概要
この記事、メインはこことここを引用し、情報を忘れないために、書きました。
MergeTreeとは
公式サイトは下記のように記載しました。MergeTreeのドキュメント
その MergeTree この家族のエンジンそして他のエンジン (*MergeTree)は、最も堅牢なClickHouseテーブルエンジンです。
テーブルエンジンとするMergeTree一族
| エンジン名 | 継承関係(extends) | 備考 |
|---|---|---|
| MergeTree | ||
| ReplacingMergeTree | MergeTree | |
| SummingMergeTree | MergeTree | |
| ArrregatingMergeTree | MergeTree | |
| CollapsingMergeTree | MergeTree | |
| VersionedCollapsingMergeTree | MergeTree | |
| GraphiteMergeTree | MergeTree | |
| ReplicatedMergeTree | MergeTreeの分散処理できるバージョン | |
| ReplicatedReplacingMergeTree | ReplicatedMergeTree | 分散処理できるバージョン |
| ReplicatedSummingMergeTree | ReplicatedMergeTree | 分散処理できるバージョン |
| ReplicatedArrregatingMergeTree | ReplicatedMergeTree | 分散処理できるバージョン |
| ReplicatedCollapsingMergeTree | ReplicatedMergeTree | 分散処理できるバージョン |
| ReplicatedVersionedCollapsingMergeTree | ReplicatedMergeTree | 分散処理できるバージョン |
| ReplicatedGraphiteMergeTree | ReplicatedMergeTree | 分散処理できるバージョン |
MergeTreeを使う
特別な集計処理はない場合、MergeTreeはよく使われているらしい。
テーブルを作成する時、MergerTreeを使う
CREATE TABLE test
(
user_id String,
date Date,
group_id String
) ENGINE = MergeTree()
ORDER BY (user_id, date,group_id)
PRIMARY KEY (user_id, date)
PARTITION BY toYYYYMM(date)
SETTINGS index_granularity= 8192 ;
各パラメタの役割
-
ORDER BY: ソートキー。各パーティション内はORDER BYで設定されているキーによって、ソートを行う、普段はORDER BYだけを設定すれば良いらしい。 -
PRIMARY KEY: clickhouseのPRIMARY KEYは普段のMySQLの主キーとは違います。ここのPRIMARY KEYは重複となっても構わなくて、インデックスとして設計されたらしい。普段は指定しなくても良いらしい。(また、主キーはソートキーのプレフィックスである必要があります)
