N高グループでICT講師をしている Kuwabara です。
本記事は、N高グループ・N中等部・NCodeLabo Advent Calendar 2025 の5日目の記事です。
この記事では、ベイズ推論の考え方を紹介します。
確率の基本から始め、ベイズの定理、確率分布といった概念を確認しながら、最終的にはベイズ線形回帰まで段階的に解説します。
ベイズ推論の全体像や雰囲気をつかむきっかけになれば幸いです。
1. 条件付き確率とベイズの定理
1.1 確率の基本
まず、確率の基本を確認しましょう。
全事象を$U$とします。
根元事象が同様に確からしい場合、事象$A$の起こる確率は
P(A)=\frac{n(A)}{n(U)}
で求めることができます。
| ベン図で図示 |
|---|
 |
例題1 (確率の基本問題)
さいころを1回振ります。出た目が偶数である確率を求めなさい。
例題1 解答
出た目が偶数の事象を$A$とします。
P(A)=\frac{n(A)}{n(U)}=\frac{3}{6}=\frac{1}{2}
1.2 条件付き確率
次に、ベイズの基礎となる条件付き確率を見ていきます。
事象$A$が起こったという前提のもとで、事象$B$が起こる条件付き確率は
P(B|A)=\frac{n(A \cap B)}{n(A)}=\frac{P(A \cap B)}{P(A)}
で求めることができます。
| ベン図で図示 |
|---|
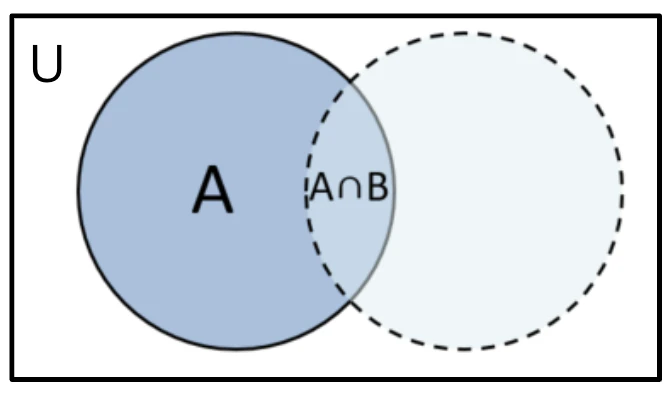 |
事象$A$が起こったという前提条件があることから、確率の全体が$U$から$A$に変わっていることがポイントです。
例題2 (条件付き確率の基本問題)
さいころを1回振ります。出た目が4以上のとき、その目が偶数である確率を求めなさい。
例題2 解答
出た目が4以上の事象を$A$、出た目が偶数の事象を$B$とします。
P(B|A)=\frac{n(A \cap B)}{n(A)}=\frac{2}{3}
| ベン図で図示 |
|---|
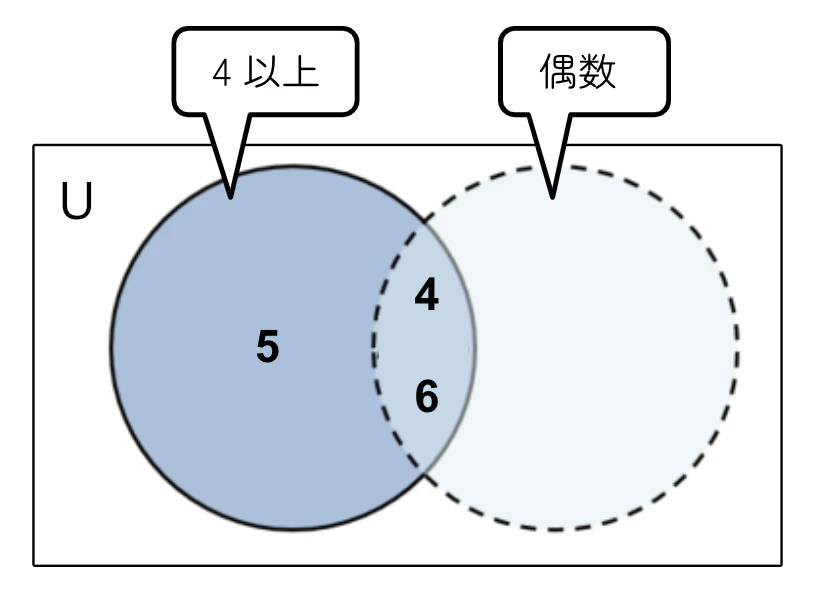 |
例題1と例題2を見比べると、どちらも求めたのは「目が偶数である確率」ですが、出た目が4以上という前提条件があるかないかで、答えの確率が変わっています。
もう少し、条件付き確率の問題を考えてみましょう。
例題3 (火曜日に生まれた女の子)
スミスさんには子どもが2人います。2人のうち、少なくとも1人は火曜日に生まれた女の子です。では、2人とも女の子である確率を求めなさい。ただし、男の子と女の子は等確率で生まれるものと仮定します。
例題3 解答
一見、$\dfrac{1}{2}$と思いがちですが、実はそうではありません。
次の表を見てみましょう。
| 火曜日に生まれた女の子 |
|---|
 |
「少なくとも1人が火曜日に生まれた女の子」という前提条件があります。
そこで、この条件を満たすマスをすべてオレンジ色で塗ると、27マスになります。この27マスが確率の全体です。
次に、この27マスの中で2人とも女の子になるマスを赤枠で囲むと、これは13マスあります。
そのため、答えは$\dfrac{13}{27}$となります。
「少なくとも1人が火曜日に生まれた女の子」という前提条件によって、もう一人の性別の確率がこのようになるのは不思議ですね。
1.3 ベイズの定理
条件付き確率の定義から
P(B|A)=\dfrac{P(A \cap B)}{P(A)}
であり、両辺に $P(A)$ をかけると、
P(A \cap B)=P(A)\cdot P(B|A)
が得られます。
同様に、
P(A|B)=\dfrac{P(A \cap B)}{P(B)}
