_config = AppConfig.INFERENCE_CONFIG_DICT
# ConverseAPIに会話履歴を渡した上で質問を行う
response = bedrock.converse(
modelId=model_id, messages=history, inferenceConfig=inference_config
)
# デバッグ用
# print(f"Converse API response: {response}")
# レスポンスの中身チェック
if (
"content" not in response["output"]["message"]
or not response["output"]["message"]["content"]
):
raise ValueError("Bedrock response content is empty.")
# 最終的に画面に表示する回答
answer = response["output"]["message"]["content"][0]["text"]
print(answer)
return answer
app_config.py
"""
各種設定値を定義する
"""
class AppConfig:
# リージョン名
REGION_NAME_DICT = {
"oregon": "us-west-2",
"verginia": "us-east-1",
"tokyo": "ap-northeast-1",
}
# Amazon BedrockのモデルID(Claude3.5 Sonnet, Claude3 Sonnet, Claude3 Haiku)
MODEL_ID_DICT = {
"claude_3_5_sonnet": "anthropic.claude-3-5-sonnet-20240620-v1:0",
"claude_3_sonnet": "anthropic.claude-3-sonnet-20240229-v1:0",
"claude_3_haiku": "anthropic.claude-3-haiku-20240307-v1:0",
}
# Claudeモデルの、推論時の各種パラメータ(追加したいパラメータを下記に追記していく)
INFERENCE_CONFIG_DICT = {
"maxTokens": 4096,
"temperature": 0.5,
# topP = 0.999(デフォルト),
# stopSequences = ['</output>']
}
# アプリ名称
APP_NAME = "Kendra-Bedrock-RAG検証"
# 各タブで利用される文言
WORDS_USED_IN_EACH_TAB_DICT = {
"rag_search": "RAG検索",
"kendra_search": "Kendra検索",
"multi_modal": "マルチモーダル",
}
# リトライ設定
# botocoreのリトライ設定の作成(Throttlingエラー回避策)
RETRY_CONFIGS = {
"max_attempts": 10, # 最大10回のリトライ
"mode": "adaptive", # リトライモード
}
# システムプロンプト
SYSTEM_PROMPT = [
{
"text": f"""
【指示】:
- 以下の「質問」と「検索結果」、過去の会話履歴に基づいて、ユーザーの質問に正確に回答してください。
- 検索結果に回答が含まれていない場合は、「該当する情報は見つかりませんでした」と明示してください。
- ユーザーから表形式での出力が要求された場合、Markdown形式で表を作成してください。
- 表の列名を明確に指定し、回答に関連する情報を整然と整理してください。
"""
}
]
# 生成AIの振る舞いの値
TEMPERATURE_OPTIONS = {"厳密に": 0.2, "バランスよく": 0.5, "創造的に": 0.8}
# カテゴリの絞り込みに使うためのカテゴリの辞書(検索条件の絞り込みの際使用する)
# NOTE 使用するドキュメントに合わせて設定してください
CATEGORY_LABELS = {
"all": "全て",
"ministry-of-health-labour-and-welfare": "厚生労働省",
"ministry-of-land-infrastructure-transport-and-tourism": "国土交通省",
}
# マルチモーダル問い合わせの場合の、サポートされるファイル形式を定義
# サポートされるファイル形式
SUPPORTED_FORMATS = {
"application/pdf": "pdf",
"text/csv": "csv",
"application/msword": "doc",
"application/vnd.openxmlformats-officedocument.wordprocessingml.document": "docx",
"application/vnd.ms-excel": "xls",
"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet": "xlsx",
"text/html": "html",
"text/plain": "txt",
"text/markdown": "md",
"image/png": "png",
"image/jpeg": "jpeg",
}
# 各種機能の使い方を定義
# NOTE 半角スペースを2つ入れると、改行が入ります
# RAG検索
HOW_TO_USE_RAG_SEARCH = """
ここでは、Amazon Bedrockを使用して、文書の検索結果を、生成AIによる回答の形式で得ることができます。
1. :red[**検索したい資料のカテゴリを選択**]
検索対象のドキュメントの種類をラジオボタンで選択してください。デフォルトでは、「全て」が選択されています。
2. :red[**生成AIが生成する回答の振る舞いを選択**]
生成AIが生成する回答の振る舞いを選択してください。デフォルトでは、"厳密に"(より事実に即した回答をさせる)が選択されています。
3. :red[**質問文の入力**]
画面下部の入力欄に質問文を入力してください。
※期待する結果が返ってこない場合は、以下の方法をお試しください。
1. :blue[**質問文や検索対象のカテゴリの設定を見直す**]
より具体的な質問や適切なカテゴリ設定を行うと、検索結果が改善される可能性があります。
2. :blue[**質問を深掘りする**]
より詳細な情報を求める質問を入力することで、期待する回答を得られる可能性があります。
"""
# Kendra検索
HOW_TO_USE_KENDRA_SEARCH = """
ここでは、Amazon Kendraを使用して、文書の検索を行うことができます。
1. :red[**検索したい資料のカテゴリを選択**]
検索対象のドキュメントの種類をラジオボタンで選択してください。デフォルトでは、「全て」が選択されています。
2. :red[**検索キーワードの入力**]
画面下部の入力欄に検索キーワードを入力してください。
※検索結果がない場合は、検索キーワードや検索対象のカテゴリの設定を見直して再度検索をお試しください。
"""
# マルチモーダル
HOW_TO_USE_MULTI_MODAL = """
ここでは、Amazon Bedrockを用いて、テキストと、画像やPDFファイルなどのアップロードされたファイルを組み合わせて生成AIに質問を行うことができます。
1. :red[**ファイルアップロード**]
画像や(PNG、JPEG)、PDFファイルなどをアップロードします。
2. :red[**質問の入力**]
画面下部の入力欄に質問を入力します。
例)「この画像から読み取ることのできる情報を全てテキストで書き起こしてください」
3. :red[**通常のチャット**]
ファイルをアップロードせずにテキストのみで生成AIに質問を行うことも可能です。
"""
.env
# Kendra indexのID、プロファイル名、S3バケット名などの情報を格納
#検証で使用するS3バケット名(データソースとして使用するS3バケット)
bucket_name = "(S3バケット名)"
#IAMユーザープロファイル名(ローカル検証用)
profile_name = "(IAMプロファイル名)"
#KendraのIndexID
kendra_index = "(KendraのindexID)"
"""