Primary key must be a prefix of the sorting key
-
PARTITION BY: 公式のサイトでは下記のように記載してあるので、そのまま載せます。(clickhouseはパーティションによって、データの更新・削除を行うのは可能です。)
パーティション分割は、 メルゲツリー 家族テーブル(含む 複製 テーブル)。 実体化ビュー に基づくMergeTreeテーブル支援を分割します。
パーティションは、指定された条件によるテーブル内のレコードの論理的な組合せです。 パーティションは、月別、日別、イベントタイプ別など、任意の条件で設定できます。 各パーティションは別に保存される簡単操作のデータです。 アクセス時のデータClickHouseの最小サブセットのパーティションは可能です。
-
index_granularity: ClickHouseはセレクトを行う場合、読み取るデータの最小サイズです。デフォルトのままでいい。8192はデフォルト値です。
ReplacingMergeTreeを使う
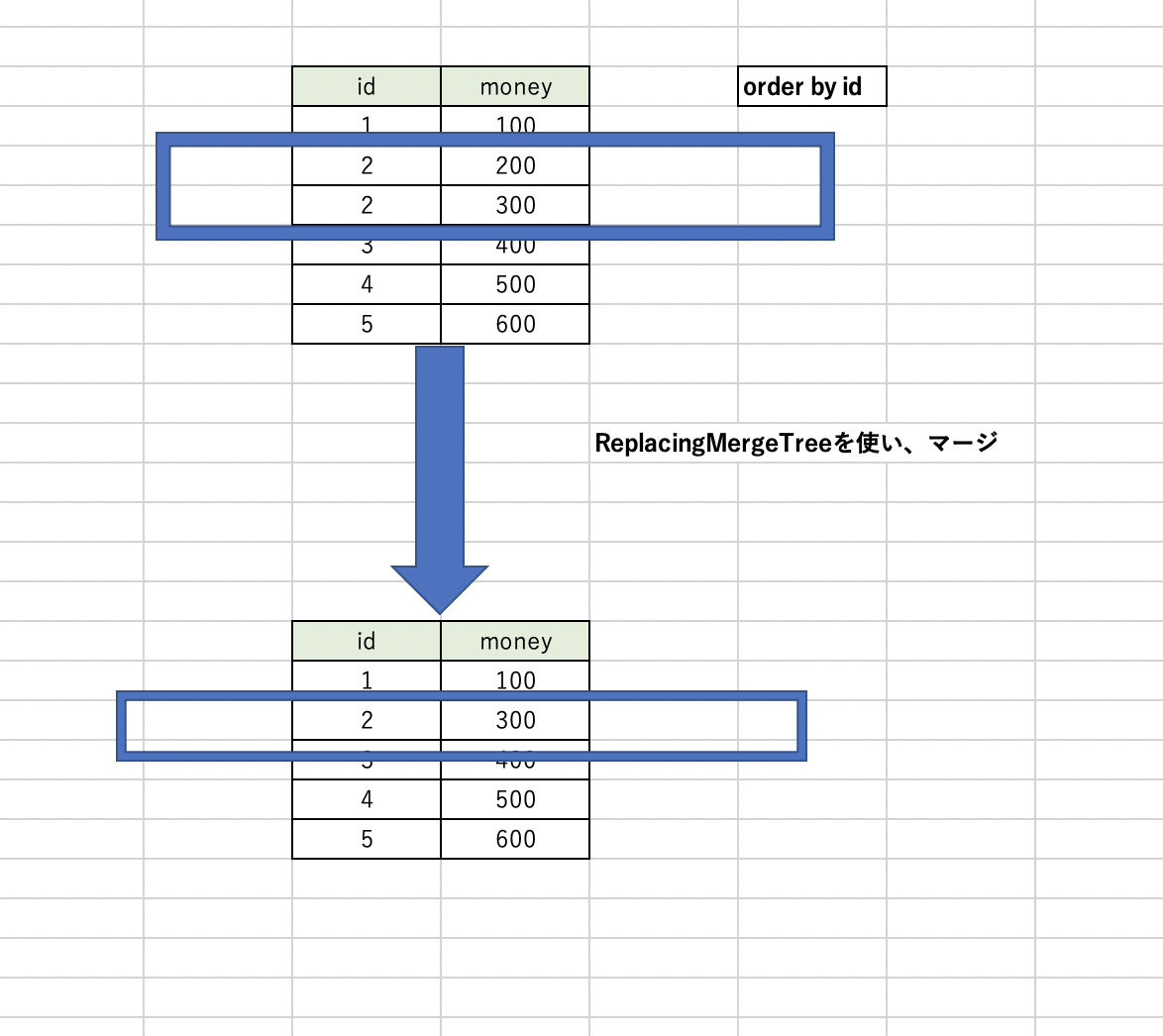
多分、ある人は気づいたと思いますが、ClickHouseのPRIMARY KEYは普段のプライマリーキーとは違いますので、じゃ、ClickHouseはMySQLみたいに、主キーを設定する場合はどうなるでしょうか?ここはReplacingMergeTree を使います。ClickHouseはORDER BYで設定されたキーによって、ReplacingMergeTreeの処理を行い、パーティションをマージする時、同じ値をもつレコードはreplaceするらしい。データ置き換えるルールとしてはカラムにverを設定する場合はver最大のやつだけ保留し、verを設定していない場合、最後のやつだけ保留する。
SummingMergeTreeを使う
SummingMergeTree集計したい時、設定した方が良さそう。SummingMergeTreeを使う場合、 primary keyを設定しているカラムは集計の対象ではないらしい。↓のはSummingMergeTreeを使うイメージです。

AggregatingMergeTreeを使う
AggregatingMergeTreeはちょっと複雑のfunctionを設定し、集計処理を行う可能なテーブルエンジンです。AggregateFunction は普段AggregatingMergeTreeと一緒に使います。引用
AggregatingMergeTree is also a kind of pre aggregation engine, which is used to improve the performance of aggregation calculation. The difference with SummingMergeTree is that SummingMergeTree aggregates non primary key columns, while AggregatingMergeTree can specify various aggregation functions.