であり、両辺に $P(B)$ をかけると、
P(A \cap B)=P(B)\cdot P(A|B)
が得られます。
2つの式はどちらも同じ $P(A \cap B)$ を表しているので、
P(A)\cdot P(B|A)=P(B)\cdot P(A|B)
が成り立ちます。これを $P(A|B)$ について解けば、
P(A|B)=\dfrac{P(A)\cdot P(B|A)}{P(B)}
が得られます。この式をベイズの定理と呼びます。
ベイズの定理の意味
$B$を観測結果、$A$をその原因としたとき、それぞれの確率は以下のように解釈できます。
- $P(A)$:原因$A$の発生確率
- $P(B)$:観測結果$B$の発生確率
- $P(B|A)$:$A$が発生した際に観測結果Bが発生する確率(時間順行)
- $P(A|B)$:$B$が発生した際に原因Aが起こっていた確率(時間逆行)
通常の確率は 「原因 → 結果」 の向きで扱いますが、
ベイズの定理は「結果 → 原因」を扱える点が非常に重要です。
「結果の情報が得られたとき、その情報をもとに原因の確率を更新する」
これがベイズ推論の本質です。
例題4 (病気に罹患している確率)
ある病気の罹患率は1%です。この病気に罹患しているか検査する方法があり、罹患している人は99%の確率で陽性と診断され、健康な人は97%の確率で陰性と診断されます。この検査で陽性と診断されたとき、実際に罹患している確率を求めなさい。
例題4 解答
病気に罹患している事象を$A$、陽性と診断される事象を$B$とします。
\begin{align}
P(A|B) &= \dfrac{P(A)\cdot P(B|A)}{P(B)} \\
&= \dfrac{\frac{1}{100}\cdot \frac{99}{100}}{\underbrace{\frac{1}{100}\cdot \frac{99}{100}}_{\text{罹患かつ陽性}}+\underbrace{\frac{99}{100}\cdot \frac{3}{100}}_{\text{健康かつ陽性}}} \\
&= \dfrac{1}{4}
\end{align}
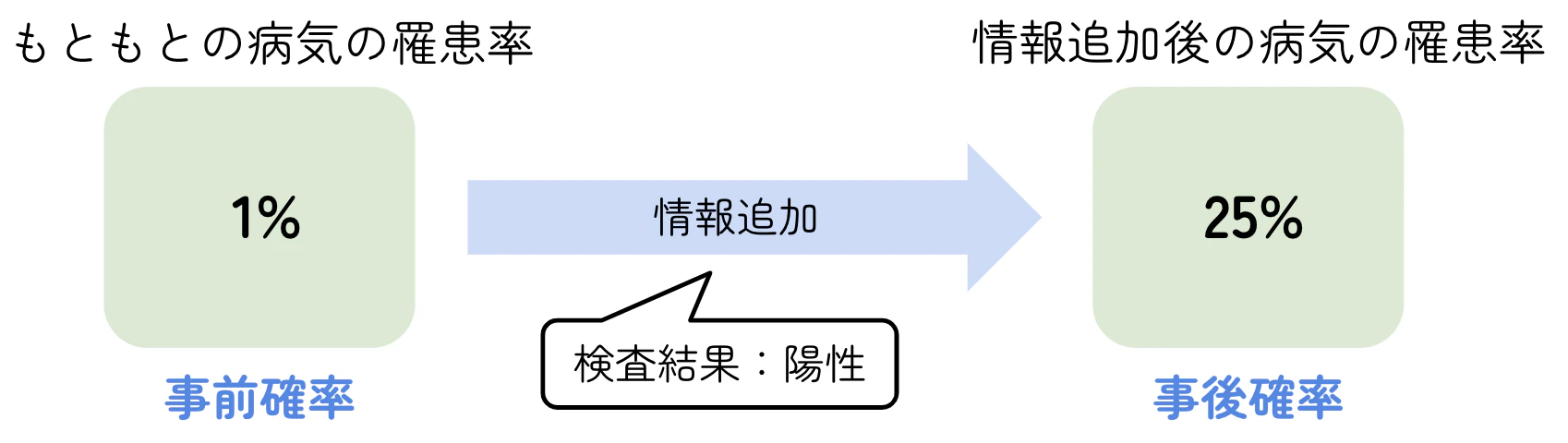
つまり、陽性判定でも実際に罹患している確率は25%であり、直感に反して低い値となります。
(※これは例題であり、実際の病気のリスク計算は年齢層・症状・追加検査など多くの要因を含みます)
ここでは、「罹患している(原因) → 陽性が出る(結果)」という時間順行の確率ではなく、
「陽性が出た(結果) → 罹患している?(原因)」という時間逆行の確率を求めている点が重要です。
また、何の情報もなければ罹患率は1%でしたが、陽性という情報が加わることで確率は25%まで更新されました。このように、観測情報に応じて確率を更新することをベイズ更新と呼びます。
| ベイズ更新 |
|---|
 |
2. 確率分布
2.1 確率分布とは何か
どの値を取るかが確率的に決まる変数のことを確率変数と呼びます。
また、その確率変数がどの値をどれだけの確率でとるのかを記述するものを確率分布と呼びます。
離散型確率分布の例
コインを2回投げたときの表が出た回数を$X$とします。
$X$がどの値を取るかは確率的に決まるので、$X$は確率変数です。
$X$の確率分布は次のようになります。
P(X) = \left\{
\begin{array}{ll}
\frac{1}{4} & (X=0) \\
\frac{1}{2} & (X=1) \\
\frac{1}{4} & (X=2) \\
\end{array}
\right.
| 離散確率分布 |
|---|
 |
このように、とびとびの値に確率が割り当てられるタイプの確率変数を離散型と呼びます。
連続型確率分布の例
0から1までのランダムな実数$X$は確率変数です。
この確率変数$X$は以下の性質を持ちます。
- $P(X=0.5)=0$ (一点の確率は0)
- $P(0\leqq X\leqq 1)=1$ (全体の確率は1)
- $P(0.4\leqq X\leqq 0.6)=0.2$ (区間の確率は面積)
| 連続確率分布 |
|---|
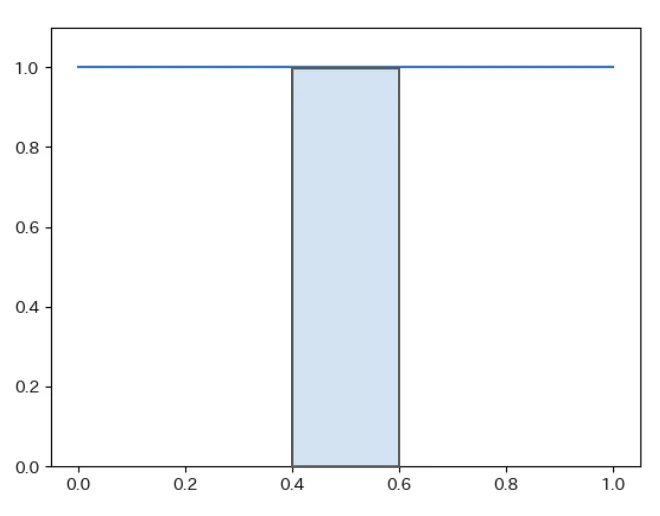 |
区間の確率は確率密度関数 $f(x)$ の積分によって求めます。
P(a\leqq X\leqq b)=\int_{a}^{b}f(x)dx
上の例では、確率密度関数は以下のようになります。
f(x)=1 (0\leqq x\leqq 1)
このように、連続的な範囲の面積として確率が決まる確率変数を連続型と呼びます。
2.2 確率分布の例
ここから先の話で登場する確率分布のみ簡単に紹介します。
連続一様分布
指定した区間の中ですべての値が同じ確率密度で現れる分布です。
f(x)=\dfrac{1}{b-a} (a\leqq x\leqq b)
- 用途:パラメータに「特に情報がない」ことを表す事前分布
(事前分布については後ほど紹介します)
| 区間が $0\leqq x\leqq 1$ の連続一様分布 |
|---|
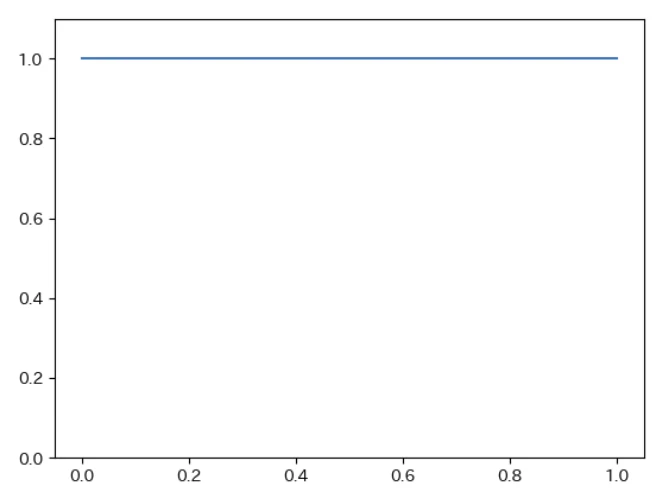 |
正規分布
統計で最も重要な分布です。多くの現象が正規分布に近づく(中心極限定理)ため、自然界で頻出します。
f(x)=\dfrac{1}{\sqrt{2\pi}\sigma}exp\left(-\dfrac{(x-\mu)^2}{2\sigma^2}\right)
- $\mu$:平均値
- $\sigma$:標準偏差
- 用途:パラメータ(例:回帰係数)の事前分布