AggregatingMergeTreeを使うイメージ↓
DROP TABLE IF EXISTS requests;
CREATE TABLE requests (
request_date Date,
request_time DateTime,
response_time Int,
request_uri String)
ENGINE = MergeTree(request_date, (request_time, request_uri), 8192);
CREATE MATERIALIZED VIEW requests_graph
ENGINE = AggregatingMergeTree(request_date, (request_hour,request_uri), 8192)
AS SELECT
request_date,
toStartOfHour(request_time) request_hour,
request_uri,
avgState(response_time) avg_response_time,
maxState(response_time) max_response_time,
minState(response_time) min_response_time,
countState() request_count
FROM requests
GROUP BY request_date, request_hour, request_uri;
insert into requests values (today(), now(), 10, 'ya.ru');
insert into requests values (today(), now(), 20, 'ya.ru');
insert into requests values (today(), now(), 10, 'google.ru');
insert into requests values (today(), now()+7200, 20, 'google.ru');
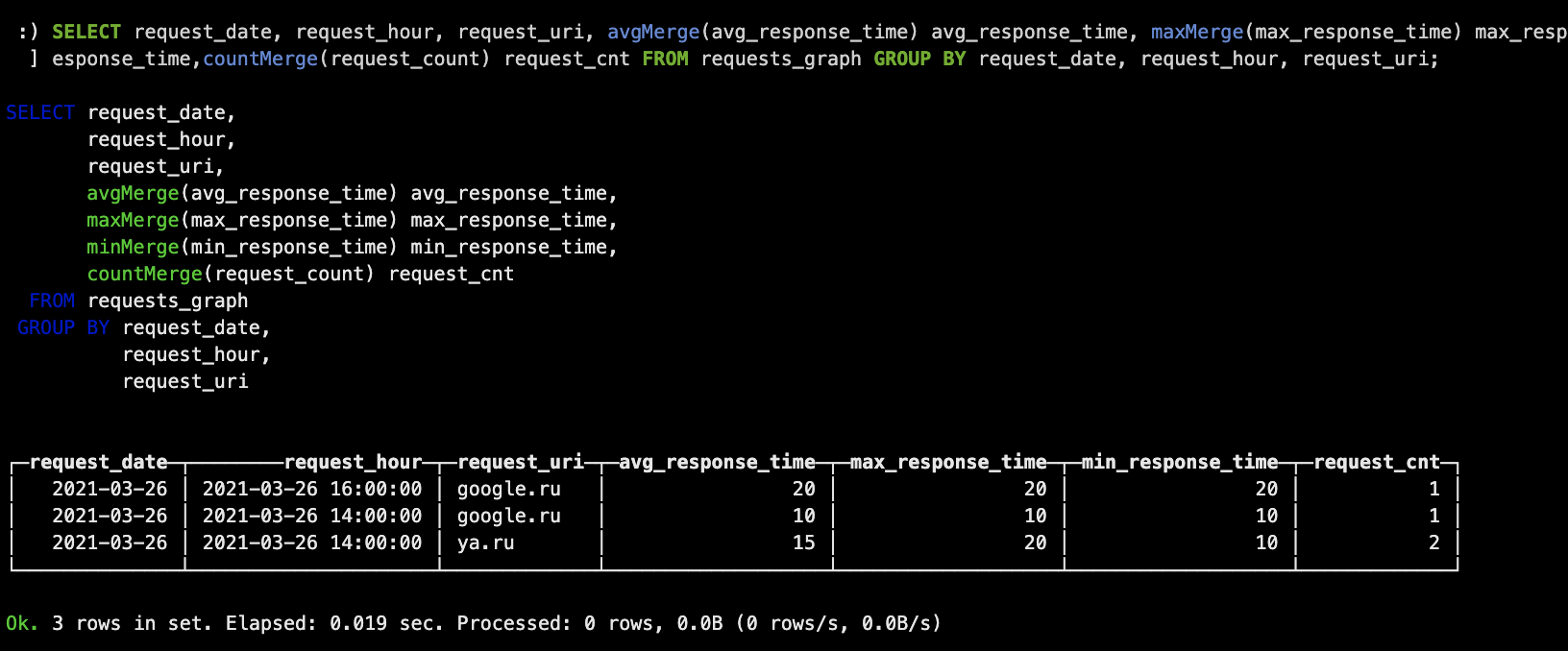
SELECT request_date,
request_hour,
request_uri,
avgMerge(avg_response_time) avg_response_time,
maxMerge(max_response_time) max_response_time,
minMerge(min_response_time) min_response_time,