| 平均値50、標準偏差10の正規分布(偏差値) |
|---|
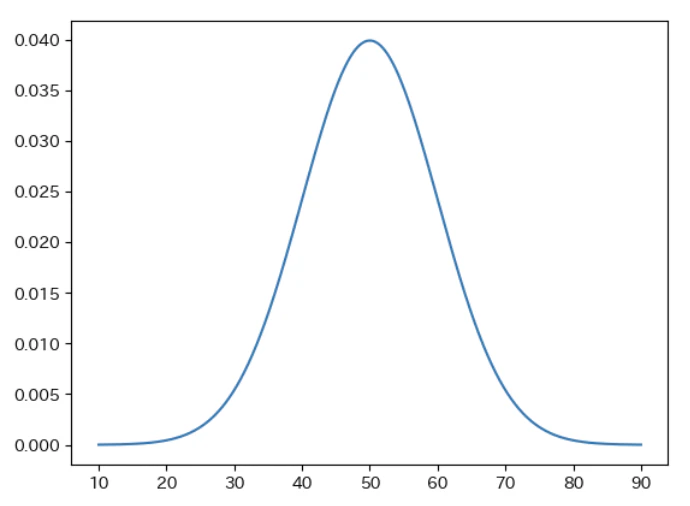 |
半正規分布
正規分布をy軸で折り返したような分布です。負の値をとらない量を表すのに使います。
f(x)=\sqrt{\dfrac{2}{\pi\sigma^2}}exp\left(-\dfrac{x^2}{2\sigma^2}\right) (x>0)
- $\sigma$:標準偏差
- 用途:標準偏差や分散といった「必ず正の値」の事前分布
| 標準偏差1の半正規分布 |
|---|
 |
ベータ分布
$\alpha$と$\beta$の2つのパラメータによって特徴づけられる分布です。0〜1の値を扱うのに使います。
f(x)=Cx^{\alpha -1}(1-x)^{\beta -1}
ただし、$C$は面積の合計を1にするための調整係数です。
C=\dfrac{(\alpha + \beta -1)!}{(\alpha -1)!(\beta -1)!}
- 用途:ベルヌーイ分布の共役事前分布
| ベータ分布 |
|---|
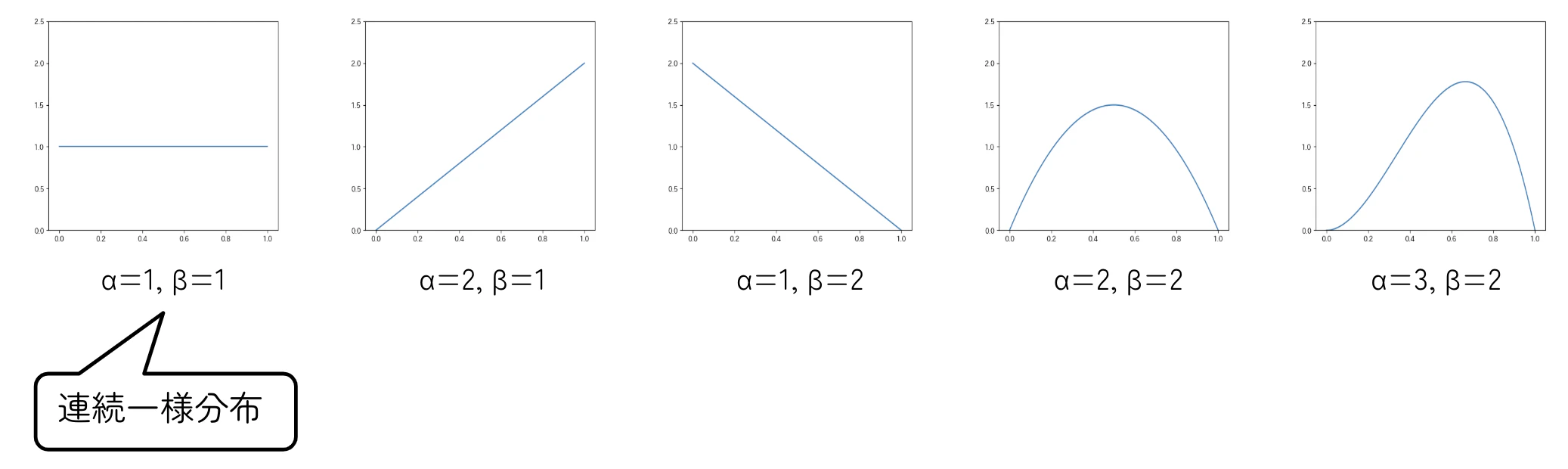 |
3. ベイズ推論
3.1 ベイズ推論とは何か
観測情報に応じて確率を更新することをベイズ更新と呼びました。
ベイズ推論とは、新しい情報が得られるたびに、パラメータ$p$の確率分布を更新していく方法です。
ベイズ推論の流れは以下となります。
- パラメータ$p$の事前分布を設定する
- 観測データが得られる
- 事前分布と観測データから、$p$の確率分布を更新し、事後分布を得る
この「事前 → 更新 → 事後」を繰り返すことで、情報が増えるたびに推定が洗練されていきます。
| ベイズ推論 |
|---|
 |
3.2 ベイズ推論の例題
例題5 (くじ引きで当たりを引く確率)
当たりの確率が一定のくじを 5 回引いたとき、結果は「当たり・外れ・外れ・当たり・外れ」でした。このくじが当たる確率$p$はどのくらいでしょうか?
例題5 解答
この問題を最尤推定という方法と、ベイズ推論という方法の2通りで考えましょう。
最尤推定
結果が「当たり・外れ・外れ・当たり・外れ」となる確率は
p\cdot (1-p)\cdot (1-p)\cdot p \cdot (1-p)=p^2(1-p)^3
です。これを尤度関数と言います。
| 尤度関数のグラフ |
|---|
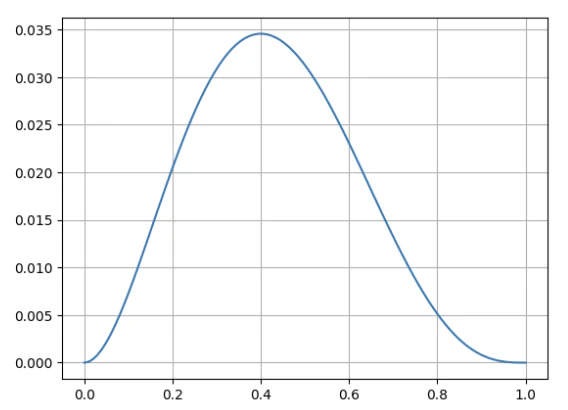 |
尤度が最大となるのは$p=0.4$のときです。そのため、最尤推定では$p$は0.4程度と推定できます。
ベイズ推論
$p$の事前分布として、連続一様分布を考えます。1回目が当たりという情報で確率分布が更新されます。
| 確率分布の更新(1回目) |
|---|
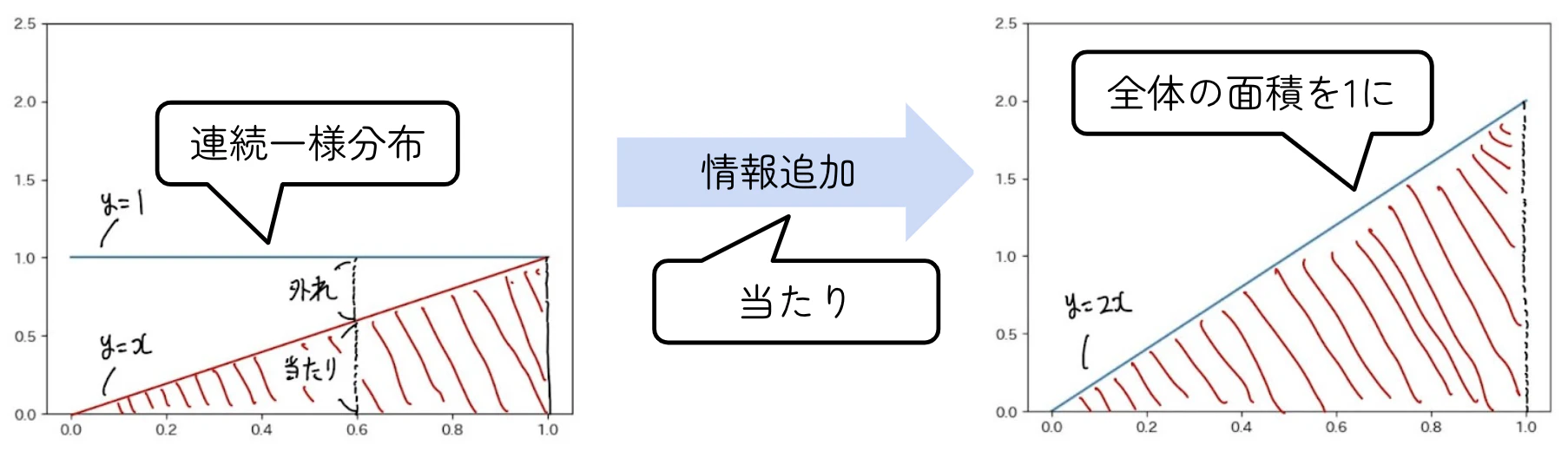 |
次に2回目が外れという情報で、また確率分布が更新されます。
| 確率分布の更新(2回目) |
|---|
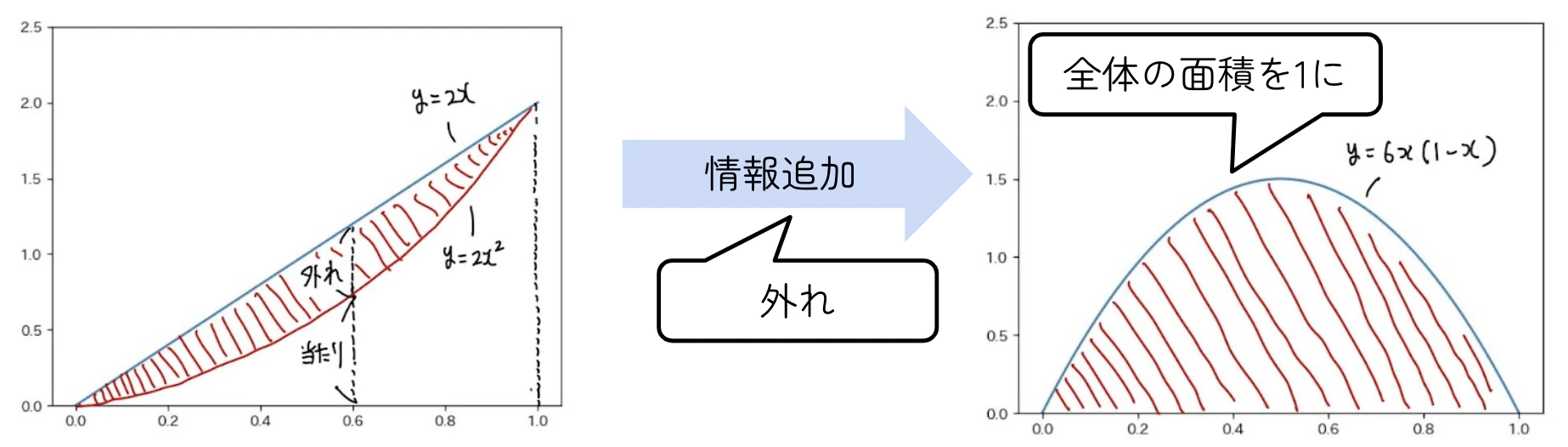 |
同じ流れで、確率分布は以下のように更新されます。
| 確率分布の更新の推移 |
|---|
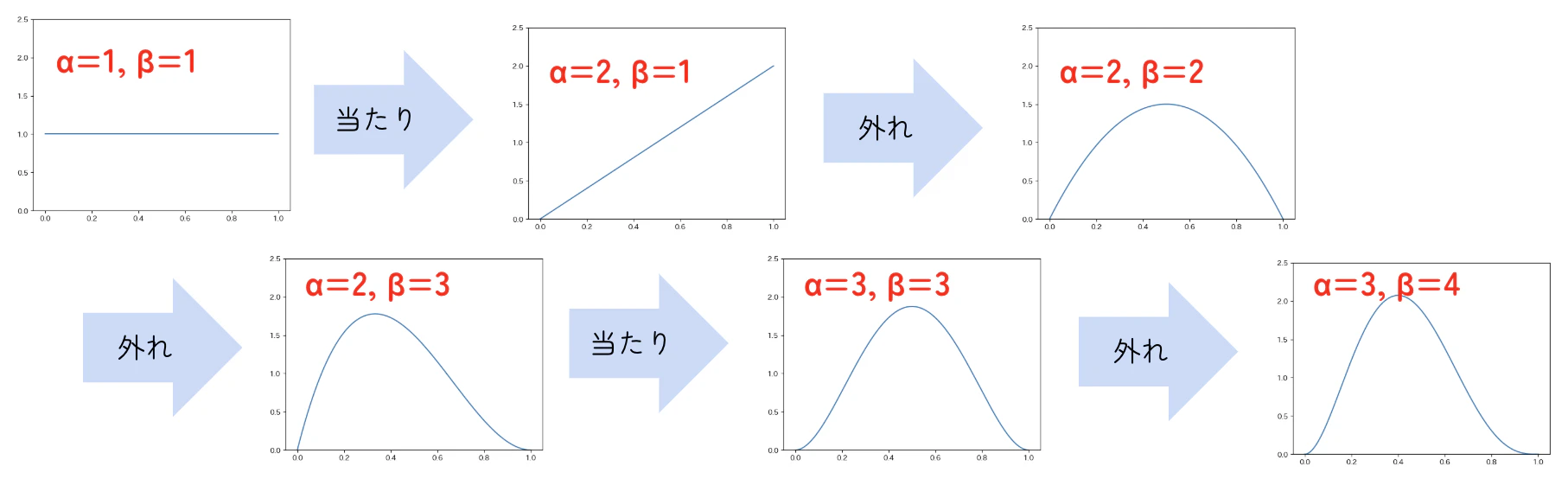 |
これらはすべてベータ分布です。
最終的な$p$の事後分布から、ベイズ推論でもやはり$p$は0.4程度と推定できます。