countMerge(request_count) request_cnt
FROM requests_graph
GROUP BY request_date, request_hour, request_uri;
AggregateFunctionとAggregatingMergeTreeを使うイメージ↓(このサンプルはここ引用した)
CREATE TABLE agg_table(
id String,
city String,
code AggregateFunction(uniq,String),
value AggregateFunction(sum,UInt32),
create_time DateTime
)
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id,city)
PRIMARY KEY id
INSERT INTO TABLE agg_table SELECT 'A000','test', uniqState('code1'), sumState(toUInt32(100)), '2019-08-10 17:00:00';
INSERT INTO TABLE agg_table SELECT 'A000','test', uniqState('code1'), sumState(toUInt32(100)), '2019-08-10 17:00:00';
INSERT INTO TABLE agg_table SELECT 'A001','test', uniqState('code1'), sumState(toUInt32(100)), '2019-08-10 17:00:00';
INSERT INTO TABLE agg_table SELECT 'A001','test', uniqState('code2'), sumState(toUInt32(50)), '2019-08-10 17:00:00';
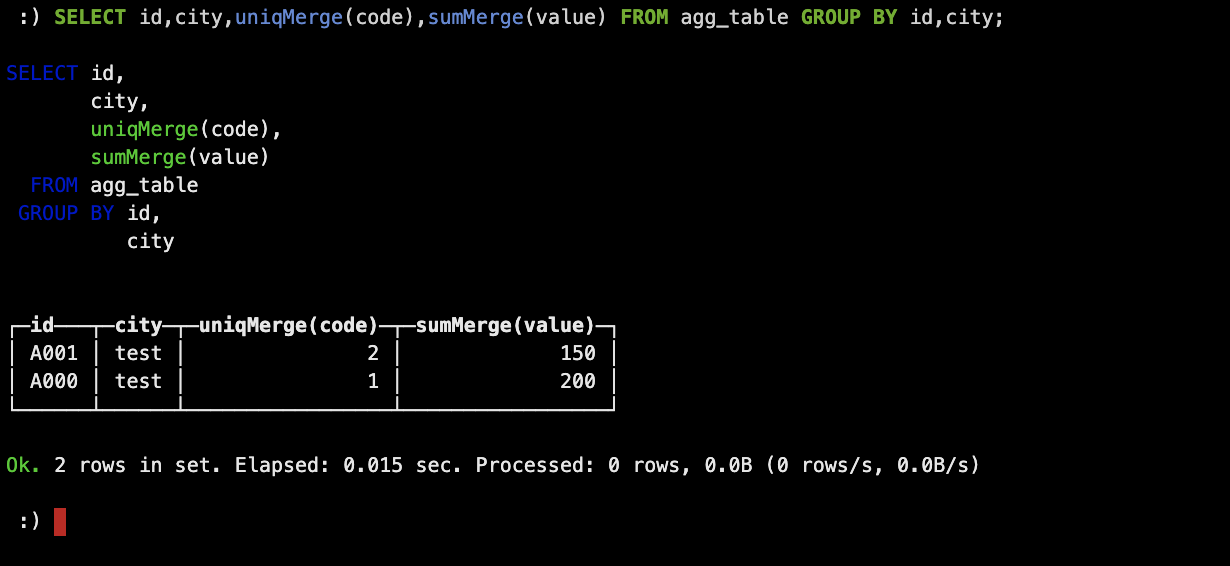
SELECT id,city,uniqMerge(code),sumMerge(value) FROM agg_table GROUP BY id,city;
ちなみに、PRIMARY KEYは一般的にAggregatingMergeTree、SummingMergeTreeを使う場合、設定する感じ。
感想
ClickHouseは色んなテーブルエンジンがあるので、今後まだ調査や勉強する必要がある