今回は「何も知らない」ことを表す連続一様分布を事前分布として使いましたが、別の事前分布を使うこともできます。
例えば、$\alpha=6,\beta=6$のベータ分布を事前分布とすると、以下のようになります。
| 確率分布の更新の推移 |
|---|
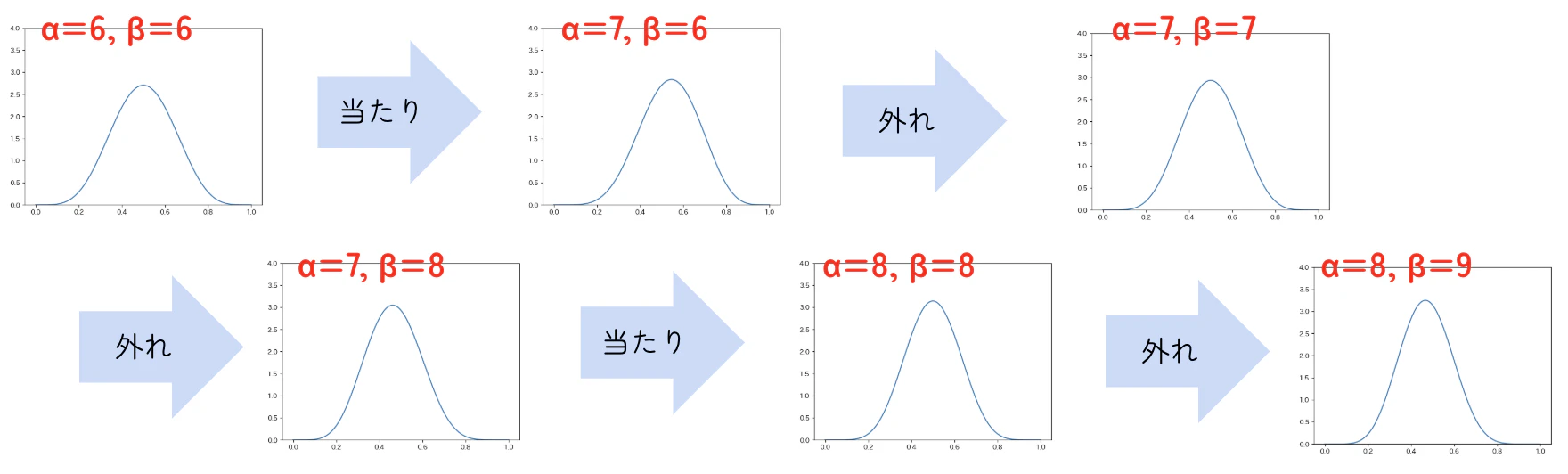 |
$\alpha=6,\beta=6$のベータ分布を事前分布とすることは、「当たり5回・外れ5回分の経験が事前にある」ことと同じ意味になります。
ベイズ推論では、観測データが少ないうちは事前分布の影響が強く出ますが、観測データが増えるほど事前分布の影響は小さくなっていきます。これは私たちの直感にも合う性質ですね。
4. ベイズ線形回帰
4.1 一般的な線形回帰
機械学習とは、コンピュータがデータをもとにルールを学習し、予測や分類を行う手法の総称です。
その中でも教師あり学習では、「正解つきのデータ」を使って学習を行い、未知のデータの正解を予測します。また、予測の中でも、数値を予測する問題を回帰と呼びます。
回帰の例として、「カリフォルニアの住宅価格」を考えましょう。
世帯所得、築年数、部屋数、居住人数といった説明変数から、目的変数である住宅価格を予測します。
| カリフォルニアの住宅価格 |
|---|
 |
簡単のため、ここでは「部屋数だけから住宅価格を予測する」場合を考えます。
| 部屋数と住宅価格の関係 |
|---|
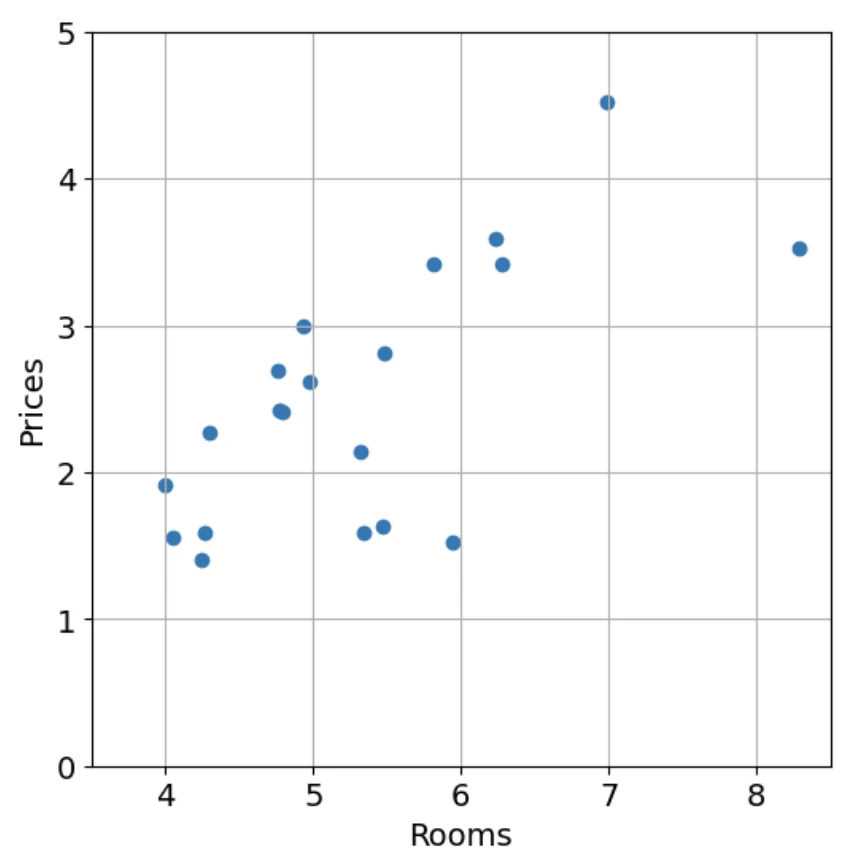 |
線形回帰では、部屋数$x$と住宅価格$y$の関係を、次の1次式で近似します。
y=\alpha x+\beta
$\alpha$ と $\beta$ を求めるために最も広く使われるのが 最小二乗法です。
流れは以下のとおりです。
- データ点の$y$座標と直線による予測値のズレ(残差)を調べる
- 各データの残差の2乗和を求める($\alpha$と$\beta$の2次関数になる)
- その関数を偏微分して、関数が最小となる$\alpha$と$\beta$を求める
| 線形回帰 |
|---|
 |
最小二乗法では$\alpha$と$\beta$が1つの値に確定するため、「その予測がどのくらい不確実なのか?」は分かりません。
一方、次に紹介する ベイズ線形回帰 は、予測の不確実性まで扱える点が大きな特徴です。
4.2 ベイズ線形回帰
ベイズ推論とは、新しい情報が得られるたびに、パラメータ$p$の確率分布を更新していく方法でした。
ベイズ線形回帰では、次のモデルを考えます:
y_n=\alpha x_n+\beta+\epsilon_n
推定したいパラメータは以下の3つです。
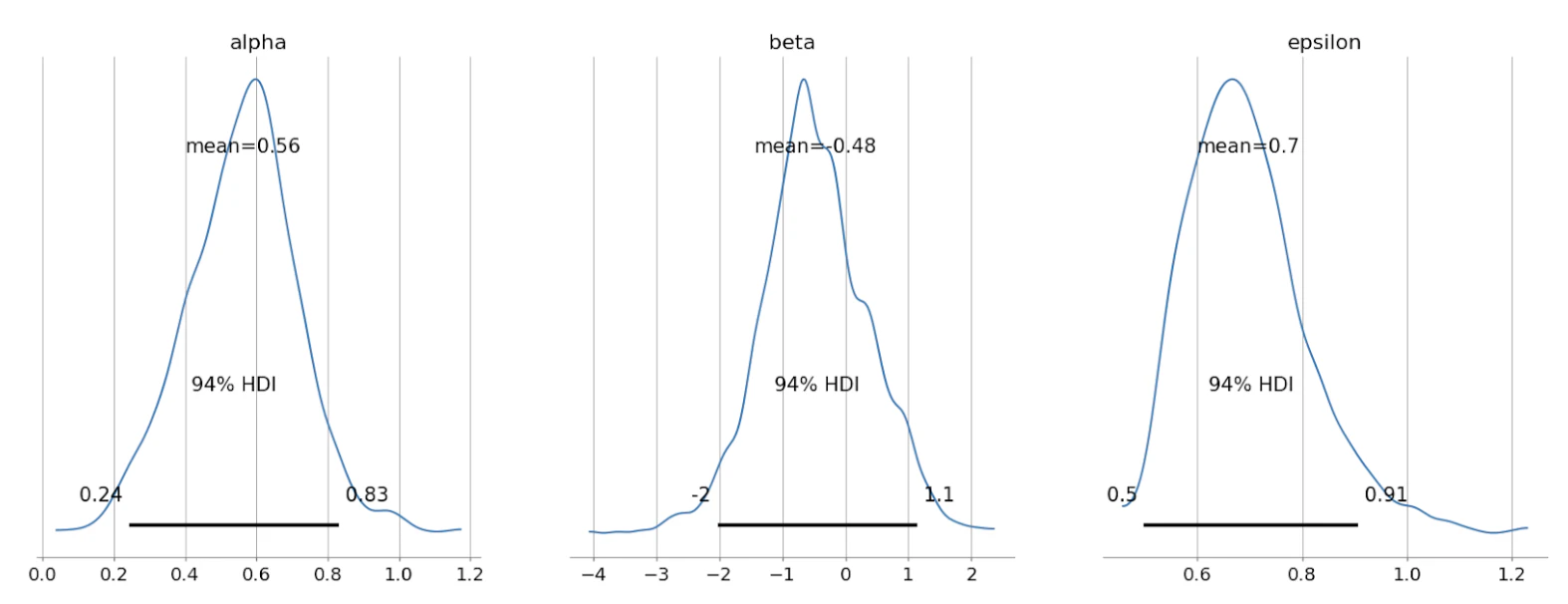
- 傾き $\alpha$
事前分布:平均値0、標準偏差10の正規分布 - 切片 $\beta$
事前分布:平均値0、標準偏差10の正規分布 - 誤差$\epsilon_n$の標準偏差 $\epsilon$
事前分布:標準偏差1の半正規分布
データを観測すると、$(\alpha,\beta,\epsilon)$ に対する事後分布が得られます。
事後分布の形は一般には複雑で、解析的に求まらない場合が多いため、MCMC(マルコフ連鎖モンテカルロ法) を用いてサンプリングし、近似的に求めます。
情報によって更新された後の $(\alpha,\beta,\epsilon)$ の事後分布は次のようになります。
| $(\alpha,\beta,\epsilon)$ の事後分布 |
|---|
 |
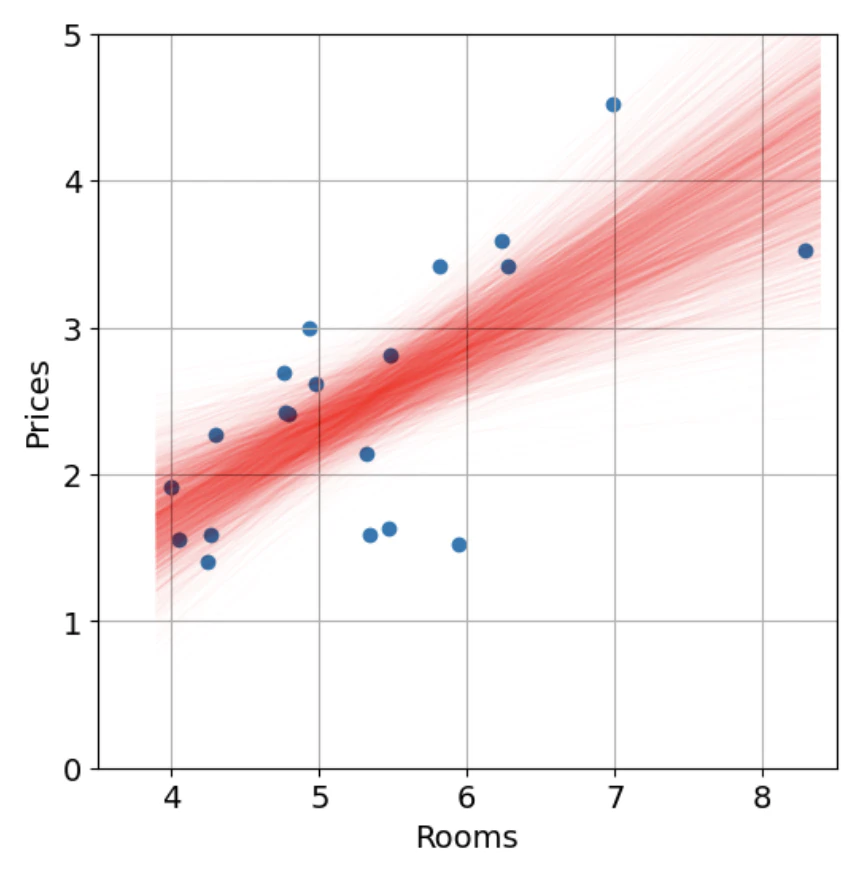
$(\alpha,\beta,\epsilon)$ がそれぞれ確率分布となるため、それらを用いて回帰直線を描くと幅を持った帯として表されます。
これは、モデルが予測に対してどのくらい不確実性を持っているかを示しています。
| ベイズ線形回帰 |
|---|
 |
まとめ
本記事では、ベイズ推論の基本的な流れを紹介しました。
ベイズ推論は「観測された情報を使って確率を更新する」というシンプルな考え方に基づいており、不確実な状況で判断を行う多くの場面で活躍します。
今回の記事が、ベイズ推論にふれる最初の一歩や、より深い理解のきっかけになれば幸いです。
参考
最後に、この記事を書くにあたり、参考にした教材を紹介します。
ここまで読んでいただき、ありがとうございました。